在現代CPU上擴充套件BERT類模型推理——第一部分




1. 背景與動機
早在2019年10月,我的同事Lysandre Debut釋出了一篇全面的(當時)推理效能基準測試部落格 (1)。
自那時起,🤗 Transformers (2) 迎來了大量新架構,數千個新模型被新增到 🤗 Hub (3),截至2021年第一季度,模型數量已超過9,000個。
隨著NLP領域越來越多地使用BERT類模型進行生產部署,高效地部署和執行這些架構仍然充滿挑戰。
這就是我們最近推出🤗 推理API的原因:讓您專注於為使用者和客戶創造價值,而不是深究執行這些模型的所有高度技術性細節。
這篇部落格文章是系列文章的第一部分,將涵蓋大部分硬體和軟體最佳化,以更好地利用CPU進行BERT模型推理。
在這篇初始部落格文章中,我們將涵蓋硬體部分:
- 設定基線——開箱即用結果
- 利用現代CPU處理CPU密集型任務時的實際和技術考量
- 核心數擴充套件——增加核心數是否真的能帶來更好的效能?
- 批次大小擴充套件——透過多個並行獨立模型例項提高吞吐量
我們決定專注於最著名的Transformer模型架構,BERT (Delvin & al. 2018) (4)。雖然本部落格文章主要關注BERT類模型以保持文章簡潔,但所有描述的技術都適用於Hugging Face模型中心上的任何架構。
在這篇部落格文章中,我們不會詳細描述Transformer架構——如果您想了解這方面的內容,我強烈推薦Jay Alammar的《圖解Transformer》部落格文章 (5)。
今天的目標是讓您瞭解從開源角度來看,在PyTorch和TensorFlow上使用BERT類模型進行推理的現狀,以及您可以輕鬆利用哪些方法來加速推理。
2. 基準測試方法
當涉及到利用Hugging Face模型中心的BERT類模型時,有許多引數可以調整以加快速度。
此外,為了量化“更快”的含義,我們將依賴廣泛採用的指標:
- 延遲:模型單次執行(即前向呼叫)所需的時間
- 吞吐量:在固定時間內執行的次數
這兩個指標將幫助我們理解這篇部落格文章中討論的優點和權衡。
基準測試方法已從頭開始重新實現,以便整合transformers提供的最新功能,並讓社群以**希望能更簡單的方式**執行和共享基準測試。
整個框架現在基於Facebook AI & Research的Hydra配置庫,使我們能夠輕鬆報告和跟蹤執行基準測試所涉及的所有專案,從而提高整體可復現性。
您可以在此處找到專案的整體結構
在2021年版本中,我們保留了透過PyTorch和TensorFlow執行推理工作負載的能力,就像之前的部落格(1)中那樣,同時支援它們的追蹤對應物TorchScript (6)和Google加速線性代數 (XLA) (7)。
此外,我們決定支援ONNX Runtime (8),因為它提供了許多專門針對基於Transformer模型的最佳化,這使其成為在討論效能時需要考慮的強有力候選。
最後但同樣重要的是,這個新的統一基準測試環境將允許我們輕鬆地執行不同場景下的推理,例如使用精度較低的數字表示(float16, int8, int4)的量化模型 (Zafrir & al.) (9)。
這種被稱為**量化**的方法在所有主要硬體供應商中得到了越來越多的採用。在不久的將來,我們希望整合Hugging Face正在積極研究的其他方法,即蒸餾、剪枝和稀疏化。
3. 基線
以下所有結果均在Amazon Web Services (AWS) c5.metal 例項上執行,該例項使用Intel Xeon Platinum 8275 CPU(48核心/96執行緒)。選擇此例項可提供所有有用的CPU功能,以加速深度學習工作負載,例如:
- AVX512指令集(可能不會被各種框架開箱即用)
- Intel深度學習加速(也稱為向量神經網路指令——VNNI),它為執行量化網路(使用int8資料型別)提供專用CPU指令
選擇使用metal例項是為了避免使用雲提供商時可能出現的任何虛擬化問題。這使我們能夠完全控制硬體,特別是在針對NUMA(非統一記憶體訪問架構)控制器時,我們將在本文後面介紹這一點。
