Habana Gaudi 上的 Transformers 入門指南

幾周前,我們很高興地宣佈 Habana Labs 和 Hugging Face 將合作加速 Transformer 模型的訓練。
與最新的基於 GPU 的 Amazon EC2 例項相比,Habana Gaudi 加速器在訓練機器學習模型方面提供了高達 40% 的價效比提升。我們非常高興能將這一價效比優勢帶給 Transformers 🚀
在這篇實操文章中,我將向您展示如何在 Amazon Web Services 上快速設定 Habana Gaudi 例項,然後微調一個 BERT 模型用於文字分類。和往常一樣,我們提供了所有程式碼,以便您可以在自己的專案中複用。
我們開始吧!
在 AWS 上設定 Habana Gaudi 例項
使用 Habana Gaudi 加速器最簡單的方法是啟動一個 Amazon EC2 DL1 例項。這些例項配備了 8 個 Habana Gaudi 處理器,藉助 Habana 深度學習亞馬遜雲主機映象 (AMI),可以輕鬆地投入使用。該 AMI 預裝了 Habana SynapseAI® SDK 以及執行 Gaudi 加速的 Docker 容器所需的工具。如果您想使用其他 AMI 或容器,可以在 Habana 文件中找到相關說明。
從 us-east-1 區域的 EC2 控制檯開始,我首先點選 啟動例項 併為例項定義一個名稱 (“habana-demo-julsimon”)。
然後,我在亞馬遜雲市場中搜索 Habana AMI。
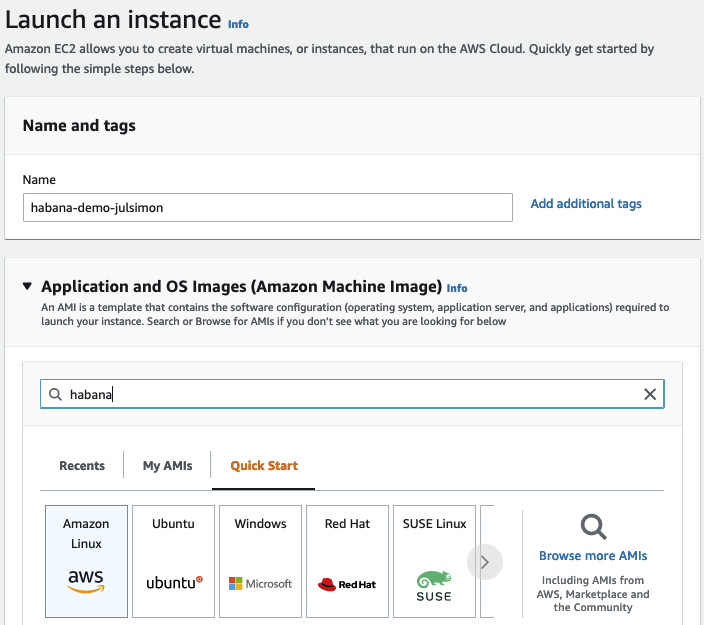
我選擇了 Habana Deep Learning Base AMI (Ubuntu 20.04)。
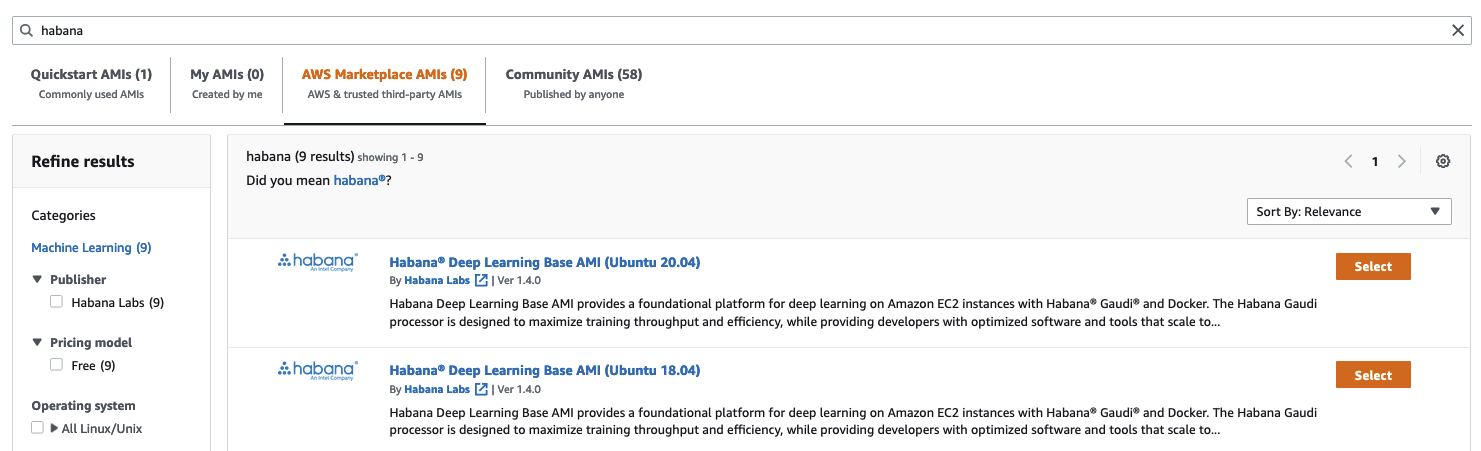
接著,我選擇了 dl1.24xlarge 例項大小(這是唯一可用的大小)。
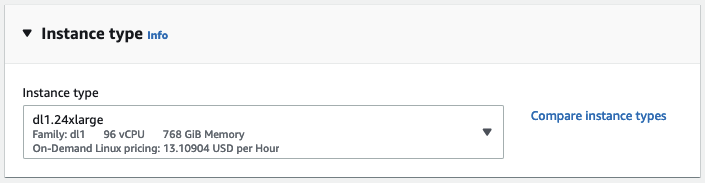
然後,我選擇將用於透過 ssh 連線到例項的金鑰對。如果您沒有金鑰對,可以在此建立。
下一步,我確保例項允許入站 ssh 流量。為了簡單起見,我沒有限制源地址,但您在自己的賬戶中絕對應該這樣做。

預設情況下,這個 AMI 將啟動一個帶有 8GB Amazon EBS 儲存的例項,這在這裡是不夠的。我將儲存空間增加到 50GB。
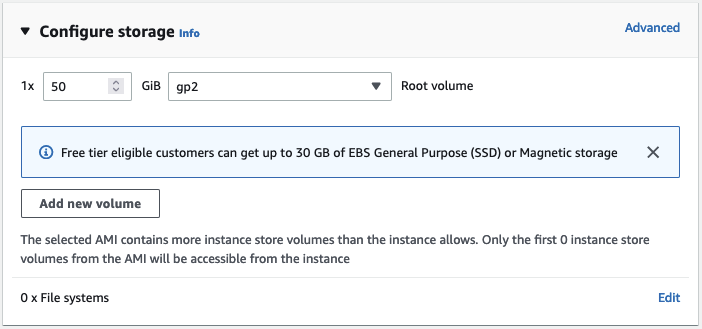
