音訊資料集完全指南







引言
🤗 Datasets 是一個開源庫,用於下載和準備來自所有領域的資料集。其極簡的 API 允許使用者僅用一行 Python 程式碼就能下載和準備資料集,並提供了一套函式來實現高效的預處理。它提供的資料集數量是無與倫比的,所有最流行的機器學習資料集都可以下載。
不僅如此,🤗 Datasets 還內建了多種針對音訊的特定功能,讓研究人員和從業者都能輕鬆處理音訊資料集。在這篇部落格中,我們將演示這些功能,展示為什麼 🤗 Datasets 是下載和準備音訊資料集的首選之地。
目錄
Hub
Hugging Face Hub 是一個託管模型、資料集和演示的平臺,所有內容都是開源和公開可用的。它擁有一個不斷增長的音訊資料集集合,涵蓋了各種領域、任務和語言。透過與 🤗 Datasets 的緊密整合,Hub 上的所有資料集都可以用一行程式碼下載。
讓我們前往 Hub,按任務篩選資料集

在撰寫本文時,Hub 上有 77 個語音識別資料集和 28 個音訊分類資料集,而且這些數字還在不斷增加。您可以選擇其中任何一個數據集來滿足您的需求。讓我們看看第一個語音識別結果。點選 common_voice 會彈出資料集卡片。
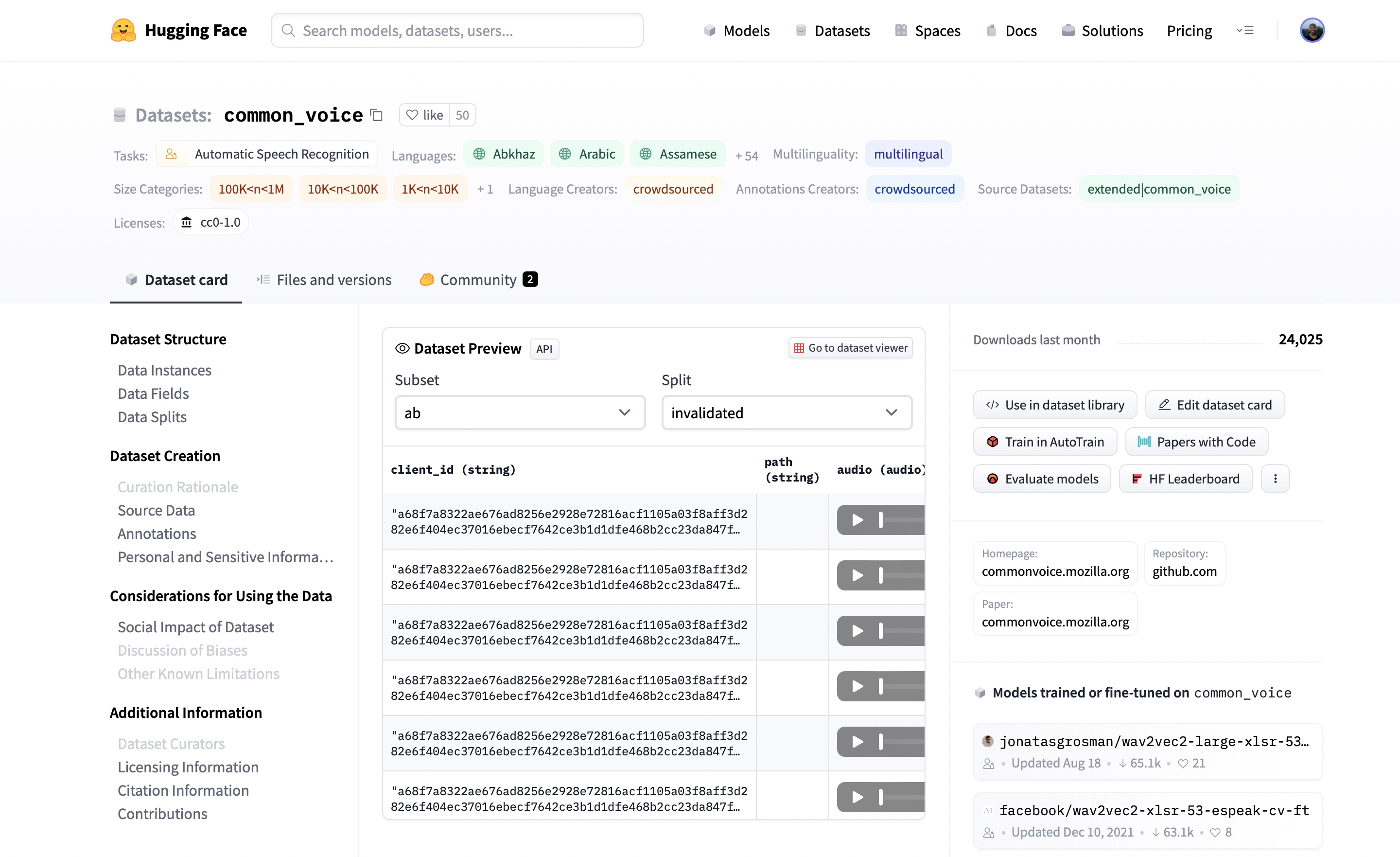
在這裡,我們可以找到關於資料集的附加資訊,檢視哪些模型在該資料集上訓練過,最令人興奮的是,可以即時收聽實際的音訊樣本。資料集預覽顯示在資料集卡片的中間。它向我們展示了每個子集和資料分割的前 100 個樣本。更重要的是,它已經載入了音訊樣本,供我們即時收聽。如果我們點選第一個樣本的播放按鈕,我們就可以聽到音訊並看到相應的文字。
資料集預覽是在決定使用音訊資料集之前體驗它的絕佳方式。您可以選擇 Hub 上的任何資料集,滾動瀏覽樣本,收聽不同子集和資料分割的音訊,判斷它是否適合您的需求。一旦您選擇了一個數據集,載入資料以便開始使用就變得非常簡單。
載入音訊資料集
🤗 Datasets 的一個關鍵特性是能夠僅用一行 Python 程式碼就下載和準備資料集。這是透過 load_dataset 函式實現的。傳統上,載入資料集涉及:i) 下載原始資料,ii) 將其從壓縮格式中解壓,以及 iii) 準備單個樣本和資料分割。使用 load_dataset,所有繁重的工作都在幕後完成。
讓我們以載入來自 Speech Colab 的 GigaSpeech 資料集為例。GigaSpeech 是一個相對較新的語音識別資料集,用於對學術語音系統進行基準測試,也是 Hugging Face Hub 上眾多音訊資料集之一。
要載入 GigaSpeech 資料集,我們只需獲取該資料集在 Hub 上的識別符號 (speechcolab/gigaspeech) 並將其指定給 load_dataset 函式。GigaSpeech 有五種大小遞增的配置,從 xs (10小時) 到 xl (10,000小時) 不等。在本教程中,我們將載入其中最小的配置。資料集的識別符號和所需的配置就是我們下載資料集所需要的全部資訊。
from datasets import load_dataset
gigaspeech = load_dataset("speechcolab/gigaspeech", "xs")
print(gigaspeech)