作業系統是Ubuntu 20.04 (LTS),所有實驗均使用Hugging Face transformers 4.5.0版本、PyTorch 1.8.1和Google TensorFlow 2.4.0進行。
4. 開箱即用結果


直截了當地說,在所有測試配置中,PyTorch 在推理結果上均優於 TensorFlow。
需要注意的是,開箱即用的結果可能無法反映 PyTorch 和 TensorFlow 的“最優”設定,因此此處看起來可能具有誤導性。
解釋這兩種框架之間差異的一種可能方式是執行運算子內部並行部分的底層技術。
PyTorch內部使用OpenMP (10)以及Intel MKL (現在是oneDNN) (11)進行高效的線性代數計算,而TensorFlow則依賴於Eigen和其自己的執行緒實現。
5. 擴充套件BERT推理以提高現代CPU的整體吞吐量
5.1. 簡介
有多種方法可以提高BERT推理等任務的延遲和吞吐量。改進和調整可以在各個層面進行,從啟用作業系統功能、將依賴庫替換為效能更好的庫、仔細調整框架屬性,到最後但同樣重要的是,利用CPU上的所有核心進行並行化邏輯。
在這篇部落格文章的剩餘部分,我們將專注於後者,也稱為**多推理流**。
這個想法很簡單:分配**同一個模型的多個例項**,並將每個例項的執行分配給**專門的、不重疊的CPU核心子集**,以實現真正的並行例項。
5.2. 現代CPU上的核心和執行緒
在最佳化CPU推理以更好地利用CPU核心的過程中,您可能已經看到——至少在過去20年中——現代CPU規格報告“核心”和“硬體執行緒”或“物理”和“邏輯”數字。這些概念指的是一種稱為**同步多執行緒**(SMT)或英特爾平臺上的**超執行緒**機制。
為了說明這一點,假設有兩個任務**A**和**B**並行執行,每個任務都在自己的軟體執行緒上。
在某個時候,這兩個任務很有可能不得不等待從主記憶體、SSD、HDD甚至網路中獲取一些資源。
如果執行緒排程在不同的物理核心上,並且沒有超執行緒,那麼在這些期間,執行任務的核心處於**空閒**狀態,等待資源到來,實際上什麼也沒做......因此沒有得到充分利用
現在,有了**SMT**,**任務A和B的兩個軟體執行緒**可以被排程在同一個**物理核心**上,這樣它們的執行就在該物理核心上交錯進行。
任務A和任務B將在物理核心上同時執行,當一個任務暫停時,另一個任務仍然可以在核心上繼續執行,從而提高該核心的利用率。
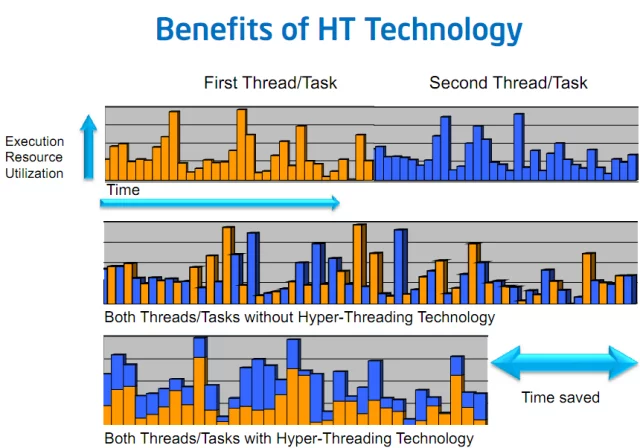
上圖 3 簡化了情況,假設是單核設定。如果您想了解更多關於 SMT 在多核 CPU 上如何工作的詳細資訊,請參閱以下兩篇對該行為進行非常深入技術解釋的文章:
回到我們的模型推理工作負載……如果你仔細思考,在一個完美最佳化的世界裡,計算佔據了大部分時間。
在這種情況下,使用邏輯核心不應該給我們帶來任何效能優勢,因為兩個邏輯核心(硬體執行緒)都會爭奪核心的執行資源。
結果,這些任務主要是通用矩陣乘法(gemms (14)),它們本質上是CPU密集型任務,因此**無法**從SMT中受益。
5.3. 利用多插槽伺服器和CPU親和性
如今的伺服器擁有許多核心,其中一些甚至支援多插槽設定(即主機板上有多個CPU)。
在Linux上,lscpu命令報告系統中所有CPU的規格和拓撲結構
ubuntu@some-ec2-machine:~$ lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 96
On-line CPU(s) list: 0-95
Thread(s) per core: 2
Core(s) per socket: 24
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Platinum 8275CL CPU @ 3.00GHz
Stepping: 7
CPU MHz: 1200.577
CPU max MHz: 3900.0000
CPU min MHz: 1200.0000
BogoMIPS: 6000.00
