最佳化故事:Bloom 推理






本文將帶您瞭解我們如何構建高效推理伺服器,為 https://huggingface.co/bigscience/bloom 提供支援的幕後故事。
我們在數週內將延遲降低了5倍(吞吐量增加了50倍)。我們想分享為實現如此顯著的速度提升所經歷的所有困難和史詩般的勝利。
許多不同的人在多個階段參與其中,因此本文不會涵蓋所有內容。請大家多多包涵,有些內容可能已經過時或完全錯誤,因為我們仍在學習如何最佳化超大型模型,並且新的硬體功能和內容不斷湧現。
如果您最喜歡的最佳化方法沒有被討論或被不正確地呈現,我們深表歉意,請與我們分享,我們非常樂意嘗試新事物並糾正我們的錯誤。
建立 BLOOM
這不言而喻,如果沒有最初可訪問的大型模型,也就沒有最佳化其推理的真正理由。這是一項由許多不同人共同完成的非凡努力。
為了在訓練期間最大化 GPU 利用率,我們探索了幾種解決方案,最終選擇 Megatron-Deepspeed 來訓練最終模型。這意味著原始程式碼不一定與 transformers 庫相容。
移植到transformers
由於原始訓練程式碼,我們著手做了一件我們經常做的事情:將現有模型移植到 transformers。目標是從訓練程式碼中提取相關部分並在 transformers 中實現。這項工作由 Younes 負責。這絕不是一項小工作,因為它花費了將近一個月的時間和 200 次提交才完成。
有幾點需要注意,它們將在後面再次提及。
我們需要有更小的模型 bigscience/bigscience-small-testing 和 bigscience/bloom-560m。這非常重要,因為它們更小,所以使用它們時一切都更快。
首先,你必須放棄最終能精確到位元組地得到相同 logits 的希望。PyTorch 版本可能會改變核心並引入細微差異,而不同的硬體由於架構不同也可能產生不同的結果(而且出於成本考慮,你可能不想一直在一臺 A100 GPU 上進行開發)。
為所有模型建立一套良好的嚴格測試套件非常重要
我們發現的最佳測試是使用一組固定的提示。你知道提示,你也知道需要確定性地完成的文字,所以是貪婪的。如果兩個生成是相同的,你基本上可以忽略小的 logits 差異。每當你看到偏差時,你需要進行調查。這可能是你的程式碼沒有做它應該做的事情,或者你實際上超出了該模型的領域,因此模型對噪聲更敏感。如果你有幾個提示並且提示足夠長,你就不太可能偶然地對所有提示都觸發這種情況。提示越多越好,越長越好。
第一個模型(small-testing)和大型 Bloom 模型一樣是 bfloat16 格式,所以一切都應該非常相似,但它訓練不多或者表現不佳,因此輸出波動很大。這意味著我們在這些生成測試中遇到了問題。第二個模型更穩定,但它是在 float16 而不是 bfloat16 中訓練和儲存的。這使得兩者之間有更大的誤差空間。
公平地說,bfloat16 -> float16 轉換在推理模式下似乎是正常的(bfloat16 主要用於處理大梯度,而推理中不存在大梯度)。
在這一步中,我們發現並實現了一個重要的權衡。因為 Bloom 是在分散式設定中訓練的,所以部分程式碼對線性層進行了張量並行化,這意味著在單個 GPU 上作為單個操作執行相同的操作會產生不同的結果。這花費了一段時間才確定,我們面臨的選擇是要麼實現100%的相容性但模型速度慢得多,要麼在生成中接受很小的差異但執行速度快得多且程式碼更簡單。我們選擇了一個可配置的標誌。
首次推理 (PP + Accelerate)
Note: Pipeline Parallelism (PP) means in this context that each GPU will own
some layers so each GPU will work on a given chunk of data before handing
it off to the next GPU.
