使用遙感(衛星)影像和說明對CLIP進行微調










使用遙感(衛星)影像和說明對CLIP進行微調

今年七月,Hugging Face 組織了一場 Flax/JAX 社群周,並邀請社群提交專案,以訓練 Hugging Face transformers 模型,領域涵蓋自然語言處理 (NLP) 和計算機視覺 (CV)。
參與者使用張量處理單元 (TPU) 和 Flax 及 JAX。JAX 是一個線性代數庫(類似 numpy),可以進行自動微分 (Autograd) 並編譯成 XLA,而 Flax 是 JAX 的神經網路庫和生態系統。TPU 計算時間由共同贊助本次活動的 Google Cloud 免費提供。
在接下來的兩週裡,團隊參與了 Hugging Face 和 Google 的講座,使用 JAX/Flax 訓練了一個或多個模型,並與社群共享,還提供了 Hugging Face Spaces 演示,展示了其模型的功能。大約有 100 個團隊參與了此次活動,共產生了 170 個模型和 36 個演示。
我們的團隊,可能和許多其他團隊一樣,是一個分散式團隊,橫跨 12 個時區。我們的共同點是我們都屬於 TWIML Slack 頻道,我們因對人工智慧 (AI) 和機器學習 (ML) 話題的共同興趣而聚集在一起。
我們使用 RSICD 資料集 中的衛星影像和說明對 OpenAI 的 CLIP 網路 進行了微調。CLIP 網路透過使用從網際網路上找到的文字與影像對進行自監督訓練來學習視覺概念。在推理過程中,給定文字描述,模型可以預測最相關的影像;或者給定影像,預測最相關的文字描述。CLIP 功能強大,足以在日常影像上以零樣本方式使用。然而,我們認為衛星影像與日常影像有足夠大的不同,因此用衛星影像對其進行微調會很有用。我們的直覺是正確的,正如評估結果(下文所述)所示。在這篇文章中,我們將詳細介紹我們的訓練和評估過程,以及我們未來在該專案上的工作計劃。
我們專案的目標是提供一項有用的服務,並演示如何將 CLIP 用於實際用例。我們的模型可用於應用程式,透過文字查詢搜尋大量的衛星影像。此類查詢可以描述影像的整體(例如,海灘、山脈、機場、棒球場等),或搜尋或提及這些影像中的特定地理或人造特徵。CLIP 也可以類似地針對其他領域進行微調,正如 medclip-demo 團隊 對醫學影像所展示的那樣。
