網際網路上的深度學習:協作訓練語言模型








現代語言模型在預訓練時通常需要大量的計算資源,如果沒有數十甚至數百個GPU或TPU,幾乎不可能獲得它們。儘管理論上可能可以結合多個個人的資源,但實際上,這種分散式訓練方法以前的成功案例有限,因為網際網路連線速度遠低於高效能GPU超級計算機。
在這篇博文中,我們描述了 DeDLOC — 一種新的協作分散式訓練方法,它可以根據參與者的網路和硬體限制進行調整。我們展示了它可以在真實場景中成功應用,透過與40名志願者一起預訓練孟加拉語模型 sahajBERT。在孟加拉語的下游任務中,該模型取得了接近最先進的質量,結果與使用數百個高階加速器的更大模型相當。
開放協作中的分散式深度學習
我們為什麼要這樣做?
如今,許多最高質量的自然語言處理系統都基於大型預訓練Transformer。通常,它們的質量隨規模的增大而提高:透過增加引數數量並利用大量的無標籤文字資料,您可以在自然語言理解和生成方面取得無與倫比的結果。
不幸的是,我們使用這些預訓練模型不僅僅是因為方便。在大型資料集上訓練Transformer所需的硬體資源常常超出個人甚至大多數商業或研究機構所能承擔的範圍。以BERT為例:其訓練成本估計約為7,000美元,而對於GPT-3這樣最大的模型,這個數字可能高達1200萬美元!這種資源限制可能看似顯而易見且不可避免,但對於更廣泛的機器學習社群來說,真的沒有替代預訓練模型的其他方法嗎?
然而,這種情況可能有一個出路:要找到解決方案,我們只需環顧四周。我們正在尋找的計算資源可能已經存在;例如,我們許多人自己家裡就有配備遊戲或工作站GPU的強大電腦。您可能已經猜到我們將像 Folding@home、Rosetta@home、Leela Chess Zero 或各種利用志願者計算的 BOINC 專案那樣,將它們的計算能力聯合起來,但這種方法更具普遍性。例如,幾個實驗室可以聯合他們的小型叢集,以利用所有可用資源,有些人可能希望使用廉價的雲實例加入實驗。
對於一個持懷疑態度的人來說,我們可能忽略了一個關鍵因素:分散式深度學習中的資料傳輸往往是瓶頸,因為我們需要從多個工作節點聚合梯度。確實,任何對網際網路分散式訓練的簡單方法都註定會失敗,因為大多數參與者沒有千兆連線,並且可能隨時從網路斷開。那麼,你怎麼可能用家庭資料套餐訓練任何東西呢?:)
作為解決這個問題的方法,我們提出了一種新的訓練演算法,稱為開放協作中的分散式深度學習(或 **DeDLOC**),在最近釋出的 預印本 中詳細描述。現在,讓我們來了解一下這個演算法的核心思想!
與志願者一起訓練
在最常用的版本中,使用多個 GPU 進行分散式訓練非常簡單。回想一下,在進行深度學習時,您通常會計算損失函式在批次訓練資料中許多示例上的平均梯度。在**資料並行**分散式深度學習的情況下,您只需將資料分散到多個工作節點,單獨計算梯度,然後在處理完本地批次後對它們進行平均。當所有工作節點上都計算出平均梯度後,我們使用最佳化器調整模型權重,並繼續訓練我們的模型。您可以在下面看到不同任務的執行說明。

分散式訓練中對等節點執行的典型機器學習任務,可能帶有角色分離
通常,為了減少同步量並穩定學習過程,我們可以在平均之前積累 N 個批次的梯度,這相當於將實際批次大小增加 N 倍。這種方法,結合對大多數最先進的語言模型使用大批次的觀察,使我們產生了一個簡單的想法:在每個最佳化器步驟之前,讓我們在所有志願者裝置上積累一個**非常**大的批次!除了與常規分散式訓練完全等效且易於擴充套件之外,這種方法還具有內建的容錯優點,我們將在下面進行說明。
