在 Hub 上釋出評估功能









此專案已歸檔。如果您想在 Hub 上評估 LLM,請檢視此排行榜集合。
TL;DR:今天我們推出了Hub 上的評估功能,這是一個由AutoTrain驅動的新工具,讓您無需編寫一行程式碼,即可在 Hub 上的任何資料集上評估任何模型!
人工智慧的進步令人驚歎,以至於現在有些人認真地討論人工智慧模型在某些任務上是否會比人類更出色。然而,這種進步並非平衡:對於幾十年前的機器學習者來說,現代硬體和演算法可能令人難以置信,我們可支配的資料和計算量也同樣令人驚歎,但我們評估這些模型的方式卻大致保持不變。
然而,毫不誇張地說,現代人工智慧正處於評估危機之中。如今,適當的評估涉及衡量許多模型,通常是在許多資料集上,並使用多種指標。但這樣做不必要地繁瑣。如果我們關注可復現性,情況尤其如此,因為自報結果可能存在無意的錯誤、細微的實現差異,甚至更糟。
我們相信,如果我們(社群)建立一套更好的最佳實踐並努力消除障礙,就能實現更好的評估。在過去的幾個月裡,我們一直在努力開發Hub 上的評估功能:只需點選一下按鈕,即可在任何資料集上使用任何指標評估任何模型。為了開始,我們評估了數百個模型,使用了幾個關鍵資料集,並使用 Hub 上巧妙的新拉取請求功能,在模型卡上打開了大量 PR,以顯示其經過驗證的效能。評估結果直接編碼在模型卡元資料中,遵循 Hub 上所有模型的一種格式。檢視DistilBERT的模型卡,看看它是什麼樣子!