接下來,我為例項分配一個 Amazon IAM 角色。在實際應用中,這個角色應該擁有執行訓練任務所需的最小許可權集,例如從您的某個 Amazon S3 儲存桶讀取資料的能力。這裡不需要這個角色,因為資料集將從 Hugging Face Hub 下載。如果您不熟悉 IAM,我強烈建議閱讀 入門文件。
然後,我請求 EC2 將我的例項配置為競價例項,這是降低每小時 13.11 美元成本的好方法。
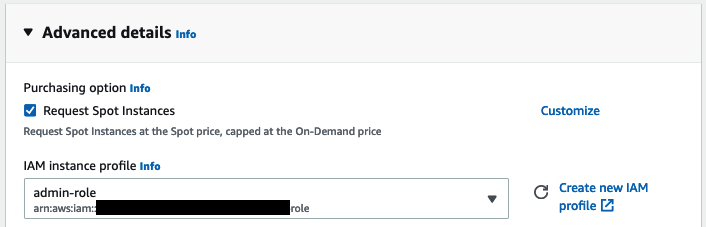
最後,我啟動了例項。幾分鐘後,例項準備就緒,我可以用 ssh 連線到它。Windows 使用者可以使用 PuTTY 按照文件執行相同的操作。
ssh -i ~/.ssh/julsimon-keypair.pem ubuntu@ec2-18-207-189-109.compute-1.amazonaws.com
在這個例項上,最後的設定步驟是拉取用於 PyTorch 的 Habana 容器,我將使用這個框架來微調我的模型。您可以在 Habana 文件中找到關於其他預構建容器以及如何構建自己的容器的資訊。
docker pull \
vault.habana.ai/gaudi-docker/1.5.0/ubuntu20.04/habanalabs/pytorch-installer-1.11.0:1.5.0-610
一旦映象被拉取到例項上,我以互動模式執行它。
docker run -it \
--runtime=habana \
-e HABANA_VISIBLE_DEVICES=all \
-e OMPI_MCA_btl_vader_single_copy_mechanism=none \
--cap-add=sys_nice \
--net=host \
--ipc=host vault.habana.ai/gaudi-docker/1.5.0/ubuntu20.04/habanalabs/pytorch-installer-1.11.0:1.5.0-610
現在我已經準備好微調我的模型了。
在 Habana Gaudi 上微調文字分類模型
我首先在我剛剛啟動的容器內克隆 Optimum Habana 倉庫。
git clone https://github.com/huggingface/optimum-habana.git
然後,我從原始碼安裝 Optimum Habana 包。
cd optimum-habana
pip install .
