使用 🤗 Transformers 微調 Whisper 模型以實現多語言 ASR







在本部落格中,我們使用 Hugging Face 🤗 Transformers 為任意多語言 ASR 資料集微調 Whisper 提供了分步指南。本部落格深入解釋了 Whisper 模型、Common Voice 資料集和微調背後的理論,並附有程式碼單元格來執行資料準備和微調步驟。如果需要一個解釋較少但包含所有程式碼的精簡版筆記,請參閱隨附的 Google Colab。
目錄
引言
Whisper 是 OpenAI 的 Alec Radford 等作者於 2022 年 9 月釋出的用於自動語音識別 (ASR) 的預訓練模型。與許多前輩模型(如 Wav2Vec 2.0)不同,後者是在未標記的音訊資料上進行預訓練,而 Whisper 是在大量已標記的音訊轉錄資料上進行預訓練的,準確地說是 68 萬小時。這比用於訓練 Wav2Vec 2.0 的未標記音訊資料(6 萬小時)要多一個數量級。更重要的是,這 68 萬小時的預訓練資料中有 11.7 萬小時是多語言 ASR 資料。這使得模型檢查點可以應用於超過 96 種語言,其中許多被認為是低資源語言。
如此大量的標註資料使 Whisper 能夠直接在語音識別的監督任務上進行預訓練,從標註的音訊-轉錄預訓練資料中學習語音到文字的對映關係。因此,Whisper 只需要很少的額外微調就能產出一個高效能的 ASR 模型。這與 Wav2Vec 2.0 形成對比,後者是在無監督的掩碼預測任務上預訓練的。在這種情況下,模型被訓練來僅從無標籤的音訊資料中學習從語音到隱藏狀態的中間對映。雖然無監督預訓練能產生高質量的語音表示,但它不會學習語音到文字的對映。這個對映只在微調期間學習,因此需要更多的微調才能獲得有競爭力的效能。
當擴充套件到 68 萬小時的標記預訓練資料時,Whisper 模型展現出強大的泛化能力,能夠適應多種資料集和領域。這些預訓練檢查點在效能上能與最先進的 ASR 系統相媲美,在 LibriSpeech ASR 的 test-clean 子集上達到了接近 3% 的詞錯誤率(WER),並在 TED-LIUM 上以 4.7% 的 WER 創造了新的 SOTA(c.f. Whisper 論文的表 8)。Whisper 在預訓練期間獲得的廣泛多語言 ASR 知識可以被用於其他低資源語言;透過微調,預訓練的檢查點可以適應特定的資料集和語言,以進一步提升這些結果。
Whisper 是一個基於 Transformer 的編碼器-解碼器模型,也稱為序列到序列模型。它將音訊頻譜特徵的序列對映到文字詞元的序列。首先,原始音訊輸入透過特徵提取器的作用被轉換為對數梅爾頻譜圖。然後,Transformer 編碼器對頻譜圖進行編碼,形成一個編碼器隱藏狀態的序列。最後,解碼器自迴歸地預測文字詞元,其條件是之前的詞元和編碼器的隱藏狀態。圖 1 概述了 Whisper 模型。

在序列到序列模型中,編碼器將音訊輸入轉換為一組隱藏狀態表示,從語音中提取重要特徵。解碼器扮演語言模型的角色,處理隱藏狀態表示並生成相應的文字轉錄。在系統架構中內部整合語言模型被稱為深度融合。這與淺層融合形成對比,後者是將語言模型與編碼器外部結合,例如 CTC + -gram(c.f. Internal Language Model Estimation)。透過深度融合,整個系統可以使用相同的訓練資料和損失函式進行端到端訓練,從而提供更大的靈活性和通常更優越的效能(c.f. ESB Benchmark)。
Whisper 使用交叉熵目標函式進行預訓練和微調,這是訓練序列到序列系統進行分類任務的標準目標函式。在這裡,系統被訓練以從預定義的文字詞元詞彙表中正確分類目標文字詞元。
Whisper 檢查點有五種不同模型大小的配置。最小的四種是在純英語或多語言資料上訓練的。最大的檢查點僅為多語言。所有 11 個預訓練檢查點都可以在 Hugging Face Hub 上找到。下表總結了這些檢查點,並附有 Hub 上模型的連結。
| 大小 | 層數 | 寬度 | 注意力頭數 | 引數量 | 僅英語 | 多語言 |
