用10億訓練對訓練一個句子嵌入模型


句子嵌入是一種將句子對映到實數向量的方法。理想情況下,這些向量能夠捕捉句子的語義並具有高度通用性。這樣的表示可以用於許多下游應用,例如聚類、文字挖掘或問答。
作為專案“用10億訓練對訓練有史以來最好的句子嵌入模型”的一部分,我們開發了最先進的句子嵌入模型。該專案在Hugging Face組織的使用JAX/Flax進行NLP和CV社群周期間進行。我們得益於高效的硬體基礎設施來執行專案:7個TPU v3-8,以及來自Google的Flax、JAX和Cloud團隊成員關於高效深度學習框架的指導!
訓練方法
模型
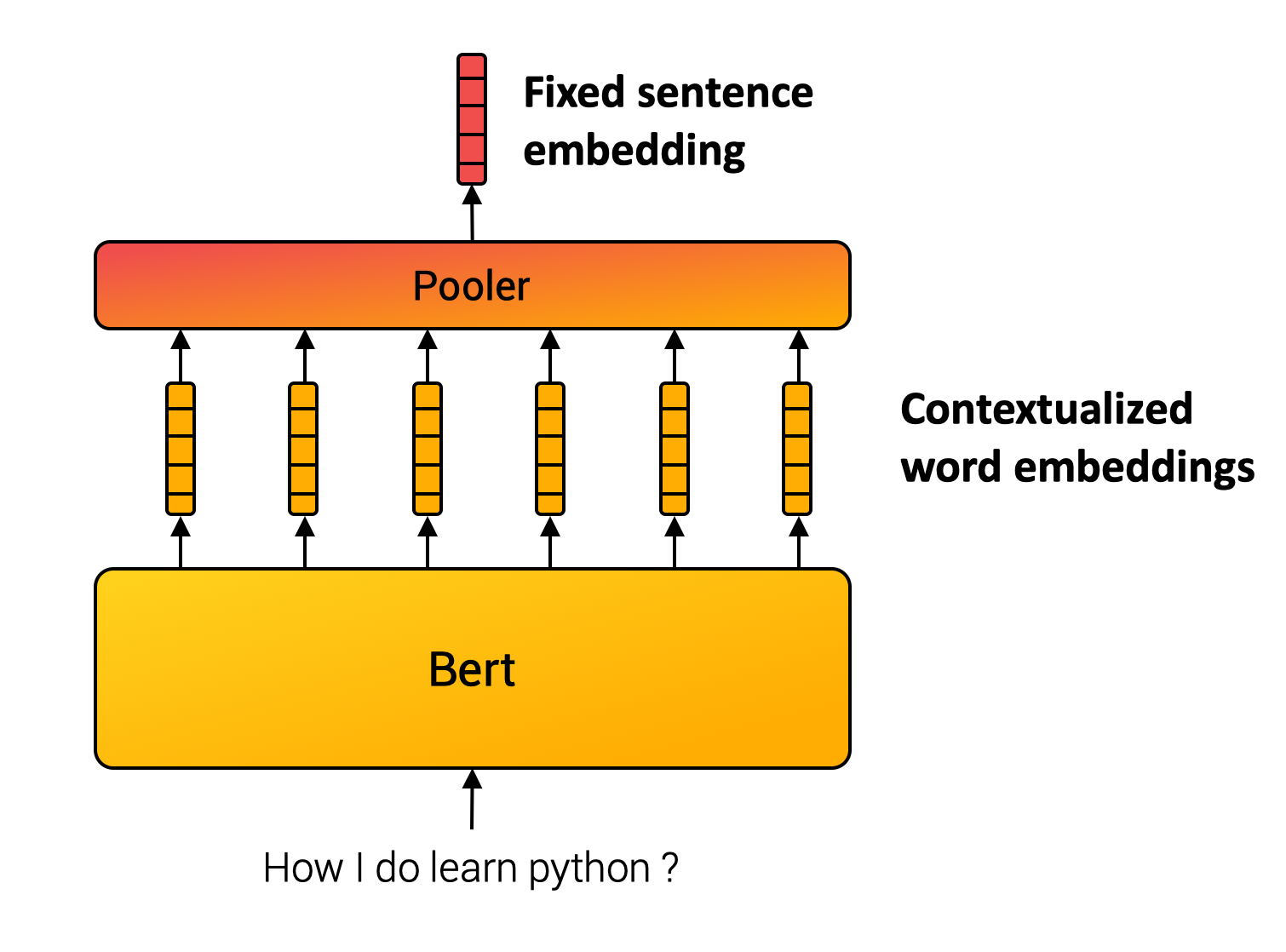
與單詞不同,我們無法定義一個有限的句子集合。因此,句子嵌入方法透過組合內部單詞來計算最終表示。例如,SentenceBert模型(Reimers and Gurevych, 2019)使用Transformer(許多NLP應用的基石),然後對上下文詞向量進行池化操作。(見下圖。)
多重負樣本排序損失
