在 🤗 Transformers 中使用約束集束搜尋引導文字生成







引言
本博文假設讀者熟悉使用不同集束搜尋變體的文字生成方法,相關解釋請參閱博文:“如何生成文字:在 Transformers 中使用不同解碼方法進行語言生成”
與普通的集束搜尋不同,約束集束搜尋允許我們對文字生成的輸出進行控制。這很有用,因為我們有時確切地知道我們希望輸出中包含什麼內容。例如,在神經機器翻譯任務中,我們可能透過查字典知道最終譯文必須包含哪些詞。有時,對於語言模型來說幾乎同樣可能的生成輸出,由於特定上下文的原因,對終端使用者來說可能並非同樣合意。這兩種情況都可以透過允許使用者告訴模型最終輸出必須包含哪些詞來解決。
為何如此困難
然而,這實際上是一個非常不簡單的問題。這是因為任務要求我們在最終輸出的某個位置、在生成的某個時間點強制生成某些子序列。
假設我們想生成一個句子 S,它必須包含短語 ,其中按順序包含詞元 。我們將期望的句子 定義為
問題在於集束搜尋是逐詞元生成序列的。雖然不完全準確,但可以將集束搜尋看作函式 ,它檢視當前從 到 已生成的詞元序列,然後預測在 位置的下一個詞元。但是這個函式如何能在任意步驟 時,知道必須在未來的某個步驟 生成這些詞元呢?或者當它在步驟 時,它如何能確定這是強制生成這些詞元的最佳位置,而不是在未來的某個步驟 呢?
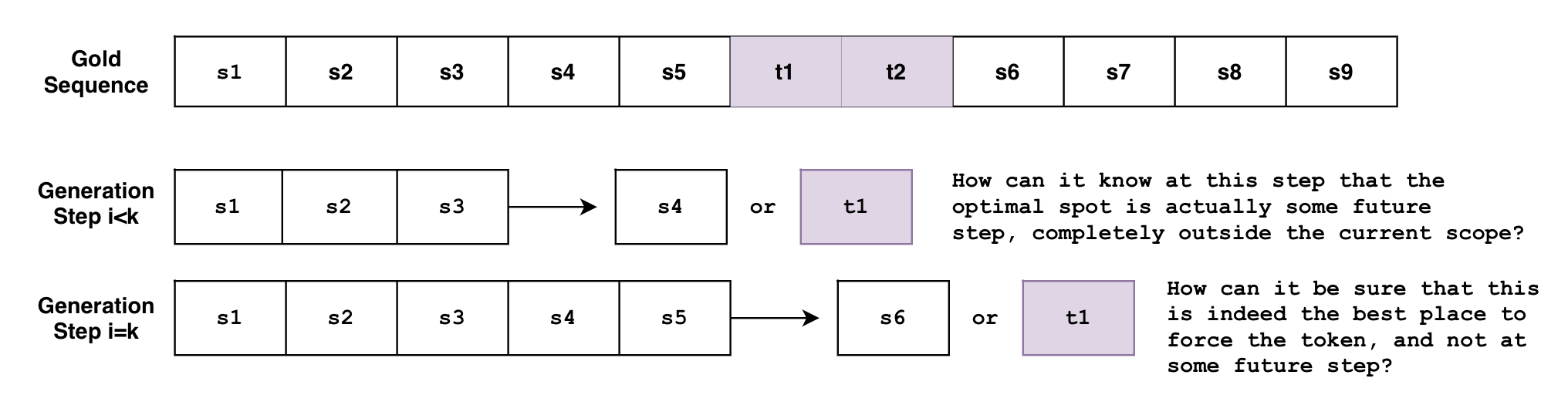
如果你有多個具有不同要求的約束怎麼辦?如果你想強制生成短語 和短語 呢?如果你想讓模型在這兩個短語之間選擇一個呢?如果我們想強制生成短語 ,並從短語列表 中強制生成一個短語呢?
以上這些例子實際上是非常合理的用例,下面將會展示,而新的約束集束搜尋功能允許所有這些操作!
本文將快速介紹新的約束集束搜尋功能能為你做什麼,然後深入探討其內部工作原理。
示例 1:強制生成一個詞
假設我們想把 "How old are you?" 翻譯成德語。
"Wie alt bist du?" 是非正式場合的說法,而 "Wie alt sind Sie?" 是正式場合的說法。
根據上下文,我們可能希望使用一種禮貌形式而不是另一種,但我們如何告訴模型這一點呢?
