加速文件 AI










企業中充滿了各種文件,其中包含的知識無法被數字化工作流程所獲取。這些文件種類繁多,從信件、發票、表格、報告到收據。隨著文字、視覺和多模態 AI 的進步,現在已經可以解鎖這些資訊。本文將向您展示,您的團隊如何利用開源模型免費構建定製化解決方案!
文件 AI 包含許多資料科學任務,例如 影像分類、影像到文字、文件問答、表格問答 和 視覺問答。本文首先對文件 AI 中的用例進行了分類,並介紹了適用於這些用例的最佳開源模型。接著,文章將重點討論授權許可、資料準備和建模。在整篇文章中,我們提供了指向 Web 演示、文件和模型的連結。
用例
構建文件 AI 解決方案至少有六種通用用例。這些用例在文件輸入和輸出的型別上有所不同。在解決企業級文件 AI 問題時,通常需要結合多種方法。
將列印、手寫或印刷的文字轉換為機器可編碼文字的過程稱為光學字元識別 (OCR)。這是一個被廣泛研究的問題,有許多成熟的開源和商業產品。下圖展示了一個將手寫體轉換為文字的例子。
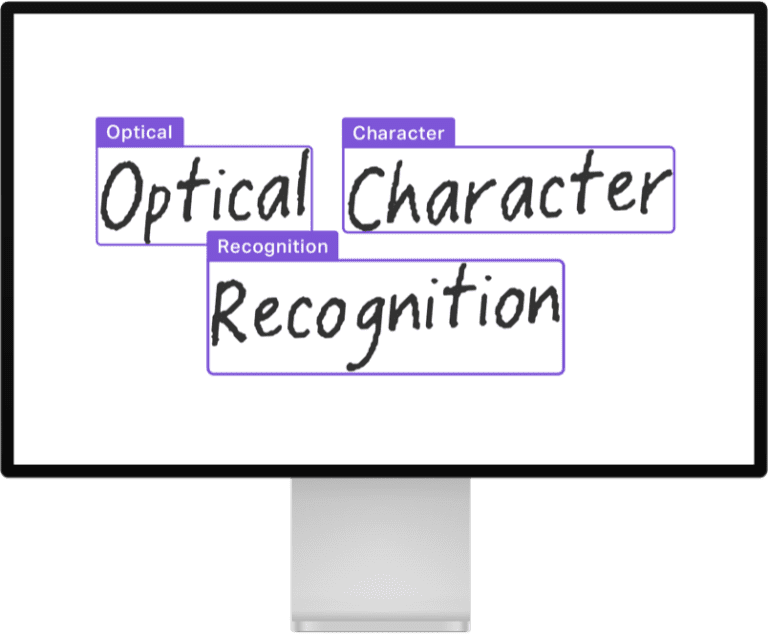
OCR 是文件 AI 用例的支柱,因為它對於將文字轉換為計算機可讀內容至關重要。一些廣泛使用的文件級 OCR 模型包括 EasyOCR 和 PaddleOCR。還有像 TrOCR: 基於 Transformer 的預訓練模型光學字元識別 這樣的模型,它可以在單行文字影像上執行。該模型與像 CRAFT 這樣的文字檢測模型配合使用,CRAFT 首先以邊界框的形式識別文件中各個“文字塊”。OCR 的相關指標是字元錯誤率 (CER) 和詞級的精確率、召回率及 F1 分數。可以檢視這個 Space 來了解 CRAFT 和 TrOCR 的演示。
將文件分類到適當的類別,如表格、發票或信件,稱為文件影像分類。分類可以只使用文件的影像或文字,也可以兩者都用。近期新增的多模態模型,它們同時利用視覺結構和底層文字,極大地提升了分類器的效能。
一種基本方法是在文件影像上應用 OCR,然後使用類似 BERT 的模型進行分類。然而,僅依賴 BERT 模型並未考慮任何佈局或視覺資訊。下圖來自 RVL-CDIP 資料集,展示了不同型別文件在視覺結構上的差異。