Virtualization: VT-x
L1d cache: 1.5 MiB
L1i cache: 1.5 MiB
L2 cache: 48 MiB
L3 cache: 71.5 MiB
NUMA node0 CPU(s): 0-23,48-71
NUMA node1 CPU(s): 24-47,72-95
在我們的例子中,我們有一臺機器,它有**2個插槽**,每個插槽提供**24個物理核心**,每個核心有**2個執行緒**(SMT)。
另一個有趣的特性是**NUMA**節點(0, 1)的概念,它表示核心和記憶體如何在系統中對映。
非統一記憶體訪問 (NUMA) 是統一記憶體訪問 (UMA) 的對立面,在 UMA 中,整個記憶體池透過插槽和主記憶體之間的一條單一統一匯流排供所有核心訪問。而 NUMA 則將記憶體池分割,每個 CPU 插槽負責定址一部分記憶體,從而減少總線上的擁堵。
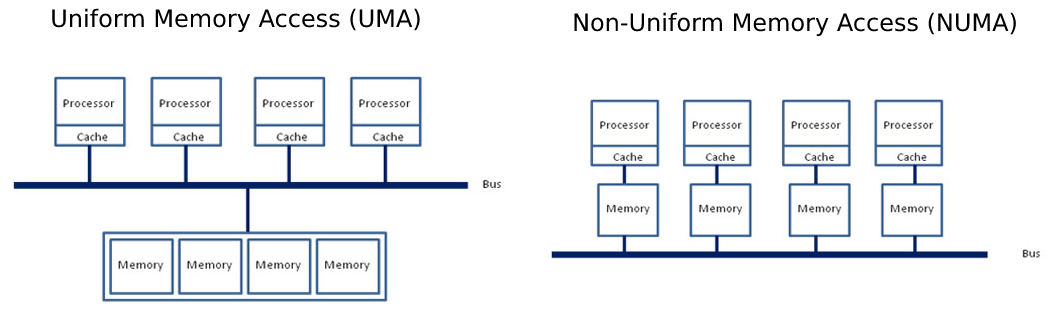
為了充分利用這種強大機器的潛力,我們需要確保我們的模型例項正確地分配到所有插槽上的所有**物理**核心,並強制記憶體分配“NUMA感知”。
在 Linux 中,NUMA 的程序配置可以透過 numactl 進行調整,它提供了一個介面來將程序繫結到一組 CPU 核心(稱為**執行緒親和性**)。
此外,它還允許調整記憶體分配策略,確保為程序分配的記憶體儘可能靠近核心的記憶體池(稱為**顯式記憶體分配指令**)。
注意:設定核心和記憶體親和性在這裡都很重要。如果計算在插槽0上進行,而記憶體分配在插槽1上,系統將需要透過插槽共享匯流排進行記憶體交換,從而導致不必要的開銷。
5.4. 調整執行緒親和性與記憶體分配策略
現在我們已經掌握了控制模型例項資源分配所需的所有引數,我們將進一步探討如何有效地部署它們,並觀察其對延遲和吞吐量的影響。
讓我們逐步進行,以瞭解每個命令和引數的影響。
首先,我們不進行任何調整就啟動推理模型,並觀察計算如何在CPU核心上分配(左側)。
python3 src/main.py model=bert-base-cased backend.name=pytorch batch_size=1 sequence_length=128
然後,我們透過 numactl 指定核心和記憶體親和性,使用所有**物理**核心,每個核心只使用一個執行緒(執行緒0)(右側)。
numactl -C 0-47 -m 0,1 python3 src/main.py model=bert-base-cased backend.name=pytorch batch_size=1 sequence_length=128

如您所見,在沒有任何特定調整的情況下,PyTorch和TensorFlow將工作分配到單個插槽上,使用該插槽中的所有邏輯核心(24個核心上的兩個執行緒)。
此外,正如我們前面強調的,在我們的例子中,我們不希望利用**SMT**功能,因此我們將程序的執行緒親和性設定為僅 targeting 1 個硬體執行緒。
請注意,這僅適用於本次執行,並且可能因個人設定而異。因此,建議針對每個具體用例檢查執行緒親和性設定。
讓我們花點時間來強調一下我們用 numactl 做了什麼
-C 0-47指示numactl執行緒親和性(核心 0 到 47)。-m 0,1指示numactl在兩個CPU插槽上分配記憶體
如果您想知道我們為什麼要將程序繫結到核心 [0...47],您需要回到 lscpu 的輸出。
從那裡您會找到 NUMA node0 和 NUMA node1 部分,其形式為 NUMA node<X> <logical ids>
在我們的例子中,每個插槽是一個NUMA節點,共有2個NUMA節點。每個插槽或每個NUMA節點有24個物理核心,每個核心有2個硬體執行緒,因此有48個邏輯核心。對於NUMA節點0,0-23是插槽0中24個物理核心上的硬體執行緒0,24-47是硬體執行緒1。同樣,對於NUMA節點1,48-71是插槽1中24個物理核心上的硬體執行緒0,72-95是硬體執行緒1。