組合模組的引數通常使用自監督目標進行學習。對於該專案,我們使用了下圖所示的對比訓練方法。我們構建了一個包含句子對 的資料集,使得句子的含義相近。例如,我們考慮(查詢,答案段落)、(問題,重複問題)、(論文標題,引用論文標題)等配對。然後,我們訓練模型將配對 對映到相近的向量,同時將不匹配的配對 對映到嵌入空間中較遠的向量。這種訓練方法也稱為批內負樣本訓練,InfoNCE或NTXentLoss。
形式上,給定一批訓練樣本,模型最佳化以下損失函式
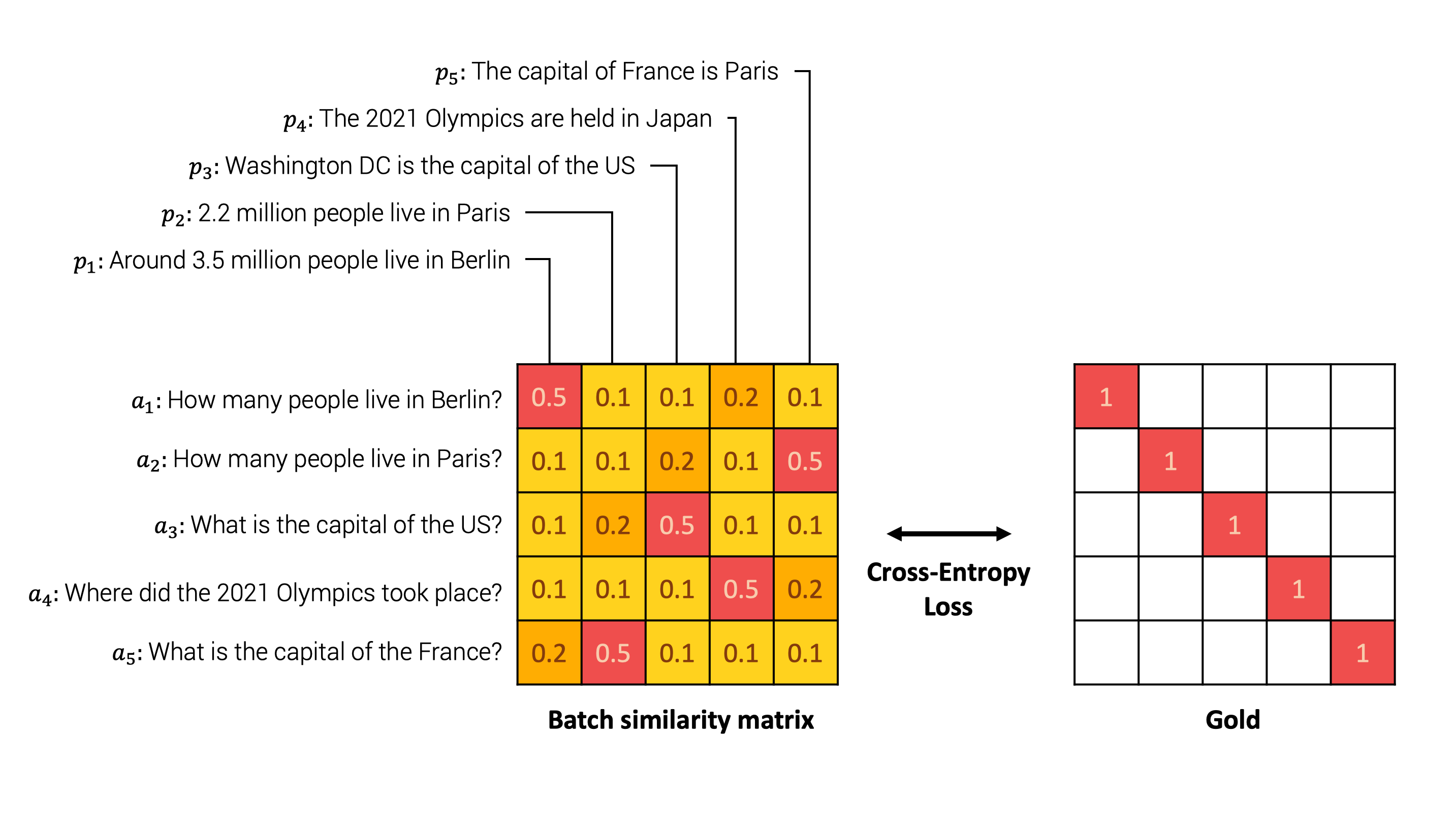
一個說明性的例子如下。模型首先嵌入批處理中每個句子對中的每個句子。然後,我們計算每對可能的 之間的相似度矩陣。然後,我們將相似度矩陣與表示原始配對的真值進行比較。最後,我們使用交叉熵損失進行比較。
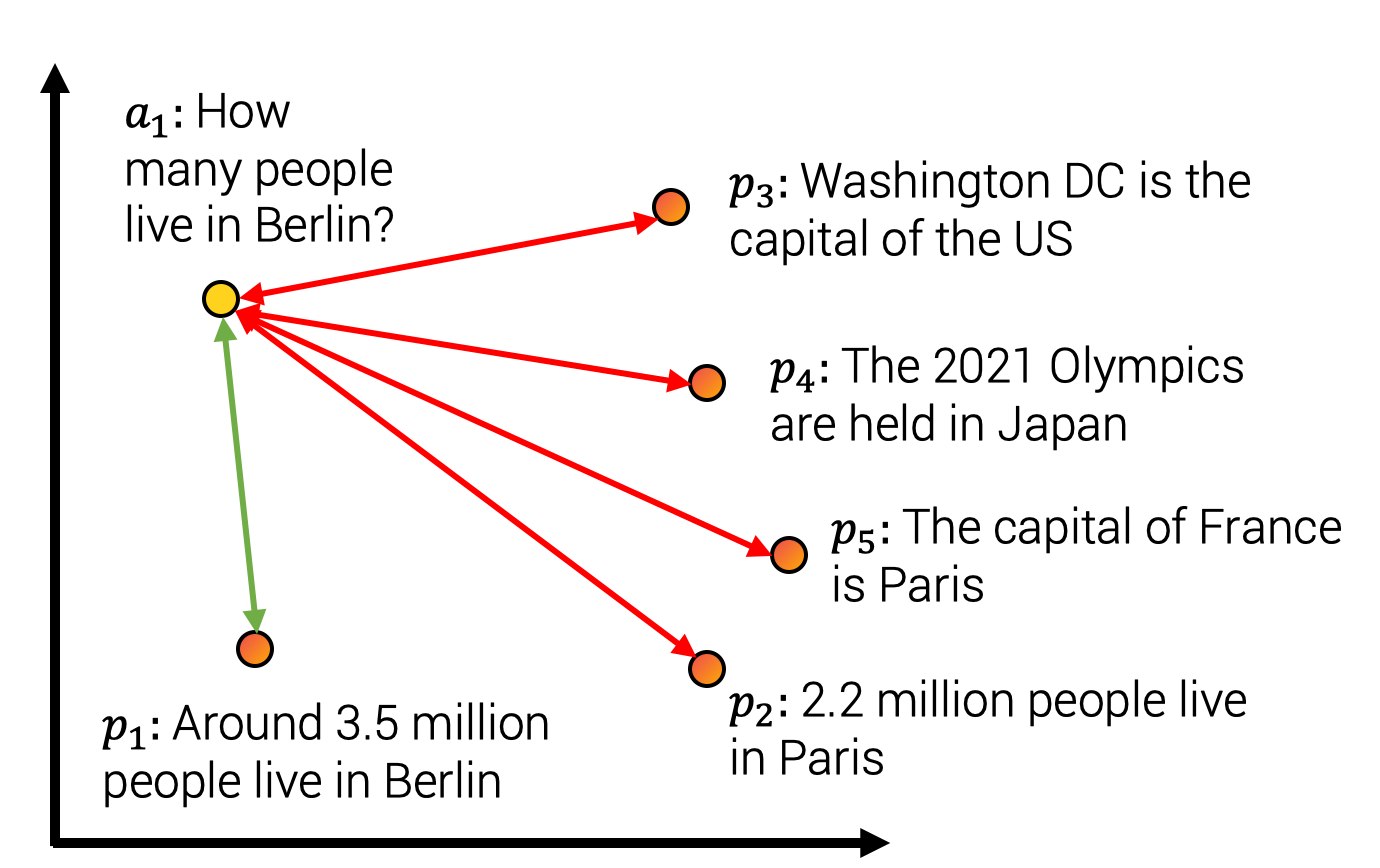
直觀地講,模型應該將句子“柏林有多少人居住?”和“大約有350萬人居住在柏林”分配高相似度,而將其他負面答案(例如“法國的首都是巴黎”)分配低相似度,如下圖所示。
在損失方程中,sim 表示 之間的相似度函式。相似度函式可以是餘弦相似度或點積運算。這兩種方法各有優缺點,總結如下(Thakur et al., 2021,Bachrach et al., 2014)
| 餘弦相似度 | 點積 |