現在我們有了可用的 transformers 乾淨版本,可以開始執行它了。
Bloom 是一個 352GB 的模型(bf16 中有 176B 個引數),我們需要至少那麼多的 GPU RAM 才能使其適應。我們曾短暫探索過在小型機器上解除安裝到 CPU,但推理速度慢了幾個數量級,所以我們放棄了。
然後我們想基本上使用 pipeline。所以這是內部測試,也是 API 始終在底層使用的東西。
然而 pipelines 不具備分散式感知能力(這不是它們的目標)。在簡短討論選項後,我們最終使用 accelerate 新建立的 device_map="auto" 來管理模型的 shards。我們不得不解決一些 bug,並稍微修改 transformers 程式碼以幫助 accelerate 完成正確的工作。
它的工作原理是,將transformer的各個層進行拆分,並將模型的一部分分配給每個GPU。因此,GPU0 完成工作後,將其交給GPU1,以此類推。
最終,透過在頂部構建一個小型HTTP伺服器,我們能夠開始提供Bloom(大型模型)服務!!
起點
但我們甚至還沒有開始討論最佳化呢!
我們實際上有很多事情要做,整個過程就像紙牌城堡。在最佳化過程中,我們將修改底層程式碼,確保不會以某種方式破壞模型非常重要,而且這比你想象的更容易做到。
所以我們現在處於最佳化的第一步,我們需要開始測量並持續測量效能。因此,我們需要考慮我們關心什麼。對於一個支援多種選項的開放式推理伺服器,我們期望使用者傳送帶有不同引數的許多查詢,而我們關心的是:
我們能同時服務的使用者數量(吞吐量) 平均使用者被服務需要多長時間(延遲)?
我們用 locust 編寫了一個測試指令碼,它正是如此。
from locust import HttpUser, between, task
from random import randrange, random
class QuickstartUser(HttpUser):
wait_time = between(1, 5)
@task
def bloom_small(self):
sentence = "Translate to chinese. EN: I like soup. CN: "
self.client.post(
"/generate",
json={
"inputs": sentence[: randrange(1, len(sentence))],
"parameters": {"max_new_tokens": 20, "seed": random()},
},
)
@task
def bloom_small(self):
sentence = "Translate to chinese. EN: I like soup. CN: "
self.client.post(
"/generate",
json={
"inputs": sentence[: randrange(1, len(sentence))],
"parameters": {
"max_new_tokens": 20,
"do_sample": True,
"top_p": 0.9,
"seed": random(),
},
},
)
注意:這並非我們使用的最好或唯一的負載測試,但它始終是第一個執行的,以便在不同方法之間進行公平比較。在此基準測試中表現最佳並不意味著它是最佳解決方案。除了實際的現實世界效能外,還需要使用其他更復雜的場景。
我們希望觀察各種實現的啟動過程,並確保在負載下伺服器能夠正常進行熔斷。熔斷意味著伺服器可以(快速地)響應,表示它不會回答您的查詢,因為同時嘗試使用它的人太多。這對於避免“死亡擁抱”至關重要。
在此基準測試中,初始效能(在 GCP 上使用 16xA100 40Go 機器,這是全程使用的機器)為:
請求/秒:0.3(吞吐量) 延遲:350毫秒/token(延遲)
這些數字並不理想。在開始工作之前,讓我們估計一下我們能想象到的最佳成績。運算元量的公式是 24Bsh^2 + 4𝐵s^2h24Bsh^2 + 4𝐵s^2h,其中 B 是批次大小,s 是序列長度,h 是隱藏維度。
我們來計算一下,單次前向傳播得到 17 TFlop。檢視 A100 的規格,它聲稱單卡 312 TFLOPS。這意味著單個 GPU 理論上可以達到 17 / 312 = 54ms/token。我們使用了 16 個這樣的 GPU,因此在整臺機器上是 3ms/token。這些數字請持保留態度,因為永遠不可能達到這些數字,而且實際效能很少與規格相符。此外,如果計算不是您的限制因素,那麼這不是您可以達到的最低點。知道您離目標有多遠是很好的實踐。在這種情況下,我們相差兩個數量級,所以距離很遠。此外,這個估計將所有浮點運算都用於延遲,這意味著一次只能處理一個請求(這沒關係,因為您正在最大限度地利用您的機器,所以沒有太多其他事情可以做,但是我們可以透過批處理更容易地獲得更高的延遲和吞吐量)。
探索多種途徑
Note: Tensor Parallelism (TP) means in this context that each GPU will own
part of the weights, so ALL gpus are active all the time and do less work.