正如我們前面解釋的,由於我們每個物理核心只針對1個執行緒,因此我們只選擇每個核心上的執行緒0,即邏輯處理器0-47。由於我們使用兩個插槽,因此還需要相應地繫結記憶體分配(0,1)。
請注意,使用兩個插槽可能並非總是能獲得最佳結果,特別是對於小問題規模。跨插槽使用計算資源的優勢可能會因跨插槽通訊開銷而降低甚至抵消。
6. 核心數擴充套件——使用更多核心是否真的能提高效能?
當考慮提高模型推理效能的可能方法時,第一個合理的解決方案可能是投入更多資源來完成相同的工作量。
在本部落格系列的其餘部分,我們將把這種設定稱為**核心數擴充套件**,這意味著只有用於完成任務的系統核心數會發生變化。這在HPC領域通常也稱為強擴充套件。
在此階段,您可能想知道為什麼要僅分配部分核心,而不是將所有資源都投入到任務中以實現最小延遲。
確實,根據問題規模,投入更多資源到任務中可能會帶來更好的結果。對於小問題,投入更多CPU核心工作也可能不會改善最終延遲。
為了說明這一點,下面的圖6展示了不同的問題大小(batch_size = 1, sequence length = {32, 128, 512}),並報告了PyTorch和TensorFlow在不同CPU核心數下執行計算的延遲。
限制參與計算的資源數量是透過限制參與**內部**操作(這裡的**內部**指的是運算子內部進行計算,也稱為“核心”)的CPU核心數量來實現的。
這可以透過以下API實現:
- PyTorch:
torch.set_num_threads(x) - TensorFlow:
tf.config.threading.set_intra_op_parallelism_threads(x)

如您所見,根據問題規模,參與計算的執行緒數對延遲測量有積極影響。
對於小規模和中等規模問題,只使用一個插槽將提供最佳效能。對於大規模問題,跨插槽通訊的開銷被計算成本所覆蓋,因此受益於使用兩個插槽上的所有可用核心。
7. 多流推理——並行使用多個例項
如果您仍在閱讀本文,那麼您現在應該能夠很好地在 CPU 上設定並行推理工作負載了。
現在,我們將強調我們強大硬體提供的一些可能性,並透過調整之前描述的旋鈕,儘可能線性地擴充套件我們的推理。
在下一節中,我們將探討另一種可能的擴充套件解決方案**批次大小擴充套件**,但在深入探討之前,讓我們看看如何利用Linux工具來分配執行緒親和性,從而實現有效的模型例項並行化。
與核心計數擴充套件設定中增加更多核心不同,現在我們將使用更多模型例項。每個例項將在其自己的硬體資源子集上獨立執行,以真正的並行方式在CPU核心的子集上執行。
7.1. 如何分配多個獨立例項
我們從簡單的開始,如果我們想在每個插槽上生成2個例項,每個例項分配24個核心:
numactl -C 0-23 -m 0 python3 src/main.py model=bert-base-cased batch_size=1 sequence_length=128 backend.name=pytorch backend.num_threads=24
numactl -C 24-47 -m 1 python3 src/main.py model=bert-base-cased batch_size=1 sequence_length=128 backend.name=pytorch backend.num_threads=24
從這裡開始,每個例項不與其他例項共享任何資源,並且從硬體角度來看,一切都以最高效率執行。
延遲測量與單個例項所能達到的結果相同,但吞吐量實際上高出2倍,因為這兩個例項以真正的並行方式執行。
我們可以進一步增加例項數量,同時降低分配給每個例項的核心數量。
讓我們執行4個獨立例項,每個例項都有效地繫結到12個CPU核心。
numactl -C 0-11 -m 0 python3 src/main.py model=bert-base-cased batch_size=1 sequence_length=128 backend.name=pytorch backend.num_threads=12