|---|---|---|---|---|---|---|
| tiny | 4 | 384 | 6 | 39 M | ✓ | ✓ |
| base | 6 | 512 | 8 | 74 M | ✓ | ✓ |
| small | 12 | 768 | 12 | 244 M | ✓ | ✓ |
| medium | 24 | 1024 | 16 | 769 M | ✓ | ✓ |
| large | 32 | 1280 | 20 | 1550 M | x | ✓ |
| large-v2 | 32 | 1280 | 20 | 1550 M | x | ✓ |
| large-v3 | 32 | 1280 | 20 | 1550 M | x | ✓ |
出於演示目的,我們將微調多語言版本的 small 檢查點,其引數量為 244M (約 1GB)。至於我們的資料,我們將在 Common Voice 資料集中的一種低資源語言上訓練和評估我們的系統。我們將展示,僅用 8 小時的微調資料,我們就能在該語言上取得強大的效能。
Whisper 這個名字來源於縮寫“WSPSR”,代表“Web-scale Supervised Pre-training for Speech Recognition”(網路規模的監督式語音識別預訓練)。
在 Google Colab 中微調 Whisper
準備環境
我們將使用幾個流行的 Python 包來微調 Whisper 模型。我們將使用 `datasets[audio]` 來下載和準備我們的訓練資料,同時使用 `transformers` 和 `accelerate` 來載入和訓練我們的 Whisper 模型。我們還需要 `soundfile` 包來預處理音訊檔案,`evaluate` 和 `jiwer` 來評估我們模型的效能,以及 `tensorboard` 來記錄我們的指標。最後,我們將使用 `gradio` 為我們微調的模型構建一個酷炫的演示。
!pip install --upgrade pip
!pip install --upgrade datasets[audio] transformers accelerate evaluate jiwer tensorboard gradio
我們強烈建議您在訓練期間將模型檢查點直接上傳到 Hugging Face Hub。Hub 提供:
- 整合的版本控制:你可以確保在訓練過程中不會丟失任何模型檢查點。
- Tensorboard 日誌:在訓練過程中跟蹤重要指標。
- 模型卡片:記錄模型的功能及其預期用途。
- 社群:與社群分享和協作的便捷方式!
將筆記本連結到 Hub 非常簡單——只需在提示時輸入您的 Hub 身份驗證令牌即可。在此處找到您的 Hub 身份驗證令牌 here
from huggingface_hub import notebook_login
notebook_login()
列印輸出
Login successful
Your token has been saved to /root/.huggingface/token
載入資料集
Common Voice 是一系列眾包資料集,其中說話者用各種語言錄製維基百科的文字。我們將使用撰寫本文時 Common Voice 資料集的最新版本(版本 11)。至於我們的語言,我們將在 印地語上微調我們的模型,這是一種在印度北部、中部、東部和西部使用的印度-雅利安語。Common Voice 11.0 包含大約 12 小時的已標記印地語資料,其中 4 小時是保留的測試資料。
提示:您可以透過檢視 Hugging Face Hub 上的 Mozilla Foundation 組織頁面來找到 Common Voice 資料集的最新版本。較新版本涵蓋更多語言,並且每種語言包含更多資料。
讓我們前往 Hub 並檢視 Common Voice 的資料集頁面:mozilla-foundation/common_voice_11_0。
我們第一次檢視此頁面時,會被要求接受使用條款。之後,我們將獲得對資料集的完全訪問許可權。
