從零開始訓練 CodeParrot 🦜







在這篇部落格文章中,我們將探討構建 GitHub CoPilot 背後的技術需要什麼。GitHub CoPilot 是一個在程式設計師編碼時提供建議的應用程式。在這個分步指南中,我們將學習如何從零開始訓練一個名為 CodeParrot 🦜 的大型 GPT-2 模型。CodeParrot 可以自動完成你的 Python 程式碼 - 在這裡試試看。讓我們開始從零構建它吧!
建立大型原始碼資料集
我們首先需要一個大型訓練資料集。為了訓練一個 Python 程式碼生成模型,我們訪問了 Google BigQuery 上可用的 GitHub 資料轉儲,並篩選出所有 Python 檔案。結果是一個 180 GB 的資料集,包含 2000 萬個檔案(可在此處獲取:here)。經過初步訓練實驗後,我們發現數據集中的重複項嚴重影響了模型效能。進一步調查資料集後,我們發現:
- 0.1% 的唯一檔案佔所有檔案的 15%
- 1% 的唯一檔案佔所有檔案的 35%
- 10% 的唯一檔案佔所有檔案的 66%
你可以在此 Twitter 帖子中瞭解更多我們的發現。我們刪除了重複項,並應用了Codex 論文中發現的相同清理啟發式方法。Codex 是 CoPilot 背後的模型,它是一個在 GitHub 程式碼上進行微調的 GPT-3 模型。
清理後的資料集仍然有 50GB 大小,可在 Hugging Face Hub 上獲取:codeparrot-clean。有了這些,我們就可以設定一個新的分詞器並訓練模型。
初始化分詞器和模型
首先我們需要一個分詞器。讓我們專門針對程式碼進行訓練,以便它能很好地分割程式碼標記。我們可以採用現有的分詞器(例如 GPT-2),並使用 train_new_from_iterator() 方法直接在我們的資料集上訓練它。然後我們將其推送到 Hub。請注意,我們從程式碼示例中省略了匯入、引數解析和日誌記錄,以保持程式碼塊緊湊。但是你可以在這裡找到包括預處理和下游任務評估在內的完整程式碼。
# Iterator for Training
def batch_iterator(batch_size=10):
for _ in tqdm(range(0, args.n_examples, batch_size)):
yield [next(iter_dataset)["content"] for _ in range(batch_size)]
# Base tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
base_vocab = list(bytes_to_unicode().values())
# Load dataset
dataset = load_dataset("lvwerra/codeparrot-clean", split="train", streaming=True)
iter_dataset = iter(dataset)
# Training and saving
new_tokenizer = tokenizer.train_new_from_iterator(batch_iterator(),
vocab_size=args.vocab_size,
initial_alphabet=base_vocab)
new_tokenizer.save_pretrained(args.tokenizer_name, push_to_hub=args.push_to_hub)
在Hugging Face 課程中瞭解更多關於分詞器以及如何構建它們。
看到那個不起眼的 `streaming=True` 引數了嗎?這個小小的改動影響巨大:它不再下載完整的(50GB)資料集,而是根據需要流式傳輸單個樣本,從而節省了大量磁碟空間!請檢視Hugging Face 課程以獲取更多關於流式傳輸的資訊。
現在,我們初始化一個新模型。我們將使用與 GPT-2 大型模型(1.5B 引數)相同的超引數,並調整嵌入層以適應我們的新分詞器,同時增加一些穩定性調整。`scale_attn_by_layer_idx` 標誌確保我們按層 ID 縮放注意力,而 `reorder_and_upcast_attn` 主要確保我們以全精度計算注意力以避免數值問題。我們將新初始化的模型推送到與分詞器相同的倉庫。
# Load codeparrot tokenizer trained for Python code tokenization
tokenizer = AutoTokenizer.from_pretrained(args.tokenizer_name)
# Configuration
config_kwargs = {"vocab_size": len(tokenizer),
"scale_attn_by_layer_idx": True,
"reorder_and_upcast_attn": True}
# Load model with config and push to hub
config = AutoConfig.from_pretrained('gpt2-large', **config_kwargs)