這時候,像 LayoutLM 和 Donut 這樣的模型就派上用場了。透過不僅結合文字,還結合視覺資訊,這些模型可以顯著提高準確性。作為比較,在重要的文件影像分類基準 RVL-CDIP 上,一個 BERT-base 模型透過使用文字可以達到 89% 的準確率。而 DiT (文件影像轉換器) 是一個純視覺模型 (即不將文字作為輸入),可以達到 92% 的準確率。但像 LayoutLMv3 和 Donut 這樣的模型,它們透過多模態 Transformer 同時使用文字和視覺資訊,可以達到 95% 的準確率!這些多模態模型正在改變從業者解決文件 AI 用例的方式。
文件佈局分析是確定文件物理結構的任務,即識別構成文件的各個基本構建塊,如文字段落、標題和表格。這個任務通常透過將其構建為影像分割/物件檢測問題來解決。模型會輸出一組分割掩碼/邊界框以及類別名稱。
目前在文件佈局分析方面最先進的模型是 LayoutLMv3 和 DiT (文件影像轉換器)。這兩個模型都使用經典的 Mask R-CNN 框架作為物件檢測的骨幹。這個文件佈局分析 Space 展示瞭如何使用 DiT 來識別文件中的文字段落、標題和表格。下圖展示了一個使用 DiT 檢測文件不同部分的示例。
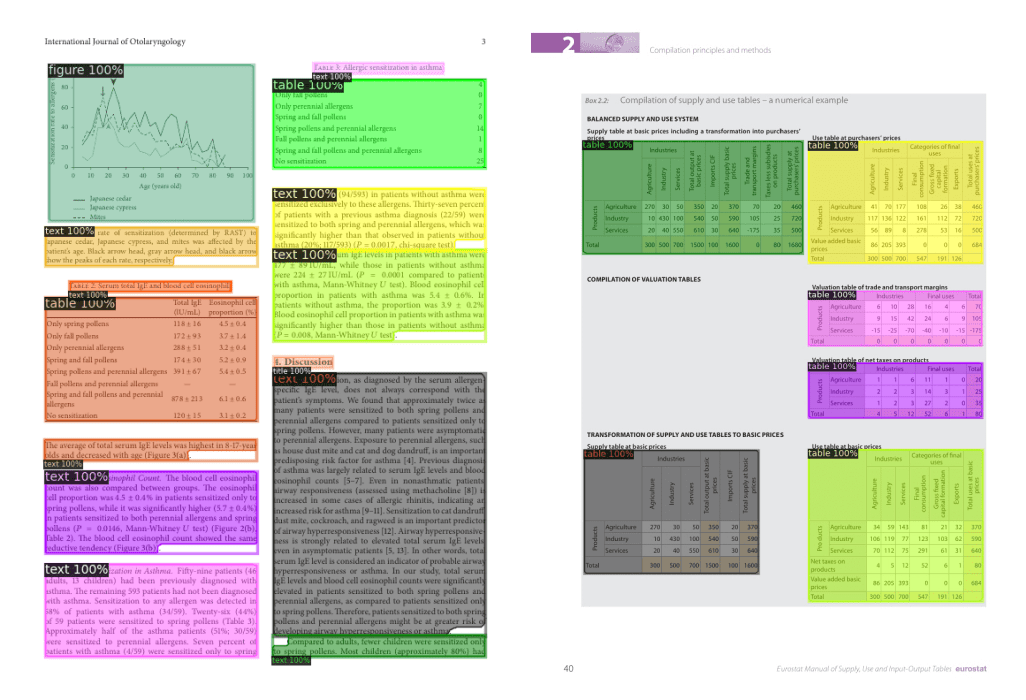
使用 DiT 進行文件佈局分析。
文件佈局分析通常使用 mAP (平均精度均值) 指標,這在評估物件檢測模型時很常用。佈局分析的一個重要基準是 PubLayNet 資料集。在撰寫本文時,LayoutLMv3 是最先進的模型,其總 mAP 得分為 0.951 (來源)。
文件解析是佈局分析的進一步延伸。文件解析是從文件中識別和提取關鍵資訊 (通常以鍵值對的形式),例如從發票表格中提取姓名、專案和總額。這個 LayoutLMv2 Space 展示瞭如何解析文件以識別問題、答案和標題。
LayoutLM 的第一個版本 (現在稱為 LayoutLMv1) 於 2020 年釋出,它在現有基準測試上取得了顯著進步,至今仍是 Hugging Face Hub 上最受歡迎的文件 AI 模型之一。LayoutLMv2 和 LayoutLMv3 在預訓練期間加入了視覺特徵,從而帶來了效能提升。LayoutLM 系列為文件 AI 的效能帶來了階躍式的變化。例如,在 FUNSD 基準資料集上,BERT 模型的 F1 得分為 60%,而使用 LayoutLM 則可以達到 90%!
