歡迎 fastai 加入 Hugging Face Hub



讓神經網路再次不酷……並分享它們
很少有像 fast.ai 生態系統這樣致力於使深度學習變得易於使用的。Hugging Face 的使命是使優秀的機器學習民主化。讓我們將機器學習(包括預訓練模型)的獨佔訪問變為過去,並進一步推動這個令人驚歎的領域。
fastai 是一個開源深度學習庫,它利用 PyTorch 和 Python 提供高階元件,用於在文字、視覺和表格資料上訓練快速、準確的神經網路,並取得最先進的成果。然而,fast.ai,這家公司,不僅僅是一個庫;它已經發展成為一個由開源貢獻者和學習神經網路的人組成的繁榮生態系統。例如,您可以檢視他們的書籍和課程。加入 fast.ai 的 Discord 和論壇。保證您會透過參與他們的社群而學到很多!
鑑於以上種種,以及更多(本文作者的旅程就始於 fast.ai 課程),我們很榮幸地宣佈,fastai 使用者現在只需一行 Python 程式碼,即可將模型分享並上傳到 Hugging Face Hub。
👉 在這篇博文中,我們將介紹 fastai 與 Hub 之間的整合。此外,您可以將此教程作為 Colab 筆記本開啟。
我們感謝 fast.ai 社群,特別是 Jeremy Howard、Wayde Gilliam 和 Zach Mueller 提供的反饋 🤗。本部落格深受 fastai 文件中Hugging Face Hub 部分的啟發。
為什麼分享到 Hub?
Hub 是一箇中心平臺,任何人都可以分享和探索模型、資料集和機器學習演示。它擁有最廣泛的開源模型、資料集和演示集合。
在 Hub 上分享您的 fastai 模型,可以擴大其影響力,使其可供他人下載和探索。您還可以使用 fastai 模型進行遷移學習;將他人的模型作為您任務的基礎。
任何人都可以透過在 hf.co/models 網頁上按 fastai 庫篩選來訪問 Hub 中的所有 fastai 模型,如下圖所示。
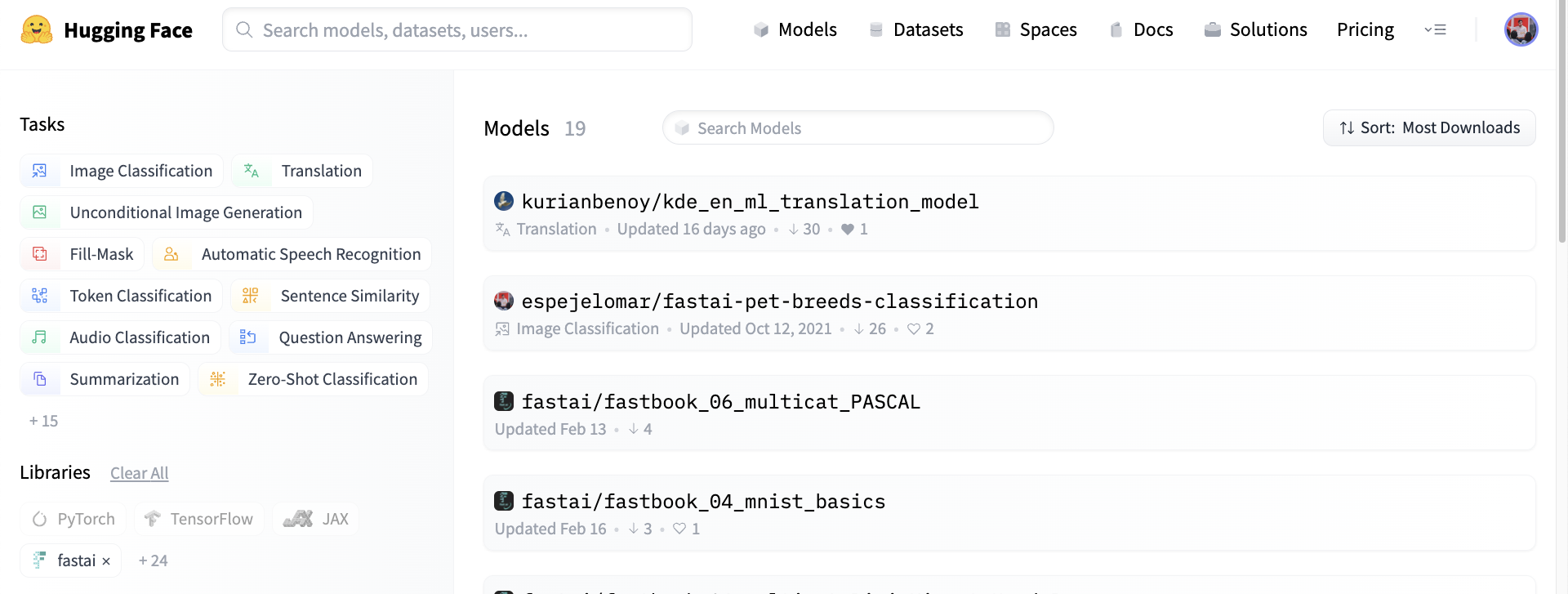
除了免費的模型託管和對更廣泛社群的曝光之外,Hub 還內建了基於 git 的版本控制(用於大檔案的 git-lfs)和用於可發現性和可重現性的模型卡。有關導航 Hub 的更多資訊,請參閱此介紹。
加入 Hugging Face 並安裝
要在 Hub 中分享模型,您需要有一個使用者。在 Hugging Face 網站上建立它。