model = AutoModelForCausalLM.from_config(config)
model.save_pretrained(args.model_name, push_to_hub=args.push_to_hub)
現在我們有了一個高效的分詞器和一個全新初始化的模型,我們可以開始實際的訓練迴圈了。
實現訓練迴圈
我們使用 🤗 Accelerate 庫進行訓練,該庫允許我們將訓練從筆記本擴充套件到多 GPU 機器,而無需更改一行程式碼。我們只需建立一個加速器並進行一些引數整理。
accelerator = Accelerator()
acc_state = {str(k): str(v) for k, v in accelerator.state.__dict__.items()}
parser = HfArgumentParser(TrainingArguments)
args = parser.parse_args()
args = Namespace(**vars(args), **acc_state)
samples_per_step = accelerator.state.num_processes * args.train_batch_size
set_seed(args.seed)
現在,我們已經準備好進行訓練了!讓我們使用 `huggingface_hub` 客戶端庫來克隆包含新分詞器和模型的倉庫。我們將為此實驗切換到一個新分支。透過這種設定,我們可以並行執行許多實驗,最後只需將最好的一個合併到主分支。
# Clone model repository
if accelerator.is_main_process:
hf_repo = Repository(args.save_dir, clone_from=args.model_ckpt)
# Checkout new branch on repo
if accelerator.is_main_process:
hf_repo.git_checkout(run_name, create_branch_ok=True)
我們可以直接從本地倉庫載入分詞器和模型。由於我們處理的是大型模型,我們可能希望開啟梯度檢查點,以減少訓練期間的 GPU 記憶體佔用。
# Load model and tokenizer
model = AutoModelForCausalLM.from_pretrained(args.save_dir)
if args.gradient_checkpointing:
model.gradient_checkpointing_enable()
tokenizer = AutoTokenizer.from_pretrained(args.save_dir)
接下來是資料集。我們使用一個能生成固定上下文大小樣本的資料集,使訓練更簡單。為了不過多浪費資料(有些樣本太短或太長),我們可以將多個示例與 EOS 標記連線起來,然後分塊。
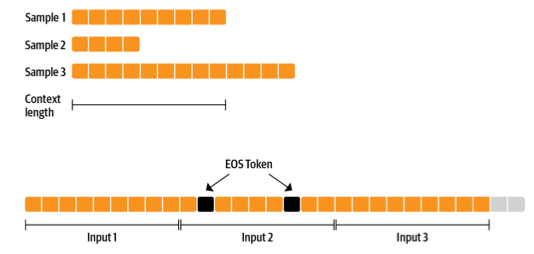
我們一起準備的序列越多,我們丟棄的令牌(上一圖中灰色部分)的比例就越小。由於我們希望流式傳輸資料集而不是預先準備所有內容,因此我們使用 `IterableDataset`。完整的資料集類如下所示
class ConstantLengthDataset(IterableDataset):
def __init__(
self, tokenizer, dataset, infinite=False, seq_length=1024, num_of_sequences=1024, chars_per_token=3.6
):
self.tokenizer = tokenizer
self.concat_token_id = tokenizer.bos_token_id
self.dataset = dataset
self.seq_length = seq_length
self.input_characters = seq_length * chars_per_token * num_of_sequences
self.epoch = 0
self.infinite = infinite
def __iter__(self):
iterator = iter(self.dataset)
more_examples = True
while more_examples:
buffer, buffer_len = [], 0
while True:
if buffer_len >= self.input_characters:
break
try:
buffer.append(next(iterator)["content"])
buffer_len += len(buffer[-1])
except StopIteration:
if self.infinite:
iterator = iter(self.dataset)
self.epoch += 1
logger.info(f"Dataset epoch: {self.epoch}")
else:
more_examples = False
break
tokenized_inputs = self.tokenizer(buffer, truncation=False)["input_ids"]