讓我們考慮在協作實驗中可能遇到的一些潛在故障情況。到目前為止,最常見的情況是,一個或幾個對等節點從訓練過程中斷開連線:他們可能連線不穩定,或者只是想將他們的 GPU 用於其他用途。在這種情況下,我們只會遭受輕微的訓練挫折:這些對等節點的貢獻將從當前累積的批次大小中扣除,但其他參與者將用他們的梯度來彌補。此外,如果有更多的對等節點加入,目標批次大小將簡單地更快達到,我們的訓練過程將自然地加速。您可以在影片中看到這一演示
自適應平均
現在我們已經討論了整個訓練過程,還有一個問題:我們如何實際聚合參與者的梯度?大多數家用電腦無法輕易接受傳入連線,下載速度也可能成為一個限制。
由於我們依靠志願硬體進行實驗,中央伺服器並不是一個真正可行的選擇,因為它在擴充套件到數十個客戶端和數億個引數時會很快面臨過載。目前大多數資料並行訓練執行無論如何都不使用這種策略;相反,它們依賴於 All-Reduce——一種高效的all-to-all通訊原語。由於巧妙的演算法最佳化,每個節點無需將整個區域性梯度傳送給每個對等節點即可計算全域性平均值。
由於 All-Reduce 是去中心化的,它似乎是一個不錯的選擇;然而,我們仍然需要考慮硬體和網路設定的多樣性。例如,一些志願者可能透過網路較慢但 GPU 強大的計算機加入,一些可能只對其他部分對等節點有更好的連線,還有一些可能被防火牆阻止傳入連線。
事實證明,我們可以透過利用這些效能資訊,在執行時提出一種最優的資料傳輸策略!從高層次上講,我們根據每個對等節點的網際網路速度將整個梯度向量分成不同的部分:連線速度最快的對等節點聚合最大的部分。此外,如果某些節點不接受傳入連線,它們只會傳送資料進行聚合,但不會自己計算平均值。根據條件,這種自適應演算法可以很好地恢復已知的分散式深度學習演算法,並透過混合策略對其進行改進,如下所示。
自適應演算法的不同平均策略示例。
💡 分散式訓練的核心技術可在 Hivemind 中獲取。
檢視倉庫並學習如何在您自己的專案中使用此庫!
sahajBERT
一如既往,擁有設計良好的演算法框架並不意味著它在實踐中會按預期工作,因為某些假設在實際訓練執行中可能不成立。為了驗證這項技術的競爭效能並展示其潛力,我們組織了一次特殊的協作活動,以預訓練孟加拉語的掩碼語言模型。儘管孟加拉語是世界上第五大母語,但公開可用的掩碼語言模型 非常少,這強調了賦能社群的工具的重要性,為該領域帶來了大量機遇。
我們與 Neuropark 社群的真實志願者一起進行了這項實驗,並使用了公開可用的資料集(OSCAR 和維基百科),因為我們希望擁有一個完全可重現的示例,可以作為其他團隊的靈感。
架構
在我們的實驗中,我們選擇了ALBER(*一種精簡版 BERT*)——一種透過掩碼語言建模(MLM)和句子順序預測(SOP)進行預訓練的語言表示模型。我們選擇這種架構是因為權重共享使其引數效率非常高:例如,ALBERT-large 大約有 1800 萬個可訓練引數,在 GLUE 基準測試中的表現與大約有 1.08 億個權重的 BERT-base 相當。這意味著對等節點之間需要交換的資料更少,這在我們的設定中至關重要,因為它顯著加快了每次訓練迭代的速度。
💡 想了解更多關於ALBERT的資訊嗎?