huggingface_hub 庫是一個輕量級的 Python 客戶端,具有與 Hugging Face Hub 互動的實用功能。要將 fastai 模型推送到 Hub,您需要預先安裝一些庫(fastai>=2.4、fastcore>=1.3.27 和 toml)。您可以在安裝 huggingface_hub 時透過指定 ["fastai"] 自動安裝它們,您的環境就可以使用了
pip install huggingface_hub["fastai"]
建立一個 fastai `Learner`
在這裡,我們訓練 fastbook 中的第一個模型來識別貓 🐱。我們強烈建議閱讀完整的 fastbook。
# Training of 6 lines in chapter 1 of the fastbook.
from fastai.vision.all import *
path = untar_data(URLs.PETS)/'images'
def is_cat(x): return x[0].isupper()
dls = ImageDataLoaders.from_name_func(
path, get_image_files(path), valid_pct=0.2, seed=42,
label_func=is_cat, item_tfms=Resize(224))
learn = vision_learner(dls, resnet34, metrics=error_rate)
learn.fine_tune(1)
將 `Learner` 分享到 Hub
`Learner` 是一個 fastai 物件,它捆綁了模型、資料載入器和損失函式。在本篇博文中,我們將互換使用 `Learner` 和 Model 這兩個詞。
首先,登入 Hugging Face Hub。您需要在您的帳戶設定中建立一個`write` token。然後有三種登入方式
在您的終端中輸入 `huggingface-cli login` 並輸入您的 token。
如果在 Python 筆記本中,您可以使用 `notebook_login`。
from huggingface_hub import notebook_login
notebook_login()
- 使用 `push_to_hub_fastai` 函式的 `token` 引數。