Usually this comes with a very slight overhead that some work is duplicated
and more importantly that the GPUs regularly have to communicate to each other
their results to continue the computation
現在我們對現狀有了很好的瞭解,是時候開始工作了。
我們根據團隊成員和各自的知識嘗試了許多不同的方法。
所有的努力都值得單獨寫一篇部落格文章,所以我將只列出它們,解釋一些最終的經驗教訓,並深入探討當前伺服器中使用的細節。從流水線並行(PP)到張量並行(TP)是延遲方面一個重要的變化。每個 GPU 將擁有部分引數,並且所有 GPU 將同時工作。因此,延遲應該會大幅降低,但代價是通訊開銷,因為它們需要定期相互通訊結果。
值得注意的是,這是一個非常廣泛的方法範圍,其目的是有意地更多地瞭解每種工具以及它如何適應未來的工作。
將程式碼移植到JAX/Flax以在TPU上執行:
- 預計選擇並行型別會更容易。因此,TP應該更容易測試。這是Jax設計的一大優點。
- 對硬體的限制更多,TPU 上的效能可能優於 GPU,並且 TPU 的供應商選擇較少。
- 缺點是需要再次移植。不過,在我們的庫中,無論如何都會受到歡迎。
結果
- 移植並不是一件容易的事,因為有些條件和核心很難正確復現。不過,仍然可以管理。
- 並行化一旦移植就很容易實現,值得稱讚的是 Jax 的說法是正確的。
- 事實證明,Ray/與TPU工作器通訊對我們來說是一個真正的痛苦。我們不知道是工具的問題、網路問題,還是僅僅是我們缺乏知識,但它比我們預期的更嚴重地減慢了實驗和工作。我們啟動了一個需要5分鐘執行的實驗,等待了5分鐘什麼也沒發生,10分鐘後仍然什麼也沒有,結果發現某個工作器宕機/沒有響應,我們不得不手動進入,找出發生了什麼,修復它,重啟一些東西,然後重新啟動,就這樣我們浪費了半個小時。重複足夠多次,浪費的時間就會迅速累積。我們想強調的是,這不一定是對我們使用的工具的批評,而是我們所擁有的主觀體驗仍然存在。
- 無法控制編譯 一旦我們讓它執行起來,我們嘗試了幾種設定,以找出哪種最適合我們設想的推理,結果發現很難從設定中猜測延遲/吞吐量會發生什麼。例如,當 batch_size=1(每個請求/使用者都是獨立的)時,我們有 0.3 rps,延遲為 15ms/token(不要過多與本文中的其他數字進行比較,因為這是在不同的機器上,配置檔案也大不相同),這很棒,但總吞吐量並不比我們使用舊程式碼時好多少。因此,我們決定新增批處理,當 BS=2 時,延遲增加了 5 倍,而吞吐量只增加了 2 倍……經過進一步調查,結果發現,直到 batch_size=16,每個 batch_size 都具有相同的延遲配置檔案。因此,我們可以以 5 倍的延遲成本獲得 16 倍的吞吐量。這還不錯,但從數字來看,我們更喜歡更精細的控制。我們追求的數字源自 100ms、1s、10s、1mn 規則。
使用 ONNX/TRT 或其他編譯方法
- 它們應該處理大部分最佳化工作
- 缺點是,通常需要手動處理並行性。
結果