論文
Transformer文件
分詞器
我們模型的第一塊被稱為*分詞器*,負責將原始文字轉換為詞彙表索引。因為我們訓練的是孟加拉語模型,與英語不是很相似,所以我們需要在分詞器中實現特定於語言的預處理。我們可以將其視為一系列操作
- **標準化:** 包括對原始文字資料的所有預處理操作。這是我們進行最多更改的步驟,因為刪除某些細節可能會改變文字的含義,也可能保持不變,這取決於語言。例如,標準ALBERT標準化器會刪除重音,而對於孟加拉語,我們需要保留它們,因為它們包含有關母音的資訊。因此,我們使用以下操作:NMT標準化、NFKC標準化、去除多個空格、孟加拉語中重複Unicode字元的同質化,以及小寫化。
- **預分詞**描述了分割輸入(例如,透過空格)以強制特定詞元邊界的規則。與原始工作一樣,我們選擇將空格保留在詞元之外。因此,為了區分單詞並避免出現多個單空格詞元,每個對應單詞開頭的詞元都以特殊字元“_”(U+2581)開頭。此外,我們將所有標點符號和數字與其他字元隔離,以精簡詞彙表。
- **分詞器建模:** 在此級別,文字被對映為詞彙表元素的序列。有幾種演算法可用於此目的,例如位元組對編碼(BPE)或Unigram,其中大多數需要從文字語料庫構建詞彙表。按照ALBERT的設定,我們使用**Unigram語言模型**方法,在OSCAR資料集的去重孟加拉語部分上訓練了一個包含32k個詞元的詞彙表。
- **後處理:** 分詞後,我們可能需要新增架構所需的幾個特殊標記,例如以特殊標記 `[CLS]` 開始序列或用特殊標記 `[SEP]` 分隔兩個段。由於我們的主要架構與原始 ALBERT 相同,我們保留了相同的後處理:具體來說,我們在每個示例的開頭新增一個 `[CLS]` 標記,並在兩個段之間和末尾新增一個 `[SEP]` 標記。
💡 瞭解更多關於 分詞器文件 中每個元件的資訊。
您可以透過執行以下程式碼重複使用我們的分詞器:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("neuropark/sahajBERT")
資料集
我們需要介紹的最後一件事是訓練資料集。正如您可能知道的,像 BERT 或 ALBERT 這樣的預訓練模型最大的優勢在於您不需要帶標註的資料集,而只需要大量的文字。為了訓練 sahajBERT,我們使用了 2021年3月20日的孟加拉語維基百科轉儲 和 OSCAR 的孟加拉語子集 (600MB + 6GB 的文字)。這兩個資料集都可以輕鬆地從 HF Hub 下載。
然而,載入整個資料集需要時間和儲存空間——這是我們的對等節點不一定擁有的。為了最大限度地利用參與者提供的資源,我們實施了**資料集流式傳輸**,這使得他們幾乎可以在加入網路後立即訓練模型。具體來說,資料集中的示例在訓練的同時進行並行下載和轉換。我們還可以打亂資料集,這樣我們的對等節點同時處理相同示例的可能性就很小。由於資料集沒有提前下載和預處理,從純文字到訓練示例所需的轉換(如下圖所示)都是即時完成的。