在 Hub 上
Hub 上的評估功能為許多有趣的用例打開了大門。從需要決定部署哪個模型的資料科學家或高管,到試圖在新資料集上重現論文結果的學者,再到希望更好地理解部署風險的倫理學家。如果我們要挑選三個主要的初始用例場景,它們是:
為您的任務找到最佳模型
假設您確切地知道您的任務是什麼,並且您想為這項工作找到合適的模型。您可以檢視代表您任務的資料集的排行榜,其中彙總了所有結果。這很棒!如果您感興趣的那個花哨的新模型還沒有在該資料集的排行榜上怎麼辦?只需在不離開 Hub 的情況下為其執行評估即可。
在新資料集上評估模型
現在,如果您有一個全新的資料集,您想對其進行基準測試怎麼辦?您可以將其上傳到 Hub,並根據需要評估任意數量的模型。無需程式碼。更重要的是,您可以確保您在您資料集上評估這些模型的方式與它們在其他資料集上評估的方式完全相同。
在許多其他相關資料集上評估您的模型
或者假設您有一個全新的問答模型,在 SQuAD 上訓練的?有數百個不同的問答資料集可以評估:😱 您可以直接從 Hub 選擇您感興趣的那些資料集並評估您的模型。
生態系統
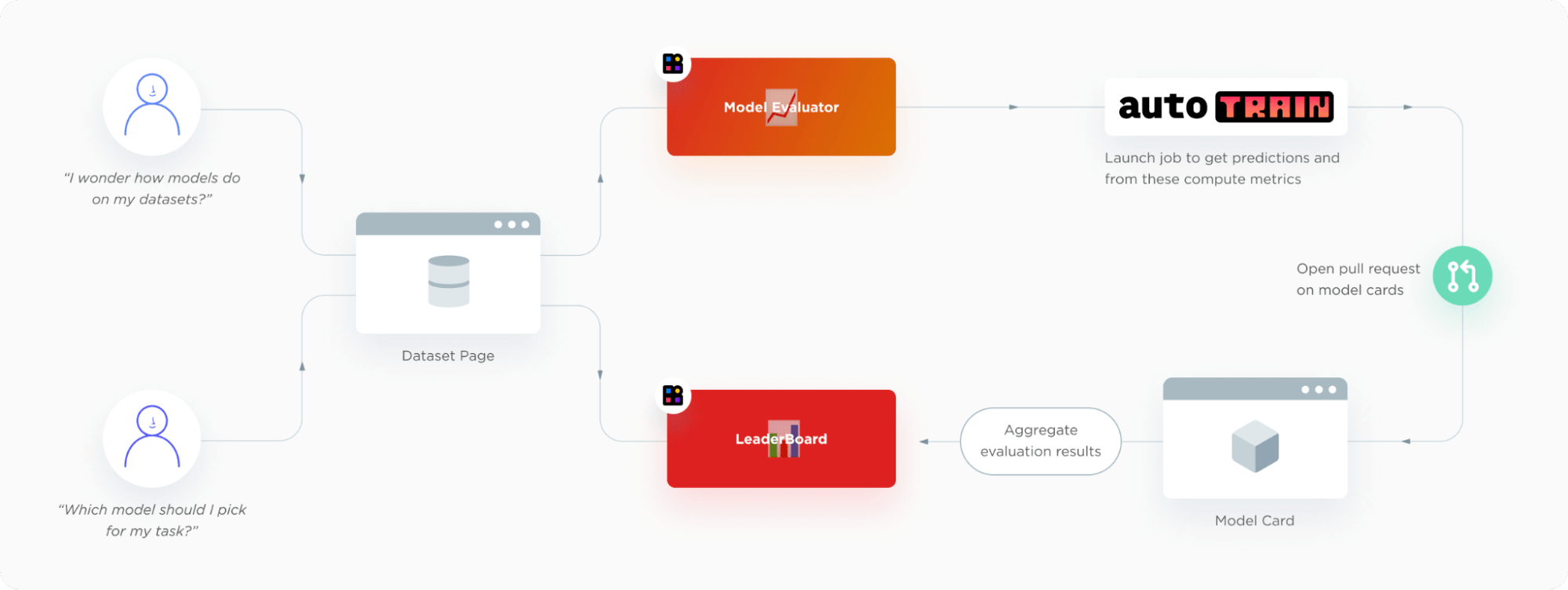
Hub 上的評估旨在讓您的生活更輕鬆。當然,幕後發生了很多事情。我們真正喜歡 Hub 上的評估功能的原因是:它與現有的 Hugging Face 生態系統完美契合,我們幾乎必須這樣做。使用者從資料集頁面開始,可以在那裡啟動評估或檢視排行榜。模型評估提交介面和排行榜是常規的 Hugging Face Spaces。評估後端由 AutoTrain 提供支援,它會在給定模型的模型卡上開啟一個 PR。
內部測試 - 區分狗、鬆餅和炸雞
那麼它在實踐中是怎樣的呢?讓我們來看一個例子。假設您的業務是區分狗、鬆餅和炸雞(也稱為內部測試!)。

如上圖所示,要解決這個問題,您需要
- 包含狗、鬆餅和炸雞圖片的真實資料集
- 在該圖片上訓練的影像分類器
幸運的是,您的資料科學團隊已將一個數據集上傳到 Hugging Face Hub,並在其上訓練了幾個不同的模型。現在您只需選擇最好的一個——讓我們使用 Hub 上的評估功能,看看它們在測試集上的表現如何!
配置評估任務
要開始,請訪問 model-evaluator Space 並選擇您要評估模型的資料集。對於我們的狗和食物影像資料集,您將看到類似下圖的內容:
