使用 AutoNLP 和 Prodigy 進行主動學習


在機器學習的背景下,主動學習是一個迭代地新增標註資料、重新訓練模型並將其提供給終端使用者的過程。這是一個無休止的過程,需要人工互動來標註/建立資料。在本文中,我們將討論如何使用 AutoNLP 和 Prodigy 來構建一個主動學習流水線。
AutoNLP
AutoNLP 是 Hugging Face 建立的一個框架,可以幫助你幾乎無需任何編碼就在自己的資料集上構建最先進的深度學習模型。AutoNLP 建立在 Hugging Face 的 transformers、datasets、inference-api 和許多其他工具的堅實基礎上。
透過 AutoNLP,你可以在自己的自定義資料集上訓練最先進的 transformer 模型,對其進行微調(自動),並將其提供給終端使用者。所有使用 AutoNLP 訓練的模型都是最先進的,並且可用於生產環境。
在撰寫本文時,AutoNLP 支援的任務包括二元分類、迴歸、多類別分類、詞元分類(例如命名實體識別或詞性標註)、問答、摘要等。你可以在此處找到所有支援任務的列表。AutoNLP 支援英語、法語、德語、西班牙語、印地語、荷蘭語、瑞典語等多種語言。它還支援使用自定義分詞器的自定義模型(以防你的語言不被 AutoNLP 支援)。
Prodigy
Prodigy 是由 Explosion(spaCy 的創造者)開發的一款標註工具。它是一個基於網路的工具,可以讓你即時標註資料。Prodigy 支援自然語言處理(NLP)任務,如命名實體識別(NER)和文字分類,但它不僅限於 NLP!它還支援計算機視覺任務,甚至可以建立你自己的任務!你可以試用 Prodigy 的演示:此處。
