隆重推出 🤗 Data Measurements Tool:一個用於檢視資料集的互動式工具



tl;dr: 我們開發了一個可以線上使用、用於構建、測量和比較資料集的工具。
點選此處訪問 🤗 Data Measurements Tool。
作為快速增長的機器學習資料集統一儲存庫的開發者(Lhoest 等人,2021),🤗 Hugging Face 團隊一直致力於支援資料集文件的良好實踐(McMillan-Major 等人,2021)。雖然靜態(如果不斷發展)文件代表了這一方向的必要第一步,但要很好地瞭解資料集的實際內容,需要有充分理由的測量以及與之互動的能力,動態視覺化感興趣的不同方面。
為此,我們推出了一款名為 🤗 Data Measurements Tool 的開源 Python 庫和無程式碼介面,它結合了我們的 Dataset 和 Spaces Hubs 以及出色的 Streamlit 工具。該工具可用於幫助理解、構建、管理和比較資料集。
什麼是 🤗 Data Measurements Tool?
Data Measurements Tool (DMT) 是一個互動式介面和開源庫,它允許資料集建立者和使用者自動計算對於負責任的資料開發有意義和有用的指標。
我們為什麼要建立這個工具?
在人工智慧開發中,對機器學習資料集的深思熟慮的策劃和分析常常被忽視。目前人工智慧中“大資料”的規範(Luccioni 等人,2021,Dodge 等人,2021)包括使用從各種網站抓取的資料,很少或根本不關注不同資料來源代表的具體測量,也不關注它們可能如何影響模型學習內容的細節。儘管資料集標註方法有助於整理更符合開發者目標的資料集,但“測量”這些資料集不同方面的方法相當有限(Sambasivan 等人,2021)。
人工智慧領域的新一波研究呼籲,從根本上改變該領域處理機器學習資料集的方式(Paullada 等人,2020,Denton 等人,2021)。這包括從一開始就定義資料集建立的細粒度要求(Hutchinson 等人,2021),根據問題內容和偏見問題策劃資料集(Yang 等人,2020,Prabhu 和 Birhane,2020),並明確資料集構建和維護中固有的價值觀(Scheuerman 等人,2021,Birhane 等人,2021)。儘管人們普遍認為資料集開發是一項應由許多不同學科的人員參與的任務,但實際上,與原始資料本身進行互動時常常存在瓶頸,因為這通常需要複雜的編碼技能才能分析和查詢資料集。
儘管如此,目前公開可用的工具很少,無法讓不同學科的人員測量、查詢和比較資料集。我們旨在幫助填補這一空白。我們借鑑了諸如 Know Your Data 和 Data Quality for AI 等最新工具,以及資料集文件的研究提案,例如 Vision and Language Datasets (Ferraro 等人,2015)、Datasheets for Datasets (Gebru 等人,2018) 和 Data Statements (Bender & Friedman 2019)。結果是一個用於資料集測量的開源庫,以及一個用於詳細資料集分析的配套無程式碼介面。
我何時可以使用 🤗 Data Measurements Tool?
🤗 Data Measurements Tool 可用於迭代探索一個或多個現有 NLP 資料集,並且很快將支援從頭開始迭代開發資料集。它提供了根據資料集研究和負責任的資料集開發而形成的實用見解,使使用者能夠深入瞭解高階資訊和特定專案。
使用 🤗 Data Measurements Tool 我能學到什麼?