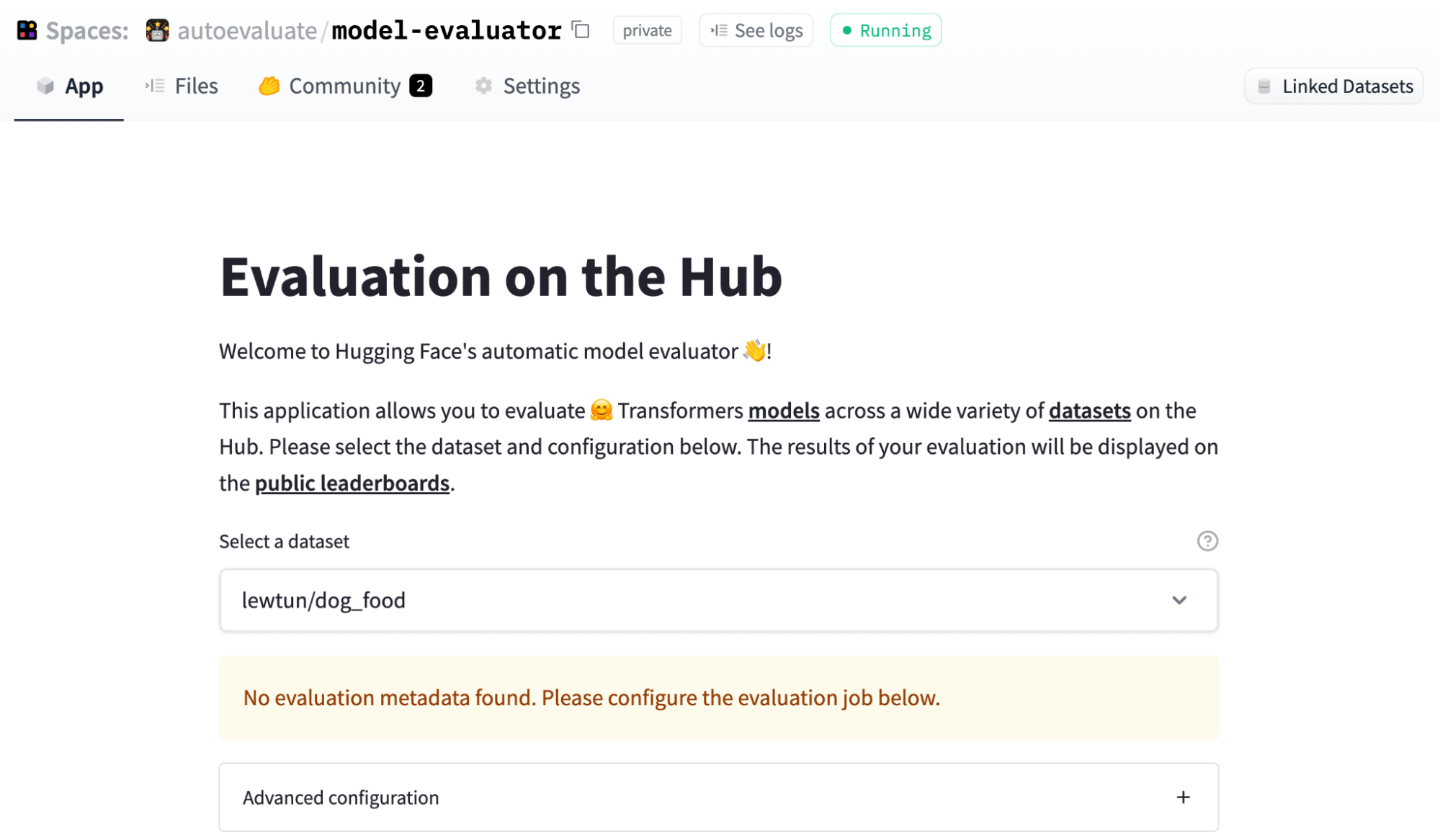
現在,Hub 上的許多資料集都包含指定如何配置評估的元資料(請檢視acronym_identification以獲取示例)。這使您可以透過單擊評估模型,但在我們的例子中,我們將向您展示如何手動配置評估。
單擊“高階配置”按鈕將顯示各種設定供您選擇
- 任務、資料集和拆分配置
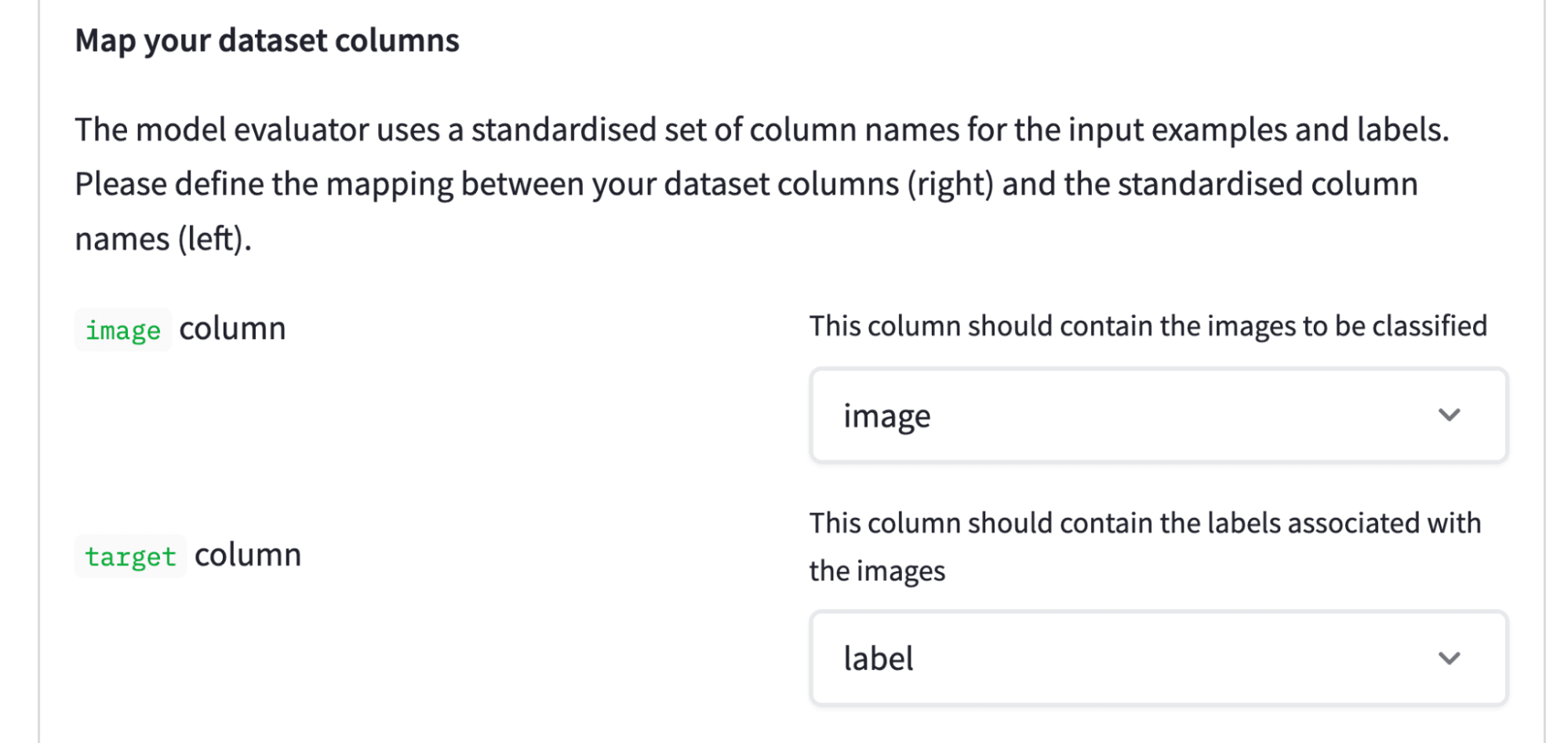
- 資料集列到標準格式的對映
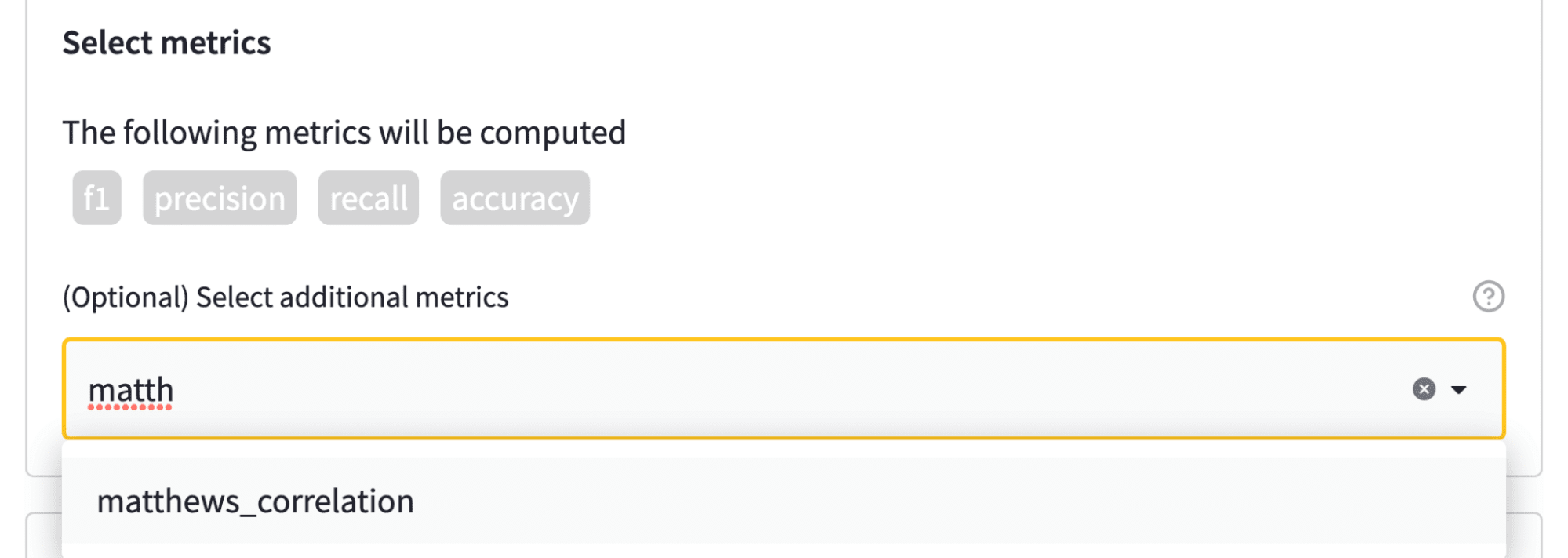
- 指標選擇
如下圖所示,配置任務、資料集和要評估的拆分非常簡單

下一步是定義哪些資料集列包含影像,哪些列包含標籤
任務和資料集配置完成後,最後(可選)一步是選擇要評估的指標。每個任務都與一組預設指標相關聯。例如,下圖顯示 F1 分數、準確度等將自動計算。為了增加趣味性,我們還將計算馬修斯相關係數,它提供了分類器效能的均衡衡量標準
配置評估任務就這麼簡單!現在我們只需選擇一些要評估的模型——讓我們來看看。
選擇要評估的模型
Hub 上的評估透過模型卡元資料中的標籤連結資料集和模型。在我們的示例中,我們有三個模型可供選擇,所以讓我們將它們全部選中!