- 結果發現,為了能夠追蹤/即時編譯/匯出(trace/jit/export)資料,我們需要重構 PyTorch 的一部分,以便它能輕鬆地與純 PyTorch 方法融合。總的來說,我們發現透過留在 PyTorch 世界中,我們可以獲得所需的大部分最佳化,從而保持靈活性,而無需投入過多的編碼工作。另一點需要注意的是,由於我們是在 GPU 上執行,並且文字生成涉及多次前向傳播,我們需要張量留在 GPU 上。有時,將張量傳送到某個庫,獲得結果,執行 logits 計算(如 argmax 或採樣),然後再將其反饋回去會很困難。將迴圈放入外部庫意味著像 Jax 一樣失去靈活性,因此這在我們的用例中沒有被考慮。
DeepSpeed
- 這是支援訓練的技術,用於推理似乎也很公平。
- 缺點是,以前從未用於/準備用於推理。
結果
- 我們很快就取得了令人印象深刻的結果,這大致與我們目前執行的最後一次迭代相同。
- 我們必須發明一種將 web 伺服器(處理併發)置於 DeepSpeed 之上的方法,DeepSpeed 也擁有多個程序(每個 GPU 一個)。由於存在一個出色的庫 Mii,它不符合我們設想的極其靈活的目標,但我們現在可能已經開始在其之上進行開發。(當前的解決方案將在稍後討論)。
- 我們遇到的 DeepSpeed 最大的問題是缺乏穩定性。我們在 CUDA 11.4 上執行它時遇到了問題,而程式碼是為 11.6 構建的。我們從未真正解決的長期存在的問題是,會定期發生核心崩潰(Cuda 非法訪問、維度不匹配等)。我們修復了其中很多問題,但在我們的 web 伺服器的壓力下,我們始終無法實現穩定性。儘管如此,我還是要感謝幫助我們的 Microsoft 團隊,我們進行了非常愉快的對話,加深了我們對正在發生的事情的理解,併為我們後續工作提供了真正的見解。
- 我感覺的一個痛點是,我們的團隊主要在歐洲,而微軟在加利福尼亞,所以合作在時間上很棘手,我們可能因此浪費了一大塊時間。這與技術部分無關,但承認合作的組織部分也同樣重要是件好事。
- 另一點需要注意的是,DeepSpeed 依賴於
transformers來注入其最佳化,由於我們幾乎持續更新程式碼,這使得 DeepSpeed 團隊很難在我們的main分支上保持程式碼正常執行。很抱歉給您帶來了不便,我想這就是為什麼它被稱為前沿技術的原因吧。
Web伺服器構想
- 鑑於我們將執行一個免費伺服器,使用者將傳送長文字、短文字,需要少量 token 或完整食譜,每個都帶有不同的引數,因此這裡必須做一些事情。
結果
- 我們使用出色的繫結 tch-rs 用
Rust重寫了所有程式碼。Rust 的目標並非效能提升,而是對並行性(執行緒/程序)的更精細控制,以及在 web 伺服器併發性和 PyTorch 併發性上進行更精細的調整。Python 因其 GIL 而臭名昭著,難以處理低階細節。 - 結果發現,大部分痛苦來自移植,之後實驗就輕鬆多了。我們發現,只要對迴圈有足夠的控制,即使在各種具有不同屬性的請求的背景下,我們也能為每個人提供出色的效能。程式碼供好奇者參考,但它不附帶任何支援或完善的文件。
- 它投入生產了幾周,因為它對並行性更寬鬆,我們可以更有效地利用 GPU(使用 GPU0 處理請求 1,而 GPU1 處理請求 0)。我們將 RPS 從 0.3 提升到約 2.5,同時保持相同的延遲。最佳情況本應是將吞吐量提高 16 倍,但這裡顯示的數字是實際工作負載測量值,所以這還算不錯。
純 PyTorch
- 純粹修改現有程式碼以使其更快,例如刪除
reshape操作,使用更最佳化的核心等。 - 缺點是,我們必須自己編寫 TP,而且我們有一個限制,即程式碼仍然符合我們的庫(大部分)。
結果
- 下一章。
最終路線:PyTorch + TP + 1 個自定義核心 + torch.jit.script