一旦我們提供了使用資料集的身份驗證,我們將看到資料集預覽。資料集預覽向我們展示了資料集的前 100 個樣本。更重要的是,它載入了音訊樣本,供我們即時收聽。我們可以透過下拉選單將子集設定為 `hi` 來選擇 Common Voice 的印地語子集(`hi` 是印地語的語言識別符號程式碼)。
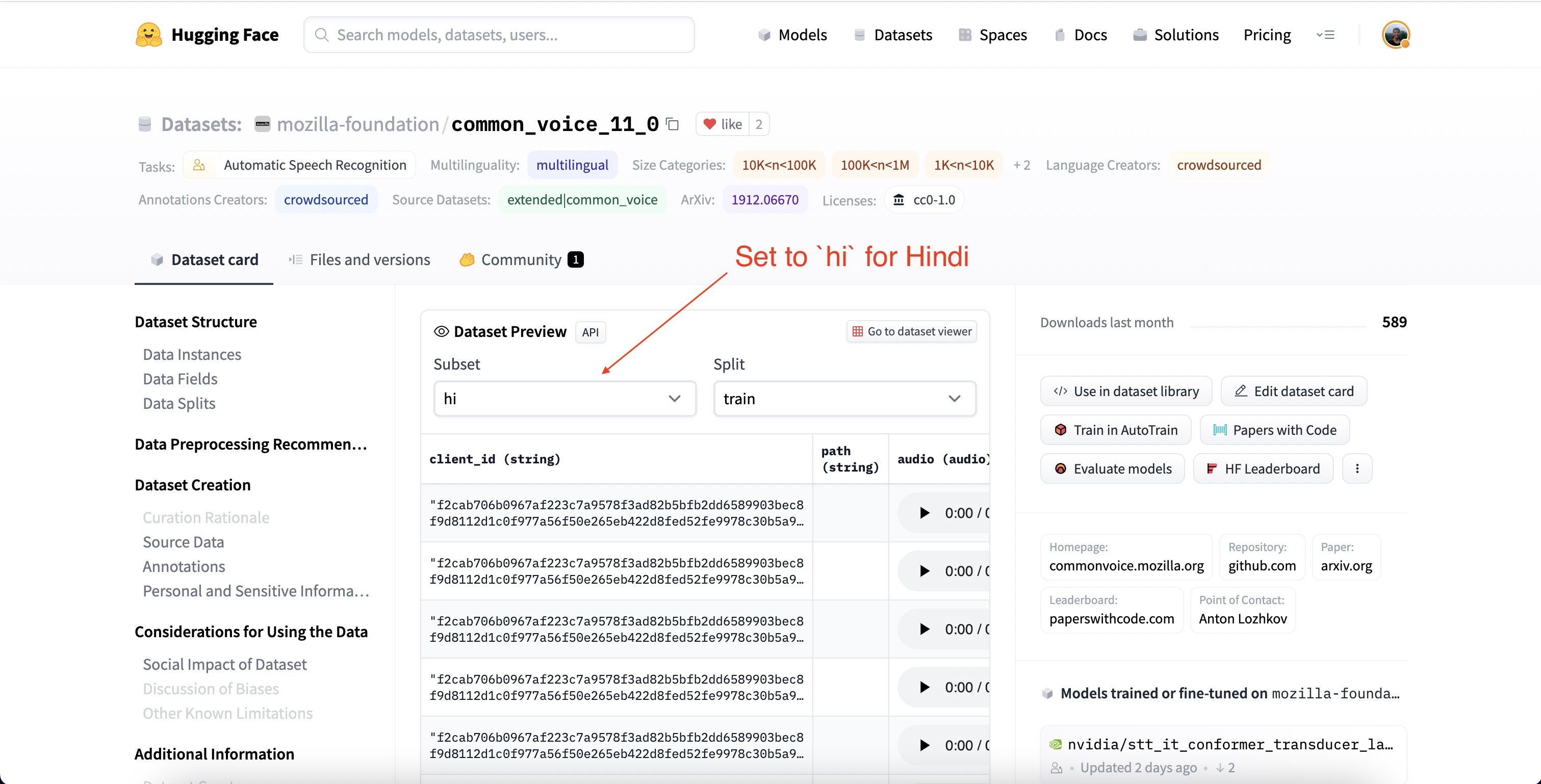
如果我們點選第一個樣本的播放按鈕,我們可以收聽音訊並檢視相應的文字。請滾動瀏覽訓練集和測試集的樣本,以便更好地瞭解我們正在處理的音訊和文字資料。從語調和風格可以看出,這些錄音來自旁白語音。您可能還會注意到說話者和錄音質量的巨大差異,這是眾包資料的常見特徵。
使用 🤗 Datasets,下載和準備資料非常簡單。我們只需一行程式碼就可以下載和準備 Common Voice 的各個資料分割。由於印地語資源非常有限,我們將合併 `train` 和 `validation` 分割,以提供大約 8 小時的訓練資料。我們將使用 4 小時的 `test` 資料作為我們的保留測試集。
from datasets import load_dataset, DatasetDict
common_voice = DatasetDict()
common_voice["train"] = load_dataset("mozilla-foundation/common_voice_11_0", "hi", split="train+validation", use_auth_token=True)
common_voice["test"] = load_dataset("mozilla-foundation/common_voice_11_0", "hi", split="test", use_auth_token=True)
print(common_voice)
列印輸出
DatasetDict({
train: Dataset({
features: ['client_id', 'path', 'audio', 'sentence', 'up_votes', 'down_votes', 'age', 'gender', 'accent', 'locale', 'segment'],
num_rows: 6540
})
test: Dataset({
features: ['client_id', 'path', 'audio', 'sentence', 'up_votes', 'down_votes', 'age', 'gender', 'accent', 'locale', 'segment'],
num_rows: 2894
})
})
大多數 ASR 資料集只提供輸入音訊樣本(`audio`)和相應的轉錄文字(`sentence`)。Common Voice 包含額外的元資料資訊,如 `accent` 和 `locale`,我們可以在 ASR 中忽略這些資訊。為了使筆記本儘可能通用,我們只考慮輸入音訊和轉錄文字進行微調,丟棄額外的元資料資訊。
common_voice = common_voice.remove_columns(["accent", "age", "client_id", "down_votes", "gender", "locale", "path", "segment", "up_votes"])
Common Voice 只是我們可以從 Hub 下載的眾多多語言 ASR 資料集之一——還有更多可供我們選擇!要檢視可用於語音識別的資料集範圍,請點選連結:Hub 上的 ASR 資料集。
準備特徵提取器、分詞器和資料
ASR 流程可以分解為三個部分:
- 一個對原始音訊輸入進行預處理的特徵提取器。
- 執行序列到序列對映的模型
- 一個將模型輸出後處理成文字格式的分詞器
在 🤗 Transformers 中,Whisper 模型有一個相關的特徵提取器和分詞器,分別稱為 WhisperFeatureExtractor 和 WhisperTokenizer。
我們將逐一詳細介紹特徵提取器和分詞器!