列印輸出
DatasetDict({
train: Dataset({
features: ['segment_id', 'speaker', 'text', 'audio', 'begin_time', 'end_time', 'audio_id', 'title', 'url', 'source', 'category', 'original_full_path'],
num_rows: 9389
})
validation: Dataset({
features: ['segment_id', 'speaker', 'text', 'audio', 'begin_time', 'end_time', 'audio_id', 'title', 'url', 'source', 'category', 'original_full_path'],
num_rows: 6750
})
test: Dataset({
features: ['segment_id', 'speaker', 'text', 'audio', 'begin_time', 'end_time', 'audio_id', 'title', 'url', 'source', 'category', 'original_full_path'],
num_rows: 25619
})
})
就這樣,我們準備好了 GigaSpeech 資料集!沒有比這更容易載入音訊資料集的方法了。我們可以看到訓練集、驗證集和測試集都已預先分割槽,並附有各自的相應資訊。
load_dataset 函式返回的物件 gigaspeech 是一個 DatasetDict。我們可以像對待普通 Python 字典一樣對待它。要獲取訓練集,我們將相應的鍵傳遞給 gigaspeech 字典。
print(gigaspeech["train"])
列印輸出
Dataset({
features: ['segment_id', 'speaker', 'text', 'audio', 'begin_time', 'end_time', 'audio_id', 'title', 'url', 'source', 'category', 'original_full_path'],
num_rows: 9389
})
這將返回一個 Dataset 物件,其中包含訓練集的資料。我們可以更進一步,獲取該分割的第一個元素。同樣,這可以透過標準的 Python 索引實現。
print(gigaspeech["train"][0])
列印輸出
{'segment_id': 'YOU0000000315_S0000660',
'speaker': 'N/A',
'text': "AS THEY'RE LEAVING <COMMA> CAN KASH PULL ZAHRA ASIDE REALLY QUICKLY <QUESTIONMARK>",
'audio': {'path': '/home/sanchit_huggingface_co/.cache/huggingface/datasets/downloads/extracted/7f8541f130925e9b2af7d37256f2f61f9d6ff21bf4a94f7c1a3803ec648d7d79/xs_chunks_0000/YOU0000000315_S0000660.wav',