能夠透過文字查詢搜尋大量影像是一項極其強大的功能,既可以用於社會公益,也可以用於惡意目的。可能的應用包括國防和反恐活動,在氣候變化影響變得難以控制之前發現並解決這些影響等。不幸的是,這種權力也可能被濫用,例如被威權國家用於軍事和警察監視,因此它也確實引發了一些倫理問題。
您可以在我們的專案頁面上閱讀有關該專案的資訊,下載我們訓練好的模型以用於您自己的資料推理,或者在我們的演示中檢視其效果。
訓練
資料集
我們主要使用 RSICD 資料集 對 CLIP 模型進行微調。該資料集包含約 10,000 張影像,這些影像是從 Google Earth、Baidu Map、MapABC 和 Tianditu 收集的。它免費提供給研究社群,以透過 探索遙感影像說明生成的模型和資料 (Lu et al, 2017) 來推進遙感說明研究。影像為 (224, 224) RGB 影像,具有各種解析度,每張影像最多有 5 個關聯的說明。

此外,我們還使用了 UCM 資料集 和 悉尼資料集 進行訓練。UCM 資料集基於 UC Merced 土地利用資料集。它包含 2100 張影像,屬於 21 個類別(每個類別 100 張影像),每張影像有 5 個說明。悉尼資料集包含來自 Google Earth 的澳大利亞悉尼影像。它包含 613 張影像,屬於 7 個類別。影像為 (500, 500) RGB,每張影像提供 5 個說明。我們使用這些額外的資料集,因為我們不確定 RSICD 資料集是否足夠大以對 CLIP 進行微調。
模型
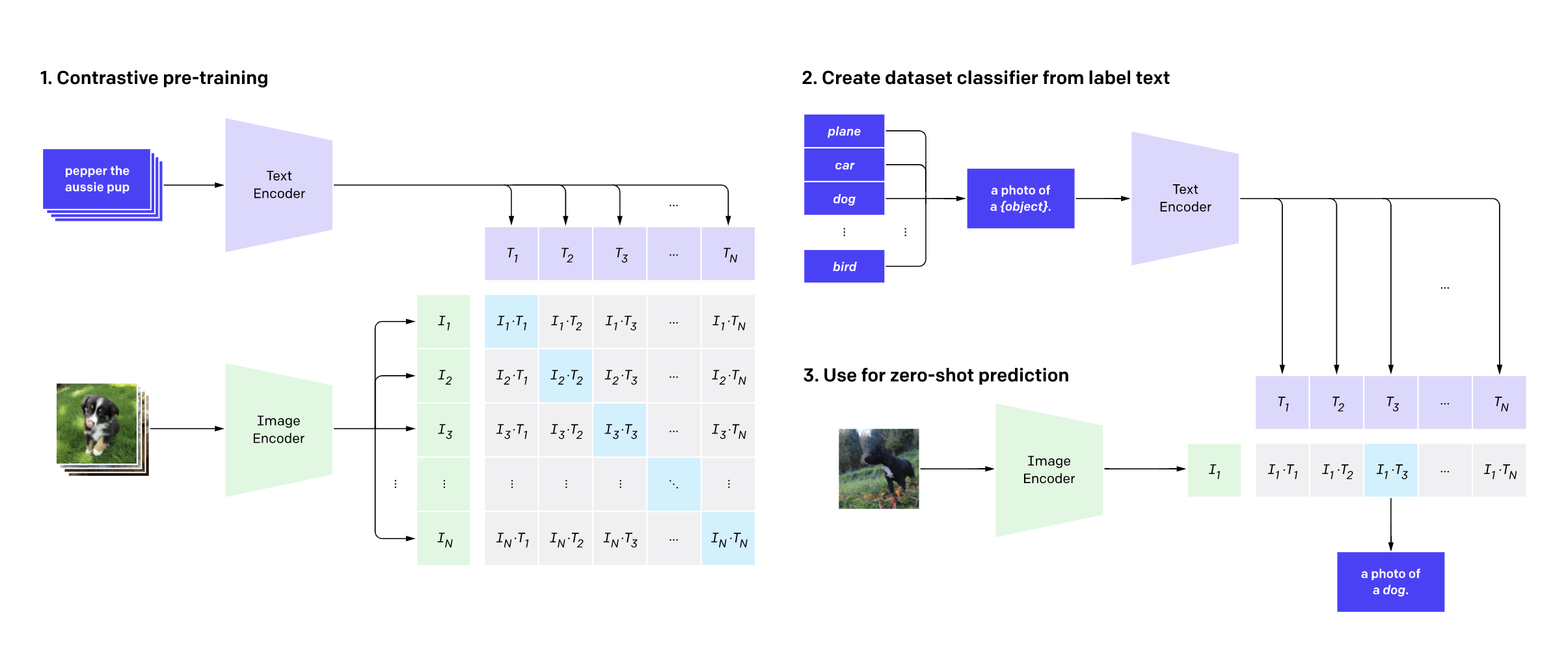
我們的模型是原始 CLIP 模型(如下所示)的微調版本。模型的輸入是分別透過 CLIP 文字編碼器和影像編碼器傳遞的一批說明和一批影像。訓練過程使用 對比學習 來學習影像和說明的聯合嵌入表示。在這個嵌入空間中,影像及其各自的說明會相互靠近,類似的影像和類似的說明也是如此。相反,不同影像的影像和說明,或不相似的影像和說明,則可能被推得更遠。
資料增強
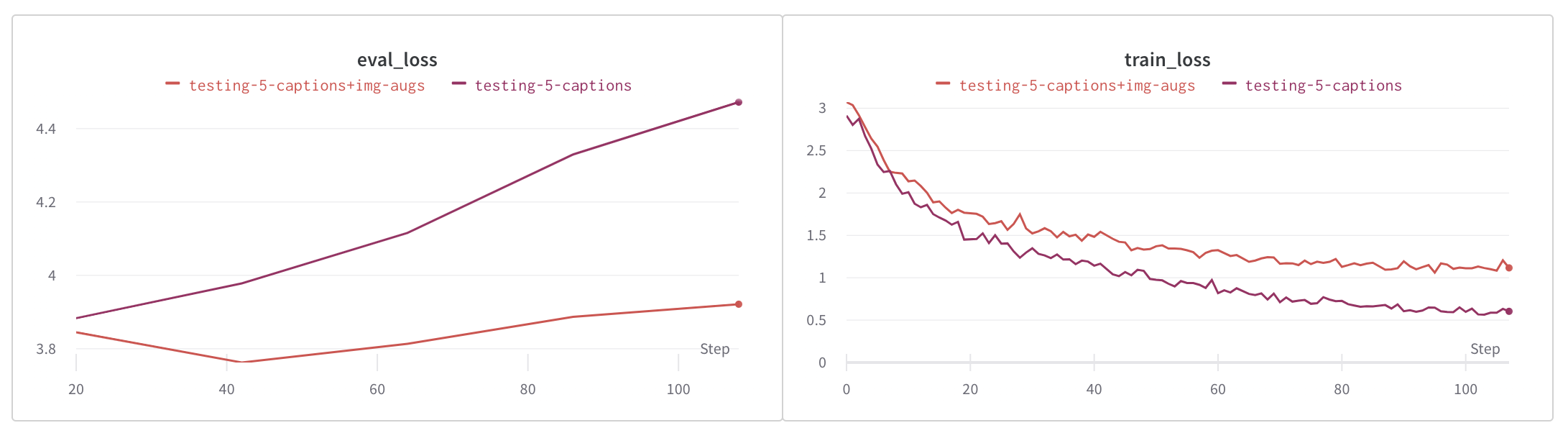
為了對資料集進行正則化並防止由於資料集大小造成的過擬合,我們使用了影像和文字增強兩種方法。