|---|---|
| 向量與其自身相似度最高,因為 。 | 其他向量可以具有更高的點積 。 |
| 對於歸一化向量,它等於點積。最大向量長度等於1。 | 對於某些近似最近鄰方法,它可能較慢,因為最大向量未知。 |
| 對於歸一化向量,它與歐幾里得距離成正比。適用於k均值聚類。 | 它不適用於k均值聚類。 |
實踐中,我們使用了縮放相似度,因為分數差異往往過小,並應用縮放因子 ,使得 ,通常 (Henderson et al., 2020,Radford et al., 2021)。
透過更好的批次提高質量
在我們的方法中,我們構建樣本對 的批次。我們將批次中的所有其他樣本,即 ,視為負樣本對。因此,批次組成是關鍵的訓練方面。根據該領域的文獻,我們主要關注批次的三個主要方面。
1. 批次大小很重要
在對比學習中,較大的批次大小意味著更好的效能。如從Qu et al., (2021)中提取的圖中所示,較大的批次大小可以提高結果。
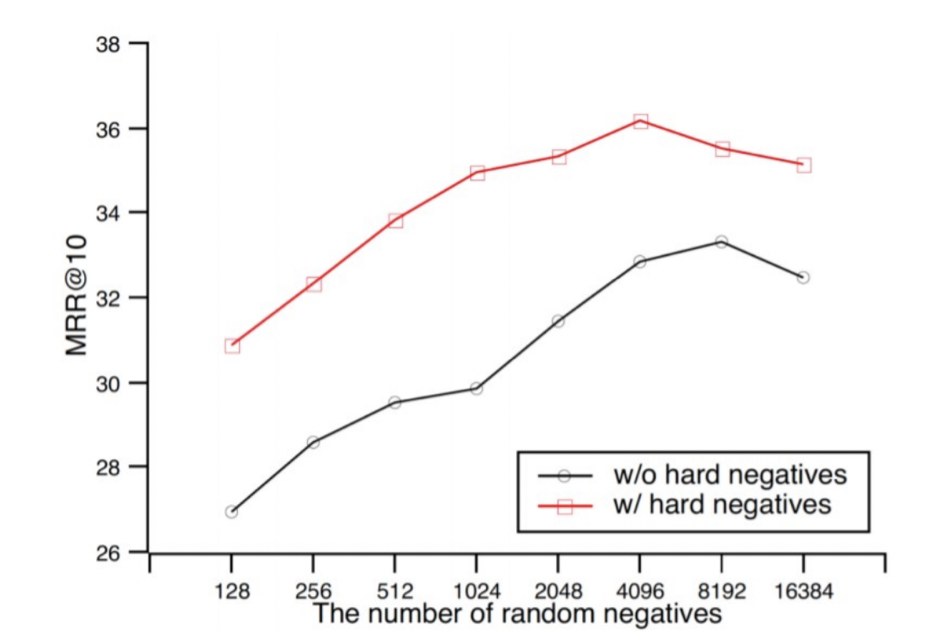
2. 難負樣本