請注意,Prodigy 是一個商業工具。你可以在此處瞭解更多資訊。
我們選擇 Prodigy 是因為它是一款非常流行的資料標註工具,並且可以無限定製。它的設定和使用也非常簡單。
資料集
現在開始本文最有趣的部分。在查看了大量資料集和不同型別的問題後,我們在 Kaggle 上偶然發現了 BBC 新聞分類資料集。該資料集曾用於一次課堂競賽,可以從此處獲取。
我們來看看這個資料集

我們可以看到這是一個分類資料集。其中有一個 Text 列,是新聞文章的文字,還有一個 Category 列,是文章的類別。總共有 5 個不同的類別:business(商業)、entertainment(娛樂)、politics(政治)、sport(體育)和 tech(科技)。
使用 AutoNLP 在這個資料集上訓練一個多類別分類模型簡直是小菜一碟。
步驟 1:下載資料集。
步驟 2:開啟 AutoNLP 並建立一個新專案。
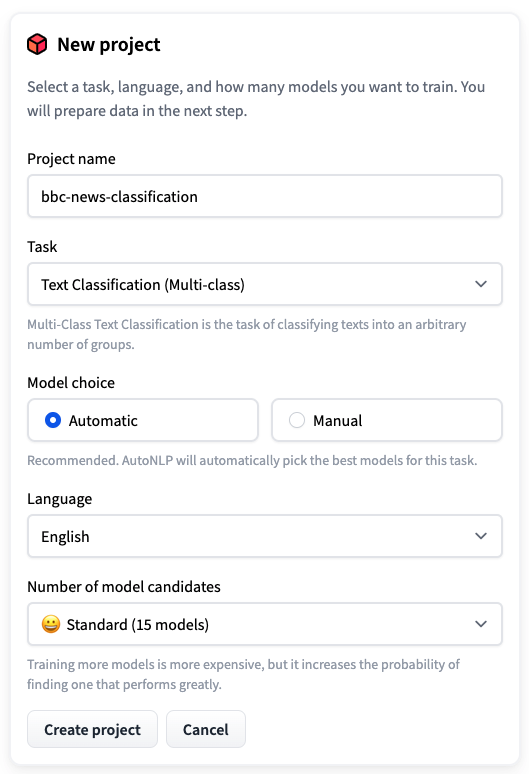
步驟 3:上傳訓練資料集並選擇自動拆分。
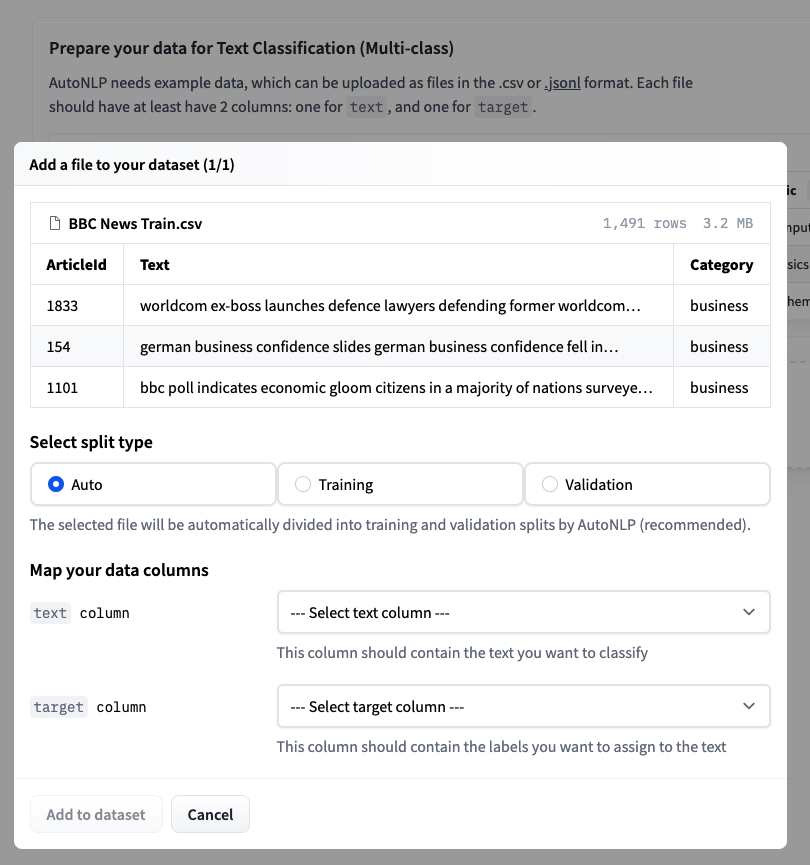
步驟 4:接受定價並訓練模型。
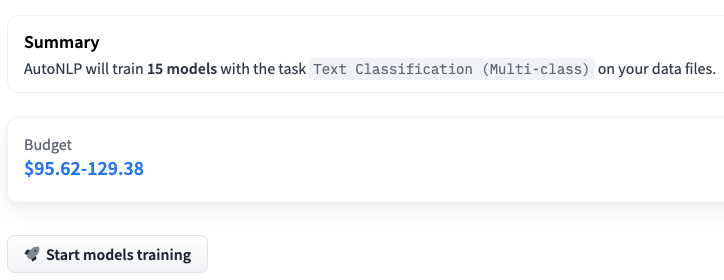
請注意,在上面的例子中,我們正在訓練 15 個不同的多類別分類模型。AutoNLP 的定價可以低至每個模型 10 美元。AutoNLP 會自動為你選擇最佳模型並進行超引數調優。所以,現在我們只需要坐下來,放鬆,等待結果。
大約 15 分鐘後,所有模型都完成了訓練,結果已經準備好了。看起來最好的模型獲得了 98.67% 的準確率!