載入 WhisperFeatureExtractor
語音由一個隨時間變化的一維陣列表示。陣列在任何給定時間步的值是訊號在該點的振幅。僅憑振幅資訊,我們就可以重建音訊的頻譜並恢復所有的聲學特徵。
由於語音是連續的,它包含無限多個振幅值。這給期望有限陣列的計算機裝置帶來了問題。因此,我們透過在固定的時間步長從訊號中取樣值來離散化我們的語音訊號。我們取樣音訊的間隔稱為取樣率,通常以樣本/秒或赫茲 (Hz) 為單位。以更高的取樣率取樣可以更好地逼近連續的語音訊號,但每秒也需要儲存更多的值。
將我們的音訊輸入取樣率與模型期望的取樣率相匹配至關重要,因為具有不同取樣率的音訊訊號具有非常不同的分佈。音訊樣本應始終以正確的取樣率進行處理。否則可能導致意想不到的結果!例如,以 16kHz 的取樣率採集音訊樣本,並以 8kHz 的取樣率播放,會使音訊聽起來像是半速播放。同樣,傳遞錯誤取樣率的音訊會使期望一種取樣率而接收到另一種取樣率的 ASR 模型失效。Whisper 特徵提取器期望音訊輸入的取樣率為 16kHz,因此我們需要將輸入匹配到這個值。我們不希望無意中用慢動作語音訓練 ASR 系統!
Whisper 特徵提取器執行兩個操作。它首先對一批音訊樣本進行填充/截斷,使所有樣本的輸入長度都為 30 秒。短於 30 秒的樣本透過在序列末尾附加零來填充到 30 秒(音訊訊號中的零對應於無訊號或靜音)。長於 30 秒的樣本被截斷為 30 秒。由於批次中的所有元素都在輸入空間中被填充/截斷到最大長度,因此在將音訊輸入轉發給 Whisper 模型時,我們不需要注意力掩碼。Whisper 在這方面是獨特的——對於大多數音訊模型,您需要提供一個注意力掩碼,詳細說明序列被填充的位置,從而在自注意力機制中應被忽略的位置。Whisper 被訓練為在沒有注意力掩碼的情況下執行,並直接從語音訊號中推斷出忽略輸入的位置。
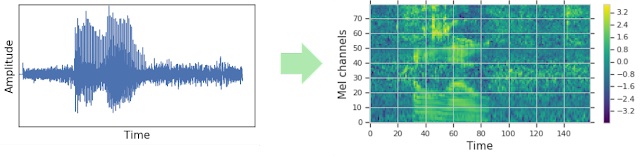
Whisper 特徵提取器執行的第二個操作是將填充後的音訊陣列轉換為對數-梅爾頻譜圖。這些頻譜圖是訊號頻率的視覺表示,有點像傅立葉變換。圖 2 顯示了一個示例頻譜圖。 軸是梅爾通道,對應於特定的頻率區間。 軸是時間。每個畫素的顏色對應於給定時間該頻率區間的對數強度。對數-梅爾頻譜圖是 Whisper 模型期望的輸入形式。
梅爾通道(頻率區間)在語音處理中是標準配置,其選擇旨在近似人類聽覺範圍。對於 Whisper 微調,我們只需要知道頻譜圖是語音訊號中頻率的視覺表示。有關梅爾通道的更多詳細資訊,請參閱梅爾頻率倒譜。
幸運的是,🤗 Transformers 的 Whisper 特徵提取器只需一行程式碼就能完成填充和頻譜圖轉換!讓我們從預訓練檢查點載入特徵提取器,為我們的音訊資料做好準備。
from transformers import WhisperFeatureExtractor
feature_extractor = WhisperFeatureExtractor.from_pretrained("openai/whisper-small")
載入 WhisperTokenizer
現在讓我們看看如何載入 Whisper 分詞器。Whisper 模型輸出的文字詞元表示預測文字在詞彙表中的索引。分詞器將一串文字詞元對映到實際的文字字串(例如 [1169, 3797, 3332] -> "the cat sat")。
傳統上,當使用僅編碼器模型進行 ASR 時,我們使用連線主義時間分類 (CTC)進行解碼。在這裡,我們需要為我們使用的每個資料集訓練一個 CTC 分詞器。使用編碼器-解碼器架構的優勢之一是我們可以直接利用預訓練模型的分詞器。
Whisper 分詞器是在 96 種預訓練語言的轉錄文字上預訓練的。因此,它有一個廣泛的位元組對,適用於幾乎所有的多語言 ASR 應用。對於印地語,我們可以載入分詞器並將其用於微調,無需任何進一步修改。我們只需指定目標語言和任務。這些引數會通知分詞器在編碼的標籤序列的開頭加上語言和任務詞元。
from transformers import WhisperTokenizer
tokenizer = WhisperTokenizer.from_pretrained("openai/whisper-small", language="Hindi", task="transcribe")
提示: 透過將上述程式碼行中的任務設定為
"translate",並將語言設定為目標文字語言,本部落格文章可以適用於語音翻譯。這將在預處理資料集時,為語音翻譯任務預置相關的任務和語言詞元。
我們可以透過編碼和解碼 Common Voice 資料集的第一個樣本來驗證分詞器是否能正確編碼印地語字元。在對轉錄文字進行編碼時,分詞器會在序列的開頭和結尾附加“特殊詞元”,包括轉錄開始/結束詞元、語言詞元和任務詞元(如上一步驟中的引數所指定)。在解碼標籤 ID 時,我們可以選擇“跳過”這些特殊詞元,從而以原始輸入形式返回一個字串。
input_str = common_voice["train"][0]["sentence"]
labels = tokenizer(input_str).input_ids
decoded_with_special = tokenizer.decode(labels, skip_special_tokens=False)
decoded_str = tokenizer.decode(labels, skip_special_tokens=True)
print(f"Input: {input_str}")
print(f"Decoded w/ special: {decoded_with_special}")
print(f"Decoded w/out special: {decoded_str}")
print(f"Are equal: {input_str == decoded_str}")
列印輸出
Input: खीर की मिठास पर गरमाई बिहार की सियासत, कुशवाहा ने दी सफाई
