在Hugging Face上推出決策Transformer 🤗








在Hugging Face,我們正在為深度強化學習的研究人員和愛好者做出貢獻。最近,我們集成了深度強化學習框架,例如 Stable-Baselines3。
今天我們很高興地宣佈,我們將離線強化學習方法 決策Transformer 整合到 🤗 transformers 庫和 Hugging Face Hub 中。我們有一些激動人心的計劃,旨在提高深度強化學習領域的可訪問性,我們期待在未來幾周和幾個月內與大家分享這些計劃。
什麼是離線強化學習?
深度強化學習(RL)是一個用於構建決策代理的框架。這些代理旨在透過試錯與環境互動,並接收獎勵作為獨特反饋來學習最優行為(策略)。
代理的目標是最大化其**累積獎勵,稱為回報。**因為強化學習是基於獎勵假設的:**所有目標都可以描述為最大化預期累積獎勵。**
深度強化學習代理**透過批次經驗學習。**問題是,它們如何收集經驗?
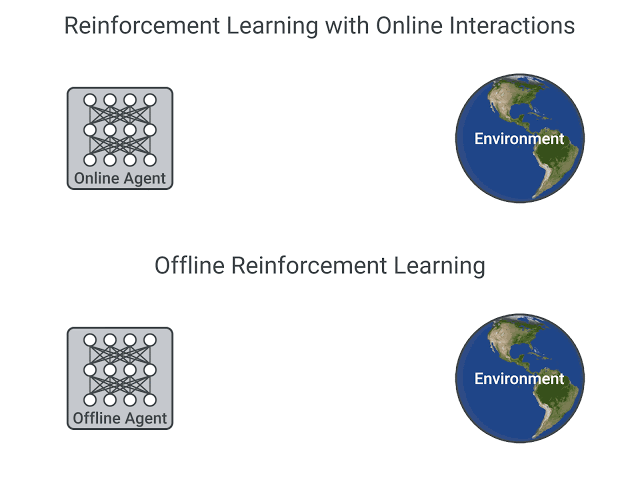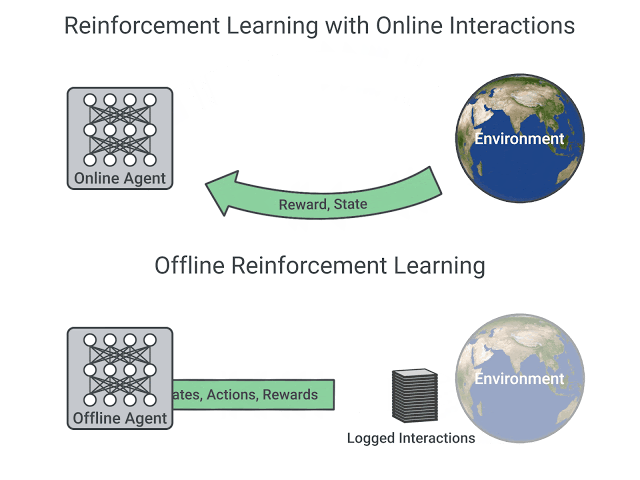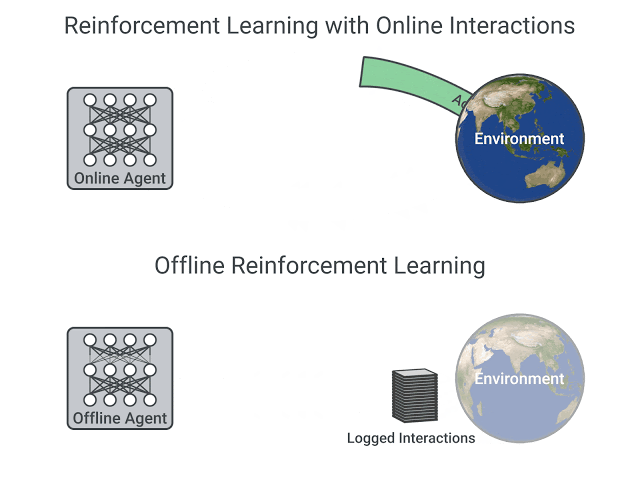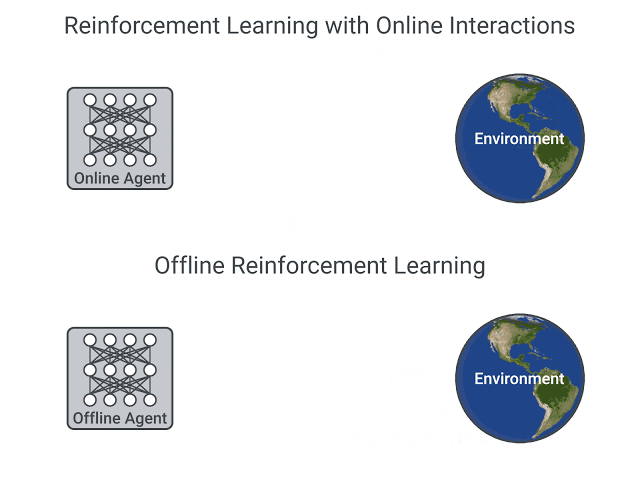
線上和離線強化學習的比較,圖片摘自 這篇文章
線上強化學習中,**代理直接收集資料**:它透過與環境互動收集一批經驗。然後,它立即(或透過某些回放緩衝區)使用這些經驗從中學習(更新其策略)。
但這暗示著您要麼直接在現實世界中訓練您的代理,要麼擁有一個模擬器。如果您沒有模擬器,則需要構建一個,這可能非常複雜(如何在一個環境中反映現實世界的複雜性?),昂貴且不安全,因為如果模擬器有缺陷,代理會利用這些缺陷以獲得競爭優勢。
另一方面,在離線強化學習中,代理只使用從其他代理或人類演示中收集的資料。**它不與環境互動**。
過程如下:
- 使用一個或多個策略和/或人類互動建立資料集。
- 在此資料集上執行離線強化學習以學習策略
這種方法有一個缺點:反事實查詢問題。如果我們的代理決定做一些我們沒有資料的事情怎麼辦?例如,在十字路口右轉,但我們沒有這條軌跡資料。
關於這個主題已經存在一些解決方案,但如果你想了解更多關於離線強化學習的資訊,你可以觀看 這個影片
介紹決策Transformer
決策Transformer模型由L. Chen等人發表的《決策Transformer:透過序列建模進行強化學習》一文引入。它將強化學習抽象為**條件序列建模問題**。