您可以將要上傳的 `Learner` 和 Hub 的倉庫 ID(格式為“namespace/repo_name”)輸入到 `push_to_hub_fastai` 中。名稱空間可以是個人賬戶,也可以是您有寫入許可權的組織(例如,“fastai/stanza-de”)。有關更多詳細資訊,請參閱 Hub 客戶端文件。
from huggingface_hub import push_to_hub_fastai
# repo_id = "YOUR_USERNAME/YOUR_LEARNER_NAME"
repo_id = "espejelomar/identify-my-cat"
push_to_hub_fastai(learner=learn, repo_id=repo_id)
該 `Learner` 現在位於 Hub 中,倉庫名為 `espejelomar/identify-my-cat`。一個自動模型卡已建立,其中包含一些連結和後續步驟。上傳 fastai `Learner`(或任何其他模型)到 Hub 時,編輯其模型卡(下圖)以幫助他人更好地理解您的工作會很有幫助(請參閱Hugging Face 文件)。
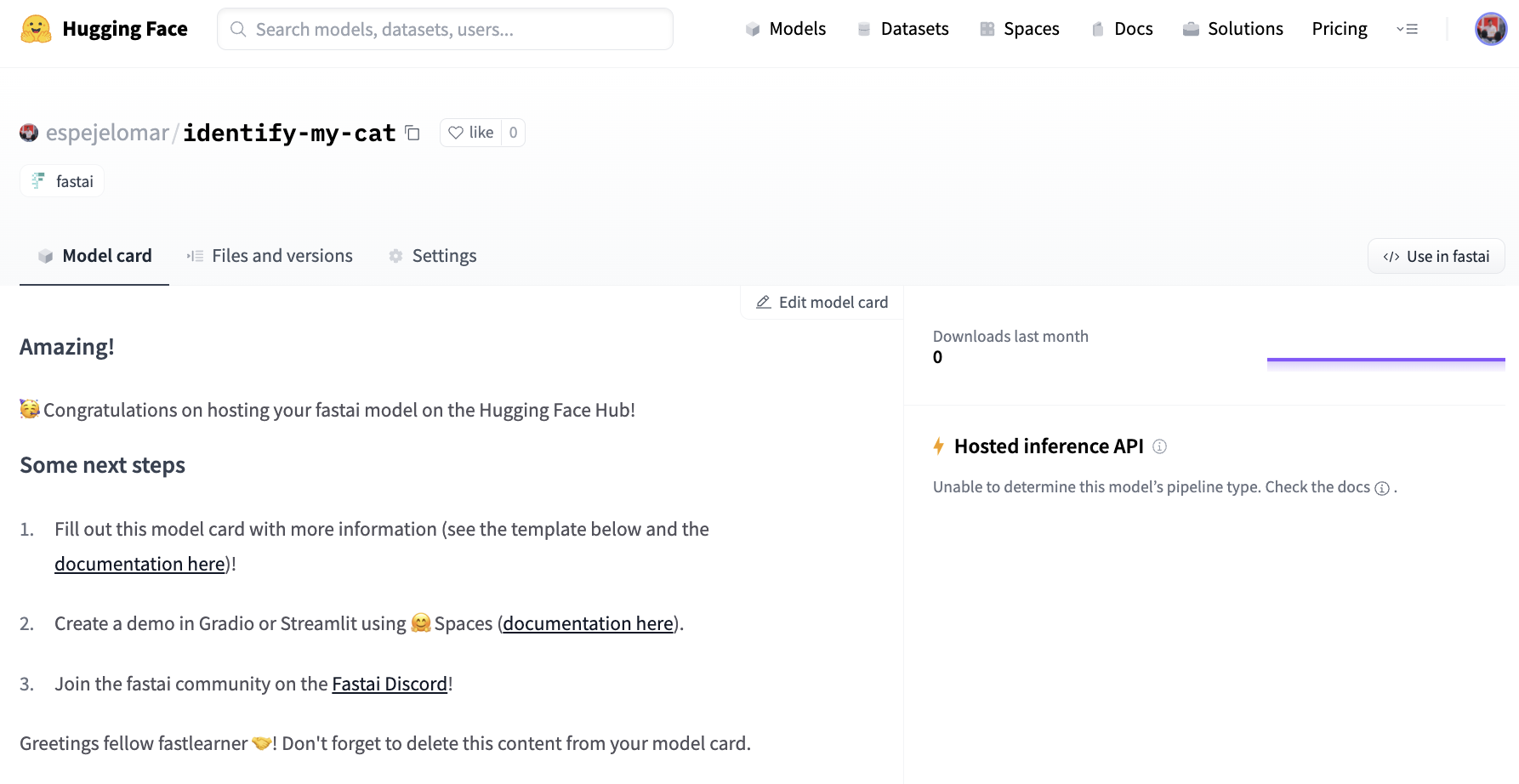
如果您想了解更多關於 `push_to_hub_fastai` 的資訊,請訪問 Hub 客戶端文件。裡面有一些您可能會感興趣的很酷的引數 👀。請記住,您的模型是一個Git 倉庫,具有 Git 帶來的一切優點:版本控制、提交、分支……
從 Hugging Face Hub 載入 `Learner`
從 Hub 載入模型更簡單。我們將載入我們的 `Learner`,“espejelomar/identify-my-cat”,並用一張貓的圖片進行測試(🦮?)。此程式碼改編自 fastbook 的第一章。
首先,上傳一張貓的圖片(或者可能是一隻狗?)。本教程的 Colab 筆記本使用 `ipywidgets` 互動式上傳貓的圖片(或者不上傳?)。這裡我們將使用這隻可愛的貓 🐅

現在讓我們載入我們剛剛在 Hub 中共享的 `Learner` 並進行測試。
from huggingface_hub import from_pretrained_fastai
# repo_id = "YOUR_USERNAME/YOUR_LEARNER_NAME"
repo_id = "espejelomar/identify-my-cat"
learner = from_pretrained_fastai(repo_id)
它奏效了 👇!