然後,我移動到包含文字分類示例的子目錄,並安裝所需的 Python 包。
cd examples/text-classification
pip install -r requirements.txt
我現在可以啟動訓練任務了,它會從 Hugging Face Hub 下載 bert-large-uncased-whole-word-masking 模型,並在 GLUE 基準測試的 MRPC 任務上進行微調。
請注意,我正在從 Hugging Face Hub 獲取 BERT 的 Habana Gaudi 配置,您也可以使用自己的配置。此外,還支援其他流行模型,您可以在 Habana 組織中找到它們的配置檔案。
python run_glue.py \
--model_name_or_path bert-large-uncased-whole-word-masking \
--gaudi_config_name Habana/bert-large-uncased-whole-word-masking \
--task_name mrpc \
--do_train \
--do_eval \
--per_device_train_batch_size 32 \
--learning_rate 3e-5 \
--num_train_epochs 3 \
--max_seq_length 128 \
--use_habana \
--use_lazy_mode \
--output_dir ./output/mrpc/
2 分 12 秒後,任務完成,並取得了 0.9181 的優異 F1 分數,如果增加更多輪次,分數肯定還會提高。
***** train metrics *****
epoch = 3.0
train_loss = 0.371
train_runtime = 0:02:12.85
train_samples = 3668
train_samples_per_second = 82.824
train_steps_per_second = 2.597
***** eval metrics *****
epoch = 3.0
eval_accuracy = 0.8505
eval_combined_score = 0.8736
eval_f1 = 0.8968
eval_loss = 0.385
eval_runtime = 0:00:06.45
eval_samples = 408
eval_samples_per_second = 63.206
eval_steps_per_second = 7.901
最後但同樣重要的是,我終止了 EC2 例項以避免不必要的費用。檢視 EC2 控制檯中的節省摘要,我看到由於使用了競價例項,我節省了 70% 的費用,每小時只需支付 3.93 美元,而不是 13.11 美元。
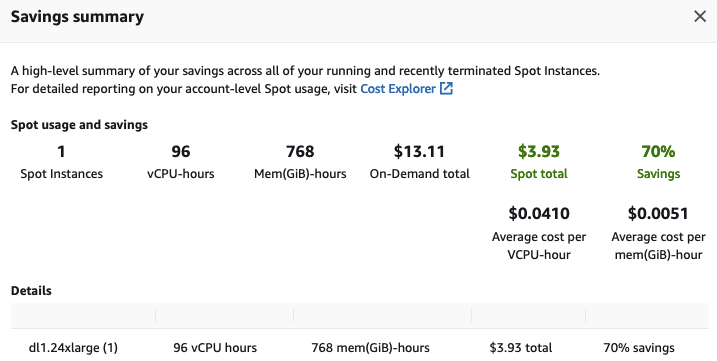
如您所見,Transformers、Habana Gaudi 和 AWS 例項的組合是強大、簡單且經濟高效的。快來試試吧,並告訴我們您的想法。我們非常歡迎您在 Hugging Face 論壇上提出問題和反饋。
請聯絡 Habana 以瞭解更多關於在 Gaudi 處理器上訓練 Hugging Face 模型的資訊。