'array': array([0.0005188 , 0.00085449, 0.00012207, ..., 0.00125122, 0.00076294,
0.00036621], dtype=float32),
'sampling_rate': 16000
},
'begin_time': 2941.889892578125,
'end_time': 2945.070068359375,
'audio_id': 'YOU0000000315',
'title': 'Return to Vasselheim | Critical Role: VOX MACHINA | Episode 43',
'url': 'https://www.youtube.com/watch?v=zr2n1fLVasU',
'source': 2,
'category': 24,
'original_full_path': 'audio/youtube/P0004/YOU0000000315.opus',
}
我們可以看到訓練集返回了許多特徵,包括 segment_id、speaker、text、audio 等等。對於語音識別,我們主要關注 text 和 audio 列。
使用 🤗 Datasets 的 remove_columns 方法,我們可以移除語音識別不需要的資料集特徵。
COLUMNS_TO_KEEP = ["text", "audio"]
all_columns = gigaspeech["train"].column_names
columns_to_remove = set(all_columns) - set(COLUMNS_TO_KEEP)
gigaspeech = gigaspeech.remove_columns(columns_to_remove)
我們來檢查一下是否成功保留了 text 和 audio 列。
print(gigaspeech["train"][0])
列印輸出
{'text': "AS THEY'RE LEAVING <COMMA> CAN KASH PULL ZAHRA ASIDE REALLY QUICKLY <QUESTIONMARK>",
'audio': {'path': '/home/sanchit_huggingface_co/.cache/huggingface/datasets/downloads/extracted/7f8541f130925e9b2af7d37256f2f61f9d6ff21bf4a94f7c1a3803ec648d7d79/xs_chunks_0000/YOU0000000315_S0000660.wav',
'array': array([0.0005188 , 0.00085449, 0.00012207, ..., 0.00125122, 0.00076294,
0.00036621], dtype=float32),
'sampling_rate': 16000}}
太好了!我們可以看到我們得到了所需的兩個列 text 和 audio。text 是一個包含樣本轉錄文字的字串,而 audio 是一個取樣率為 16KHz 的一維振幅值陣列。我們的資料集載入完成了!