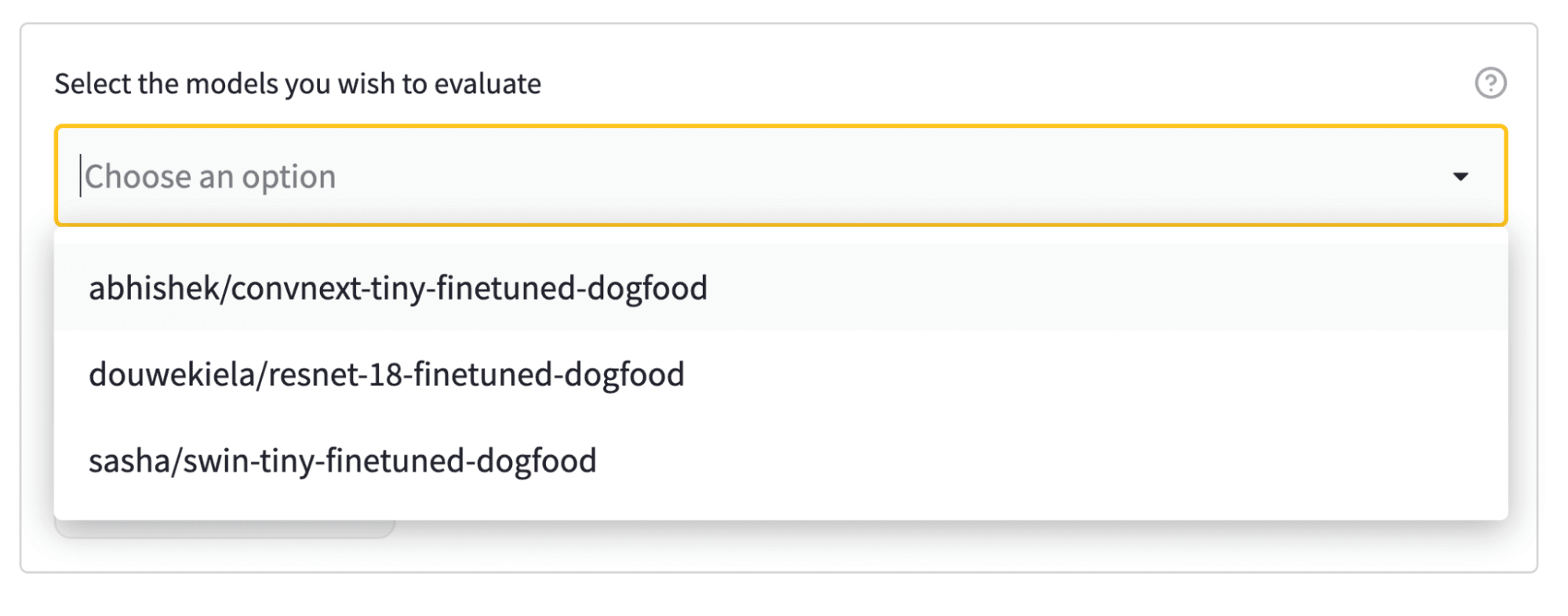
選擇模型後,只需輸入您的 Hugging Face Hub 使用者名稱(以便在評估完成時收到通知),然後點選大大的“評估模型”按鈕