在同一張圖中,我們觀察到包含難負樣本也能提高效能。難負樣本是指很難與 區分的樣本 。在我們的例子中,它可能是“法國的首都是什麼?”和“美國的首都是什麼?”這樣的配對,它們語義內容相近,需要精確理解整個句子才能正確回答。相反,“法國的首都是什麼?”和“有多少部星球大戰電影?”這樣的樣本則較容易區分,因為它們不屬於同一主題。
3. 跨資料集批次
我們連線了多個數據集來訓練我們的模型。我們構建了一個大型批次,並從同一批次資料集中收集樣本,以限制主題分佈並傾向於難負樣本。然而,我們還在批次中混合了至少兩個資料集,以學習主題之間的全域性結構,而不僅僅是主題內的區域性結構。
訓練基礎設施和資料
如前所述,資料量和批次大小直接影響模型效能。作為專案的一部分,我們得益於高效的硬體基礎設施。我們在TPU上訓練模型,TPU是谷歌開發的計算單元,對於矩陣乘法非常高效。TPU有一些硬體特性,可能需要一些特定的程式碼實現。
此外,我們在一個大型語料庫上訓練了模型,我們連線了多達10億個句子對資料集!所有使用的模型資料集都詳細列在模型卡片中。
結論
您可以在我們的HuggingFace倉庫中找到我們在挑戰期間建立的所有模型和資料集。我們訓練了20個通用句子轉換器模型,例如Mini-LM(Wang et al., 2020)、RoBERTa(liu et al., 2019)、DistilBERT(Sanh et al., 2020)和MPNet(Song et al., 2020)。