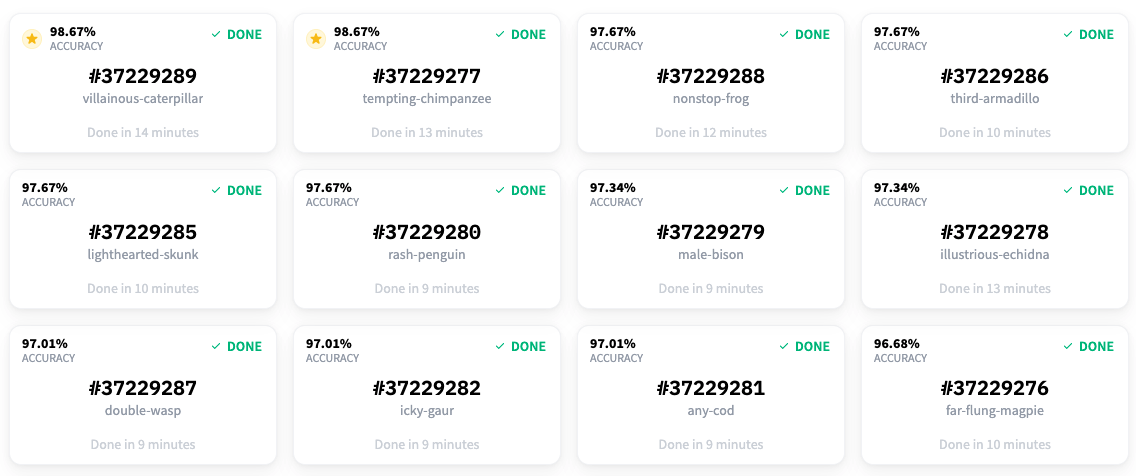
所以,我們現在能夠以 98.67% 的準確率對資料集中的文章進行分類!但是等等,我們之前談論的是主動學習和 Prodigy。它們去哪兒了?🤔 我們確實使用了 Prodigy,我們很快就會看到。我們用它來為這個資料集進行命名實體識別任務的標註。在開始標註部分之前,我們覺得如果能有一個專案,不僅能檢測新聞文章中的實體,還能對它們進行分類,那就太酷了。這就是為什麼我們基於現有的標籤構建了這個分類模型。
主動學習
我們使用的資料集確實有類別,但沒有實體識別的標籤。因此,我們決定使用 Prodigy 為另一個任務標註資料集:命名實體識別。
一旦你安裝了 Prodigy,你只需執行
$ prodigy ner.manual bbc blank:en BBC_News_Train.csv --label PERSON,ORG,PRODUCT,LOCATION
我們來看看這些不同的值
bbc是將由 Prodigy 建立的資料集。blank:en是正在使用的spaCy分詞器。BBC_News_Train.csv是將用於標註的資料集。PERSON,ORG,PRODUCT,LOCATION是將用於標註的標籤列表。
執行上述命令後,你可以訪問 prodigy 的網頁介面(通常在 localhost:8080)並開始標註資料集。Prodigy 的介面非常簡單、直觀且易於使用。介面如下所示