編寫更高效的 PyTorch 程式碼
列表上的第一項是刪除最初實現中不必要的操作。有些可以透過檢視程式碼並找出明顯缺陷來發現。
- Alibi 在 Bloom 中用於新增位置嵌入,它在太多地方被計算,我們可以只計算一次,並且更有效率。
這是一個10倍的速度提升,最新版本還包含了填充!由於這一步只計算一次,實際速度並不重要,但總的來說減少操作次數和張量建立是一個好的方向。
當您開始分析時,其他部分會更清晰地展現出來,我們廣泛使用了tensorboard 擴充套件
這提供了這種型別的影像,可以提供見解。
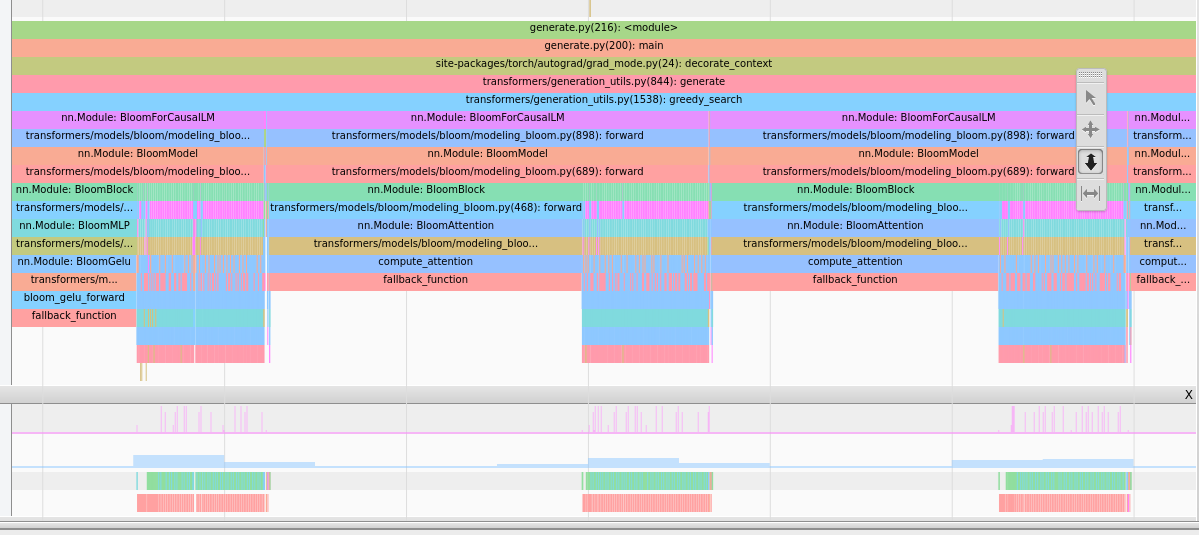 注意力佔用大量時間,請注意這是 CPU 檢視,因此長條不代表時間長,而是表示 CPU 正在等待上一步的 GPU 結果。
注意力佔用大量時間,請注意這是 CPU 檢視,因此長條不代表時間長,而是表示 CPU 正在等待上一步的 GPU 結果。 我們看到 `baddbmm` 之前有許多 `cat` 操作。
我們看到 `baddbmm` 之前有許多 `cat` 操作。例如,透過移除大量 reshape/transpose,我們發現: - 注意力是熱點路徑(這是預期的,但驗證總是好的)。 - 在注意力中,由於大量的 reshape,許多核心實際上是複製操作。 - 我們可以透過重構權重本身和過去來移除 reshape。這是一個破壞性更改,但它確實顯著提高了效能!
支援 TP
好的,我們已經移除了大部分唾手可得的最佳化,現在在 PP 中,延遲大致從 350ms/token 降低到 300ms/token。這使得延遲降低了 15%,但實際上它提供了更多,不過我們最初的測量並不十分嚴謹,所以就暫且沿用這個數字。
然後我們著手提供了一個 TP 實現。事實證明,它比我們預期的要快得多,實現只花了一個(有經驗的)開發人員半天的時間。結果在這裡。我們還能夠複用其他專案的程式碼,這很有幫助。
延遲直接從 300ms/token 降至 91ms/token,這極大地改善了使用者體驗。一個簡單的 20 token 請求從 6 秒縮短到 2 秒,從“緩慢”體驗變為“略有延遲”。
此外,吞吐量也大幅提高到 10 RPS。吞吐量的提高是因為 batch_size=1 的查詢與 batch_size=32 的查詢花費相同的時間,此時吞吐量基本上在延遲成本上是“免費”的。
唾手可得的最佳化
現在我們有了 TP 實現,可以再次開始分析和最佳化。這是一個足夠顯著的轉變,我們必須重新開始。
最突出的一點是,同步(ncclAllReduce)開始在負載中佔據主導地位,這是預期的,這是同步部分,它確實需要一些時間。我們從未嘗試過研究和最佳化這一點,因為它已經使用了 nccl,但那裡可能仍然有一些改進空間。我們認為這很難做得更好。
第二點是,Gelu 運算子啟動了許多逐元素核心,總的來說,它佔用的計算份額比我們預期的要大。
我們進行了更改
def bloom_gelu_forward(x):
return x * 0.5 * (1.0 + torch.tanh(0.79788456 * x * (1 + 0.044715 * x * x)))
到
@torch.jit.script
def bloom_gelu_forward(x):
return x * 0.5 * (1.0 + torch.tanh(0.79788456 * x * (1 + 0.044715 * x * x)))
這將操作從多個小的逐元素核心(以及因此產生的張量複製)轉換為單個核心操作!