all_token_ids = []
for tokenized_input in tokenized_inputs:
all_token_ids.extend(tokenized_input + [self.concat_token_id])
for i in range(0, len(all_token_ids), self.seq_length):
input_ids = all_token_ids[i : i + self.seq_length]
if len(input_ids) == self.seq_length:
yield torch.tensor(input_ids)
緩衝區中的文字將並行分詞並連線起來。然後,分塊的樣本將被生成,直到緩衝區為空,然後該過程重新開始。如果我們將 `infinite` 設定為 `True`,資料集迭代器將在其末尾重新啟動。
def create_dataloaders(args):
ds_kwargs = {"streaming": True}
train_data = load_dataset(args.dataset_name_train, split="train", streaming=True)
train_data = train_data.shuffle(buffer_size=args.shuffle_buffer, seed=args.seed)
valid_data = load_dataset(args.dataset_name_valid, split="train", streaming=True)
train_dataset = ConstantLengthDataset(tokenizer, train_data, infinite=True, seq_length=args.seq_length)
valid_dataset = ConstantLengthDataset(tokenizer, valid_data, infinite=False, seq_length=args.seq_length)
train_dataloader = DataLoader(train_dataset, batch_size=args.train_batch_size)
eval_dataloader = DataLoader(valid_dataset, batch_size=args.valid_batch_size)
return train_dataloader, eval_dataloader
train_dataloader, eval_dataloader = create_dataloaders(args)
在開始訓練之前,我們需要設定最佳化器和學習率排程器。我們不想對偏差和 LayerNorm 權重應用權重衰減,因此我們使用一個輔助函式來排除它們。
def get_grouped_params(model, args, no_decay=["bias", "LayerNorm.weight"]):
params_with_wd, params_without_wd = [], []
for n, p in model.named_parameters():
if any(nd in n for nd in no_decay): params_without_wd.append(p)
else: params_with_wd.append(p)
return [{"params": params_with_wd, "weight_decay": args.weight_decay},
{"params": params_without_wd, "weight_decay": 0.0},]
optimizer = AdamW(get_grouped_params(model, args), lr=args.learning_rate)
lr_scheduler = get_scheduler(name=args.lr_scheduler_type, optimizer=optimizer,
num_warmup_steps=args.num_warmup_steps,
num_training_steps=args.max_train_steps,)
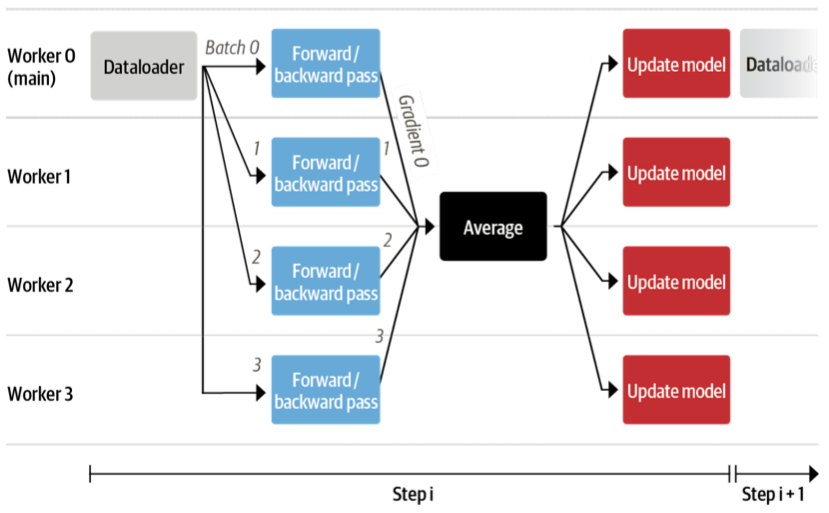
一個大問題是所有資料和模型將如何分佈在多個 GPU 上。這聽起來像是一項複雜的任務,但實際上只需要 🤗 Accelerate 的一行程式碼即可。
model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader)
在底層,它會使用分散式資料並行(DistributedDataParallel),這意味著每個批次都會被髮送到每個擁有自己模型副本的 GPU 工作器。在那裡,梯度會被計算,然後聚合以更新每個工作器上的模型。
我們還想時不時地在驗證集上評估模型,所以讓我們寫一個函式來完成這項任務。這會自動以分散式方式完成,我們只需要從工作節點收集所有損失即可。我們還想報告困惑度。
def evaluate(args):