numactl -C 12-23 -m 0 python3 src/main.py model=bert-base-cased batch_size=1 sequence_length=128 backend.name=pytorch backend.num_threads=12
numactl -C 24-35 -m 1 python3 src/main.py model=bert-base-cased batch_size=1 sequence_length=128 backend.name=pytorch backend.num_threads=12
numactl -C 36-47 -m 1 python3 src/main.py model=bert-base-cased batch_size=1 sequence_length=128 backend.name=pytorch backend.num_threads=12
結果保持不變,我們的4個例項有效地以真正的並行方式執行。
延遲會比上一個例子略高(使用的核心數減少2倍),但吞吐量將再次提高2倍。
7.2. 智慧排程——為不同問題大小分配不同的模型例項
這種設定提供的另一種可能性是為各種問題大小精心調整多個例項。
透過智慧排程方法,可以根據請求工作負載將傳入請求重定向到提供最佳延遲的正確配置。
# Small-sized problems (sequence length <= 32) use only 8 cores (on socket 0 - 8/24 cores used)
numactl -C 0-7 -m 0 python3 src/main.py model=bert-base-cased batch_size=1 sequence_length=32 backend.name=pytorch backend.num_threads=8
# Medium-sized problems (32 > sequence <= 384) use remaining 16 cores (on socket 0 - (8+16)/24 cores used)
numactl -C 8-23 -m 0 python3 src/main.py model=bert-base-cased batch_size=1 sequence_length=128 backend.name=pytorch backend.num_threads=16
# Large sized problems (sequence >= 384) use the entire CPU (on socket 1 - 24/24 cores used)
numactl -C 24-37 -m 1 python3 src/main.py model=bert-base-cased batch_size=1 sequence_length=384 backend.name=pytorch backend.num_threads=24
8. 批次大小擴充套件——透過多個並行獨立模型例項提高吞吐量和延遲
另一種非常有意思的擴充套件推理方向是:在池中放入更多模型例項,同時按比例減少每個例項實際接收的工作負載。
這種方法實際上改變了問題的大小(批次大小)和參與計算的資源(核心)。
為了說明這一點,想象你有一臺擁有 C 個 CPU 核心的伺服器,你想執行一個包含 B 個樣本和 S 個令牌的工作負載。
您可以將此工作負載表示為形狀為 [B, S] 的張量,其中 B 是批次大小,S 是 B 個樣本中的最大序列長度。
對於所有例項(N),每個例項在 C / N 個核心上執行,並將接收任務的子集 [B / N, S]。
每個例項接收的不是全域性批次,而是其子集 [B / N, S],因此得名**批次大小擴充套件**。
為了突出這種擴充套件方法的好處,下面的圖表報告了在擴充套件模型例項時延遲和吞吐量的影響。
在檢視結果時,讓我們關注延遲和吞吐量方面:
一方面,我們取例項池中的最大延遲來反映處理批次中所有樣本所需的時間。換句話說,由於例項以真正的並行方式執行,因此從所有例項中收集所有批次塊所需的時間取決於池中單個例項完成其塊所需的最長時間。