易於載入,易於處理
用 🤗 Datasets 載入資料集只是樂趣的一半。我們現在可以使用其提供的工具套件來高效地預處理資料,為模型訓練或推理做準備。在本節中,我們將執行資料預處理的三個階段。
1. 重取樣音訊資料
load_dataset 函式會以釋出時的取樣率準備音訊樣本。但這不一定是我們模型所期望的取樣率。在這種情況下,我們需要將音訊 重取樣 到正確的取樣率。
我們可以使用 🤗 Datasets 的 cast_column 方法將音訊輸入設定為我們期望的取樣率。此操作不會就地更改音訊,而是向 datasets 發出訊號,在載入音訊樣本時 動態地 對其進行重取樣。下面的程式碼單元格會將取樣率設定為 8kHz。
from datasets import Audio
gigaspeech = gigaspeech.cast_column("audio", Audio(sampling_rate=8000))
重新載入 GigaSpeech 資料集中的第一個音訊樣本會將其重取樣到所需的取樣率。
print(gigaspeech["train"][0])
列印輸出
{'text': "AS THEY'RE LEAVING <COMMA> CAN KASH PULL ZAHRA ASIDE REALLY QUICKLY <QUESTIONMARK>",
'audio': {'path': '/home/sanchit_huggingface_co/.cache/huggingface/datasets/downloads/extracted/7f8541f130925e9b2af7d37256f2f61f9d6ff21bf4a94f7c1a3803ec648d7d79/xs_chunks_0000/YOU0000000315_S0000660.wav',
'array': array([ 0.00046338, 0.00034808, -0.00086153, ..., 0.00099299,
0.00083484, 0.00080221], dtype=float32),
'sampling_rate': 8000}
}
我們可以看到取樣率已經降到了 8kHz。陣列值也不同了,因為我們現在每兩個原始振幅值大約只保留一個。讓我們將資料集的取樣率設定回 16kHz,這是大多數語音識別模型所期望的取樣率。
gigaspeech = gigaspeech.cast_column("audio", Audio(sampling_rate=16000))
print(gigaspeech["train"][0])
列印輸出
{'text': "AS THEY'RE LEAVING <COMMA> CAN KASH PULL ZAHRA ASIDE REALLY QUICKLY <QUESTIONMARK>",
'audio': {'path': '/home/sanchit_huggingface_co/.cache/huggingface/datasets/downloads/extracted/7f8541f130925e9b2af7d37256f2f61f9d6ff21bf4a94f7c1a3803ec648d7d79/xs_chunks_0000/YOU0000000315_S0000660.wav',
'array': array([0.0005188 , 0.00085449, 0.00012207, ..., 0.00125122, 0.00076294,
0.00036621], dtype=float32),
'sampling_rate': 16000}
}
很簡單!cast_column 提供了一種在需要時直接重取樣音訊資料集的機制。
2. 預處理函式
處理音訊資料集最具挑戰性的方面之一是以正確的格式為我們的模型準備資料。使用 🤗 Datasets 的 map 方法,我們可以編寫一個函式來預處理資料集的單個樣本,然後無需任何程式碼更改即可將其應用於每個樣本。
首先,讓我們從 🤗 Transformers 載入一個處理器物件。這個處理器將音訊預處理為輸入特徵,並將目標文字標記化為標籤。AutoProcessor 類用於從給定的模型檢查點載入處理器。在示例中,我們從 OpenAI 的 Whisper medium.en 檢查點載入處理器,但您可以將其更改為 Hugging Face Hub 上的任何模型識別符號。
from transformers import AutoProcessor
processor = AutoProcessor.from_pretrained("openai/whisper-medium.en")
太好了!現在我們可以編寫一個函式,它接受一個訓練樣本,並透過 processor 為我們的模型進行準備。我們還將計算每個音訊樣本的輸入長度,這是下一步資料準備所需的資訊。
def prepare_dataset(batch):
audio = batch["audio"]
batch = processor(audio["array"], sampling_rate=audio["sampling_rate"], text=batch["text"])
batch["input_length"] = len(audio["array"]) / audio["sampling_rate"]
return batch
我們可以使用 🤗 Datasets 的 map 方法將資料準備函式應用於我們所有的訓練樣本。在這裡,我們還刪除了 text 和 audio 列,因為我們已經將音訊預處理為輸入特徵,並將文字標記化為標籤。
gigaspeech = gigaspeech.map(prepare_dataset, remove_columns=gigaspeech["train"].column_names)
3. 過濾函式
在訓練之前,我們可能有一個過濾訓練資料的啟發式方法。例如,我們可能想要過濾掉任何長度超過 30 秒的音訊樣本,以防止音訊樣本被截斷或冒著記憶體不足的風險。我們可以用與上一步為模型準備資料幾乎相同的方式來做到這一點。
我們首先編寫一個函式,指示哪些樣本要保留,哪些要丟棄。這個函式 is_audio_length_in_range 返回一個布林值:短於 30 秒的樣本返回 True,而長於 30 秒的樣本返回 False。
MAX_DURATION_IN_SECONDS = 30.0
def is_audio_length_in_range(input_length):
return input_length < MAX_DURATION_IN_SECONDS
我們可以使用 🤗 Datasets 的 filter 方法將此過濾函式應用於我們所有的訓練樣本,保留所有短於 30 秒的樣本 (True),並丟棄那些較長的樣本 (False)。
gigaspeech["train"] = gigaspeech["train"].filter(is_audio_length_in_range, input_columns=["input_length"])
就這樣,我們為模型完全準備好了 GigaSpeech 資料集!總的來說,從載入資料集到最後的過濾步驟,這個過程總共需要 13 行 Python 程式碼。
為了儘可能保持 notebook 的通用性,我們只執行了基本的資料準備步驟。然而,您可以對音訊資料集應用的函式沒有任何限制。您可以擴充套件函式 prepare_dataset 來執行更復雜的操作,例如資料增強、語音活動檢測或降噪。使用 🤗 Datasets,如果您能用 Python 函式編寫它,您就能將它應用於您的資料集!