model.eval()
losses = []
for step, batch in enumerate(eval_dataloader):
with torch.no_grad():
outputs = model(batch, labels=batch)
loss = outputs.loss.repeat(args.valid_batch_size)
losses.append(accelerator.gather(loss))
if args.max_eval_steps > 0 and step >= args.max_eval_steps:
break
loss = torch.mean(torch.cat(losses))
try:
perplexity = torch.exp(loss)
except OverflowError:
perplexity = float("inf")
return loss.item(), perplexity.item()
我們現在準備好編寫主訓練迴圈了。它看起來很像一個普通的 PyTorch 訓練迴圈。在這裡和那裡,你可以看到我們使用的是加速器函式而不是原生的 PyTorch。此外,每次評估後,我們都會將模型推送到分支。
# Train model
model.train()
completed_steps = 0
for step, batch in enumerate(train_dataloader, start=1):
loss = model(batch, labels=batch, use_cache=False).loss
loss = loss / args.gradient_accumulation_steps
accelerator.backward(loss)
if step % args.gradient_accumulation_steps == 0:
accelerator.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
completed_steps += 1
if step % args.save_checkpoint_steps == 0:
eval_loss, perplexity = evaluate(args)
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(args.save_dir, save_function=accelerator.save)
if accelerator.is_main_process:
hf_repo.push_to_hub(commit_message=f"step {step}")
model.train()
if completed_steps >= args.max_train_steps:
break
當我們呼叫 `wait_for_everyone()` 和 `unwrap_model()` 時,我們確保所有工作器都已準備就緒,並且早期由 `prepare()` 新增的任何模型層都已移除。我們還使用了易於實現的梯度累積和梯度裁剪。最後,訓練完成後,我們執行最後一次評估並儲存最終模型,然後將其推送到 Hub。
# Evaluate and save the last checkpoint
logger.info("Evaluating and saving model after training")
eval_loss, perplexity = evaluate(args)
log_metrics(step, {"loss/eval": eval_loss, "perplexity": perplexity})
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(args.save_dir, save_function=accelerator.save)
if accelerator.is_main_process:
hf_repo.push_to_hub(commit_message="final model")
完成!這就是訓練一個完整的 GPT-2 模型從頭開始所需的所有程式碼,僅有不到 150 行。我們沒有展示指令碼的匯入和日誌,以使程式碼更緊湊。現在,讓我們實際訓練它吧!
有了這段程式碼,我們為即將出版的《Transformer 和自然語言處理》一書訓練了模型:一個擁有 1.1 億和 15 億引數的 GPT-2 模型。我們使用一臺 16 x A100 GPU 機器分別訓練了這些模型 1 天和 1 周。足夠的時間喝杯咖啡,讀一兩本書了!
評估
這對於預訓練來說仍然是相對較短的訓練時間,但我們已經可以觀察到與類似模型相比良好的下游效能。我們根據 Codex 論文中引入的 OpenAI HumanEval 基準對模型進行了評估。它衡量了程式碼生成模型在近 200 個程式設計挑戰上的效能。
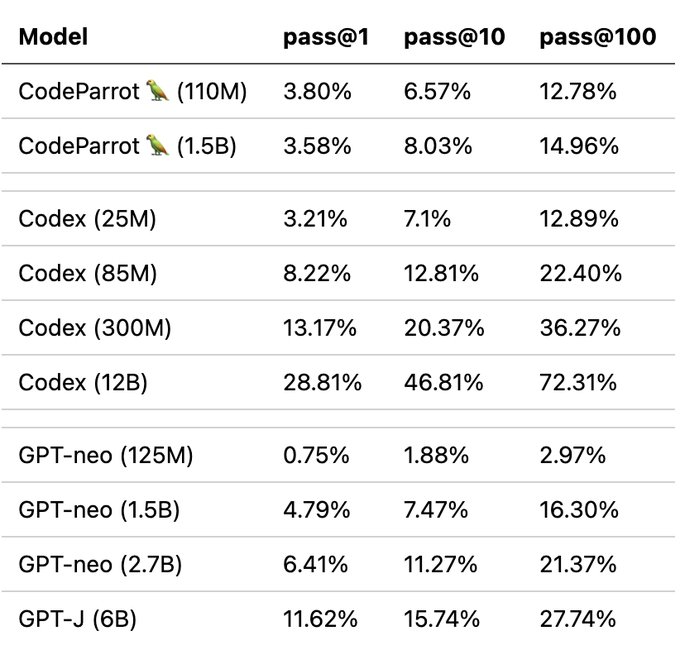
請注意,CodeParrot 大約訓練了 25-30B 個 token,而 GPT-neo 訓練了 300B 個 token,Codex 訓練了 300B (GPT-3 檢查點) + 100B (程式碼) 個 token。因此,在這裡你絕對物有所值。