這使得延遲從 91ms/token 降低到 81ms/token,直接提升了 10%!
但請注意,這並非可以隨意使用的神奇黑箱,核心融合不一定會發生,或者之前使用的操作可能已經極其高效。
我們發現它效果很好的地方:
- 您有大量小/逐元素操作
- 您有一個熱點,其中有一些難以去除的重塑和複製操作
- 當融合發生時。
史詩級失敗
在我們的測試期間,我們也曾發現 Rust 伺服器的延遲比 Python 伺服器低 25%。這相當奇怪,但由於測量結果一致,並且因為移除核心可以提高速度,我們當時認為降低 Python 開銷可能會帶來不錯的提升。
我們啟動了一個為期 3 天的工作,旨在重新實現 torch.distributed 的必要部分,以便在 Rust 環境中執行 nccl-rs。我們讓版本執行起來了,但與 Python 版本相比,生成結果有些異常。在調查問題期間,我們發現……我們忘記在 PyTorch 測量中移除分析器了……
那是一次史詩般的失敗,因為移除它後,我們又回到了那 25% 的效能,然後兩個程式碼執行速度都一樣快。這正是我們最初預期的,Python 不應該成為效能瓶頸,因為它主要執行的是 torch cpp 的程式碼。最終,3 天的時間並不是世界末日,將來某個時候它可能還會派上用場,但仍然相當糟糕。在進行最佳化時,進行錯誤或具有誤導性的測量是相當常見的,這最終會令人失望,甚至對整體產品有害。這就是為什麼小步進行並儘快對結果抱有期望有助於控制這種風險。
另一個我們需要格外小心的地方是初始前向傳播(沒有 past)和後續前向傳播(有 past)。如果你優化了第一個,你很可能會減慢後面更重要且佔大部分執行時間的傳播。另一個相當常見的罪魁禍首是測量的是 CPU 時間,而不是實際的 CUDA 時間,所以你在執行時需要 torch.cuda.synchronize() 以確保核心完成。
自定義核心
到目前為止,我們已經實現了接近 DeepSpeed 的效能,而無需 PyTorch 之外的任何自定義程式碼!相當棒。我們也不必在執行時批處理大小的靈活性上做出任何妥協!
但鑑於 DeepSpeed 的經驗,我們希望嘗試編寫一個自定義核心,以在 torch.jit.script 無法為我們完成的 hot path 中融合一些操作。本質上是以下兩行:
attn_weights = attention_scores.masked_fill_(attention_mask, torch.finfo(attention_scores.dtype).min)
attention_probs = F.softmax(attn_weights, dim=-1, dtype=torch.float32).to(input_dtype)
第一個 mask fill 會建立一個新的張量,它在這裡只是為了告訴 softmax 運算子忽略這些值。此外,softmax 需要在 float32 上計算(為了穩定性),但在自定義核心中,我們可以限制必要的向上轉換量,因此我們將它們限制在實際的總和和累加值上。
程式碼可以在此處找到。請記住,我們只有一個 GPU 架構作為目標,因此我們可以專注於此,而且我們(尚)不是編寫核心的專家,因此可能有更好的方法來完成此操作。
這個自定義核心又帶來了 10% 的延遲提升,從 81ms/token 降至 71ms/token 的延遲。同時保持了我們的靈活性。
之後,我們研究並探索了其他一些方法,例如融合更多運算元、移除其他重塑操作,或將它們放置在其他位置。但沒有任何嘗試能對最終版本產生足夠顯著的影響。
Web伺服器部分
就像 Rust 版本一樣,我們必須實現帶有不同引數的請求的批處理。由於我們處於 PyTorch 世界中,我們幾乎完全控制正在發生的事情。由於我們處於 Python 中,我們有一個限制因素,即 torch.distributed 需要在多個程序而不是執行緒上執行,這意味著程序之間通訊略微困難。最終,我們選擇透過 Redis pub/sub 傳輸原始字串,一次性將請求分發給所有程序。由於我們在不同的程序中,這樣做比傳輸張量(它們更大)更容易。
然後我們不得不放棄使用 generate,因為這會將引數應用於批處理的所有成員,而我們實際上希望應用不同的引數集。幸運的是,我們可以重用較低級別的項,例如 LogitsProcessor,從而為我們節省大量工作。
所以我們重構了一個 generate 函式,它接受一個引數列表,並將其應用於批處理的每個成員。
終端使用者體驗的另一個非常重要的方面是延遲。由於我們為不同的請求設定了不同的引數集,我們可能會遇到以下情況:
20 token 請求需要 1.5 秒,而 250 token 請求需要 18 秒。如果一直進行批處理,我們就會讓請求 250 token 的使用者等待 18 秒,這在他看來就像我們以 900ms/token 的速度執行,這相當慢!