流式處理模式:終極解決方案
處理音訊資料集面臨的最大挑戰之一是它們的龐大規模。GigaSpeech 的 xs 配置僅包含 10 小時的訓練資料,但下載和準備就佔用了超過 13GB 的儲存空間。那麼,當我們想要在更大的資料分割上進行訓練時會發生什麼呢?完整的 xl 配置包含 10,000 小時的訓練資料,需要超過 1TB 的儲存空間。對於大多數語音研究人員來說,這遠遠超出了典型硬碟的規格。我們是否需要花錢購買額外的儲存空間?還是有一種方法可以在這些資料集上進行訓練而 沒有磁碟空間限制?
🤗 Datasets 讓我們能夠做到這一點。這是透過使用流式處理 (streaming) 模式實現的,如圖 1 所示。流式處理允許我們在迭代資料集時逐步載入資料。我們不是一次性下載整個資料集,而是逐個樣本載入資料集。我們在迭代資料集時,動態地 載入和準備需要的樣本。這樣,我們只加載我們正在使用的樣本,而不是那些我們不用的!一旦我們處理完一個樣本,我們就繼續迭代資料集並載入下一個。
這類似於 下載 電視劇和 線上觀看 電視劇。當我們下載一部電視劇時,我們會將整個影片離線下載並儲存到我們的磁碟上。我們必須等待整個影片下載完成才能觀看,並且需要與影片檔案大小相當的磁碟空間。相比之下,線上觀看電視劇時,我們不會將影片的任何部分下載到磁碟,而是即時迭代遠端影片檔案,並按需載入每個部分。我們不必等待整個影片緩衝完畢才能開始觀看,只要影片的第一部分準備好了就可以開始!這就是我們應用於載入資料集的相同 流式處理 原則。

與一次性下載整個資料集相比,流式處理模式有三個主要優勢:
- 磁碟空間: 在我們迭代資料集時,樣本被逐個載入到記憶體中。由於資料沒有在本地下載,因此沒有磁碟空間要求,所以您可以使用任意大小的資料集。
- 下載和處理時間: 音訊資料集很大,需要大量時間來下載和處理。透過流式處理,載入和處理是動態進行的,這意味著您可以在第一個樣本準備好後立即開始使用資料集。
- 便於實驗: 您可以在少數樣本上進行實驗,以檢查您的指令碼是否正常工作,而無需下載整個資料集。
流式處理模式有一個需要注意的地方。在下載資料集時,原始資料和處理後的資料都儲存在本地磁碟上。如果我們想重用這個資料集,我們可以直接從磁碟載入處理後的資料,跳過下載和處理步驟。因此,我們只需要執行一次下載和處理操作,之後就可以重用準備好的資料。而在流式處理模式下,資料不會下載到磁碟。因此,下載的資料和預處理的資料都不會被快取。如果我們想重用資料集,必須重複流式處理步驟,再次動態載入和處理音訊檔案。因此,建議下載您可能多次使用的資料集。
如何啟用流式處理模式?很簡單!只需在載入資料集時設定 streaming=True。剩下的事情都會為您處理好。
gigaspeech = load_dataset("speechcolab/gigaspeech", "xs", streaming=True)
本教程中到目前為止涵蓋的所有步驟都可以應用於流式處理的資料集,無需任何程式碼更改。唯一的變化是您不能再使用 Python 索引訪問單個樣本 (即 gigaspeech["train"][sample_idx])。相反,您必須迭代資料集,例如使用 for 迴圈。
流式處理模式可以將您的研究提升到一個新的水平:不僅最大的資料集對您來說觸手可及,而且您可以輕鬆地在一個指令碼中評估多個數據集上的系統,而無需擔心您的磁碟空間。與在單個數據集上進行評估相比,多資料集評估為語音識別系統的泛化能力提供了更好的衡量標準 (c.f. 端到端語音基準 (ESB))。附帶的 Google Colab 提供了一個示例,演示如何在一個指令碼中使用流式處理模式在八個英語語音識別資料集上評估 Whisper 模型。
Hub 上的音訊資料集概覽
本節為 Hugging Face Hub 上最流行的語音識別、語音翻譯和音訊分類資料集提供參考指南。我們可以將針對 GigaSpeech 資料集所涵蓋的所有內容應用於 Hub 上的任何資料集。我們所要做的就是在 load_dataset 函式中切換資料集識別符號。就這麼簡單!