LayoutLMv1 現在有了許多後續模型,包括 ERNIE-Layout,它在這個 Space 中展示了有前景的結果。對於多語言用例,有 LayoutLM 的多語言變體,如 LayoutXLM 和 LiLT。下圖來自 LayoutLM 論文,展示了 LayoutLM 分析不同文件的情景。
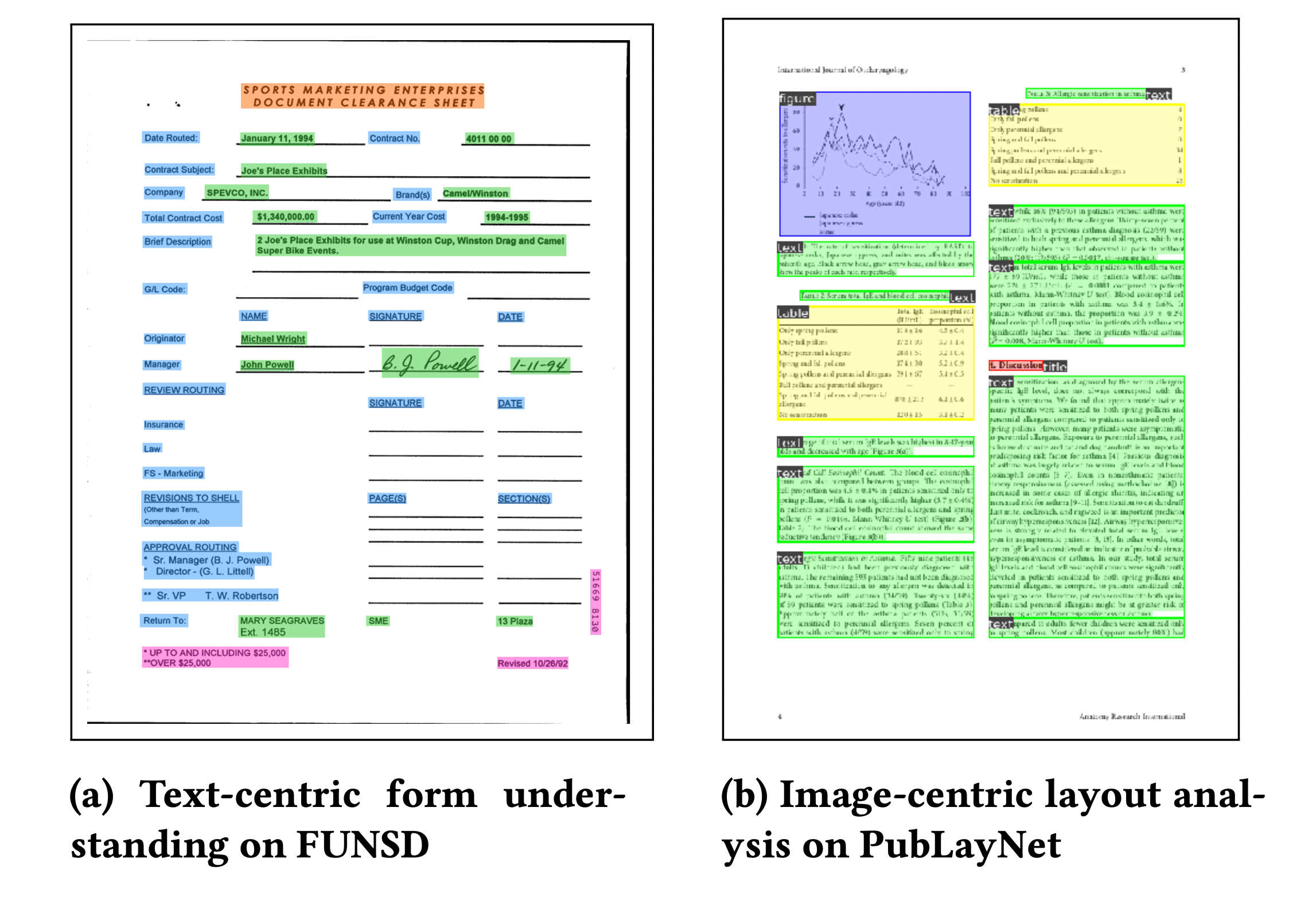
LayoutLM 的許多後繼者採用了一種生成的、端到端的方法。這始於 Donut 模型,它簡單地將文件影像作為輸入,並生成文字作為輸出,不依賴於任何獨立的 OCR 引擎。

由編碼器-解碼器 Transformer 組成的 Donut 模型。圖片來自 Donut 論文。
在 Donut 之後,各種類似的模型被髮布,包括谷歌的 Pix2Struct 和微軟的 UDOP。如今,像 LLaVa-NeXT 和 Idefics2 這樣的大型視覺語言模型可以被微調,以端到端的方式執行文件解析。事實上,只要任務可以被定義為影像-文字到文字的任務,這些模型就可以被微調以執行任何文件 AI 任務,從文件影像分類到文件解析。例如,可以參考這篇教程筆記,來微調谷歌的 PaliGemma (一個較小的視覺語言模型) 以從收據影像中返回 JSON。

像 PaliGemma 這樣的視覺語言模型可以在任何影像-文字到文字任務上進行微調。請參閱教程筆記。
資料科學家們發現,文件佈局分析和提取是企業中的關鍵用例。現有的商業解決方案通常無法處理企業資料在內容和結構上的多樣性。因此,資料科學團隊透過微調自己的模型,常常可以超越商業工具。
文件中通常包含表格,而大多數 OCR 工具在處理表格資料時效果並不理想。表格檢測是識別表格在文件中位置的任務,表格提取則是建立這些資訊的結構化表示。表格結構識別是識別構成表格的各個部分,如行、列和單元格的任務。表格功能分析 (FA) 則是識別表格的鍵和值的任務。下圖來自 Table Transformer,它說明了這些不同子任務之間的區別。