資料集基礎知識
對資料集進行高層次概覽
這開始回答“這個資料集是什麼?它是否有缺失項?”之類的問題。你可以將其用作“健全性檢查”,以確保你正在處理的資料集符合你的預期。
資料集描述(來自 Hugging Face Hub)
缺失值或 NaN 的數量
描述性統計
檢視資料集的表面特徵
這開始回答“這個資料集包含什麼樣的語言?它的多樣性如何?”之類的問題。
資料集詞彙量大小和詞語分佈,包括開放類詞和封閉類詞。
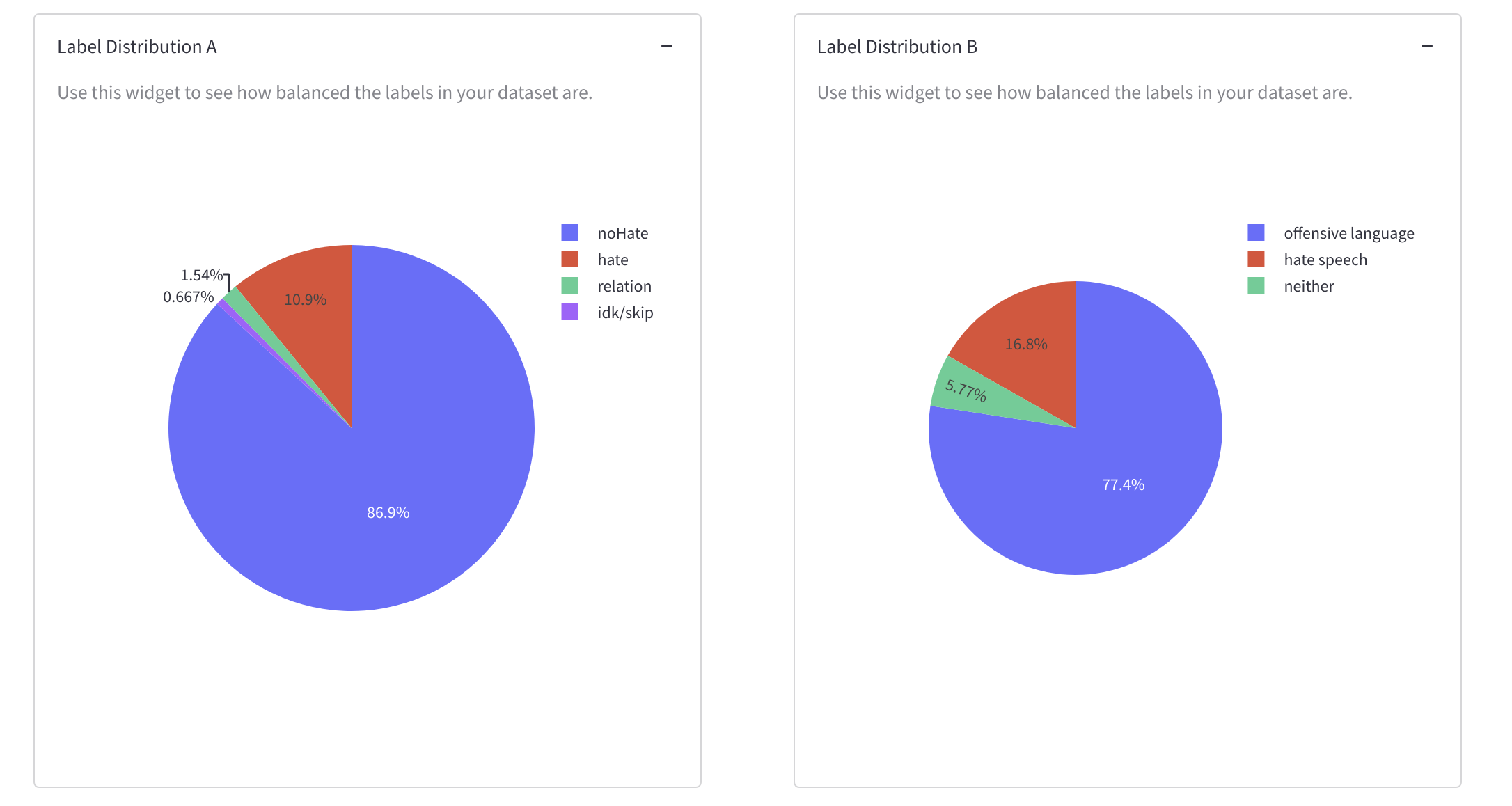
資料集標籤分佈和關於類別(不)平衡的資訊。
例項長度的平均值、中位數、範圍和分佈。
資料集中重複項的數量及其重複次數。
你可以使用這些小部件來檢查資料集中出現最多和最少的內容是否符合資料集的目標。這些測量旨在告知資料集是否能有效捕捉多種上下文,或者其捕捉範圍是否更受限,並測量標籤和例項長度的“平衡”程度。你還可以使用這些小部件來識別你可能希望刪除的異常值和重複項。
分佈統計
測量資料集中的語言模式
這開始回答“這個資料集中的語言行為如何?”之類的問題。
- 對齊普夫定律的遵循程度,該定律測量資料集中單詞的分佈與自然語言中單詞預期分佈的接近程度。
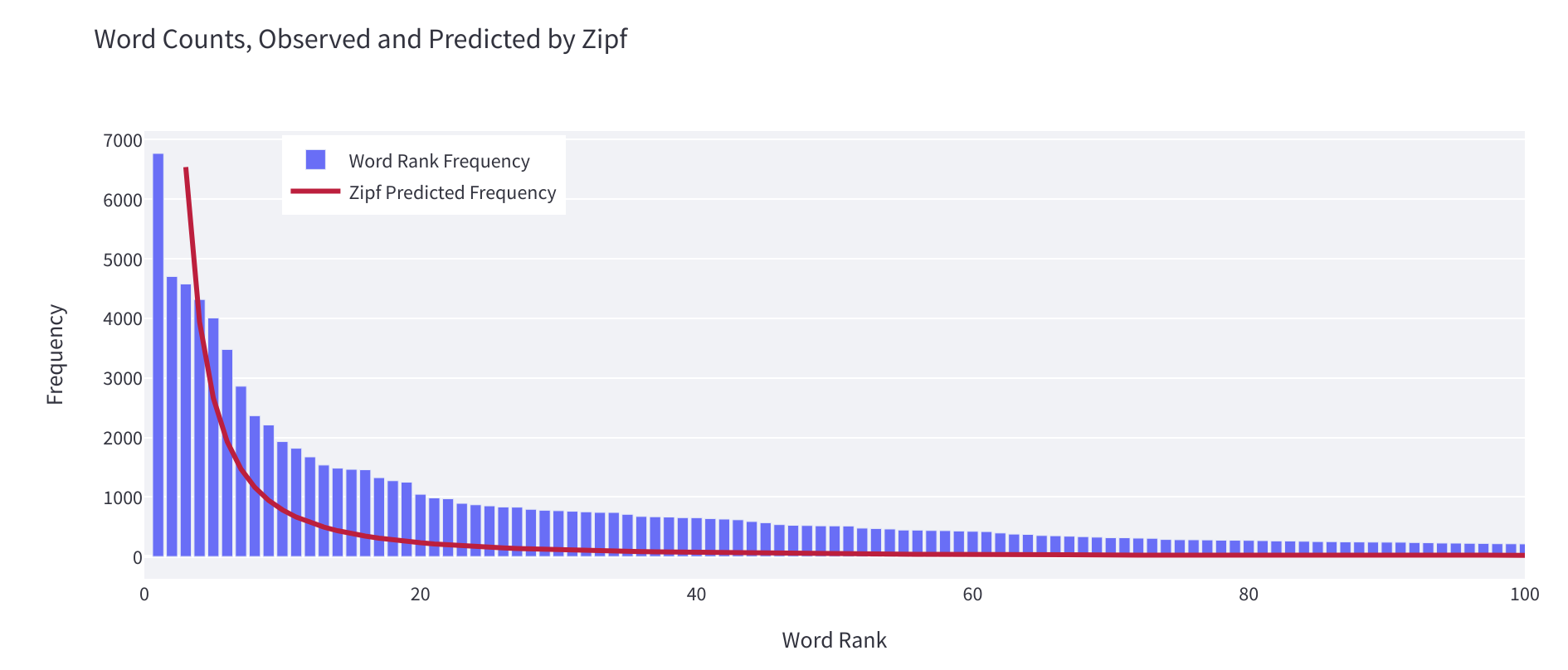