英語語音識別
語音識別,或語音轉文字,是將口語語音對映到書面文字的任務,其中語音和文字都使用同一種語言。我們總結了 Hub 上最受歡迎的英語語音識別資料集。
| 資料集 | 領域 | 說話風格 | 訓練時長 | 大小寫 | 標點符號 | 許可證 | 推薦用途 |
|---|---|---|---|---|---|---|---|
| LibriSpeech | 有聲讀物 | 朗讀 | 960 | ❌ | ❌ | CC-BY-4.0 | 學術基準測試 |
| Common Voice 11 | 維基百科 | 朗讀 | 2300 | ✅ | ✅ | CC0-1.0 | 非母語使用者 |
| VoxPopuli | 歐洲議會 | 演說 | 540 | ❌ | ✅ | CC0 | 非母語使用者 |
| TED-LIUM | TED 演講 | 演說 | 450 | ❌ | ❌ | CC-BY-NC-ND 3.0 | 技術主題 |
| GigaSpeech | 有聲讀物、播客、YouTube | 朗讀、自發 | 10000 | ❌ | ✅ | apache-2.0 | 跨領域的魯棒性 |
| SPGISpeech | 財經會議 | 演說、自發 | 5000 | ✅ | ✅ | 使用者協議 | 完全格式化的轉錄文字 |
| Earnings-22 | 財經會議 | 演說、自發 | 119 | ✅ | ✅ | CC-BY-SA-4.0 | 口音多樣性 |
| AMI | 會議 | 自發 | 100 | ✅ | ✅ | CC-BY-4.0 | 嘈雜語音環境 |
請參考 Google Colab,瞭解如何在一個指令碼中對所有八個英語語音識別資料集進行系統評估的指南。
以下資料集描述主要摘自 ESB 基準 論文。
LibriSpeech ASR
LibriSpeech 是一個用於評估 ASR 系統的標準大型資料集。它包含大約 1,000 小時從 LibriVox 專案收集的有聲讀物朗讀音訊。LibriSpeech 在促進研究人員利用大量已有的轉錄語音資料方面發揮了重要作用。因此,它已成為對學術語音系統進行基準測試最受歡迎的資料集之一。
librispeech = load_dataset("librispeech_asr", "all")
Common Voice
Common Voice 是一系列眾包的開放許可語音資料集,說話者用各種語言錄製來自維基百科的文字。由於任何人都可以貢獻錄音,因此在音訊質量和說話者方面存在顯著差異。音訊條件具有挑戰性,存在錄音偽影、帶口音的語音、猶豫以及外來詞的存在。轉錄文字既有大小寫也有標點符號。11.0 版本的英文子集包含大約 2,300 小時的驗證資料。使用該資料集需要您同意 Common Voice 的使用條款,這些條款可以在 Hugging Face Hub 上找到:mozilla-foundation/common_voice_11_0。一旦您同意了使用條款,您將被授予訪問資料集的許可權。然後,您在載入資料集時需要提供來自 Hub 的身份驗證令牌。
common_voice = load_dataset("mozilla-foundation/common_voice_11", "en", use_auth_token=True)
VoxPopuli
VoxPopuli 是一個大規模多語言語音語料庫,由 2009-2020 年歐洲議會活動錄音資料組成。因此,它佔據了演講和政治言論這一獨特的領域,且主要來源於非母語使用者。其英語子集包含約 550 小時的標註語音。
voxpopuli = load_dataset("facebook/voxpopuli", "en")
TED-LIUM
TED-LIUM 是一個基於英語 TED 演講影片的資料集。其說話風格為演講式教育講座。轉錄的演講涵蓋了文化、政治和學術等一系列不同主題,因此包含了大量技術詞彙。第 3 版(最新版)資料集包含約 450 小時的訓練資料。驗證和測試資料來自舊版資料集,與早期版本保持一致。