Decoded w/ special: <|startoftranscript|><|hi|><|transcribe|><|notimestamps|>खीर की मिठास पर गरमाई बिहार की सियासत, कुशवाहा ने दी सफाई<|endoftext|>
Decoded w/out special: खीर की मिठास पर गरमाई बिहार की सियासत, कुशवाहा ने दी सफाई
Are equal: True
合併建立 WhisperProcessor
為了簡化特徵提取器和分詞器的使用,我們可以將兩者封裝到一個單獨的 `WhisperProcessor` 類中。這個處理器物件繼承自 `WhisperFeatureExtractor` 和 `WhisperProcessor`,可以根據需要用於音訊輸入和模型預測。這樣做,我們在訓練期間只需要跟蹤兩個物件:`processor` 和 `model`。
from transformers import WhisperProcessor
processor = WhisperProcessor.from_pretrained("openai/whisper-small", language="Hindi", task="transcribe")
準備資料
讓我們列印 Common Voice 資料集的第一個例子,看看資料的形式。
print(common_voice["train"][0])
列印輸出
{'audio': {'path': '/home/sanchit_huggingface_co/.cache/huggingface/datasets/downloads/extracted/607848c7e74a89a3b5225c0fa5ffb9470e39b7f11112db614962076a847f3abf/cv-corpus-11.0-2022-09-21/hi/clips/common_voice_hi_25998259.mp3',
'array': array([0.0000000e+00, 0.0000000e+00, 0.0000000e+00, ..., 9.6724887e-07,
1.5334779e-06, 1.0415988e-06], dtype=float32),
'sampling_rate': 48000},
'sentence': 'खीर की मिठास पर गरमाई बिहार की सियासत, कुशवाहा ने दी सफाई'}
我們可以看到,我們有一個一維的輸入音訊陣列和相應的目標轉錄文字。我們已經重點討論了取樣率的重要性,以及我們需要將音訊的取樣率與 Whisper 模型的取樣率(16kHz)相匹配。由於我們的輸入音訊取樣率為 48kHz,我們需要在將其傳遞給 Whisper 特徵提取器之前,將其下采樣到 16kHz。
我們將使用資料集的 `cast_column` 方法將音訊輸入設定為正確的取樣率。此操作不會就地更改音訊,而是向 `datasets` 發出訊號,在音訊樣本首次載入時動態地重新取樣。
from datasets import Audio
common_voice = common_voice.cast_column("audio", Audio(sampling_rate=16000))
重新載入 Common Voice 資料集中的第一個音訊樣本會將其重新取樣到所需的取樣率。
print(common_voice["train"][0])
列印輸出
{'audio': {'path': '/home/sanchit_huggingface_co/.cache/huggingface/datasets/downloads/extracted/607848c7e74a89a3b5225c0fa5ffb9470e39b7f11112db614962076a847f3abf/cv-corpus-11.0-2022-09-21/hi/clips/common_voice_hi_25998259.mp3',
'array': array([ 0.0000000e+00, 0.0000000e+00, 0.0000000e+00, ...,
-3.4206650e-07, 3.2979898e-07, 1.0042874e-06], dtype=float32),
'sampling_rate': 16000},
'sentence': 'खीर की मिठास पर गरमाई बिहार की सियासत, कुशवाहा ने दी सफाई'}
太棒了!我們可以看到取樣率已經下采樣到 16kHz。陣列的值也不同了,因為我們現在大約每三個舊值才有一個振幅值。
現在我們可以編寫一個函式來為模型準備資料。
- 我們透過呼叫 `batch["audio"]` 來載入和重取樣音訊資料。如上所述,🤗 Datasets 會動態執行任何必要的重取樣操作。
- 我們使用特徵提取器從我們的一維音訊陣列中計算對數-梅爾頻譜圖輸入特徵。
- 我們透過使用分詞器將轉錄文字編碼為標籤 ID。
def prepare_dataset(batch):
# load and resample audio data from 48 to 16kHz
audio = batch["audio"]
# compute log-Mel input features from input audio array
batch["input_features"] = feature_extractor(audio["array"], sampling_rate=audio["sampling_rate"]).input_features[0]
# encode target text to label ids
batch["labels"] = tokenizer(batch["sentence"]).input_ids
return batch
我們可以使用資料集的 `.map` 方法將資料準備函式應用於我們所有的訓練樣本。