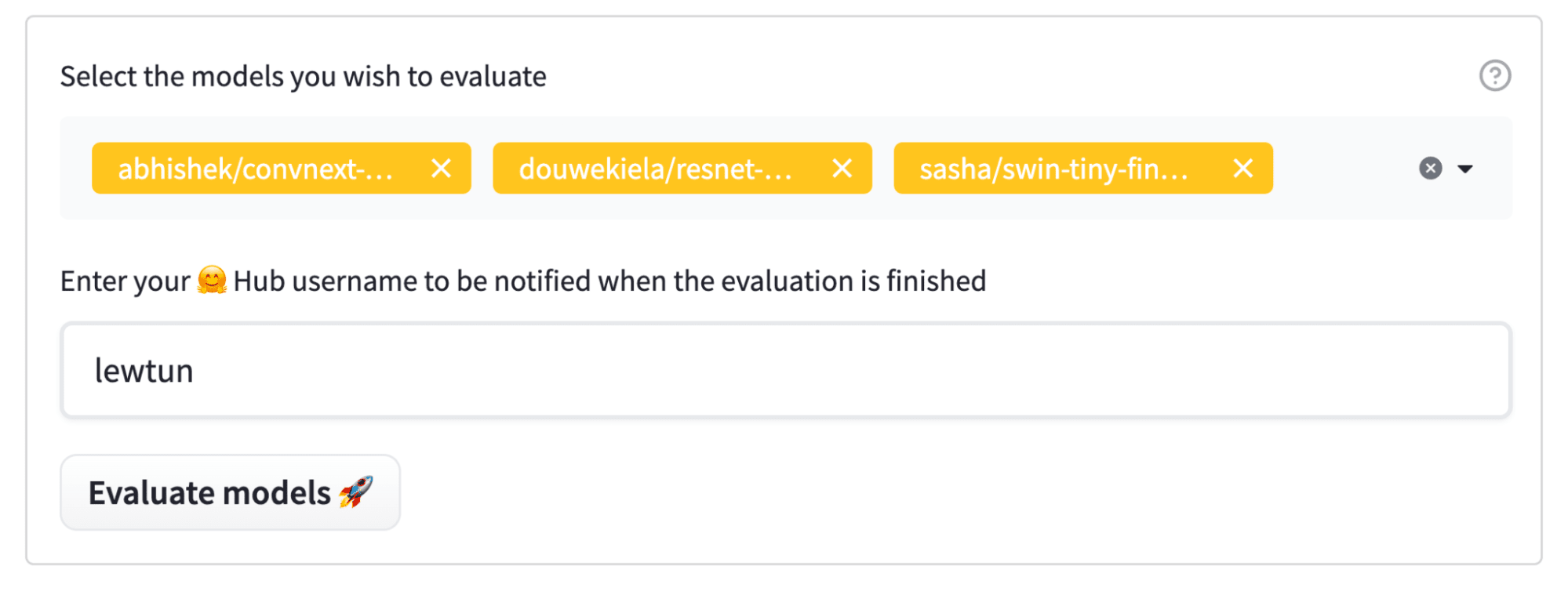
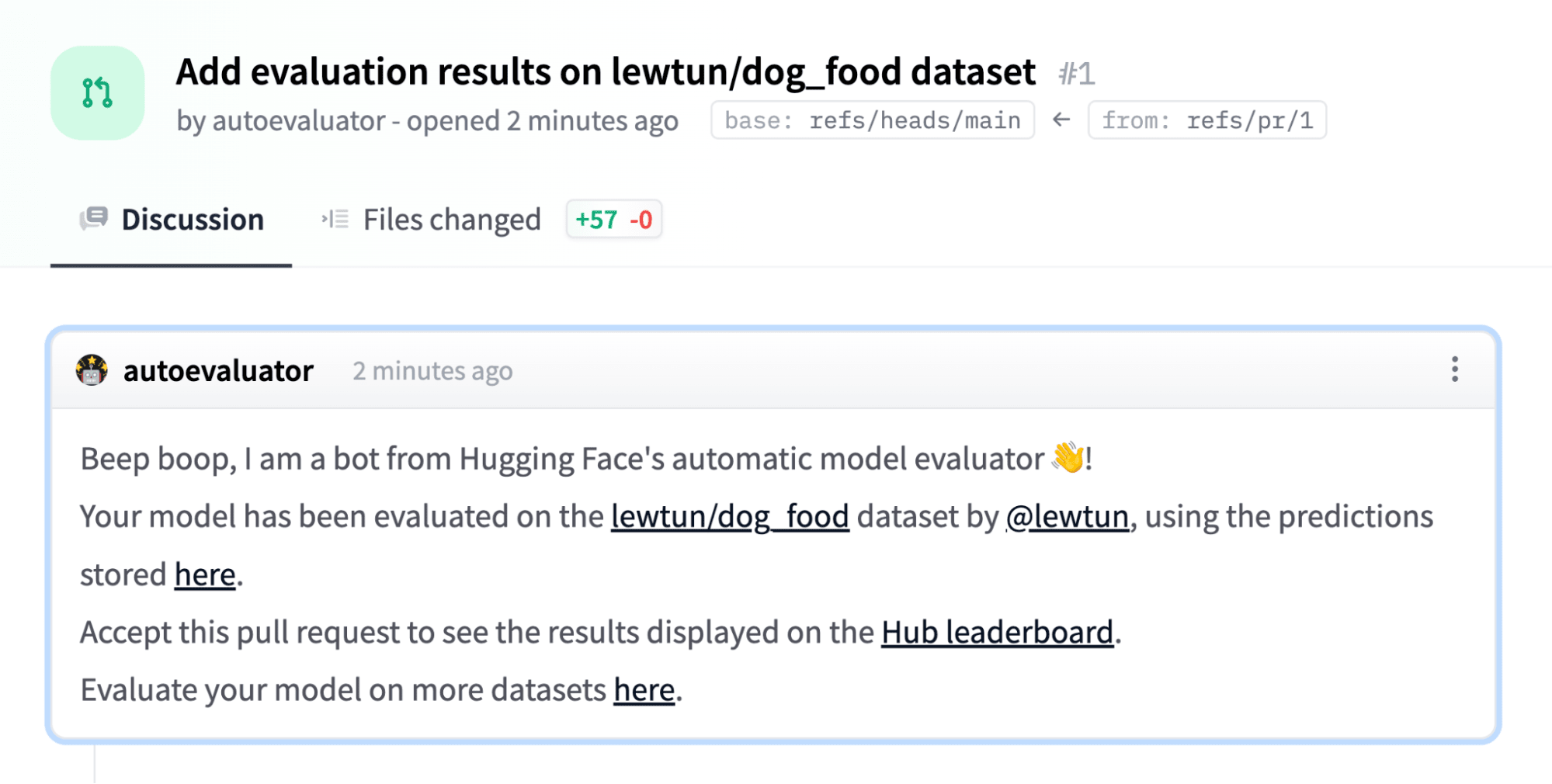
任務提交後,模型將自動評估,並且將開啟一個 