引入 HELMET:全面評估長上下文語言模型














聯絡方式:hyen@cs.princeton.edu
論文:https://arxiv.org/abs/2410.02694
網站:https://princeton-nlp.github.io/HELMET
程式碼和資料:https://github.com/princeton-nlp/HELMET
自去年十月首次釋出HELMET以來,長上下文語言模型的發展速度比以往任何時候都快,我們很高興看到社群對HELMET的採用,例如微軟的Phi-4和AI21的Jamba 1.6。在首次釋出後,我們向評估套件中添加了更多模型並進行了額外的分析。我們很高興分享我們的新結果,並將在ICLR 2025上展示HELMET!
在這篇部落格中,我們將描述HELMET的構建、我們的主要發現以及實踐者如何在未來的研究和應用中使用HELMET來區分各種LCLM。最後,我們將提供一份HELMET與HuggingFace配合使用的快速入門指南。
評估長上下文語言模型既具有挑戰性又很重要
從總結大量法律文件到即時學習新任務,長上下文語言模型(LCLM)具有巨大的潛力,可以改變我們使用和與語言模型互動的方式。語言模型一直受到其上下文視窗的限制,大約為2K到8K個token(例如ChatGPT、Llama-2/3)。最近,模型開發者不斷增加其模型的上下文視窗,最新模型如GPT-4o、Claude-3和Gemini-1.5支援高達數百萬個token的上下文視窗。

然而,隨著上下文視窗的增加,以前的自然語言基準(例如Scrolls)不再適合評估LCLM。因此,困惑度和合成任務(例如大海撈針)成為LCLM最流行的評估指標,但它們通常不反映真實世界效能。模型開發者也可能在其他任意資料集上進行評估,這使得模型比較複雜。此外,LCLM的現有基準可能會顯示出令人困惑和反直覺的結果,使得難以理解不同模型的優缺點(圖1)。