傳統的集束搜尋
以下是我們在傳統集束搜尋設定中進行文字翻譯的方式。
!pip install -q git+https://github.com/huggingface/transformers.git
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("t5-base")
model = AutoModelForSeq2SeqLM.from_pretrained("t5-base")
encoder_input_str = "translate English to German: How old are you?"
input_ids = tokenizer(encoder_input_str, return_tensors="pt").input_ids
outputs = model.generate(
input_ids,
num_beams=10,
num_return_sequences=1,
no_repeat_ngram_size=1,
remove_invalid_values=True,
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
Output:
----------------------------------------------------------------------------------------------------
Wie alt bist du?
使用約束集束搜尋
但如果我們知道我們想要正式的輸出而不是非正式的呢?如果我們根據先驗知識知道生成結果必須包含什麼,並且可以將其注入到生成過程中呢?
以下是現在可以使用 model.generate() 的 force_words_ids 關鍵字引數實現的功能
tokenizer = AutoTokenizer.from_pretrained("t5-base")
model = AutoModelForSeq2SeqLM.from_pretrained("t5-base")
encoder_input_str = "translate English to German: How old are you?"
force_words = ["Sie"]
input_ids = tokenizer(encoder_input_str, return_tensors="pt").input_ids
force_words_ids = tokenizer(force_words, add_special_tokens=False).input_ids
outputs = model.generate(
input_ids,
force_words_ids=force_words_ids,
num_beams=5,
num_return_sequences=1,
no_repeat_ngram_size=1,
remove_invalid_values=True,
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
Output:
----------------------------------------------------------------------------------------------------
Wie alt sind Sie?
如你所見,我們能夠利用關於期望輸出的先驗知識來引導生成。以前我們必須生成一堆可能的輸出,然後篩選出符合我們要求的。現在我們可以在生成階段就做到這一點。
示例 2:析取約束
我們上面提到了一個用例,我們知道最終輸出中要包含哪些詞。一個例子可能是在神經機器翻譯中使用字典查詢。
但如果我們不知道該使用哪種詞形,比如我們希望 ["raining", "rained", "rains", ...] 這樣的輸出同樣可能呢?更普遍地說,總有我們不想要逐字逐句完全相同的詞,而可能對其他相關的可能性持開放態度的情況。
允許這種行為的約束是析取約束,它允許使用者輸入一個詞列表,其目的是引導生成,使得最終輸出必須包含該詞列表中的至少一個。
以下是一個混合使用上述兩種約束型別的例子
from transformers import GPT2LMHeadModel, GPT2Tokenizer
model = GPT2LMHeadModel.from_pretrained("gpt2")
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
force_word = "scared"
force_flexible = ["scream", "screams", "screaming", "screamed"]
force_words_ids = [
tokenizer([force_word], add_prefix_space=True, add_special_tokens=False).input_ids,
tokenizer(force_flexible, add_prefix_space=True, add_special_tokens=False).input_ids,
]
starting_text = ["The soldiers", "The child"]
input_ids = tokenizer(starting_text, return_tensors="pt").input_ids
outputs = model.generate(
input_ids,
force_words_ids=force_words_ids,
num_beams=10,
num_return_sequences=1,
no_repeat_ngram_size=1,
remove_invalid_values=True,
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
print(tokenizer.decode(outputs[1], skip_special_tokens=True))
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Output:
----------------------------------------------------------------------------------------------------
The soldiers, who were all scared and screaming at each other as they tried to get out of the
The child was taken to a local hospital where she screamed and scared for her life, police said.