核心思想是,我們不使用RL方法(例如擬合價值函式)來訓練策略,從而告訴我們採取什麼行動才能最大化回報(累積獎勵),而是使用序列建模演算法(Transformer)。該演算法在給定期望回報、過去狀態和行動的情況下,生成未來的行動以實現期望回報。它是一個自迴歸模型,以期望回報、過去狀態和行動為條件,生成實現期望回報的未來行動。
這完全改變了強化學習的正規化,因為我們使用生成軌跡建模(建模狀態、動作和獎勵序列的聯合分佈)來取代傳統的RL演算法。這意味著在決策Transformer中,我們不最大化回報,而是生成一系列未來動作以實現期望的回報。
這個過程是這樣的
- 我們向決策Transformer輸入最後 K 個時間步,包含 3 種輸入:
- 剩餘回報
- 狀態
- 行動
- 如果狀態是向量,則使用線性層嵌入token;如果是幀,則使用CNN編碼器。
- 輸入由GPT-2模型處理,該模型透過自迴歸建模預測未來的動作。
 決策Transformer架構。狀態、動作和回報被輸入到特定模態的線性嵌入層,並新增位置性劇集時間步編碼。Token被送入GPT架構,該架構使用因果自注意力掩碼自迴歸地預測動作。圖片來自[1]。
決策Transformer架構。狀態、動作和回報被輸入到特定模態的線性嵌入層,並新增位置性劇集時間步編碼。Token被送入GPT架構,該架構使用因果自注意力掩碼自迴歸地預測動作。圖片來自[1]。
在 🤗 Transformers 中使用決策Transformer
決策Transformer模型現已作為 🤗 transformers 庫的一部分提供。此外,我們還分享了 Gym 環境中連續控制任務的九個預訓練模型檢查點。
一個“專家”決策Transformer模型,使用離線強化學習在Gym Walker2d環境中學習。
安裝包
pip install git+https://github.com/huggingface/transformers
載入模型
使用決策Transformer相對容易,但由於它是一個自迴歸模型,因此在每個時間步準備模型輸入時需要注意。我們準備了 Python 指令碼 和 Colab Notebook 來演示如何使用此模型。
在 🤗 transformers 庫中載入預訓練的決策Transformer非常簡單
from transformers import DecisionTransformerModel
model_name = "edbeeching/decision-transformer-gym-hopper-expert"
model = DecisionTransformerModel.from_pretrained(model_name)
建立環境
我們為 Gym Hopper、Walker2D 和 Halfcheetah 提供了預訓練的檢查點。Atari 環境的檢查點也將很快提供。
import gym
env = gym.make("Hopper-v3")