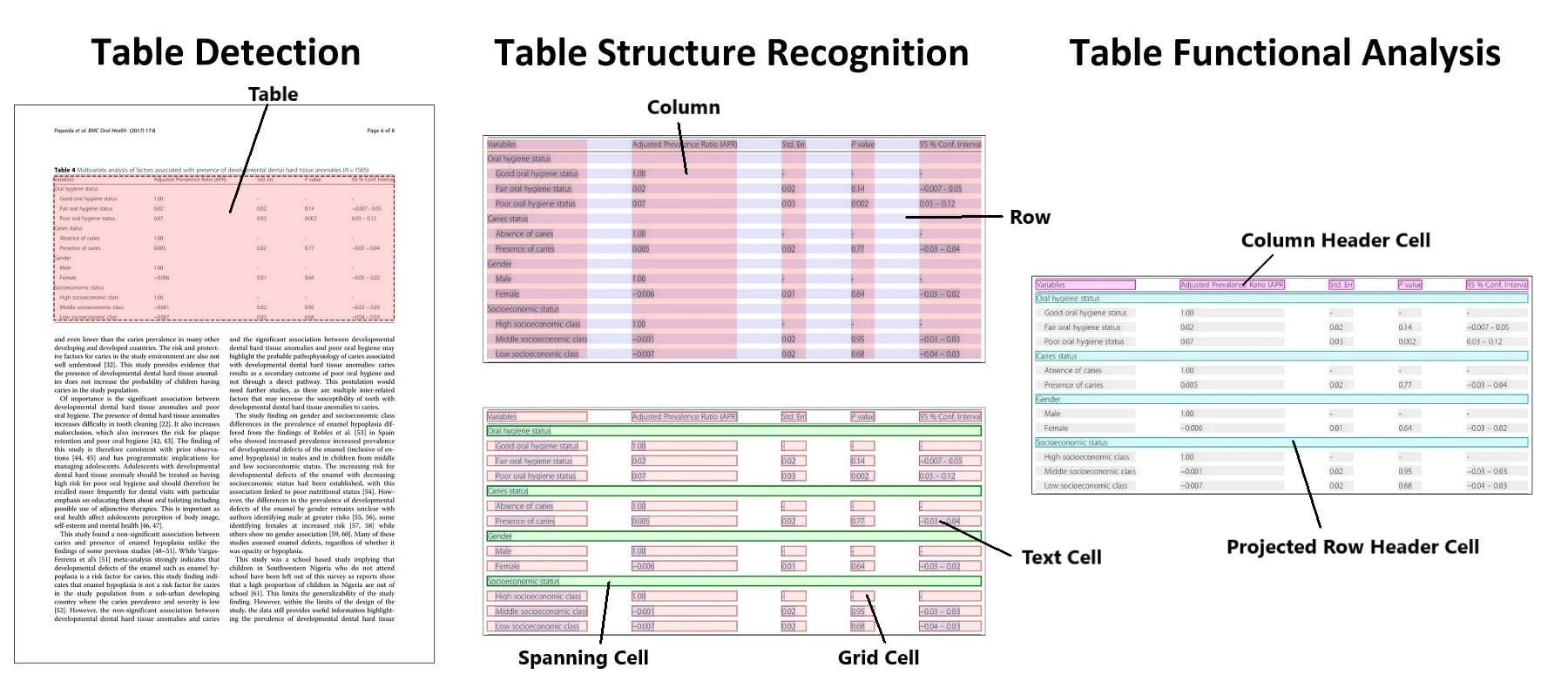
表格檢測和結構識別的方法與文件佈局分析類似,都使用物件檢測模型,輸出一組邊界框和相應的類別。
最新的方法,如 Table Transformer,可以用同一個模型實現表格檢測和表格結構識別。Table Transformer 是一個類似 DETR 的物件檢測模型,在 PubTables-1M (一個包含一百萬個表格的資料集) 上進行訓練。表格檢測和結構識別的評估通常使用平均精度 (AP) 指標。據報道,Table Transformer 在 PubTables-1M 上的效能為:表格檢測的 AP 為 0.966,表格結構識別 + 功能分析的 AP 為 0.912。
表格檢測和提取是一種令人興奮的方法,但其在您的資料上的結果可能會有所不同。根據我們的經驗,表格的質量和格式差異很大,這會影響模型的效能。在一些自定義資料上進行額外的微調將大大提高效能。
對文件進行問答極大地改變了人們與 AI 的互動方式。近期的進步使得可以要求模型回答關於影像的問題——這被稱為文件視覺問答,簡稱 DocVQA。在收到一個問題後,模型會分析影像並給出答案。下圖是來自 DocVQA 資料集 的一個例子。使用者問:“請問上面寫的郵政編碼是多少?” 模型則回答了相應的答案。

在過去,構建一個 DocVQA 系統通常需要多個模型協同工作。可能會有單獨的模型用於分析文件佈局、執行 OCR、提取實體,然後再回答問題。最新的 DocVQA 模型可以以端到端的方式實現問答,僅包含一個單一的 (多模態) 模型。