如你所見,第一個輸出使用了 "screaming",第二個輸出使用了 "screamed",並且兩者都逐字使用了 "scared"。可供選擇的列表 ["screaming", "screamed", ...] 不必是詞形變化;這可以滿足任何我們需要從詞列表中選擇一個的用例。
傳統的集束搜尋
以下是傳統集束搜尋的一個例子,摘自之前的一篇博文
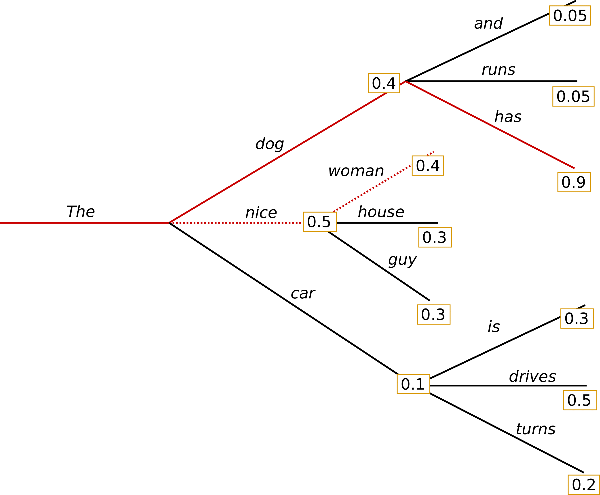
與貪婪搜尋不同,集束搜尋透過保留更長的假設列表來工作。在上圖中,我們展示了在生成的每個可能步驟中的三個可能的下一個詞元。
在 num_beams=3 的情況下,以下是看待上述示例集束搜尋第一步的另一種方式
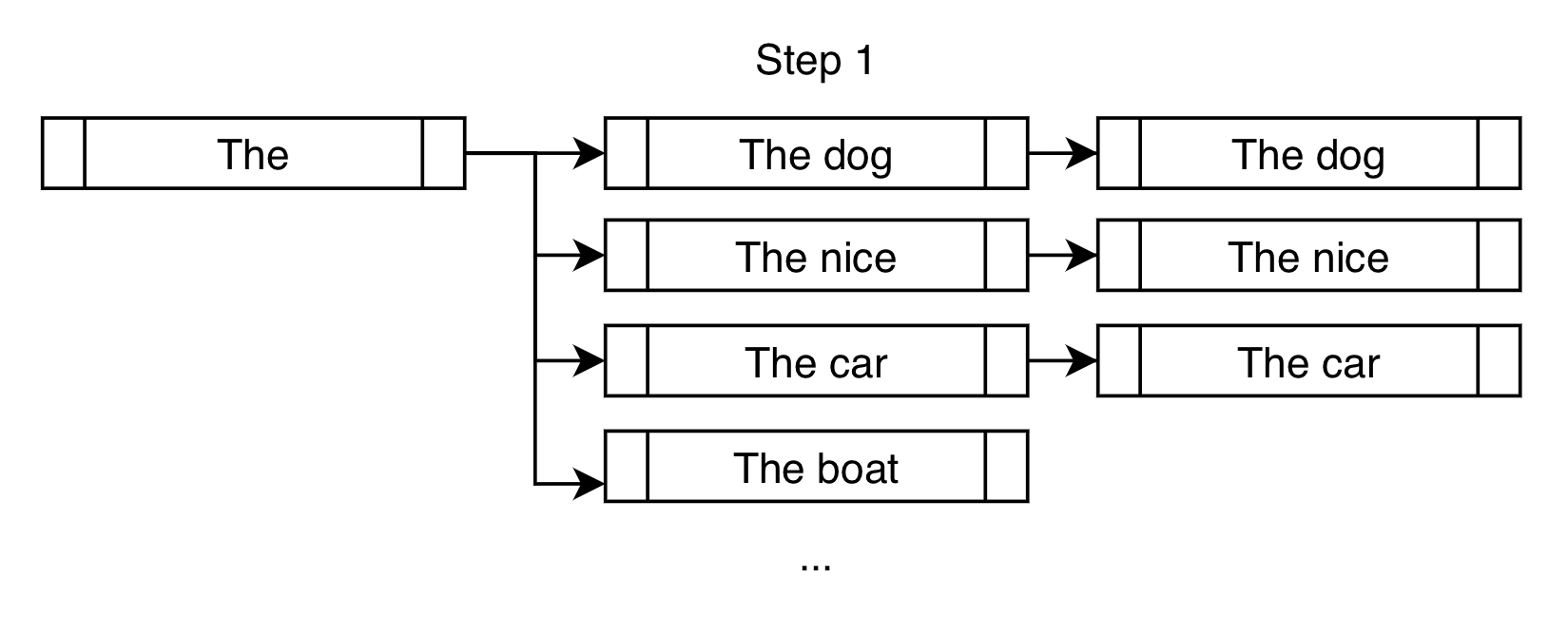
集束搜尋不會像貪婪搜尋那樣只選擇 "The dog",而是允許對 "The nice" 和 "The car" 進行進一步考慮。