tedlium = load_dataset("LIUM/tedlium", "release3")
GigaSpeech
GigaSpeech 是一個多領域英語語音識別語料庫,精選自於有聲讀物、播客和 YouTube。它涵蓋了敘述性和自發性演講,主題多樣,如藝術、科學和體育。它包含從 10 小時到 10,000 小時不等的訓練集劃分,以及標準化的驗證和測試集劃分。
gigaspeech = load_dataset("speechcolab/gigaspeech", "xs", use_auth_token=True)
SPGISpeech
SPGISpeech 是一個英語語音識別語料庫,由 S&P Global 公司手動轉錄的公司財報電話會議錄音組成。轉錄文字根據專業的演講和自發性語音風格指南進行了完全格式化。它包含從 200 小時到 5,000 小時不等的訓練集劃分,並有規範的驗證和測試集劃分。
spgispeech = load_dataset("kensho/spgispeech", "s", use_auth_token=True)
Earnings-22
Earnings-22 是一個時長 119 小時的英語財報電話會議語料庫,收集自全球各大公司。該資料集的開發目標是彙集涵蓋真實世界金融主題的廣泛的說話者和口音。說話者和口音具有高度多樣性,說話者來自七個不同的語言區。Earnings-22 最初主要作為僅供測試的資料集釋出。Hub 上提供的資料集版本已被劃分為訓練-驗證-測試集。
earnings22 = load_dataset("revdotcom/earnings22")
AMI
AMI 包含 100 小時的會議錄音,使用不同的錄音流進行採集。該語料庫包含手動標註的會議正交轉錄文字,並在詞級別上對齊。AMI 資料集的單個樣本包含非常大的音訊檔案(10到60分鐘之間),這些檔案被分割成適合大多數語音識別系統訓練的長度。AMI 包含兩種劃分:IHM 和 SDM。IHM (individual headset microphone) 包含較容易的近場語音,而 SDM (single distant microphone) 包含較難的遠場語音。
ami = load_dataset("edinburghcstr/ami", "ihm")
多語言語音識別
多語言語音識別指除英語外的所有語言的語音識別(語音轉文字)。
Multilingual LibriSpeech
Multilingual LibriSpeech 是 LibriSpeech ASR 語料庫的多語言版本。它包含一個大型的朗讀有聲讀物語料庫,取自 LibriVox 專案,是適合學術研究的資料集。它包含八種高資源語言的資料劃分——英語、德語、荷蘭語、西班牙語、法語、義大利語、葡萄牙語和波蘭語。
Common Voice
Common Voice 是一系列眾包的開放許可語音資料集,說話者用各種語言錄製維基百科的文字。由於任何人都可以貢獻錄音,因此音訊質量和說話者都存在顯著差異。音訊條件具有挑戰性,存在錄音偽影、帶口音的語音、猶豫以及外來詞的出現。轉錄文字保留了大小寫和標點符號。截至第 11 版,該資料集已涵蓋超過 100 種語言,包括低資源和高資源語言。
VoxPopuli
VoxPopuli 是一個大規模多語言語音語料庫,由 2009-2020 年歐洲議會活動錄音資料組成。因此,它佔據了演講和政治言論這一獨特的領域,且主要來源於非母語使用者。它包含 15 種歐洲語言的標註音訊-轉錄資料。
FLEURS
FLEURS (Few-shot Learning Evaluation of Universal Representations of Speech) 是一個用於評估 102 種語言(包括許多被歸類為“低資源”的語言)語音識別系統的資料集。該資料來源自 FLoRes-101 資料集,這是一個機器翻譯語料庫,包含 3001 個從英語到 101 種其他語言的句子翻譯。母語使用者被錄製用其母語朗讀句子轉錄文字。錄製的音訊資料與句子轉錄文字配對,從而為所有 101 種語言生成多語言語音識別資料。訓練集每種語言包含約 10 小時的有監督音訊-轉錄資料。