Hub 拉取請求,其中包含評估結果
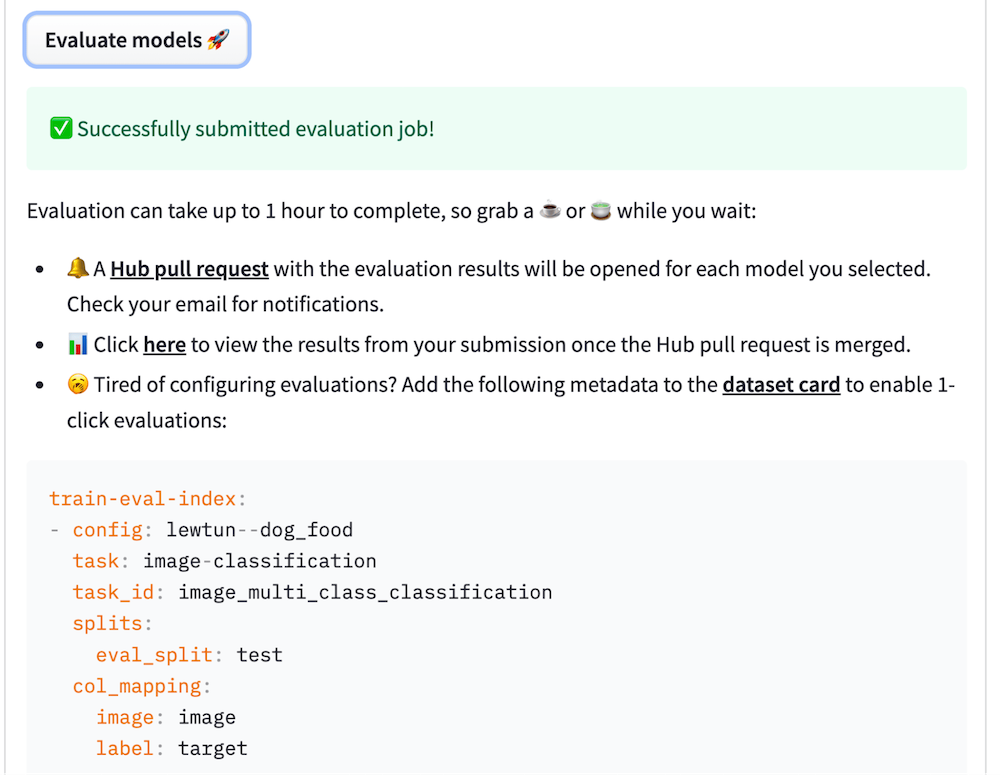
您還可以將評估元資料複製貼上到資料集卡中,以便您和社群下次可以跳過手動配置!