正如您在圖7中看到的,隨著例項數量的增加,實際的延遲增益確實取決於問題的大小。在所有情況下,我們都可以找到最優的資源分配(批次大小和例項數量)來最小化我們的延遲,但核心參與計算的數量沒有特定的模式。
另外,需要注意的是,在其他系統(例如作業系統、核心版本、框架版本等)上,結果可能完全不同。
圖8總結了旨在最小化延遲的最佳多例項配置,透過取所涉及例項數量的最小值。
例如,對於 {batch = 8, sequence length = 128},使用4個例項(每個例項 {batch = 2} 和12個核心)可獲得最佳延遲測量結果。
圖9報告了PyTorch和TensorFlow在各種問題規模下最小化延遲的所有設定。
**劇透**:在後續的部落格文章中,我們將討論許多其他最佳化,這些最佳化將顯著影響此圖表。


另一方面,我們將吞吐量視為所有並行執行模型例項的總和。它允許我們視覺化系統在新增越來越多例項(每個例項資源更少但工作負載按比例分配)時的可擴充套件性。
在這裡,結果顯示出幾乎線性的可伸縮性,從而實現了最佳的硬體利用率。

9. 結論
透過這篇部落格文章,我們涵蓋了PyTorch和TensorFlow開箱即用的BERT推理效能,這些效能是透過簡單的PyPi安裝,且無需進一步調整即可獲得的。
需要強調的是,這裡提供的資料反映了開箱即用的框架設定,因此可能無法提供絕對最佳的效能。
我們決定不在本部落格文章中包含最佳化,以專注於硬體和效率。最佳化將在第二部分討論!🚀
然後,我們涵蓋並詳細闡述了設定執行緒親和性的影響和重要性,以及目標問題規模與完成任務所需核心數量之間的權衡。
此外,重要的是要定義最佳化部署時使用**哪些標準**(即延遲與吞吐量),因為由此產生的設定可能完全不同。
更普遍地說,小問題(短序列和/或小批次)可能需要更少的核心來獲得最佳延遲,而大問題(非常長的序列和/或大批次)則需要更多核心。
在考慮最終部署平臺時,涵蓋所有這些方面是很有趣的,因為它可以大幅削減基礎設施成本。
例如,我們這臺48核機器每小時收費**4.848美元**,而一臺只有8核的小型例項則將成本降至**0.808美元/小時**,從而實現**6倍的成本降低**。
最後但同樣重要的是,本部落格文章中討論的許多引數都可以透過一個啟動指令碼自動調整,該指令碼深受英特爾最初編寫並可在此處獲得的指令碼的啟發。
啟動指令碼能夠自動啟動您的Python程序,並設定正確的執行緒親和性,有效地在例項之間分配資源,以及許多其他效能提示!我們將在第二部分詳細介紹許多這些提示🧐。
在後續的部落格文章中,將涉及更高階的設定和調整技術,以進一步降低模型延遲,例如:
- 啟動指令碼演練
- 調整記憶體分配庫
- 使用Linux的透明巨頁機制
- 使用供應商特定的數學/並行庫
敬請期待!🤗
致謝
- Omry Yadan (Facebook FAIR) - OmegaConf & Hydra 的作者,感謝他提供正確設定 Hydra 的所有提示。
- 所有英特爾和英特爾實驗室的自然語言處理同事們——感謝他們對transformers以及更廣泛的自然語言處理領域所做的持續最佳化和研究努力。
- Hugging Face 的同事們——感謝他們在評審過程中提供的所有評論和改進。
參考文獻
- Transformer基準測試:PyTorch與TensorFlow
- HuggingFace的Transformers:最先進的自然語言處理
- HuggingFace的模型中心
- BERT - 用於語言理解的深度雙向Transformer預訓練 (Devlin & al. 2018)
- Jay Alammar的圖解Transformer部落格文章
- PyTorch - TorchScript
- Google加速線性代數 (XLA)
- ONNX Runtime - 最佳化和加速機器學習推理和訓練
- Q8BERT - 量化8位BERT (Zafrir & al. 2019)
- OpenMP
- Intel oneDNN
- 英特爾® 超執行緒技術——技術使用者指南
- 超執行緒技術簡介
- BLAS (基礎線性代數子程式) - 維基百科
- 最佳化NUMA應用程式