DocVQA 通常使用平均歸一化萊文斯坦相似度 (ANLS) 指標進行評估。有關此指標的更多詳細資訊,我們建議參考本指南。目前在 DocVQA 基準測試上,開源模型中的 SOTA (state-of-the-art) 是 LayoutLMv3,它達到了 83.37 的 ANLS 分數。然而,這個模型是由 OCR + 多模態 Transformer 組成的流水線。
像 Donut、LLaVa-NeXT 和 Idefics2 這樣的較新模型,使用單一的基於 Transformer 的神經網路以端到端的方式解決此任務,不依賴於 OCR。Impira 託管了一個非常有趣的 Space,展示了 LayoutLM 和 Donut 在 DocVQA 上的應用。
視覺問答非常引人注目;然而,要成功使用它,需要考慮許多因素。擁有準確的訓練資料、評估指標和後處理至關重要。對於著手這個用例的團隊來說,要知道 DocVQA 可能很難正常工作。在某些情況下,響應可能不可預測,模型可能會“幻覺”,給出文件中沒有出現的答案。視覺問答模型可能會繼承資料中的偏見,從而引發倫理問題。確保正確的模型設定和後處理是構建成功的 DocVQA 解決方案的必要組成部分。
文件 AI 中的許可問題有哪些?
工業界和學術界為推動文件 AI 的發展做出了巨大貢獻。有各種各樣的模型和資料集可供資料科學家使用。然而,對於構建企業解決方案來說,許可問題可能是一個無法逾越的障礙。一些知名的模型具有限制性許可,禁止將模型用於商業目的。最值得注意的是,微軟的 LayoutLMv2 和 LayoutLMv3 檢查點不能用於商業用途。當您開始一個專案時,我們建議仔細評估潛在模型的許可。在專案開始時瞭解您想使用哪些模型至關重要,因為這可能會影響資料收集和標註。本文末尾有一張表格,列出了流行模型及其許可資訊。
文件 AI 中的資料準備問題有哪些?