你可以用它來判斷你的資料集是否代表了自然界中語言的典型行為,或者是否存在一些不自然的地方。如果你喜歡最佳化,那麼你可以將這個小部件計算出的 alpha 值視為在資料集開發過程中儘可能接近 1 的值。關於不同語言中遵循齊普夫定律的 alpha 值的更多細節可在此處找到。
一般來說,如果 alpha 大於 2 或最小排名大於 10(僅供參考),則意味著你的分佈對於自然語言來說相對不自然。這可能是資料集中混合了偽影(例如 HTML 標記)的跡象。你可以使用這些資訊來清理資料集,或者指導你確定應如何分佈新增到資料集中的進一步語言。
比較統計
這開始回答“這個資料集中有哪些主題、偏見和關聯?”之類的問題。
嵌入聚類以確定資料集中任何相似語言的聚類。當資料集由成百上千個句子組成時,理解其中表示的文字多樣性可能具有挑戰性。根據相似性度量對這些文字項進行分組可以幫助使用者瞭解它們的分佈。我們展示了資料集中文字欄位的層次聚類,該聚類基於 Sentence-Transformer 模型和最大點積 單鏈接準則。要探索這些聚類,你可以:
- 將滑鼠懸停在節點上以檢視 5 個最具代表性的示例(已去重)
- 在文字框中輸入一個示例,以檢視它與哪個葉子聚類最相似
- 按 ID 選擇一個聚類以顯示其所有示例