在下一步中,我們為上一步建立的三個分支中的每一個考慮下一個可能的詞元。
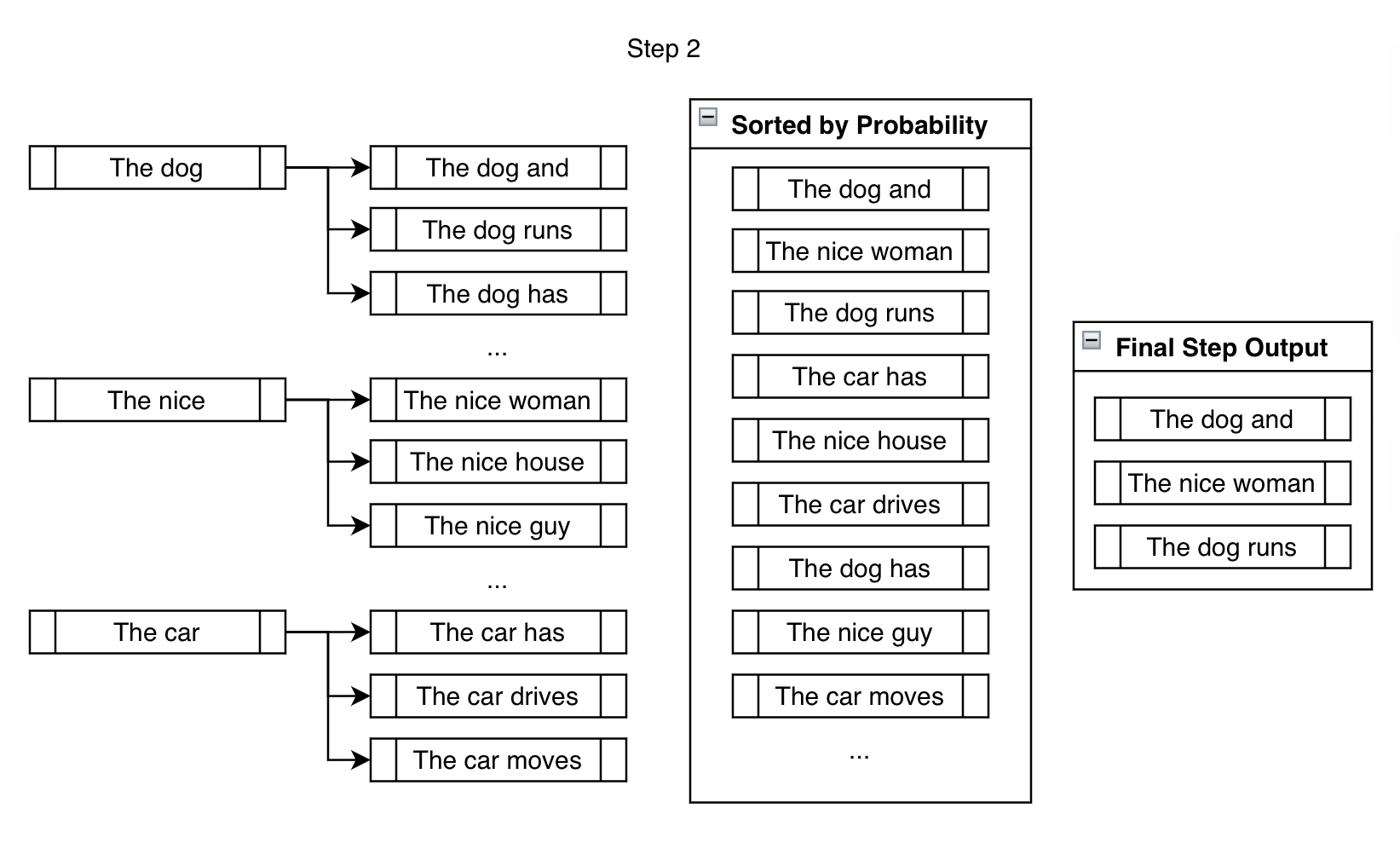
儘管我們最終考慮的輸出遠多於 num_beams,但在每一步結束時,我們會將它們減少到 num_beams。我們不能一直分支下去,否則我們需要跟蹤的 beams 數量將是 對於 步來說,這個數字會很快變得非常大( 個 beam 經過 步後是 個 beam!)。
在剩下的生成過程中,我們重複上述步驟,直到滿足結束條件,例如生成 <eos> 詞元或達到 max_length。分支、排序、縮減,然後重複。
約束集束搜尋
約束集束搜尋試圖透過在生成的每一步注入所需的詞元來滿足約束。
假設我們想在生成的輸出中強制包含短語 "is fast"。