common_voice = common_voice.map(prepare_dataset, remove_columns=common_voice.column_names["train"], num_proc=4)
好的!這樣我們就為訓練做好了充分的資料準備!讓我們繼續看看如何使用這些資料來微調 Whisper。
注意:目前 `datasets` 同時使用 `torchaudio` 和 `librosa` 進行音訊載入和重取樣。如果您希望實現自己的定製化資料載入/取樣,可以使用 `"path"` 列獲取音訊檔案路徑並忽略 `"audio"` 列。
訓練與評估
現在我們已經準備好了資料,可以深入研究訓練流程了。 🤗 Trainer 將為我們完成大部分繁重的工作。我們只需要做的是:
載入預訓練檢查點:我們需要載入一個預訓練檢查點併為其正確配置訓練。
定義資料整理器:資料整理器接收我們預處理過的資料,並準備好供模型使用的 PyTorch 張量。
評估指標:在評估期間,我們希望使用詞錯誤率 (WER) 指標來評估模型。我們需要定義一個 `compute_metrics` 函式來處理這個計算。
定義訓練引數:這些引數將由 🤗 Trainer 用於構建訓練計劃。
一旦我們微調了模型,我們將在測試資料上對其進行評估,以驗證我們是否已正確地訓練它來轉錄印地語語音。
載入預訓練檢查點
我們將從預訓練的 Whisper `small` 檢查點開始我們的微調執行。為此,我們將從 Hugging Face Hub 載入預訓練的權重。同樣,透過使用 🤗 Transformers,這非常簡單!
from transformers import WhisperForConditionalGeneration
model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-small")
在推理時,Whisper 模型會自動檢測源音訊的語言,並預測該語言的詞元 ID。在源音訊語言已知的情況下,例如多語言微調,顯式設定語言是有益的。這可以避免預測錯誤語言的情況,從而導致預測文字在生成過程中偏離真實語言。為此,我們將 langauge 和 task 引數設定為生成配置。我們還將任何 `forced_decoder_ids` 設定為 None,因為這是設定語言和任務引數的舊方法。
model.generation_config.language = "hindi"
model.generation_config.task = "transcribe"
model.generation_config.forced_decoder_ids = None
定義資料整理器
序列到序列語音模型的資料整理器是獨特的,因為它獨立處理 `input_features` 和 `labels`:`input_features` 必須由特徵提取器處理,而 `labels` 必須由分詞器處理。
`input_features` 已經被填充到 30 秒並轉換為固定維度的對數-梅爾頻譜圖,所以我們只需將它們轉換為批處理的 PyTorch 張量。我們使用特徵提取器的 `.pad` 方法並設定 `return_tensors=pt` 來實現這一點。請注意,這裡沒有應用額外的填充,因為輸入是固定維度的,`input_features` 只是被轉換為 PyTorch 張量。
另一方面,`labels` 是未填充的。我們首先使用分詞器的 `.pad` 方法將序列填充到批次中的最大長度。然後將填充詞元替換為 `-100`,這樣在計算損失時就不會考慮這些詞元。然後我們從標籤序列的開頭剪掉轉錄開始詞元,因為我們稍後會在訓練中附加它。
我們可以利用我們之前定義的 `WhisperProcessor` 來執行特徵提取器和分詞器的操作。
import torch
from dataclasses import dataclass
from typing import Any, Dict, List, Union
@dataclass
class DataCollatorSpeechSeq2SeqWithPadding:
processor: Any
decoder_start_token_id: int
def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
# split inputs and labels since they have to be of different lengths and need different padding methods
# first treat the audio inputs by simply returning torch tensors
input_features = [{"input_features": feature["input_features"]} for feature in features]
batch = self.processor.feature_extractor.pad(input_features, return_tensors="pt")
# get the tokenized label sequences
label_features = [{"input_ids": feature["labels"]} for feature in features]
# pad the labels to max length
labels_batch = self.processor.tokenizer.pad(label_features, return_tensors="pt")
# replace padding with -100 to ignore loss correctly
labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
# if bos token is appended in previous tokenization step,
# cut bos token here as it's append later anyways
if (labels[:, 0] == self.decoder_start_token_id).all().cpu().item():