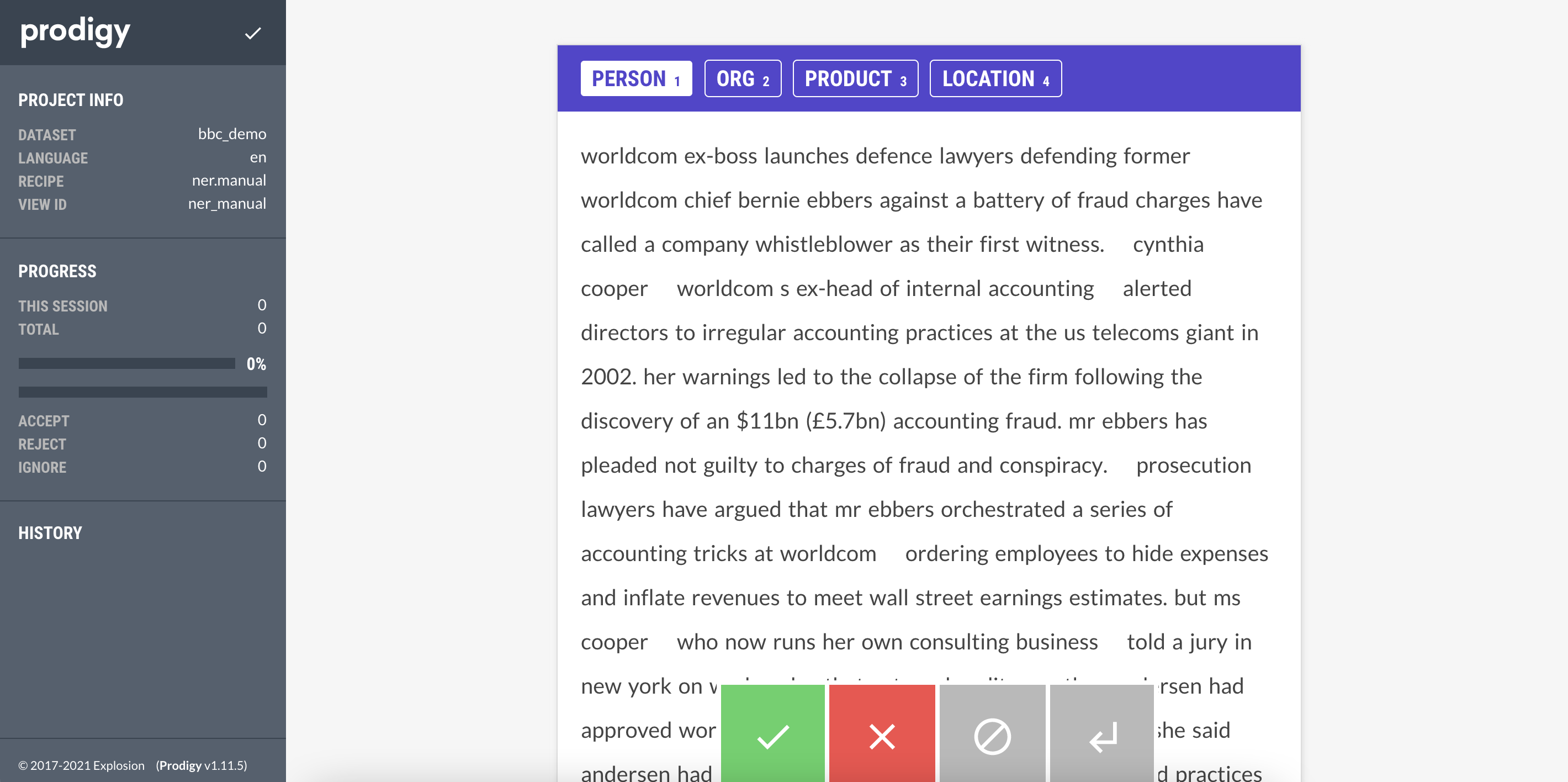
你所要做的就是選擇要標註的實體(PERSON, ORG, PRODUCT, LOCATION),然後選擇屬於該實體的文字。完成一個文件後,你可以點選綠色按鈕,Prodigy 會自動為你提供下一個未標註的文件。
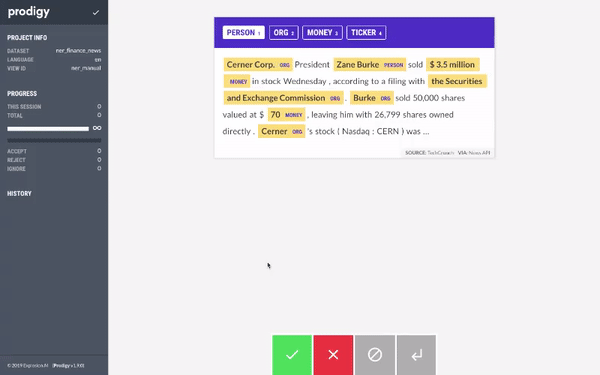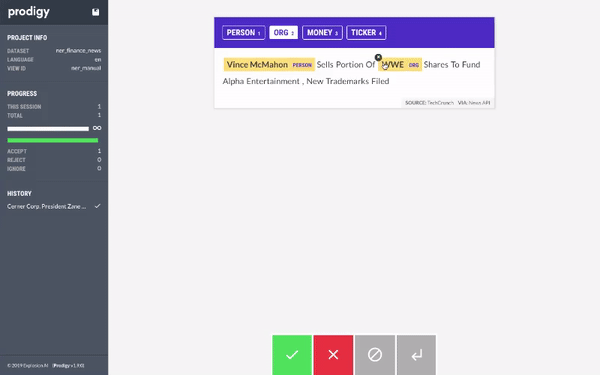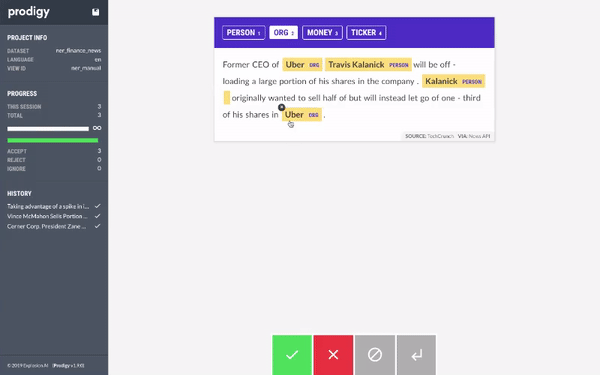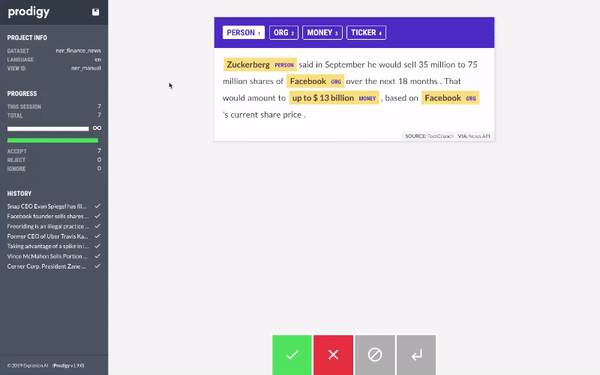
我們開始使用 Prodigy 標註資料集。當我們有大約 20 個樣本時,我們使用 AutoNLP 訓練了一個模型。Prodigy 不會以 AutoNLP 格式匯出資料,所以我們寫了一個快速簡陋的指令碼將資料轉換為 AutoNLP 格式
import json
import spacy
from prodigy.components.db import connect
db = connect()
prodigy_annotations = db.get_dataset("bbc")
examples = ((eg["text"], eg) for eg in prodigy_annotations)
nlp = spacy.blank("en")
