Accelerate 1.0.0








Accelerate 在今天是什麼?
3.5 年前,Accelerate 是一個簡單的框架,旨在透過一個低階抽象來簡化*原始* PyTorch 訓練迴圈,從而使多 GPU 和 TPU 系統上的訓練更容易。
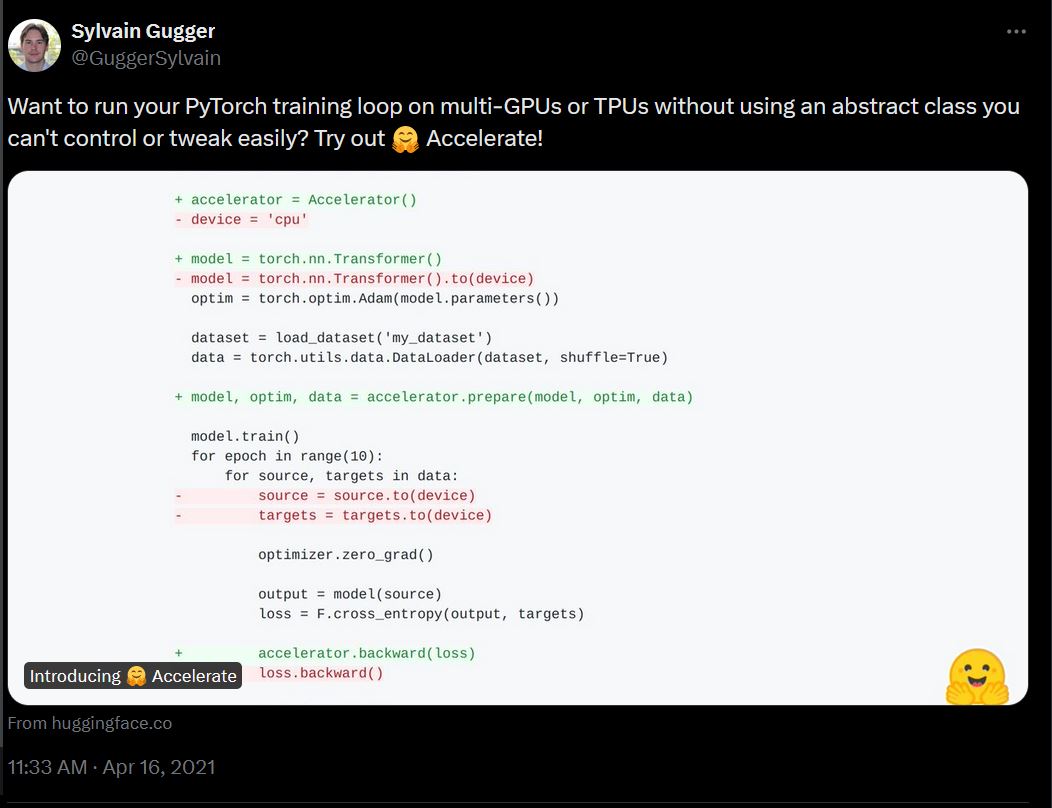
從那時起,Accelerate 已擴充套件成為一個多功能的庫,旨在解決大規模訓練和大型模型面臨的許多常見問題,在這個 4050 億引數(Llama)成為新的語言模型規模的時代。這包括:
- 一個靈活的低階訓練 API,允許在六種不同的硬體加速器(CPU、GPU、TPU、XPU、NPU、MLU)上進行訓練,同時保留原始訓練迴圈的 99%。
- 一個易於使用的命令列介面,旨在配置和執行跨不同硬體配置的指令碼。
- 大模型推理或
device_map="auto"的誕生地,允許使用者不僅在多裝置上對 LLM 進行推理,現在還透過引數高效微調(PEFT)等技術幫助在小型計算裝置上訓練 LLM。
這三個方面使 Accelerate 成為了 Hugging Face 幾乎所有軟體包的基礎,包括 transformers、diffusers、peft、trl 等!
由於該軟體包已穩定近一年,我們很高興地宣佈,從今天起,我們已釋出 Accelerate 1.0.0 的第一個釋出候選版本!
本部落格將詳細介紹:
- 我們為什麼決定釋出 1.0 版本?
- Accelerate 的未來是什麼,以及我們認為 PyTorch 的整體發展方向是什麼?
- 發生了哪些破壞性更改和棄用,以及如何輕鬆遷移?
為什麼是 1.0 版本?