由於我們身處一個具有極高靈活性的 PyTorch 世界,我們可以做的是,一旦生成了前 20 個 token,就立即從批處理中提取第一個請求,並在請求的 1.5 秒內將其返回給該使用者!我們還節省了相當於 230 個 token 的計算量。
因此,靈活性對於獲得最佳延遲至關重要。
最後說明和瘋狂想法
最佳化是一項永無止境的工作,與其他專案一樣,20% 的工作通常能帶來 80% 的結果。在某個時候,我們開始採用一種小型測試策略來找出我們的一些想法的潛在產出,如果測試沒有產生顯著結果,那麼我們就放棄這個想法。一天帶來 10% 的增長很有價值,兩週帶來 10 倍的增長也很有價值。兩週帶來 10% 的增長就不那麼有趣了。
您嘗試過...嗎?
我們知道存在但由於各種原因未使用的事物。可能是我們覺得它不適合我們的用例,工作量太大,收益不夠可觀,甚至僅僅是因為我們有太多選項可以嘗試,由於時間不足而放棄了一些選項。以下內容不分先後順序。
- Cuda 圖
- nvFuser (這就是
torch.jit.script的動力來源,所以我們確實使用了它。) - FasterTransformer
- Nvidia 的 Triton
- XLA (Jax 也在使用 xla !)
- torch.fx
- TensorRT
如果您最喜歡的工具在此處缺失,或者您認為我們遺漏了可能有用且重要的內容,請隨時與我們聯絡!
Flash attention
我們曾簡要研究過整合 Flash Attention,雖然它在第一次前向傳播(沒有 past_key_values)時表現極佳,但在使用 past_key_values 時並沒有帶來那麼大的改進。由於我們需要對其進行調整,使其包含 alibi 張量進行計算,因此我們決定暫時不做這項工作(至少目前如此)。
OpenAI Triton
Triton 是一個構建 Python 自定義核心的優秀框架。我們希望更多地使用它,但到目前為止還沒有。我們很期待看到它是否比我們的 Cuda 核心表現更好。當我們考慮這部分的選擇時,直接用 Cuda 編寫似乎是實現我們目標的最短路徑。
填充和重塑
如本文所述,每次張量複製都有成本,而生產執行的另一個隱藏成本是填充。當兩個查詢長度差異很大時,您必須填充(使用虛擬 token)以使其適應正方形。這可能會導致許多不必要的計算。更多資訊。
理想情況下,我們應該完全避免這些計算,並且永遠不要進行重塑。Tensorflow 有 RaggedTensor 的概念,PyTorch 有 Nested tensors。這兩者似乎都不如常規張量那麼簡化,但可能會讓我們進行更少的計算,這始終是一個勝利。
在一個理想的世界裡,整個推理都將用 CUDA 或純 GPU 實現。考慮到我們融合操作時獲得的效能提升,這看起來很理想。但它能達到什麼程度,我們一無所知。如果更聰明的 GPU 人有想法,我們洗耳恭聽!
致謝
所有這些工作都是許多 HF 團隊成員合作的成果。排名不分先後,@ThomasWang @stas @Nouamane @Suraj @Sanchit @Patrick @Younes @Sylvain @Jeff (Microsoft) @Reza 以及所有 BigScience 組織。