dataset = []
for doc, eg in nlp.pipe(examples, as_tuples=True):
try:
doc.ents = [doc.char_span(s["start"], s["end"], s["label"]) for s in eg["spans"]]
iob_tags = [f"{t.ent_iob_}-{t.ent_type_}" if t.ent_iob_ else "O" for t in doc]
iob_tags = [t.strip("-") for t in iob_tags]
tokens = [str(t) for t in doc]
temp_data = {
"tokens": tokens,
"tags": iob_tags
}
dataset.append(temp_data)
except:
pass
with open('data.jsonl', 'w') as outfile:
for entry in dataset:
json.dump(entry, outfile)
outfile.write('\n')
這將為我們提供一個 JSONL 檔案,可以用於使用 AutoNLP 訓練模型。步驟將與之前相同,只是在建立 AutoNLP 專案時我們將選擇 Token Classification(詞元分類)任務。使用我們最初的資料,我們用 AutoNLP 訓練了一個模型。最好的模型準確率約為 86%,但精確率和召回率為 0。我們知道模型什麼都沒學到。這很明顯,因為我們只有大約 20 個樣本。
在標註了大約 70 個樣本後,我們開始看到一些結果。準確率上升到 92%,精確率為 0.52,召回率約為 0.42。我們取得了一些結果,但仍然不盡如人意。在下圖中,我們可以看到這個模型在一個未見過的樣本上的表現。
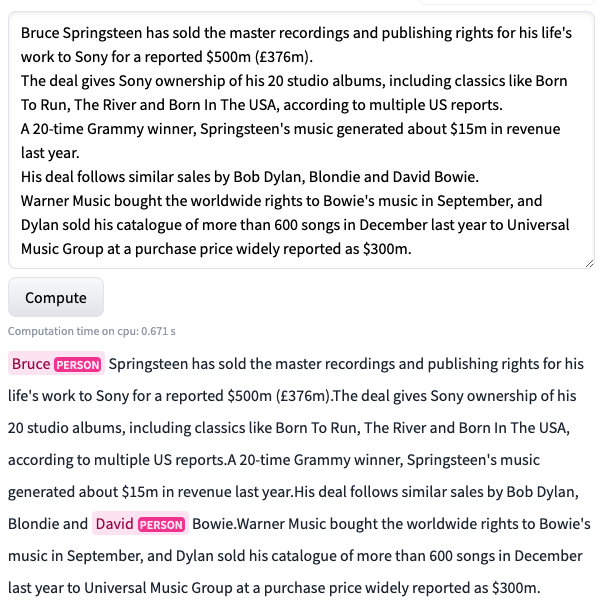
正如你所看到的,模型表現得還很吃力。但這比以前好多了!之前,模型甚至無法在相同的文字中預測出任何東西。至少現在,它能夠識別出 Bruce 和 David 是人名。
因此,我們繼續努力。我們又標註了一些樣本。
請注意,在每次迭代中,我們的資料集都在變大。我們所做的只是將新的資料集上傳到 AutoNLP,讓它完成剩下的工作。
在標註了大約 150 個樣本後,我們開始得到一些不錯的結果。準確率上升到 95.7%,精確率為 0.64,召回率約為 0.76。
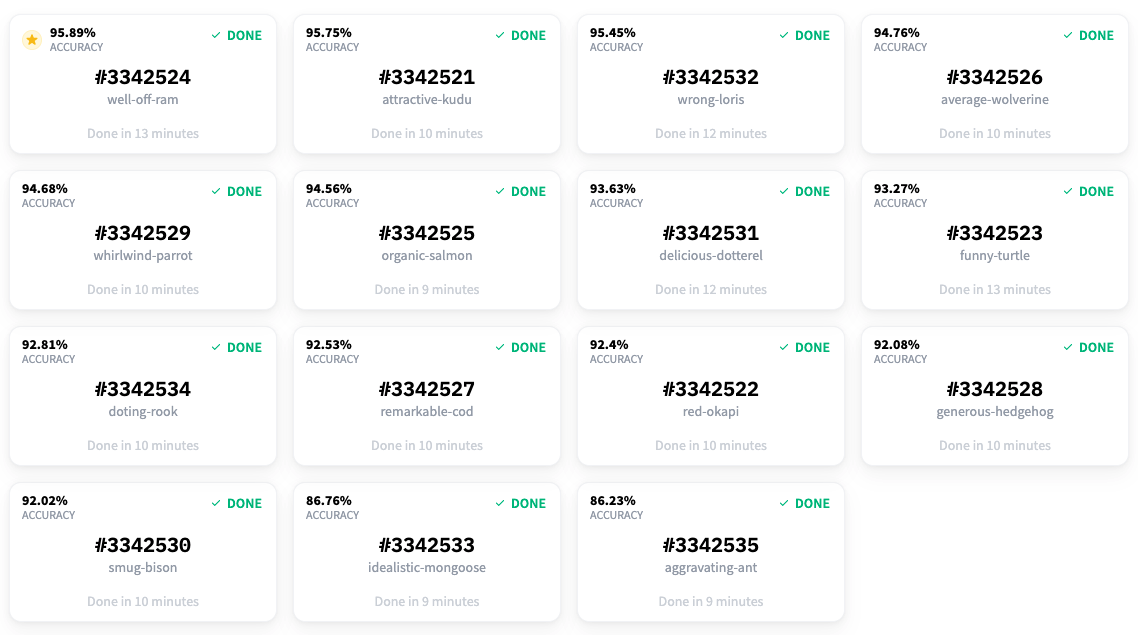
讓我們看看這個模型在同一個未見過的樣本上的表現如何。
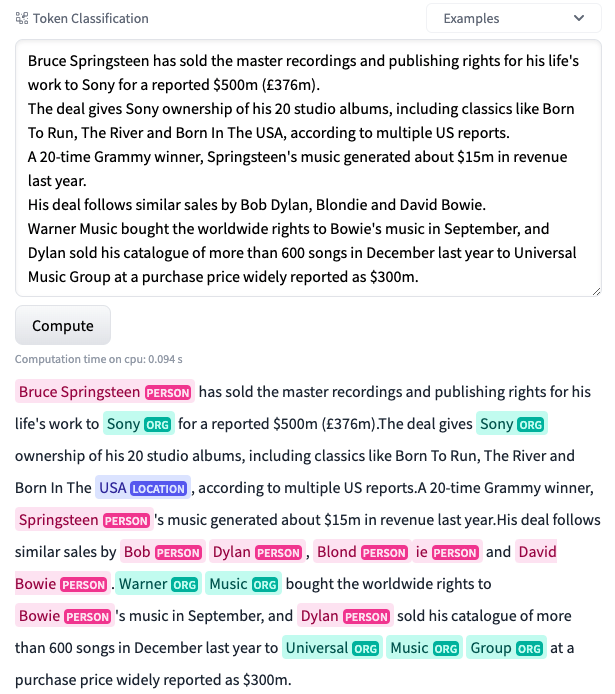