state_dim = env.observation_space.shape[0] # state size
act_dim = env.action_space.shape[0] # action size
自迴歸預測函式
該模型執行自迴歸預測;也就是說,當前時間步**t**的預測會依次依賴於前一時間步的輸出。這個函式相當複雜,所以我們將在註釋中進行解釋。
# Function that gets an action from the model using autoregressive prediction
# with a window of the previous 20 timesteps.
def get_action(model, states, actions, rewards, returns_to_go, timesteps):
# This implementation does not condition on past rewards
states = states.reshape(1, -1, model.config.state_dim)
actions = actions.reshape(1, -1, model.config.act_dim)
returns_to_go = returns_to_go.reshape(1, -1, 1)
timesteps = timesteps.reshape(1, -1)
# The prediction is conditioned on up to 20 previous time-steps
states = states[:, -model.config.max_length :]
actions = actions[:, -model.config.max_length :]
returns_to_go = returns_to_go[:, -model.config.max_length :]
timesteps = timesteps[:, -model.config.max_length :]
# pad all tokens to sequence length, this is required if we process batches
padding = model.config.max_length - states.shape[1]
attention_mask = torch.cat([torch.zeros(padding), torch.ones(states.shape[1])])
attention_mask = attention_mask.to(dtype=torch.long).reshape(1, -1)
states = torch.cat([torch.zeros((1, padding, state_dim)), states], dim=1).float()
actions = torch.cat([torch.zeros((1, padding, act_dim)), actions], dim=1).float()
returns_to_go = torch.cat([torch.zeros((1, padding, 1)), returns_to_go], dim=1).float()
timesteps = torch.cat([torch.zeros((1, padding), dtype=torch.long), timesteps], dim=1)
# perform the prediction
state_preds, action_preds, return_preds = model(
states=states,
actions=actions,
rewards=rewards,
returns_to_go=returns_to_go,
timesteps=timesteps,
attention_mask=attention_mask,
return_dict=False,)
return action_preds[0, -1]
評估模型
為了評估模型,我們需要一些額外的資訊;訓練期間使用的狀態的均值和標準差。幸運的是,這些資訊可以在Hugging Face Hub上每個檢查點的模型卡中找到!
我們還需要一個模型的目標回報。這就是回報條件離線強化學習的強大之處:我們可以使用目標回報來控制策略的效能。這在多人設定中可能非常有用,我們可以根據玩家的難度調整對手機器人的效能。作者在他們的論文中展示了一個很好的圖表!
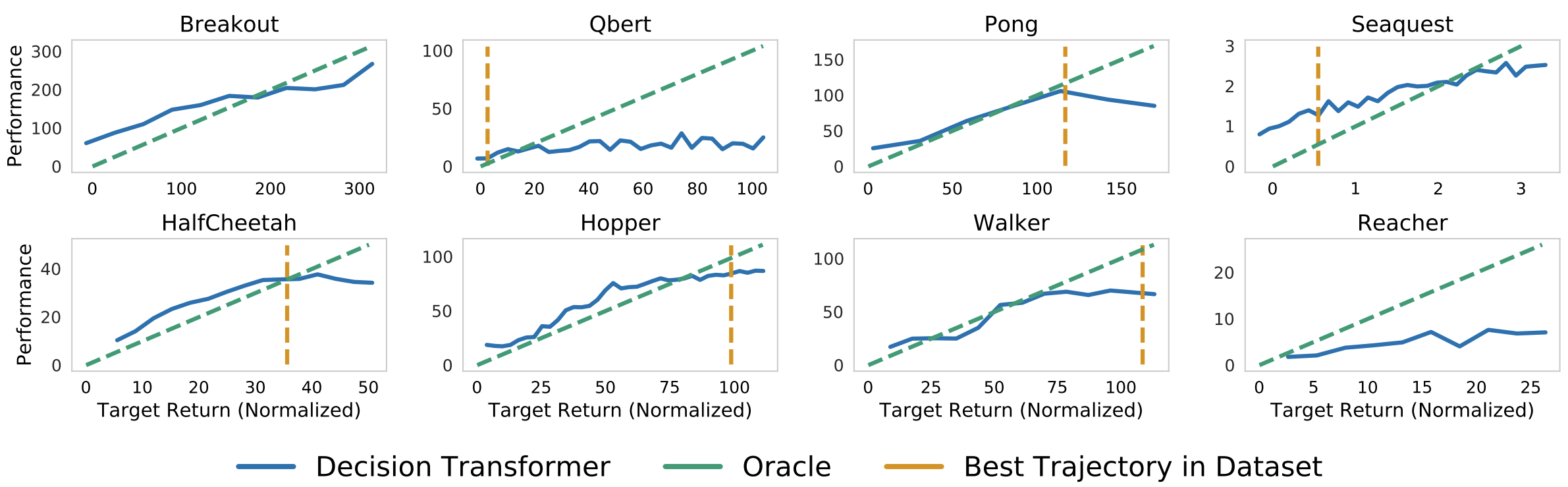 決策Transformer在給定目標(期望)回報條件下的取樣(評估)回報。上圖:Atari。下圖:D4RL medium-replay資料集。圖片來自[1]。
決策Transformer在給定目標(期望)回報條件下的取樣(評估)回報。上圖:Atari。下圖:D4RL medium-replay資料集。圖片來自[1]。
TARGET_RETURN = 3.6 # This was normalized during training