釋出 1.0.0 版本的計劃已經醞釀了一年多。API 大致達到了我們期望的程度,以 Accelerator 為中心,大大簡化了配置並使其更具可擴充套件性。然而,我們知道在我們將 Accelerate 的“基礎”稱為“功能完整”之前,還有一些缺失的部分:
- 整合 MS-AMP 和
TransformersEngine的 FP8 支援(更多資訊請參閱此處和此處) - 在使用 DeepSpeed 時支援多個模型的編排(實驗性)
- 大模型推理 API 的
torch.compile支援(需要torch>=2.5) - 將
torch.distributed.pipelining整合作為另一種分散式推理機制 - 將
torchdata.StatefulDataLoader整合作為另一種資料載入器機制
隨著 1.0 版本所做的更改,Accelerate 已準備好應對新的技術整合,同時保持使用者介面 API 的穩定。
Accelerate 的未來
現在 1.0 版本即將完成,我們可以專注於社群中即將出現的新技術,並找到將其整合到 Accelerate 中的途徑,因為我們預見 PyTorch 生態系統即將發生一些根本性的變化。
- 作為多模型 DeepSpeed 支援的一部分,我們發現雖然 DeepSpeed 目前的運作方式*可以*,但隨著我們努力支援簡單的封裝以準備模型用於任何多模型訓練場景,最終可能需要對整體 API 進行一些重大更改。
- 隨著 torchao 和 torchtitan 的興起,它們暗示了 PyTorch 的未來整體方向。目標是更原生支援 FP8 訓練、新的分散式分片 API 以及對新版本 FSDP(FSDPv2)的支援,我們預計 Accelerate 的大部分內部和通用使用 API 將需要更改(希望不會太劇烈),以滿足這些需求,因為這些框架將慢慢變得更加穩定。
- 在
torchao/FP8 的基礎上,許多新框架正在引入不同的想法和實現,以使 FP8 訓練能夠正常穩定執行(例如transformer_engine、torchao、MS-AMP、nanotron)。我們 Accelerate 的目標是將這些實現集中在一個地方,並透過簡單的配置讓使用者根據自己的意願探索和測試每一個,旨在找到最終最穩定和靈活的那些。這是一個快速發展的研究領域(並非雙關語),特別是隨著 NVIDIA 的 FP4 訓練支援即將到來,我們希望確保我們不僅能夠支援每種方法,而且能夠為每種方法提供 可靠的基準,以展示它們開箱即用的特性(只需最少的調整)與原生 BF16 訓練的比較。
我們對 PyTorch 生態系統中分散式訓練的未來感到非常興奮,我們希望確保 Accelerate 在每一步都提供支援,降低這些新技術的入門門檻。透過這樣做,我們希望社群能夠繼續共同實驗和學習,以找到在更復雜的計算系統上訓練和擴充套件更大模型的最佳方法。
如何試用
要嘗試 Accelerate 的第一個釋出候選版本,請使用以下方法之一:
- pip
pip install --pre accelerate
- Docker
docker pull huggingface/accelerate:gpu-release-1.0.0rc1
有效的釋出標籤有:
gpu-release-1.0.0rc1cpu-release-1.0.0rc1gpu-fp8-transformerengine-release-1.0.0rc1gpu-deepspeed-release-1.0.0rc1
遷移幫助
以下是本次釋出中所有棄用的完整詳細資訊:
- 傳入
dispatch_batches、split_batches、even_batches和use_seedable_sampler到Accelerator()現在應透過建立accelerate.utils.DataLoaderConfiguration()並將其傳入Accelerator()來處理(Accelerator(dataloader_config=DataLoaderConfiguration(...)))。 Accelerator().use_fp16和AcceleratorState().use_fp16已被移除;這應該透過檢查accelerator.mixed_precision == "fp16"來替代。Accelerator().autocast()不再接受cache_enabled引數。取而代之的是,應該使用AutocastKwargs()例項來處理此標誌(以及其他標誌),並將其傳遞給Accelerator(Accelerator(kwargs_handlers=[AutocastKwargs(cache_enabled=True)]))。accelerate.utils.is_tpu_available應替換為accelerate.utils.is_torch_xla_available。accelerate.utils.modeling.shard_checkpoint應替換為huggingface_hub庫中的split_torch_state_dict_into_shards。accelerate.tqdm.tqdm()不再接受True/False作為第一個引數,而是應該將main_process_only作為命名引數傳入。ACCELERATE_DISABLE_RICH不再是有效的環境變數,取而代之的是,應該透過設定ACCELERATE_ENABLE_RICH=1手動啟用rich回溯。- FSDP 設定
fsdp_backward_prefetch_policy已替換為fsdp_backward_prefetch。
總結
非常感謝您使用 Accelerate;在過去幾年中,看著一個最初的小想法發展成為超過 1 億次下載量和近 30 萬次每日下載量,這真是令人驚歎。
透過這次釋出候選版本,我們希望為社群提供一個機會,在正式釋出之前進行試用並遷移到 1.0 版本。