labels = labels[:, 1:]
batch["labels"] = labels
return batch
讓我們初始化我們剛剛定義的資料整理器。
data_collator = DataCollatorSpeechSeq2SeqWithPadding(
processor=processor,
decoder_start_token_id=model.config.decoder_start_token_id,
)
評估指標
接下來,我們定義將在評估集上使用的評估指標。我們將使用詞錯誤率 (WER) 指標,這是評估 ASR 系統的“事實標準”指標。更多資訊,請參閱 WER 文件。我們將從 🤗 Evaluate 載入 WER 指標。
import evaluate
metric = evaluate.load("wer")
然後我們只需定義一個函式,該函式接收我們的模型預測並返回 WER 指標。這個名為 `compute_metrics` 的函式首先在 `label_ids` 中將 `-100` 替換為 `pad_token_id`(撤銷我們在資料整理器中為在損失中正確忽略填充詞元而應用的步驟)。然後它將預測的 ID 和標籤 ID 解碼為字串。最後,它計算預測和參考標籤之間的 WER。
def compute_metrics(pred):
pred_ids = pred.predictions
label_ids = pred.label_ids
# replace -100 with the pad_token_id
label_ids[label_ids == -100] = tokenizer.pad_token_id
# we do not want to group tokens when computing the metrics
pred_str = tokenizer.batch_decode(pred_ids, skip_special_tokens=True)
label_str = tokenizer.batch_decode(label_ids, skip_special_tokens=True)
wer = 100 * metric.compute(predictions=pred_str, references=label_str)
return {"wer": wer}
定義訓練引數
在最後一步,我們定義所有與訓練相關的引數。下面解釋了部分引數:
- `output_dir`:儲存模型權重的本地目錄。這也將是 Hugging Face Hub 上的倉庫名稱。
- `generation_max_length`:評估期間自迴歸生成的最大詞元數。
- `save_steps`:訓練期間,每 `save_steps` 個訓練步驟,中間檢查點將被儲存並非同步上傳到 Hub。
- `eval_steps`:訓練期間,每 `eval_steps` 個訓練步驟,將對中間檢查點進行評估。
- `report_to`:儲存訓練日誌的位置。支援的平臺有 `"azure_ml"`、`"comet_ml"`、`"mlflow"`、`"neptune"`、`"tensorboard"` 和 `"wandb"`。選擇你喜歡的,或者保留為 `"tensorboard"` 以記錄到 Hub。
有關其他訓練引數的更多詳細資訊,請參閱 Seq2SeqTrainingArguments 文件。
from transformers import Seq2SeqTrainingArguments
training_args = Seq2SeqTrainingArguments(
output_dir="./whisper-small-hi", # change to a repo name of your choice
per_device_train_batch_size=16,
gradient_accumulation_steps=1, # increase by 2x for every 2x decrease in batch size
learning_rate=1e-5,
warmup_steps=500,
max_steps=5000,
gradient_checkpointing=True,
fp16=True,
evaluation_strategy="steps",
per_device_eval_batch_size=8,
predict_with_generate=True,
generation_max_length=225,
save_steps=1000,
eval_steps=1000,
logging_steps=25,
report_to=["tensorboard"],
load_best_model_at_end=True,
metric_for_best_model="wer",
greater_is_better=False,
push_to_hub=True,
)
注意:如果不想將模型檢查點上傳到 Hub,請設定 `push_to_hub=False`。
我們可以將訓練引數以及我們的模型、資料集、資料整理器和 `compute_metrics` 函式轉發給 🤗 Trainer。
from transformers import Seq2SeqTrainer
trainer = Seq2SeqTrainer(
args=training_args,
model=model,
train_dataset=common_voice["train"],
eval_dataset=common_voice["test"],
data_collator=data_collator,
compute_metrics=compute_metrics,
tokenizer=processor.feature_extractor,
)
這樣,我們就可以開始訓練了!