我們的模型在多個通用句子相似度評估任務中達到了最先進的水平。我們還共享了8個數據集,專門用於問答、句子相似度和性別評估。
通用句子嵌入可用於多種應用。我們構建了一個Spaces演示來展示多種應用
- 句子相似度模組比較主文字與您選擇的其他文字的相似度。在後臺,演示提取每個文字的嵌入,並使用餘弦相似度計算源句子與其他文字之間的相似度。
- 非對稱問答將給定查詢的答案可能性與您選擇的候選答案進行比較。
- 搜尋/聚類返回與查詢相近的答案。例如,如果輸入“python”,它將使用點積距離檢索最接近的句子。
- 性別偏見評估透過隨機抽樣句子來報告訓練集中固有的性別偏見。給定一個錨文字,其中未提及目標職業的性別,以及兩個帶有性別代詞的命題,我們比較模型是否為給定命題分配更高的相似度,從而評估其偏向特定性別的比例。
使用JAX/Flax進行NLP和CV社群周是一次緊張而收穫豐厚的體驗!Google的Flax、JAX和Cloud以及Hugging Face團隊成員的指導質量和他們的存在幫助我們所有人學到了很多。我們希望所有專案都像我們自己的專案一樣充滿樂趣。如果您有任何問題或建議,請隨時與我們聯絡!