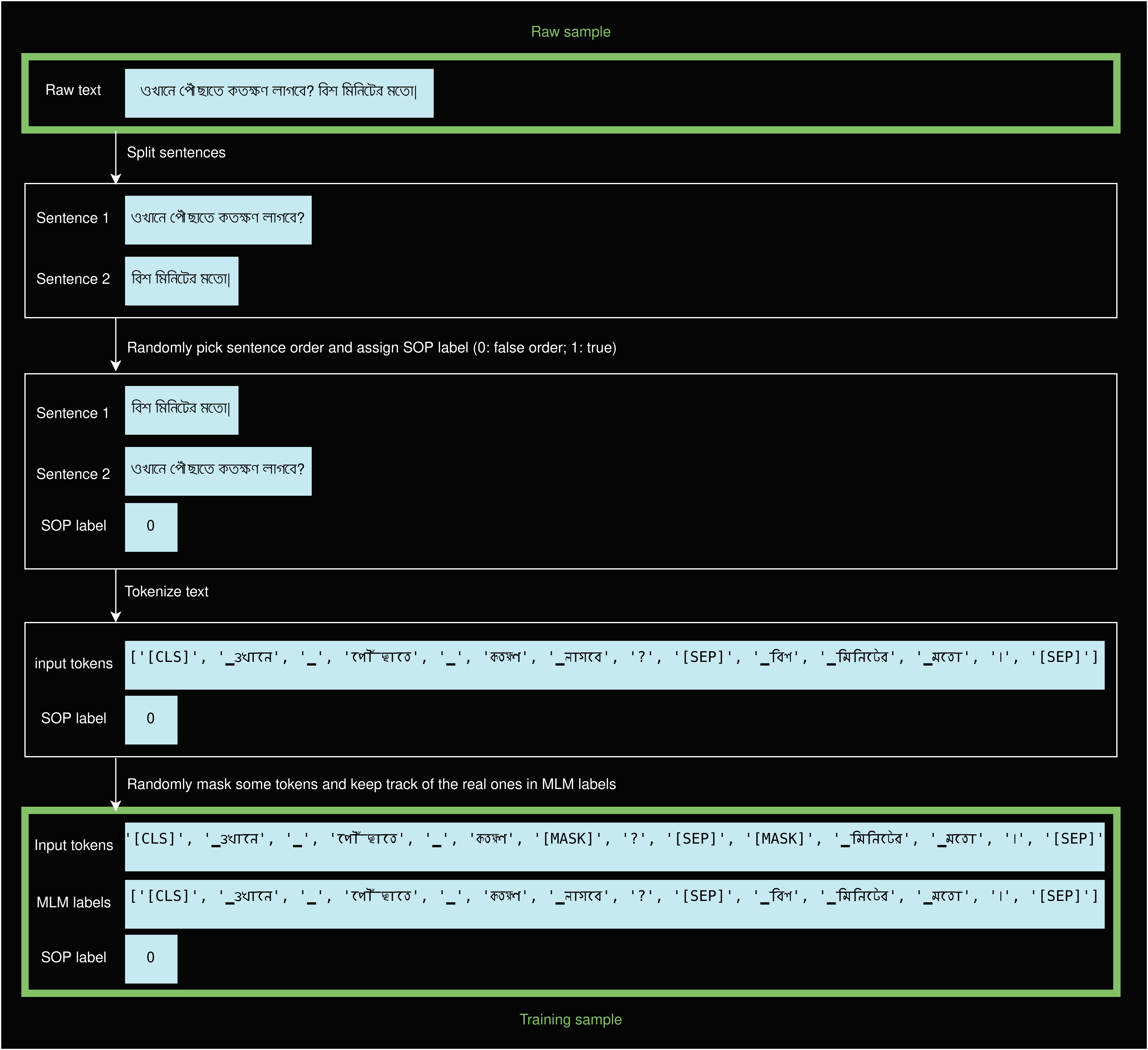
從原始樣本到訓練樣本
資料集流式傳輸模式在 🤗 資料集庫的 v1.9 版本中可用,所以您現在可以按以下方式使用它
from datasets import load_dataset
oscar_dataset = load_dataset("oscar", name="unshuffled_deduplicated_bn", streaming=True)
💡 在文件中瞭解更多關於流式載入資料集的資訊
協作活動
sahajBERT 協作訓練活動於5月12日至5月21日舉行。此次活動匯聚了40名參與者,其中30名是孟加拉語志願者,10名是其中一位作者所在組織的志願者。這40名志願者加入了 Neuropark Discord 頻道,以獲取有關該活動的所有資訊並參與討論。為了加入實驗,志願者被要求:
- 向版主傳送他們的使用者名稱以獲得白名單許可權;
- 在本地、Google Colaboratory 或 Kaggle 上開啟提供的 notebook;
- 執行一個程式碼單元格,並在提示時填寫他們的 Hugging Face 憑據;
- 在共享儀表板上觀察訓練損失的下降!
出於安全考慮,我們設定了授權系統,以便只有 Neuropark 社群成員才能訓練模型。撇開技術細節不談,我們的授權協議允許我們保證每個參與者都在白名單中,並認可每個對等節點的個人貢獻。
在下圖中,您可以看到每個志願者的活動。在實驗過程中,志願者登入了600個不同的會話。參與者定期並行啟動多個執行,其中許多人隨著時間的推移分散啟動的執行。個別參與者的執行平均持續4小時,最長持續21小時。您可以在論文中閱讀更多關於參與者統計資料的資訊。
顯示 sahajBERT 實驗參與者的圖表。圓圈半徑與處理的批次總數成比例,如果參與者不活躍,圓圈則變灰。每個紫色方塊代表一個活躍裝置,顏色越深表示效能越高。
除了參與者提供的資源外,我們還使用了 16 個可搶佔式(廉價但經常中斷)單 GPU T4 雲實例,以確保執行的穩定性。實驗的累計執行時間為 234 天,在下圖中您可以看到每個對等節點對損失曲線的貢獻部分!
最終模型已上傳至模型中心,如果您願意,可以下載並使用它:https://huggingface.co/neuropark/sahajBERT
評估
為了評估 sahajBERT 的效能,我們將其微調到兩個孟加拉語下游任務中:
- 在 WikiANN 的孟加拉語分支上進行命名實體識別 (NER)。此任務的目標是將輸入文字中的每個標記分類為以下類別之一:人物、組織、地點或 none。
- 在 IndicGLUE 中的 Soham 文章資料集上進行新聞類別分類 (NCC)。此任務的目標是預測輸入文字所屬的類別。
我們在訓練期間對 NER 任務進行了評估,以檢查一切是否順利;正如您在下面的圖中看到的,情況確實如此!