影像增強是使用 Pytorch 的 Torchvision 包中的內建轉換進行內聯完成的。使用的轉換包括隨機裁剪、隨機調整大小和裁剪、顏色抖動以及隨機水平和垂直翻轉。
我們透過反向翻譯增強了文字,以生成每張影像少於 5 個獨特說明的影像的說明。Hugging Face 的 Marian MT 系列模型用於將現有說明翻譯成法語、西班牙語、義大利語和葡萄牙語,然後再翻譯回英語,以補充這些影像的說明。
如下圖所示,影像增強顯著減少了過擬合,而文字和影像增強則進一步減少了過擬合。
評估
指標
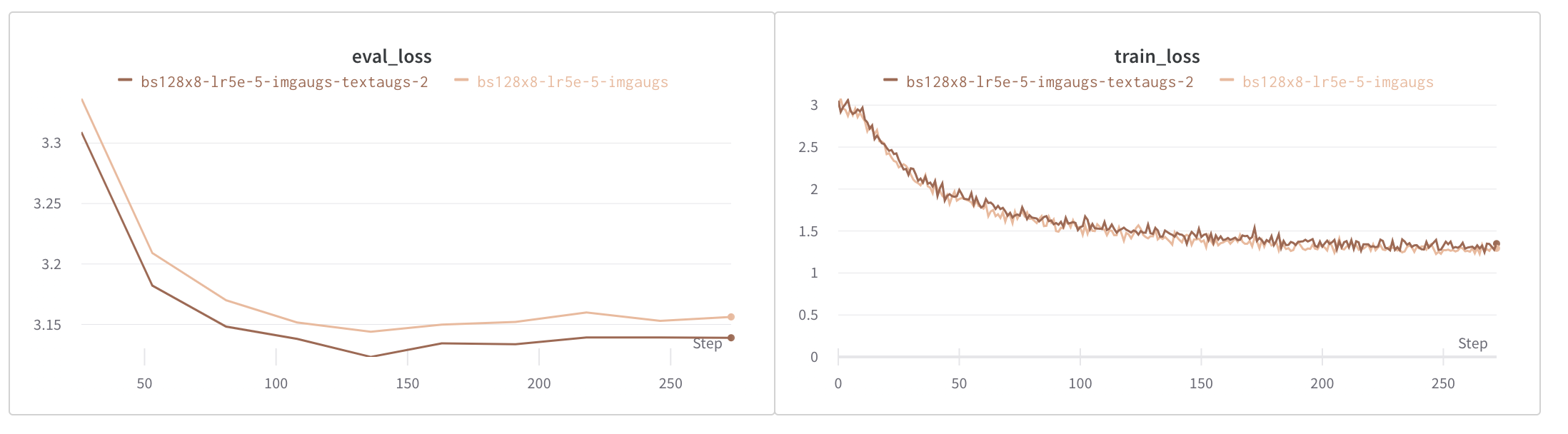
RSICD 測試集的子集用於評估。我們在此子集中發現了 30 種影像類別。評估透過將每張影像與一組 30 個形式為 "An aerial photograph of {category}" 的說明句子進行比較來完成。模型生成了 30 個說明的排序列表,從最相關到最不相關。對應於得分最高的 k 個說明(k=1、3、5 和 10)的類別與透過影像檔名提供的類別進行比較。分數在用於評估的整組影像上進行平均,並針對各種 k 值進行報告,如下所示。
baseline 模型代表預訓練的 openai/clip-vit-base-path32 CLIP 模型。該模型使用 RSICD 資料集中的說明和影像進行微調,從而顯著提升了效能,如下所示。
我們最好的模型是在影像和文字增強下訓練的,批處理大小為 1024(8 個 TPU 核心上每個 128),並使用 Adam 最佳化器,學習率為 5e-6。我們的第二個基礎模型使用相同的超引數訓練,但我們使用了 Adafactor 最佳化器,學習率為 1e-4。您可以從下表中連結的模型儲存庫下載任一模型。
| 模型名稱 | k=1 | k=3 | k=5 | k=10 |
|---|---|---|---|---|
| 基準 | 0.572 | 0.745 | 0.837 | 0.939 |
| bs128x8-lr1e-4-augs/ckpt-2 | 0.819 | 0.950 | 0.974 | 0.994 |
| bs128x8-lr1e-4-imgaugs/ckpt-2 | 0.812 | 0.942 | 0.970 | 0.991 |