_,_,probs = learner.predict(img)
print(f"Probability it's a cat: {100*probs[1].item():.2f}%")
Probability it's a cat: 100.00%
Hub 客戶端文件中包含 `from_pretrained_fastai` 的更多詳細資訊。
`Blurr`:結合 fastai 和 Hugging Face Transformers(並分享它們)!
[Blurr 是]一個專為 fastai 開發者設計的庫,旨在訓練和部署 Hugging Face Transformers - Blurr 文件。
我們將:
- 使用高階 Blurr API 訓練一個 `blurr` Learner。它將從 Hugging Face Hub 載入 `distilbert-base-uncased` 模型,並準備一個序列分類模型。
- 使用 `push_to_hub_fastai` 將其分享到 Hub,名稱空間為 `fastai/blurr_IMDB_distilbert_classification`。
- 使用 `from_pretrained_fastai` 載入它,並使用 `learner_blurr.predict()` 進行嘗試。
協作和開源太棒了!
首先,安裝 `blurr` 並訓練 Learner。
git clone https://github.com/ohmeow/blurr.git
cd blurr
pip install -e ".[dev]"
import torch
import transformers
from fastai.text.all import *
from blurr.text.data.all import *
from blurr.text.modeling.all import *
path = untar_data(URLs.IMDB_SAMPLE)
model_path = Path("models")
imdb_df = pd.read_csv(path / "texts.csv")
learn_blurr = BlearnerForSequenceClassification.from_data(imdb_df, "distilbert-base-uncased", dl_kwargs={"bs": 4})
learn_blurr.fit_one_cycle(1, lr_max=1e-3)
使用 `push_to_hub_fastai` 分享到 Hub。
from huggingface_hub import push_to_hub_fastai
# repo_id = "YOUR_USERNAME/YOUR_LEARNER_NAME"
repo_id = "fastai/blurr_IMDB_distilbert_classification"
push_to_hub_fastai(learn_blurr, repo_id)
使用 `from_pretrained_fastai` 從 Hub 載入 `blurr` 模型。
from huggingface_hub import from_pretrained_fastai
# repo_id = "YOUR_USERNAME/YOUR_LEARNER_NAME"
repo_id = "fastai/blurr_IMDB_distilbert_classification"
learner_blurr = from_pretrained_fastai(repo_id)
用幾個句子試一下,並用 `learner_blurr.predict()` 檢視它們的情感(消極或積極)。
sentences = ["This integration is amazing!",
"I hate this was not available before."]
probs = learner_blurr.predict(sentences)
print(f"Probability that sentence '{sentences[0]}' is negative is: {100*probs[0]['probs'][0]:.2f}%")
print(f"Probability that sentence '{sentences[1]}' is negative is: {100*probs[1]['probs'][0]:.2f}%")
又成功了!
Probability that sentence 'This integration is amazing!' is negative is: 29.46%
Probability that sentence 'I hate this was not available before.' is negative is: 70.04%
接下來做什麼?
參加 fast.ai 課程(新版本即將推出),關注 Jeremy Howard 和 fast.ai 的 Twitter 更新,並開始在 Hub 上分享您的 fastai 模型 🤗。或者載入一個Hub 中已有的模型。
📧 歡迎透過 Hugging Face Discord 聯絡我們,如果您有專案想法,請分享。我們很樂意聽取您的反饋 💖。
您想將您的庫整合到 Hub 嗎?
此整合透過 `huggingface_hub` 庫實現。如果您想將您的庫新增到 Hub,我們為您準備了指南!或者只需標記 Hugging Face 團隊的某人即可。
向 Hugging Face 團隊為此整合所做的一切工作致敬,特別是 @osanseviero 🦙。
感謝 fastlearners 和 hugging learners 🤗。