語音翻譯
語音翻譯是將口頭語音對映到書面文字的任務,其中語音和文字使用不同的語言(例如,英語語音到法語文字)。
CoVoST 2
CoVoST 2 是一個大規模多語言語音翻譯語料庫,涵蓋從 21 種語言翻譯到英語以及從英語翻譯到 15 種語言。該資料集使用 Mozilla 的開源 Common Voice 眾包語音錄音資料庫建立。該語料庫共包含 2,900 小時的語音資料。
FLEURS
FLEURS (Few-shot Learning Evaluation of Universal Representations of Speech) 是一個用於評估 102 種語言(包括許多被歸類為“低資源”的語言)語音識別系統的資料集。該資料來源自 FLoRes-101 資料集,這是一個機器翻譯語料庫,包含 3001 個從英語到 101 種其他語言的句子翻譯。母語使用者被錄製用其母語朗讀句子轉錄文字。透過將錄製的音訊資料與 101 種語言中每一種的句子轉錄文字配對,構建了一個 路並行的語音翻譯資料語料庫。訓練集每個源-目標語言組合包含約 10 小時的有監督音訊-轉錄資料。
音訊分類
音訊分類是將原始音訊輸入對映到類別標籤輸出的任務。音訊分類的實際應用包括關鍵詞識別、說話人意圖識別和語種識別。
SpeechCommands
SpeechCommands 是一個由一秒長的音訊檔案組成的資料集,每個檔案包含一個英語口語單詞或背景噪音。這些單詞取自一小組命令,並由許多不同的說話者說出。該資料集旨在幫助訓練和評估小型裝置上的關鍵詞識別系統。
多語言口語詞彙
多語言口語詞彙是一個大規模語料庫,由一秒鐘的音訊樣本組成,每個樣本包含一個口語單詞。該資料集包含 50 種語言和超過 34 萬個關鍵詞,總計 2340 萬個一秒鐘的口語樣本,或超過 6000 小時的音訊。音訊-轉錄資料來自 Mozilla Common Voice 專案。為每個話語在詞級別上生成時間戳,並用於提取單個口語單詞及其相應的轉錄,從而形成一個新的單個口語單詞語料庫。該資料集的預期用途是多語言關鍵詞識別和口語術語搜尋領域的學術研究和商業應用。
FLEURS
FLEURS (Few-shot Learning Evaluation of Universal Representations of Speech) 是一個用於評估 102 種語言(包括許多被歸類為“低資源”的語言)語音識別系統的資料集。該資料來源自 FLoRes-101 資料集,這是一個機器翻譯語料庫,包含 3001 個從英語到 101 種其他語言的句子翻譯。母語使用者被錄製用其母語朗讀句子轉錄文字。錄製的音訊資料與所說語言的標籤配對。該資料集可用作語種識別的音訊分類資料集:訓練系統來預測語料庫中每個話語的語言。
結束語
在這篇博文中,我們探索了 Hugging Face Hub 並體驗了資料集預覽功能,這是一種在下載前試聽音訊資料集的有效方法。我們用一行 Python 程式碼載入了一個音訊資料集,並執行了一系列通用的預處理步驟,為機器學習模型做準備。總共只需要 13 行程式碼,依靠簡單的 Python 函式即可完成必要的操作。我們介紹了流式模式,這是一種動態載入和準備音訊資料樣本的方法。最後,我們總結了 Hub 上最受歡迎的語音識別、語音翻譯和音訊分類資料集。
讀完這篇部落格後,我們希望您會同意 🤗 Datasets 是下載和準備音訊資料集的首選之地。 🤗 Datasets 的成功離不開社群的努力。如果您想貢獻資料集,請參閱新增新資料集指南。
感謝以下為本博文做出貢獻的個人:Vaibhav Srivastav、Polina Kazakova、Patrick von Platen、Omar Sanseviero 和 Quentin Lhoest。