在傳統的集束搜尋設定中,我們在每個分支找到機率最高的 k 個下一個詞元,並將它們加入考慮範圍。在約束設定中,我們做同樣的事情,但同時也會新增那些能讓我們更接近滿足約束的詞元。下面是一個演示
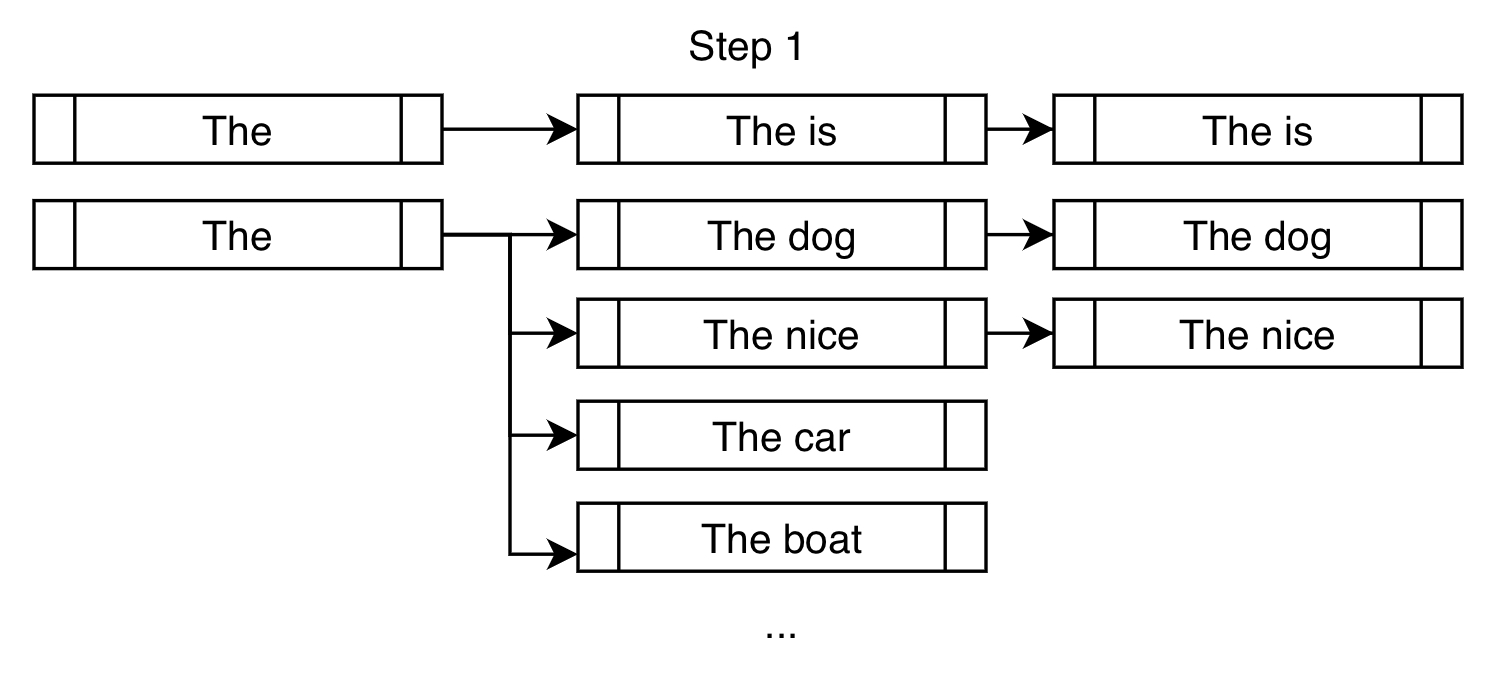
除了像 "dog" 和 "nice" 這樣常見的高機率下一個詞元之外,我們強制加入詞元 "is",以便更接近滿足我們 "is fast" 的約束。
在下一步中,下面分支出的候選詞元與傳統集束搜尋的大部分相同。但和上面的例子一樣,約束集束搜尋透過在每個新分支上強制約束來擴充套件現有候選詞元
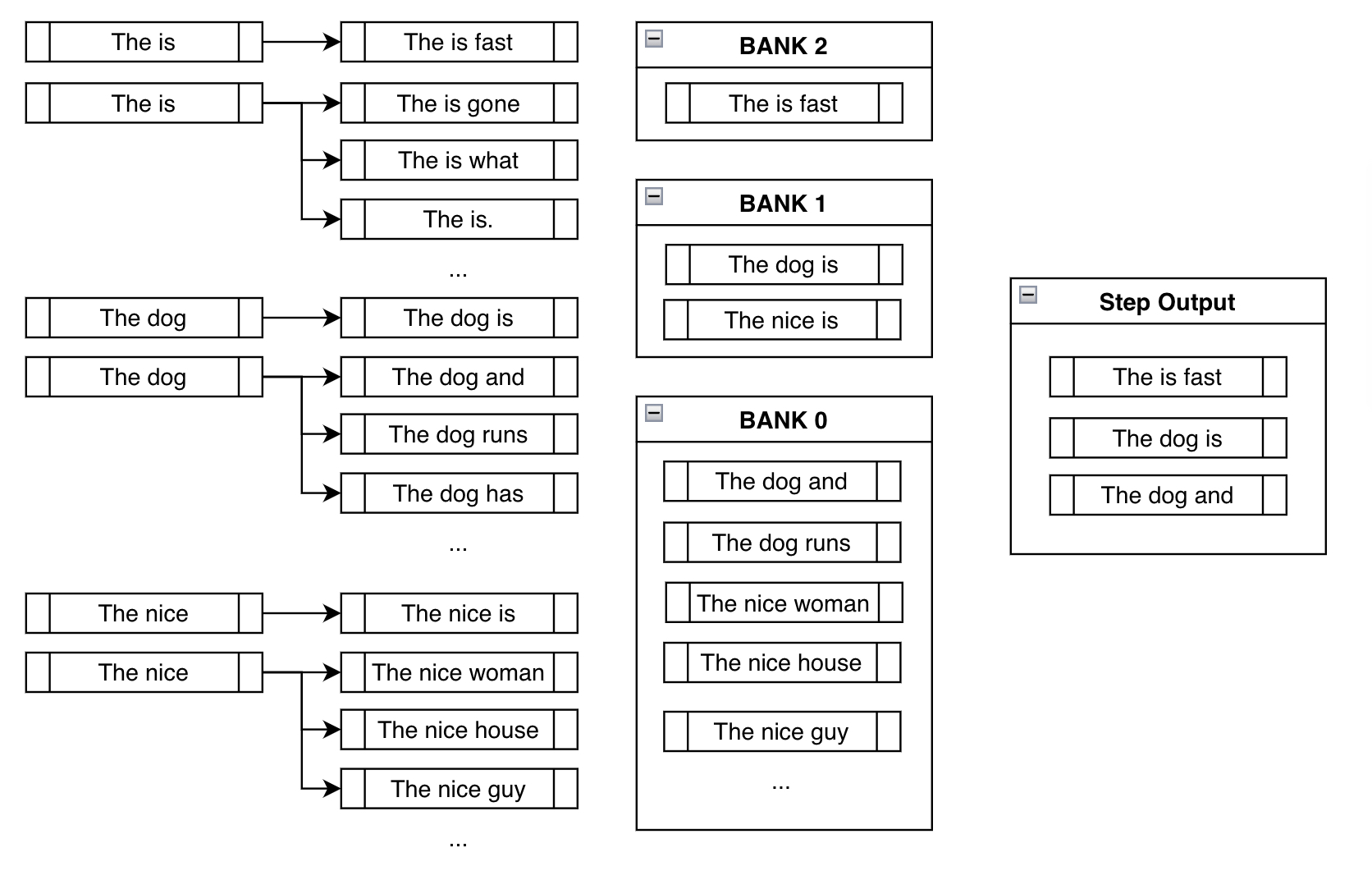
組 (Banks)
在討論下一步之前,我們需要考慮上一步中可能出現的不良行為。
簡單地在輸出中強制加入所需短語 "is fast" 的問題在於,大多數情況下,你會得到像上面 "The is fast" 這樣無意義的輸出。這實際上是使這個問題變得不簡單的原因。