來自不同預訓練模型檢查點的微調模型在NER任務上的評估指標。
在訓練結束時,我們將 sahajBERT 與其他三個預訓練語言模型進行了比較:XLM-R Large、IndicBert 和 bnRoBERTa。在下表中,您可以看到我們的模型獲得了與 HF Hub 上最佳孟加拉語模型相當的結果,儘管我們的模型只有約 1800 萬個訓練引數,而例如 XLM-R(一個強大的多語言基線)擁有約 5.59 億個引數,並且在數百個 V100 GPU 上進行訓練。
| 模型 | NER F1(均值 ± 標準差) | NCC 準確率(均值 ± 標準差) |
|---|---|---|
| sahajBERT | 95.45 ± 0.53 | 91.97 ± 0.47 |
| XLM-R-大 | 96.48 ± 0.22 | 90.05 ± 0.38 |
| IndicBert | 92.52 ± 0.45 | 74.46 ± 1.91 |
| bnRoBERTa | 82.32 ± 0.67 | 80.94 ± 0.45 |
這些模型也可以在 Hub 上找到。您可以透過在它們的模型卡上使用託管推理 API 小部件,或者直接在您的 Python 程式碼中載入它們來測試它們。
sahajBERT-NER
模型卡片:https://huggingface.co/neuropark/sahajBERT-NER
from transformers import (
AlbertForTokenClassification,
TokenClassificationPipeline,
PreTrainedTokenizerFast,
)
# Initialize tokenizer
tokenizer = PreTrainedTokenizerFast.from_pretrained("neuropark/sahajBERT-NER")
# Initialize model
model = AlbertForTokenClassification.from_pretrained("neuropark/sahajBERT-NER")
# Initialize pipeline
pipeline = TokenClassificationPipeline(tokenizer=tokenizer, model=model)
raw_text = "এই ইউনিয়নে ৩ টি মৌজা ও ১০ টি গ্রাম আছে ।" # Change me
output = pipeline(raw_text)
sahajBERT-NCC
模型卡片:https://huggingface.co/neuropark/sahajBERT-NER
from transformers import (
AlbertForSequenceClassification,
TextClassificationPipeline,
PreTrainedTokenizerFast,
)
# Initialize tokenizer
tokenizer = PreTrainedTokenizerFast.from_pretrained("neuropark/sahajBERT-NCC")
# Initialize model
model = AlbertForSequenceClassification.from_pretrained("neuropark/sahajBERT-NCC")
# Initialize pipeline
pipeline = TextClassificationPipeline(tokenizer=tokenizer, model=model)
raw_text = "এই ইউনিয়নে ৩ টি মৌজা ও ১০ টি গ্রাম আছে ।" # Change me
output = pipeline(raw_text)
結論
在這篇博文中,我們討論了能夠實現神經網路協作預訓練的方法,sahajBERT 是將其應用於真實世界問題的第一個真正成功的例子。
這一切對更廣泛的機器學習社群意味著什麼?首先,現在可以與朋友一起進行大規模分散式預訓練,我們希望看到許多以前難以獲得的新穎模型。此外,我們的結果對於多語言 NLP 可能很重要,因為現在任何語言的社群都可以訓練自己的模型,而無需將大量計算資源集中在一個地方。
致謝
DeDLOC 論文和 sahajBERT 訓練實驗由 Michael Diskin、Alexey Bukhtiyarov、Max Ryabinin、Lucile Saulnier、Quentin Lhoest、Anton Sinitsin、Dmitry Popov、Dmitry Pyrkin、Maxim Kashirin、Alexander Borzunov、Albert Villanova del Moral、Denis Mazur、Ilia Kobelev、Yacine Jernite、Thomas Wolf 和 Gennady Pekhimenko 共同完成。該專案是 Hugging Face、Yandex Research、HSE University、MIPT、University of Toronto 和 Vector Institute 合作的成果。
此外,我們還要感謝 Stas Bekman、Dmitry Abulkhanov、Roman Zhytar、Alexander Ploshkin、Vsevolod Plokhotnyuk 和 Roman Kail 在構建訓練基礎設施方面提供的寶貴幫助。同時,我們感謝 Abhishek Thakur 在下游評估方面提供的幫助,以及 Tanmoy Sarkar 和 Omar Sanseviero,他們幫助我們組織了協作實驗,並在訓練過程中定期向參與者提供狀態更新。
下面是協作實驗的所有參與者
參考文獻
“開放協作中的分散式深度學習”,ArXiv
sahajBERT 實驗的程式碼在 DeDLOC 倉庫中。