檢視排行榜
為了便於模型比較,Hub 上的評估還提供了排行榜,讓您可以檢視哪些模型在哪個分割和指標上表現最佳
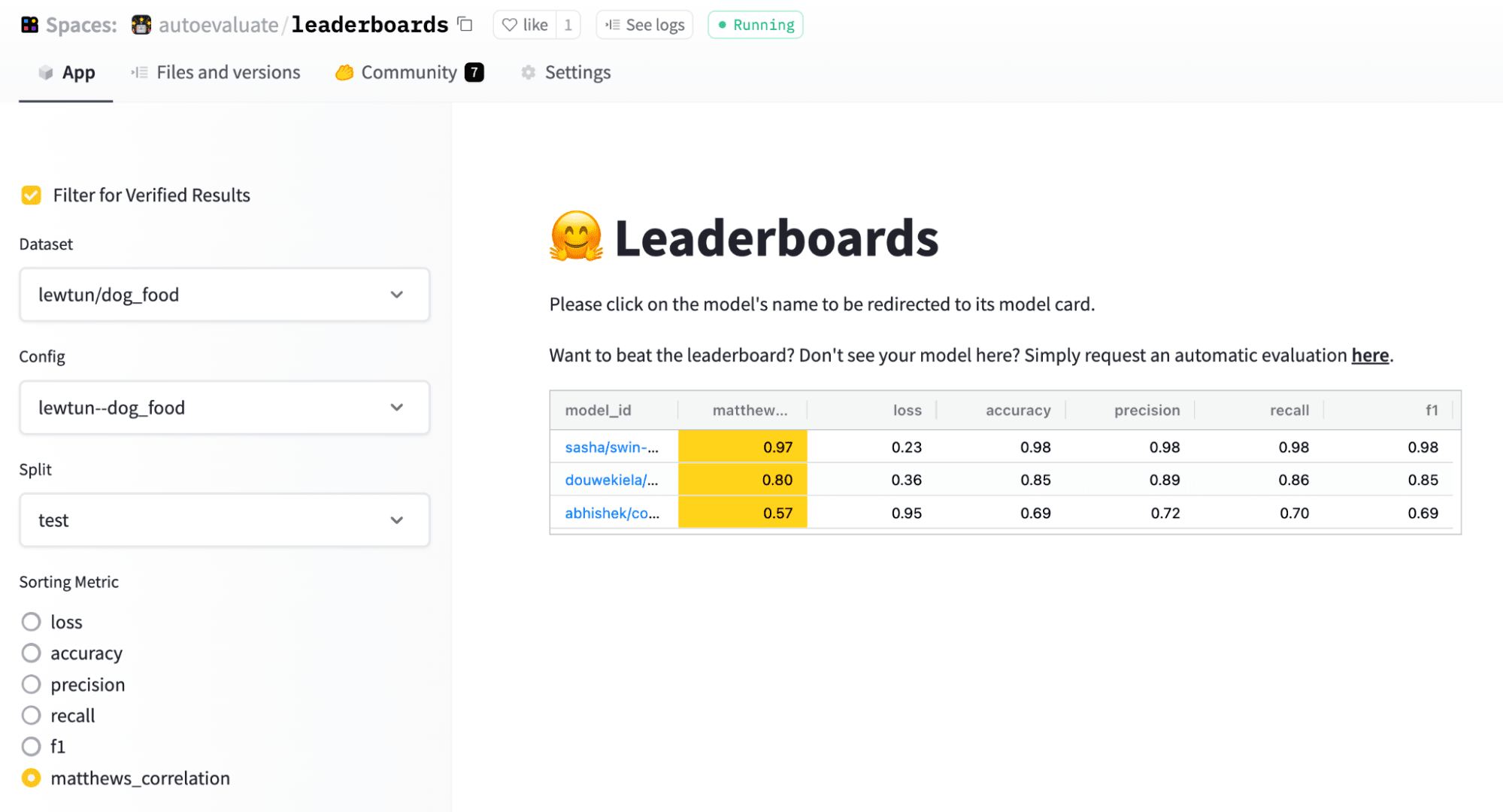
看來 Swin Transformer 脫穎而出!
親自嘗試!
如果您想評估自己選擇的模型,請檢視以下熱門資料集,嘗試使用 Hub 上的評估功能:
- 情感 (Emotion) 用於文字分類
- MasakhaNER 用於命名實體識別
- SAMSum 用於文字摘要
更大的圖景
自機器學習誕生以來,我們一直透過計算在假定獨立同分布的保留測試集上計算某種形式的準確率來評估模型。在現代 AI 的壓力下,這種正規化現在開始出現嚴重的裂痕。
基準測試正在趨於飽和,這意味著機器在某些測試集上的表現幾乎比我們提出新的測試集更快。然而,眾所周知,AI 系統脆弱且容易受到甚至放大嚴重的惡意偏見。可復現性不足。開放性被事後才考慮。當人們專注於排行榜時,部署模型的實際考慮因素(例如效率和公平性)往往被忽略。資料在模型開發中扮演的巨大作用仍然沒有得到足夠的重視。更重要的是,預訓練和基於提示的上下文學習實踐模糊了“分佈內”的含義。機器學習正在慢慢追趕這些方面,我們希望透過我們的工作幫助該領域向前發展。
下一步
幾周前,我們釋出了 Hugging Face Evaluate 庫,旨在降低機器學習評估最佳實踐的門檻。我們還舉辦了基準測試,例如 RAFT 和 GEM。Hub 上的評估是我們努力實現未來模型以更全面、多維度、可信賴且可復現的方式進行評估的合乎邏輯的下一步。請繼續關注即將釋出的更多功能,包括更多工,以及一個全新改進的資料測量工具!
我們很高興看到社群將如何利用這一點!如果您想提供幫助,請在儘可能多的資料集上評估儘可能多的模型。一如既往,請透過社群選項卡或論壇給我們提供大量反饋!