文件 AI 的資料準備至關重要且充滿挑戰。擁有正確標註的資料至關重要。以下是我們在資料準備方面學到的一些經驗。
首先,機器學習依賴於資料的規模和質量。如果你的文件影像質量差,你不能指望 AI 能神奇地讀懂這些文件。同樣,如果你的訓練資料量小但類別多,你的模型效能可能會很差。文件 AI 和其他機器學習問題一樣,更多的資料通常會帶來更好的效能。
其次,保持方法的靈活性。你可能需要測試幾種不同的方法來找到最佳解決方案。一個很好的例子是 OCR,你可以使用像 Tesseract 這樣的開源產品,像 Cloud Vision API 這樣的商業解決方案,或者像 Donut 這樣的開源多模態模型內建的 OCR 功能。
第三,從小規模的資料標註開始,並明智地選擇你的工具。根據我們的經驗,幾百份文件就可以得到不錯的結果。所以從小處著手,並仔細評估你的效能。一旦你確定了大致的方法,就可以開始擴大資料規模,以最大限度地提高你的預測準確性。在進行標註時,請記住,像佈局識別和文件提取這樣的任務需要識別文件內的特定區域。你需要確保你的標註工具支援邊界框。
文件 AI 中的建模問題有哪些?
構建模型的靈活性為資料科學家帶來了許多選擇。我們強烈建議團隊從預訓練的開源模型開始。這些模型可以針對您的特定文件進行微調,這通常是獲得一個好模型的最快方法。
對於考慮構建自己的預訓練模型的團隊,請注意這可能涉及數百萬份文件,並且訓練一個模型可能需要幾周時間。構建預訓練模型需要大量投入,不推薦大多數資料科學團隊這樣做。相反,可以從微調一個模型開始,但首先要問自己以下這些問題。
你希望模型處理 OCR 嗎?例如,Donut 不需要對文件進行 OCR,它直接處理全解析度影像,因此在建模前無需 OCR。然而,根據你的問題設定,單獨進行 OCR 可能會更簡單。
你應該使用更高解析度的影像嗎?當使用 LayoutLMv2 處理影像時,它會將影像下采樣到 224x224,這會破壞影像的原始寬高比。像 Donut、Pix2Struct 和 Idefics2 等較新的模型則使用完整的高解析度影像,並保持原始寬高比。研究表明,更高的影像解析度可以顯著提高效能,因為它讓模型能“看到”更多資訊。然而,這也帶來了訓練和推理時需要額外記憶體的代價。

影像解析度對下游任務效能的影響。圖片摘自 Pix2Struct 論文。
你如何評估模型?注意邊界框未對齊的問題。你應該確保你選擇的 OCR 引擎提供的邊界框與模型處理器對齊。驗證這一點可以避免出現意外的差結果。其次,讓你的專案需求指導你的評估指標。例如,在某些任務中,如詞元分類或問答,100% 匹配可能不是最佳指標。像部分匹配這樣的指標可以考慮更多潛在的詞元,例如將“Acme”和“inside Acme”視為匹配。最後,在評估過程中考慮倫理問題,因為這些模型可能使用有偏見的資料,或提供不穩定的結果,可能對某些人群產生偏見。
下一步
您是否看到了文件 AI 的可能性?我們每天都與企業合作,利用最先進的視覺和語言模型解鎖寶貴的資料。我們在本文中包含了各種演示的連結,您可以將它們作為起點。文章的最後一部分包含了開始編寫您自己的模型 (例如視覺問答) 的資源。一旦您準備好開始構建您的解決方案,Hugging Face 公共中心是一個很好的起點。它託管了大量的文件 AI 模型。
如果您想加速您的文件 AI 工作,Hugging Face 可以提供幫助。透過我們的,我們與企業合作,為 AI 用例提供指導。對於文件 AI,這可能包括幫助構建預訓練模型、提高微調任務的準確性,或為處理您的第一個文件 AI 用例提供整體指導。
我們還可以提供計算積分套餐,供您大規模使用我們的訓練 (AutoTrain) 或推理 (Spaces 或 Inference Endpoints) 產品。
資源
許多文件 AI 模型的 Notebook 和教程可以在以下位置找到:
- Niels 的 Transformers-Tutorials
- Philipp 的 Document AI with Hugging Face Transformers
哪些是流行的開源文件 AI 模型?
下表列出了當前可用的、在文件 AI 任務上達到 SOTA (state-of-the-art) 效能的 Transformers 模型。一個重要趨勢是,我們看到越來越多的視覺語言模型以端到端的方式執行文件 AI 任務,將文件影像作為輸入並生成文字作為輸出。
最後更新於 2024 年 6 月。