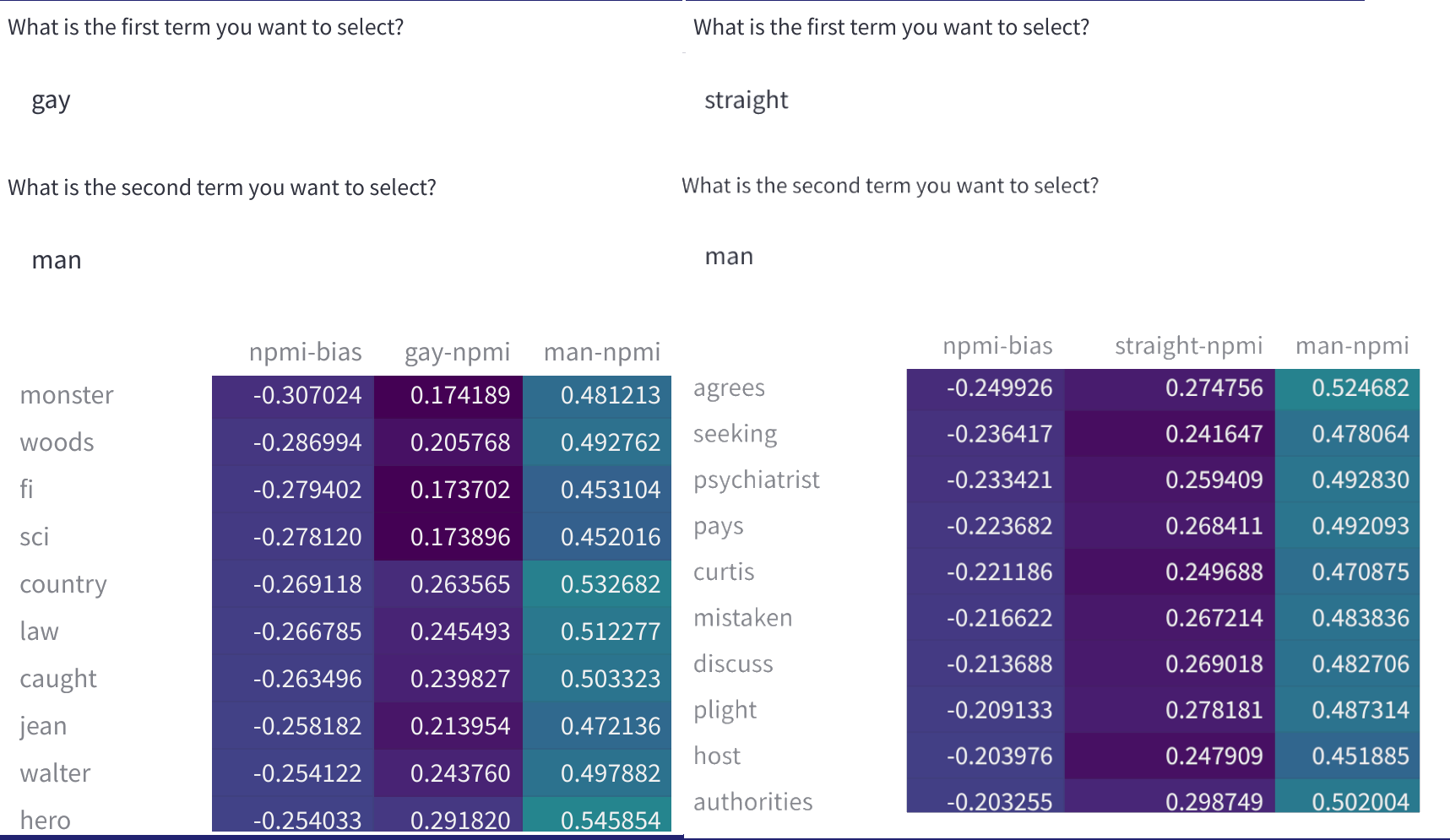
資料集中詞對之間的標準化點互資訊 (nPMI),可用於識別有問題的刻板印象。你可以將其用作處理資料集“偏見”的工具,這裡的“偏見”指的是針對性別和性取向等身份群體的刻板印象和偏見。我們將在不久的將來新增更多術語。
🤗 Data Measurements Tool 的開發狀態如何?
我們目前展示了該工具的 alpha 版本 (v0),演示了它在 Dataset Hub 上可用的一些流行英語資料集(例如 SQuAD、imdb、C4 等)上的實用性,並提供了上述功能。我們為 nPMI 視覺化選擇的詞彙是我們正在使用的資料集中頻繁出現的身份術語的子集。
在未來幾周和幾個月內,我們將擴充套件該工具以:
- 涵蓋 🤗 Datasets 庫中更多語言和資料集。
- 為使用者提供資料集和迭代資料集構建的支援。
- 為工具本身新增更多特性和功能。例如,我們將支援為 nPMI 視覺化新增您自己的術語,以便您可以選擇對您最重要的詞彙。
致謝
感謝 Thomas Wolf 發起了這項工作,以及 🤗 團隊的其他成員(Quentin、Lewis、Sylvain、Nate、Julien C.、Julien S.、Clément、Omar 和許多其他人!)提供的幫助和支援。