關於解決這個問題的複雜性的更深入討論,可以在 huggingface/transformers 中提出的原始功能請求 issue 中找到。
組 (Banks) 透過在滿足約束和建立合理輸出之間建立平衡來解決這個問題。
組 指的是在滿足約束方面取得了 步進展的 beam 列表。將所有可能的 beam 分配到各自的組後,我們進行輪詢選擇。在上面的例子中,我們會從組 2 中選擇機率最高的輸出,然後從組 1 中選擇機率最高的,再從組 0 中選擇一個,然後是組 2 中機率第二高的,組 1 中機率第二高的,依此類推。由於我們使用 num_beams=3,我們只需將上述過程重複三次,最終得到 ["The is fast", "The dog is", "The dog and"]。
這樣,即使我們強制模型考慮我們手動添加了所需詞元的分支,我們仍然會跟蹤其他可能更有意義的高機率序列。儘管 "The is fast" 完全滿足了我們的約束,但它並不是一個非常合理的短語。幸運的是,我們在未來的步驟中有 "The dog is" 和 "The dog and" 可用,希望它們能引匯出更合理的輸出。
這種行為在上述示例的第三步中得到了展示
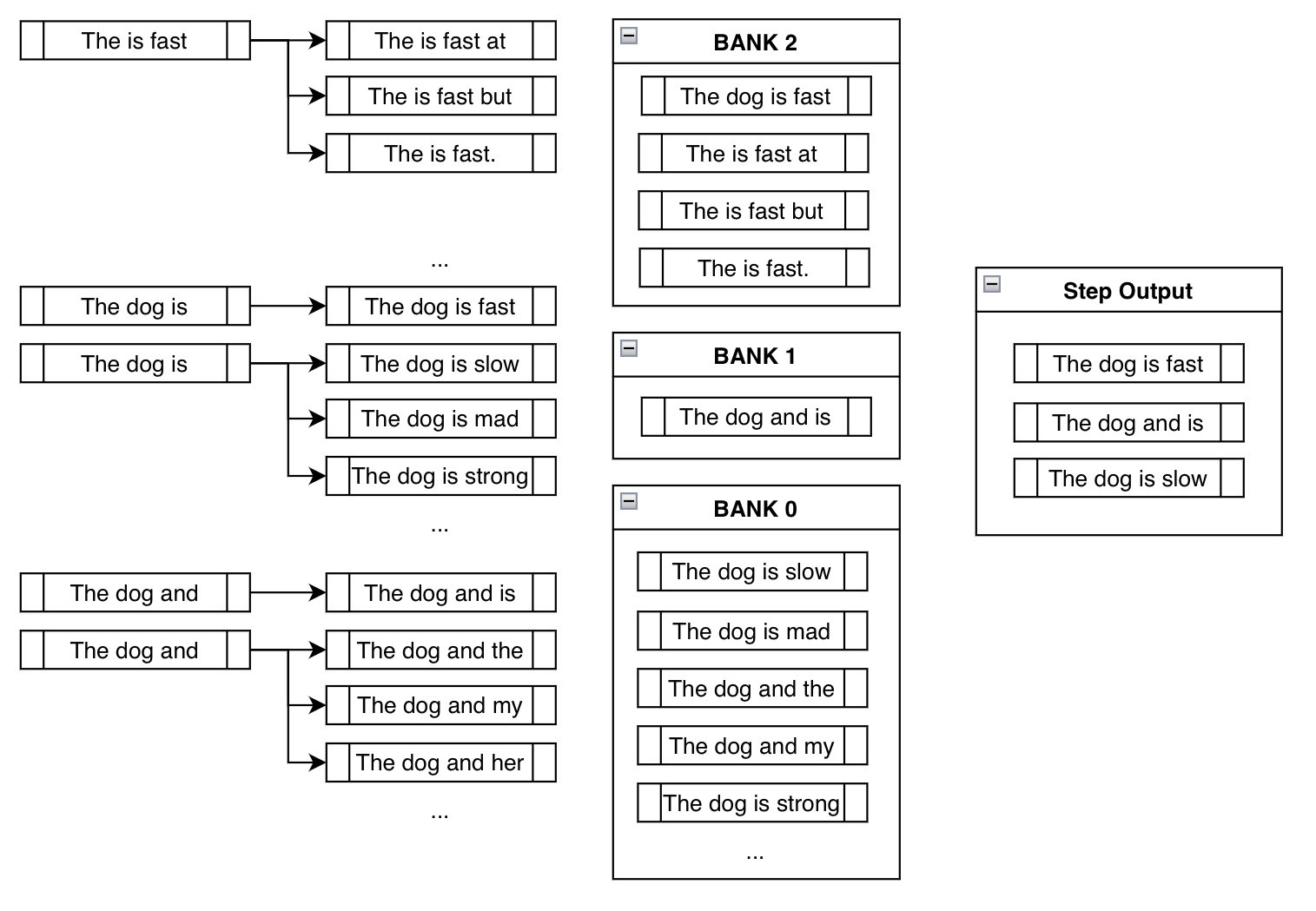
請注意 "The is fast" 不需要任何手動新增約束詞元,因為它已經滿足了約束(即,已包含短語 "is fast")。另外,請注意像 "The dog is slow" 或 "The dog is mad" 這樣的 beam 實際上在組 0 中,因為雖然它包含了詞元 "is",但它必須從頭開始才能生成 "is fast"。在 "is" 後面加上 "slow" 這樣的詞,實際上是重置了它的進展。
最後請注意,我們最終得到了一個包含我們約束短語的合理輸出:"The dog is fast"!