| bs128x8-lr1e-4-imgaugs-textaugs/ckpt-42 | 0.843 | 0.958 | 0.977 | 0.993 |
| bs128x8-lr5e-5-imgaugs-textaugs/ckpt-8 | 0.831 | 0.959 | 0.977 | 0.994 |
| bs128x8-lr5e-5-imgaugs/ckpt-4 | 0.746 | 0.906 | 0.956 | 0.989 |
| bs128x8-lr5e-5-imgaugs-textaugs-2/ckpt-4 | 0.811 | 0.945 | 0.972 | 0.993 |
| bs128x8-lr5e-5-imgaugs-textaugs-3/ckpt-5 | 0.823 | 0.946 | 0.971 | 0.992 |
| bs128x8-lr5e-5-wd02/ckpt-4 | 0.820 | 0.946 | 0.965 | 0.990 |
| bs128x8-lr5e-6-adam/ckpt-11 | 0.883 | 0.968 | 0.982 | 0.998 |
1 - 我們最好的模型,2 - 我們第二好的模型
演示
您可以在這裡訪問 CLIP-RSICD 演示。它使用我們微調過的 CLIP 模型提供以下功能:
- 文字到影像搜尋
- 影像到影像搜尋
- 在影像中查詢文字特徵
前兩個功能使用 RSICD 測試集作為其影像語料庫。它們使用我們微調過的最佳 CLIP 模型進行編碼,並存儲在 NMSLib 索引中,該索引允許基於近似最近鄰的檢索。對於文字到影像和影像到影像搜尋,查詢文字或影像分別使用我們的模型進行編碼,並與語料庫中的影像向量進行匹配。對於第三個功能,我們將傳入的影像分成多個補丁並對其進行編碼,編碼查詢的文字特徵,將文字向量與每個影像補丁向量進行匹配,並返回在每個補丁中找到該特徵的機率。
未來工作
我們很高興有機會進一步完善我們的模型。我們未來工作的一些想法如下:
- 使用 CLIP 編碼器和 GPT-3 解碼器構建一個序列到序列的模型,並將其訓練用於影像字幕。
- 在來自其他資料集的更多影像字幕對上微調模型,並研究我們是否可以提高其效能。
- 調查微調如何影響模型在非 RSICD 影像字幕對上的效能。
- 調查微調模型對它未曾微調過的類別進行分類的能力。
- 使用其他標準(如影像分類)評估模型。