MAX_EPISODE_LENGTH = 1000
state_mean = np.array(
[1.3490015, -0.11208222, -0.5506444, -0.13188992, -0.00378754, 2.6071432,
0.02322114, -0.01626922, -0.06840388, -0.05183131, 0.04272673,])
state_std = np.array(
[0.15980862, 0.0446214, 0.14307782, 0.17629202, 0.5912333, 0.5899924,
1.5405099, 0.8152689, 2.0173461, 2.4107876, 5.8440027,])
state_mean = torch.from_numpy(state_mean)
state_std = torch.from_numpy(state_std)
state = env.reset()
target_return = torch.tensor(TARGET_RETURN).float().reshape(1, 1)
states = torch.from_numpy(state).reshape(1, state_dim).float()
actions = torch.zeros((0, act_dim)).float()
rewards = torch.zeros(0).float()
timesteps = torch.tensor(0).reshape(1, 1).long()
# take steps in the environment
for t in range(max_ep_len):
# add zeros for actions as input for the current time-step
actions = torch.cat([actions, torch.zeros((1, act_dim))], dim=0)
rewards = torch.cat([rewards, torch.zeros(1)])
# predicting the action to take
action = get_action(model,
(states - state_mean) / state_std,
actions,
rewards,
target_return,
timesteps)
actions[-1] = action
action = action.detach().numpy()
# interact with the environment based on this action
state, reward, done, _ = env.step(action)
cur_state = torch.from_numpy(state).reshape(1, state_dim)
states = torch.cat([states, cur_state], dim=0)
rewards[-1] = reward
pred_return = target_return[0, -1] - (reward / scale)
target_return = torch.cat([target_return, pred_return.reshape(1, 1)], dim=1)
timesteps = torch.cat([timesteps, torch.ones((1, 1)).long() * (t + 1)], dim=1)
if done:
break
您可以在我們的 Colab Notebook 中找到一個更詳細的示例,其中包括建立代理的影片。
結論
除了決策Transformer,我們還希望支援深度強化學習社群的更多用例和工具。因此,我們非常期待聽到您對決策Transformer模型的反饋,以及更普遍地,我們可以與您一起構建的任何對RL有用的東西。請隨時**與我們聯絡**。
接下來呢?
在未來幾周和幾個月內,我們計劃支援生態系統中的其他工具
- 整合**RL-baselines3-zoo**
- 上傳**RL-trained-agents模型**到Hub:使用stable-baselines3訓練的強化學習代理的大量集合
- 整合其他深度強化學習庫
- 實現用於Atari的卷積決策Transformer
- 更多精彩敬請期待🥳
保持聯絡的最佳方式是**加入我們的discord伺服器**,與我們和社群交流。
參考文獻
[1] Chen, Lili, et al. "決策Transformer:透過序列建模進行強化學習." 神經資訊處理系統進展 34 (2021)。
[2] Agarwal, Rishabh, Dale Schuurmans, and Mohammad Norouzi. "離線強化學習的樂觀展望." 國際機器學習會議. PMLR, 2020。
致謝
我們感謝論文的第一作者 Kevin Lu 和 Lili Chen 提供的建設性交流。