我們最初擔心盲目新增所需詞元會導致像 "The is fast" 這樣無意義的短語。然而,透過使用從組中輪詢選擇的方法,我們隱式地排除了無意義的輸出,而偏向於更合理的輸出。
更多關於 Constraint 類和自定義約束
這個解釋的主要 takeaways 可以總結如下。在每一步,我們不斷地“糾纏”模型,讓它考慮滿足我們約束的詞元,同時跟蹤那些不滿足約束的 beam,直到我們最終得到包含我們期望短語的、機率相當高的序列。
因此,設計這個實現的一個原則性方法是將每個約束表示為一個 Constraint 物件,其目的是跟蹤其進展並告訴集束搜尋接下來要生成哪些詞元。雖然我們為 model.generate() 提供了關鍵字引數 force_words_ids,但實際上在後端發生的是以下情況
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, PhrasalConstraint
tokenizer = AutoTokenizer.from_pretrained("t5-base")
model = AutoModelForSeq2SeqLM.from_pretrained("t5-base")
encoder_input_str = "translate English to German: How old are you?"
constraints = [
PhrasalConstraint(
tokenizer("Sie", add_special_tokens=False).input_ids
)
]
input_ids = tokenizer(encoder_input_str, return_tensors="pt").input_ids
outputs = model.generate(
input_ids,
constraints=constraints,
num_beams=10,
num_return_sequences=1,
no_repeat_ngram_size=1,
remove_invalid_values=True,
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
Output:
----------------------------------------------------------------------------------------------------
Wie alt sind Sie?
你可以自己定義一個並將其輸入到 constraints 關鍵字引數中,以設計你獨特的約束。你只需建立一個 Constraint 抽象介面類的子類,並遵循其要求。你可以在這裡找到 Constraint 的定義以獲取更多資訊。
一些獨特的想法(尚未實現;也許你可以試試!)包括像 OrderedConstraints、TemplateConstraints 這樣的約束,這些可能會在未來加入。目前,生成是透過在輸出的任何位置包含序列來完成的。例如,前面的一個例子中,一個序列是 scared -> screaming,另一個是 screamed -> scared。OrderedConstraints 可以允許使用者指定這些約束被滿足的順序。
TemplateConstraints 可以允許該功能更小眾的用法,其目標可以是這樣的
starting_text = "The woman"
template = ["the", "", "School of", "", "in"]
possible_outputs == [
"The woman attended the Ross School of Business in Michigan.",
"The woman was the administrator for the Harvard School of Business in MA."
]
或者
starting_text = "The woman"
template = ["the", "", "", "University", "", "in"]
possible_outputs == [
"The woman attended the Carnegie Mellon University in Pittsburgh.",
]
impossible_outputs == [
"The woman attended the Harvard University in MA."
]
或者如果使用者不關心兩個詞之間可以有多少個詞元,那麼可以直接使用 OrderedConstraint。
結論
約束集束搜尋為我們提供了一種靈活的方式,將外部知識和要求注入到文字生成中。以前,沒有簡單的方法告訴模型 1. 包含一個序列列表,其中 2. 一些是可選的,一些不是,以便 3. 它們在序列的某個位置以各自合理的位置生成。現在,我們可以透過混合使用不同子類的 Constraint 物件來完全控制我們的生成!
這個新功能主要基於以下論文
- 《使用約束集束搜尋的引導式開放詞彙影像描述》(Guided Open Vocabulary Image Captioning with Constrained Beam Search)
- 《用於神經機器翻譯的帶動態束分配的快速詞彙約束解碼》(Fast Lexically Constrained Decoding with Dynamic Beam Allocation for Neural Machine Translation)
- 《用於翻譯和單語重寫的改進詞彙約束解碼》(Improved Lexically Constrained Decoding for Translation and Monolingual Rewriting)
- 《因果關係的引導式生成》(Guided Generation of Cause and Effect)
像上面這些一樣,許多新的研究論文正在探索使用外部知識(例如知識圖譜、知識庫)來引導大型深度學習模型輸出的方法。希望這個約束集束搜尋功能能成為實現這一目標的又一個有效方法。
感謝所有為這個功能貢獻提供指導的人:Patrick von Platen,從最初的 issue 到最終的 PR 都參與其中,以及 Narsil Patry,為程式碼提供了詳細的反饋。
本帖縮圖使用了歸屬於以下來源的圖示:由 Freepik - Flaticon 建立的速記圖示