但是,這個 *pass@k* 指標到底是什麼?簡單來說,它衡量的是給定模型生成的 *k* 個候選程式中,至少有一個程式透過程式設計問題單元測試的機率。自然,隨著 k 的增加,該指標也會增加,因為更多的候選程式有可能解決編碼挑戰。你可以使用 `datasets` 來使用該指標
from datasets import load_metric
code_eval = datasets.load_metric("code_eval")
test_cases = ["assert add(2,3)==5"]
candidates = [["def add(a,b): return a*b", "def add(a, b): return a+b"]]
pass_at_k, results = code_eval.compute(references=test_cases, predictions=candidates, k=[1, 2])
print(pass_at_k)
# -> {'pass@1': 0.5, 'pass@2': 1.0}
您還可以使用 `datasets` 載入 OpenAI 的 HumanEval 資料集
from datasets import load_dataset
dataset = load_dataset("openai_humaneval")
現在,讓我們看看漫長等待之後我們得到了什麼!
結果
我們先從簡單的開始,檢查模型是否能編寫一個函式,根據檔案路徑返回檔案大小:
提示
def get_files_size(filename):
完成
"""
Returns the file size of a file.
:param filepath: The path to the file.
:type filepath: str
:return: The file size.
:rtype: int
"""
return os.path.getsize(filepath)
到目前為止一切順利,但讓我們更進一步,嘗試一些更有趣的事情。構建生產就緒程式碼中最不令人興奮的方面之一就是編寫單元測試。讓我們看看能否使用 CodeParrot 為我們完成這項工作!
提示
def is_even(value):
"""Returns True if value is an even number."""
return value % 2 == 0
# setup unit tests for is_even
import unittest
完成
class TestIsEven(unittest.TestCase):
"""Tests for is_even function."""
def test_is_even(self):
"""Test is_even function."""
self.assertTrue(is_even(0))
self.assertTrue(is_even(1))
self.assertTrue
儘管測試條件本身看起來不太對勁,但模型已經為我們構建了所有樣板程式碼。僅此一項就可能非常有用,可以為我們節省幾分鐘時間!
但我們真正想要做的是構建更好的 Transformer 模型。讓我們使用 CodeParrot 來幫助我們實現這一點。
提示
from transformers import AutoTokenizer, AutoModelForSequenceClassification
# build a BERT classifier
完成
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
model = AutoModelForSequenceClassification.from_pretrained('bert-base-uncased')
看幾個例子固然不錯,但現在你可能想親自嘗試一下。我們為此準備了一些線上演示!
演示
您可以在我們新增到 Hugging Face Spaces 的兩個演示中試用這些模型。第一個演示可以讓你快速生成程式碼,而第二個演示則可以讓你用模型高亮顯示程式碼以發現錯誤!
您也可以直接使用 `transformers` 庫中的模型
from transformers import pipeline
pipe = pipeline('text-generation', model='lvwerra/codeparrot')
pipe('def hello_world():')
總結
在這篇簡短的部落格文章中,我們詳細介紹了訓練大型 GPT-2 模型 CodeParrot 🦜 用於程式碼生成的所有步驟。透過使用 🤗 Accelerate,我們構建了一個不到 200 行程式碼的訓練指令碼,該指令碼可以輕鬆地擴充套件到多個 GPU。有了它,你現在就可以訓練自己的 GPT-2 模型了!
這篇帖子簡要介紹了 CodeParrot 🦜,但如果你對深入瞭解如何預訓練這些模型感興趣,我們建議閱讀即將出版的《Transformer 和自然語言處理》一書中專門的章節。該章節提供了更多關於構建自定義資料集、訓練新分詞器時的設計考慮以及架構選擇的詳細資訊。