訓練
要啟動訓練,只需執行:
trainer.train()
訓練將需要大約 5-10 小時,具體取決於您的 GPU 或分配給 Google Colab 的 GPU。根據您的 GPU,開始訓練時可能會遇到 CUDA `"out-of-memory"` 錯誤。在這種情況下,您可以將 `per_device_train_batch_size` 遞減 2 的倍數,並使用 `gradient_accumulation_steps` 來補償。
列印輸出
| 步驟 | 訓練損失 | 輪次 | 驗證損失 | WER |
|---|---|---|---|---|
| 1000 | 0.1011 | 2.44 | 0.3075 | 34.63 |
| 2000 | 0.0264 | 4.89 | 0.3558 | 33.13 |
| 3000 | 0.0025 | 7.33 | 0.4214 | 32.59 |
| 4000 | 0.0006 | 9.78 | 0.4519 | 32.01 |
| 5000 | 0.0002 | 12.22 | 0.4679 | 32.10 |
在 4000 個訓練步驟後,我們最好的 WER 是 32.0%。作為參考,預訓練的 Whisper `small` 模型達到了 63.5% 的 WER,這意味著我們透過微調實現了 31.5% 的絕對改進。對於僅 8 小時的訓練資料來說,這相當不錯!
現在我們準備在 Hugging Face Hub 上分享我們微調過的模型。為了使其更易於訪問,並帶有適當的標籤和 README 資訊,我們可以在推送時設定適當的關鍵字引數(kwargs)。您可以根據您的資料集、語言和模型名稱更改這些值。
kwargs = {
"dataset_tags": "mozilla-foundation/common_voice_11_0",
"dataset": "Common Voice 11.0", # a 'pretty' name for the training dataset
"dataset_args": "config: hi, split: test",
"language": "hi",
"model_name": "Whisper Small Hi - Sanchit Gandhi", # a 'pretty' name for your model
"finetuned_from": "openai/whisper-small",
"tasks": "automatic-speech-recognition",
}
現在可以將訓練結果上傳到 Hub。為此,請執行 `push_to_hub` 命令。
trainer.push_to_hub(**kwargs)
現在,您可以使用 Hub 上的連結與任何人分享此模型。他們也可以使用識別符號 `"your-username/the-name-you-picked"` 載入它,例如:
from transformers import WhisperForConditionalGeneration, WhisperProcessor
model = WhisperForConditionalGeneration.from_pretrained("sanchit-gandhi/whisper-small-hi")
processor = WhisperProcessor.from_pretrained("sanchit-gandhi/whisper-small-hi")
雖然微調後的模型在 Common Voice 印地語測試資料上取得了令人滿意的結果,但它絕不是最優的。本筆記本的目的是演示如何將預訓練的 Whisper 檢查點微調到任何多語言 ASR 資料集上。透過最佳化訓練超引數,如學習率和丟棄率,並使用更大的預訓練檢查點(`medium` 或 `large-v3`),結果可能會得到改善。
構建演示
現在我們已經微調了我們的模型,我們可以構建一個演示來展示其 ASR 功能!我們將使用 🤗 Transformers `pipeline`,它將處理整個 ASR 流程,從預處理音訊輸入到解碼模型預測。我們將使用 Gradio 構建我們的互動式演示。Gradio 可以說是構建機器學習演示最直接的方法;使用 Gradio,我們可以在幾分鐘內構建一個演示!
執行下面的示例將生成一個 Gradio 演示,我們可以透過計算機的麥克風錄製語音,並將其輸入到我們微調的 Whisper 模型中以轉錄相應的文字。
from transformers import pipeline
import gradio as gr
pipe = pipeline(model="sanchit-gandhi/whisper-small-hi") # change to "your-username/the-name-you-picked"
def transcribe(audio):
text = pipe(audio)["text"]
return text
iface = gr.Interface(
fn=transcribe,
inputs=gr.Audio(source="microphone", type="filepath"),
outputs="text",
title="Whisper Small Hindi",
description="Realtime demo for Hindi speech recognition using a fine-tuned Whisper small model.",
)
iface.launch()
結束語
在本部落格中,我們介紹了使用 🤗 Datasets、Transformers 和 Hugging Face Hub 進行多語言 ASR 微調 Whisper 的分步指南。如果您想自己嘗試微調,請參考 Google Colab。如果您對微調其他 Transformers 模型(包括英語和多語言 ASR)感興趣,請務必檢視 examples/pytorch/speech-recognition 中的示例指令碼。




