哇!這太棒了!正如你所看到的,模型現在的表現非常出色!它能夠檢測出同一文字中的許多實體。精確率和召回率仍然有點低,因此我們繼續標註更多資料。在標註了大約 250 個樣本後,我們在精確率和召回率方面取得了最好的結果。準確率上升到約 95.9%,精確率和召回率分別為 0.73 和 0.79。此時,我們決定停止標註並結束實驗過程。下圖顯示了隨著我們向資料集中新增更多樣本,最佳模型的準確率是如何提高的
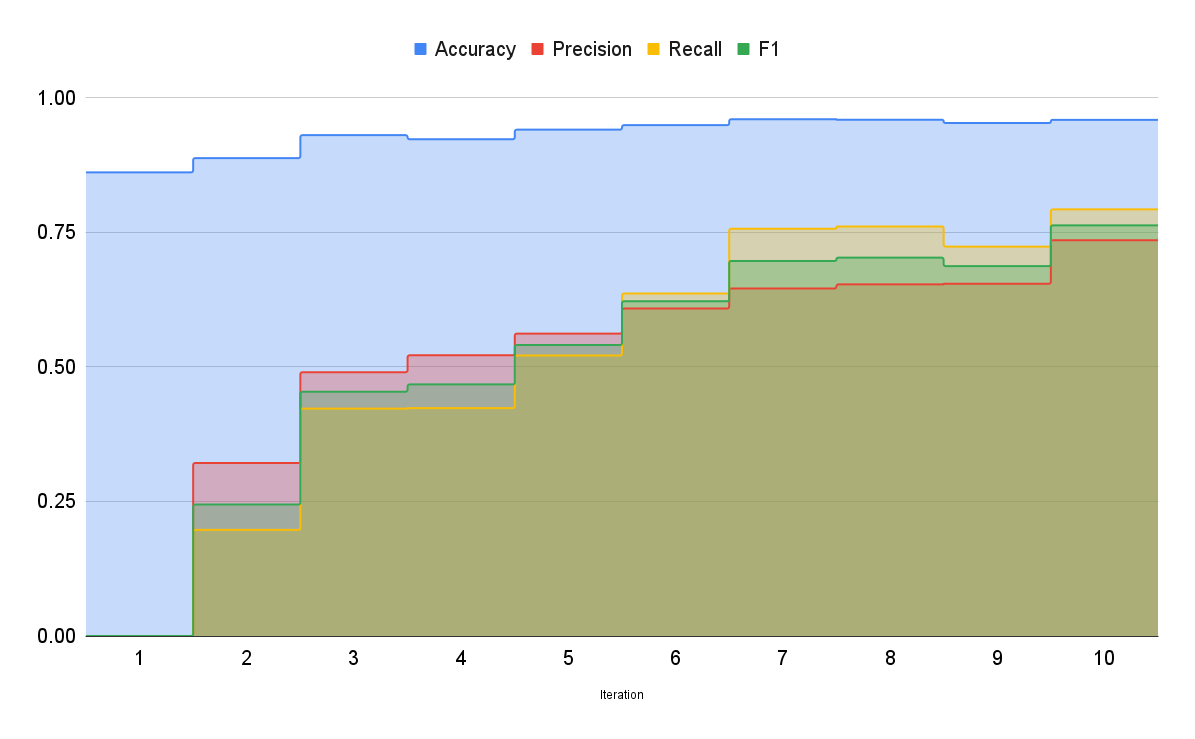
眾所周知,更多相關資料會帶來更好的模型,從而產生更好的結果。透過這次實驗,我們成功建立了一個不僅可以對新聞文章中的實體進行分類,還可以對其進行歸類的模型。使用 Prodigy 和 AutoNLP 這樣的工具,我們只投入時間和精力來標註資料集(而 Prodigy 提供的介面甚至使這個過程變得更簡單)。AutoNLP 為我們節省了大量的時間和精力:我們不必去弄清楚該使用哪些模型、如何訓練它們、如何評估它們、如何調整引數、使用哪種最佳化器和排程器、預處理、後處理等等。我們只需要標註資料集,讓 AutoNLP 完成其他所有工作。
我們相信,藉助 AutoNLP 和 Prodigy 這樣的工具,建立資料和最先進的模型變得非常容易。而且由於整個過程幾乎不需要任何編碼,即使沒有編碼背景的人也可以建立通常不對公眾開放的資料集,使用 AutoNLP 訓練自己的模型,並與社群中的其他人分享模型(或者僅僅用於他們自己的研究/業務)。
我們已經開源了使用此過程建立的最佳模型。你可以在此處嘗試。標註好的資料集也可以在此處下載。
模型之所以能達到最先進水平,完全歸功於它們所訓練的資料。