在這項工作中,我們提出了HELMET(如何有效且徹底地評估長上下文模型),這是一個用於評估LCLM的綜合基準,它在多個方面改進了現有基準——多樣性、可控性和可靠性。我們評估了59個近期LCLM,發現跨不同應用評估模型對於理解其能力至關重要,並且前沿LCLM在複雜任務上仍然受限。
現有評估過度依賴合成任務
隨著工業界和開源社群LCLM的發展,擁有可靠的方法來評估和比較這些模型變得至關重要。然而,當前模型通常在不同的基準上進行評估(表1)。
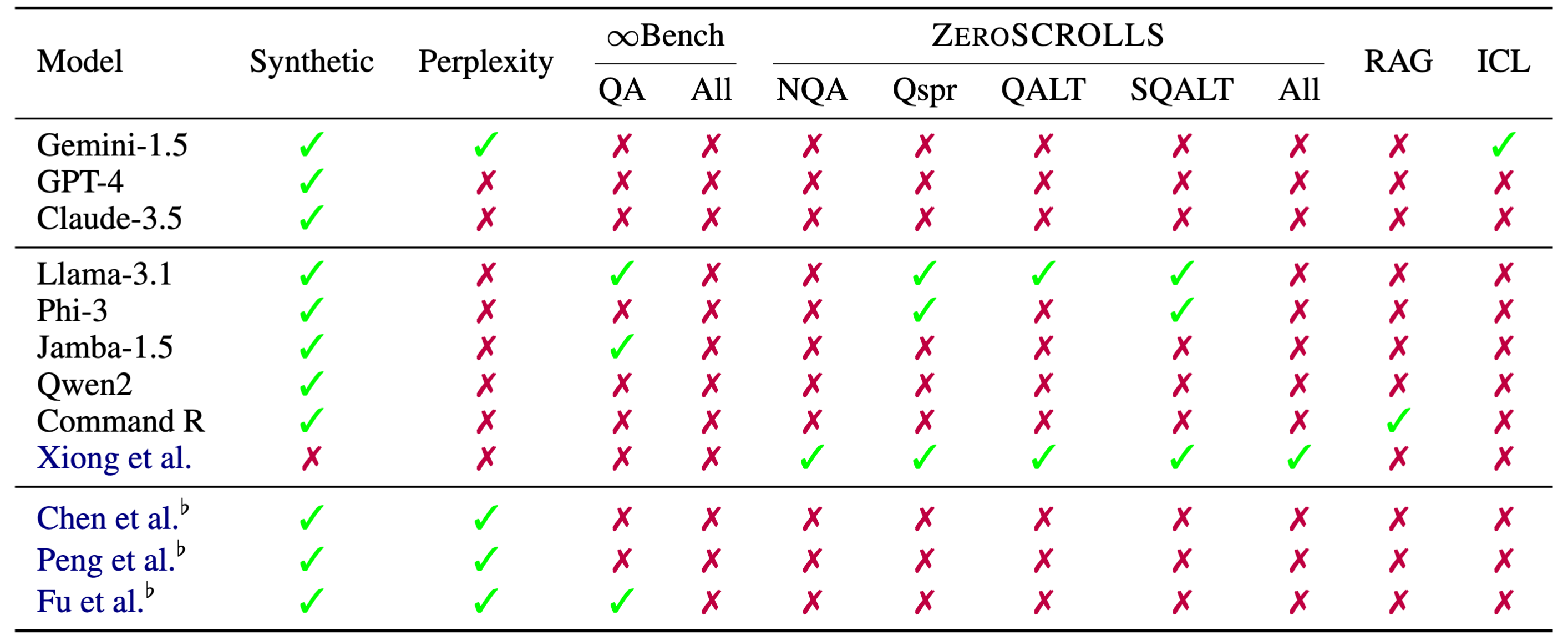
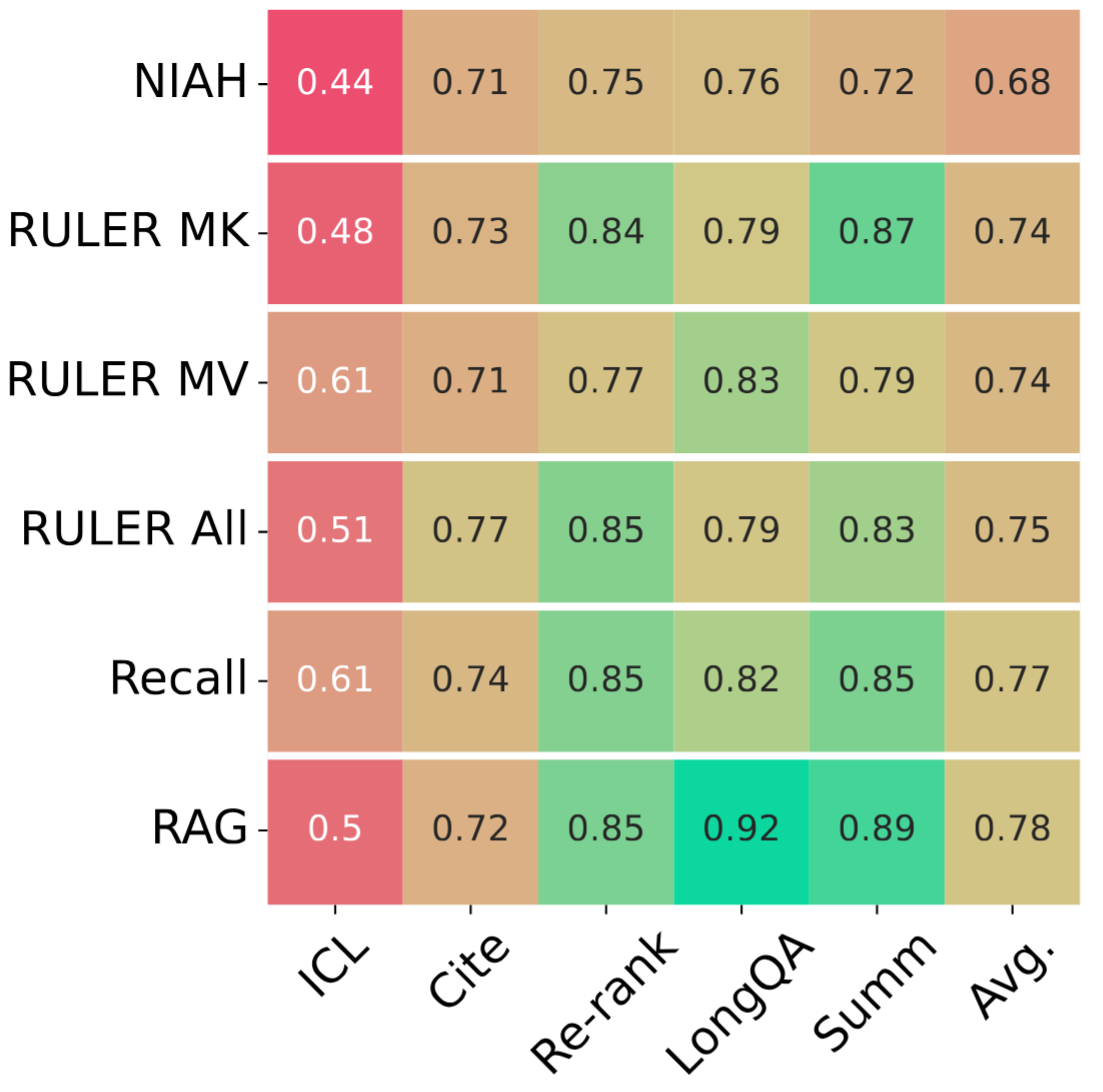
評估長上下文語言模型的常見做法是使用困惑度或合成任務,例如大海撈針(NIAH)。然而,最近的研究表明,困惑度與下游效能相關性不佳(Fang et al., 2024)。在圖2中,我們展示了像NIAH這樣的合成任務與真實世界效能不相關,但更復雜的合成任務與真實世界任務具有更高的相關性。
在現有具有實際應用的基準中,例如ZeroScrolls(Shaman et al., 2023)、LongBench(Bai et al., 2024)和InfiniteBench(Zhang et al., 2024),仍然存在關鍵限制:
- 下游任務覆蓋不足:通常側重於特定領域
- 對於測試前沿LCLM來說長度不足:舊的問答資料集通常限制在<32K個token(例如QASPER、QuALITY)
- 不可靠的指標:ROUGE等N-gram匹配指標噪音大——它們與人類判斷相關性不佳(Goyal et al., 2023)且無法區分模型
- 與基礎模型不相容:需要指令微調,這意味著它們不能用於基礎模型開發
因此,我們提出了HELMET來解決這些限制,並對LCLM進行全面評估。
為LCLM制定多樣化、可控且可靠的評估
我們設計HELMET時考慮了以下期望:
- 下游任務的廣泛覆蓋
- 可控的長度和複雜度
- 基礎模型和指令微調模型的可靠評估
表2顯示了基準的概覽。在我們的實驗中,我們評估了從8K到128K個token的輸入長度,但HELMET可以輕鬆擴充套件到更長的上下文長度。
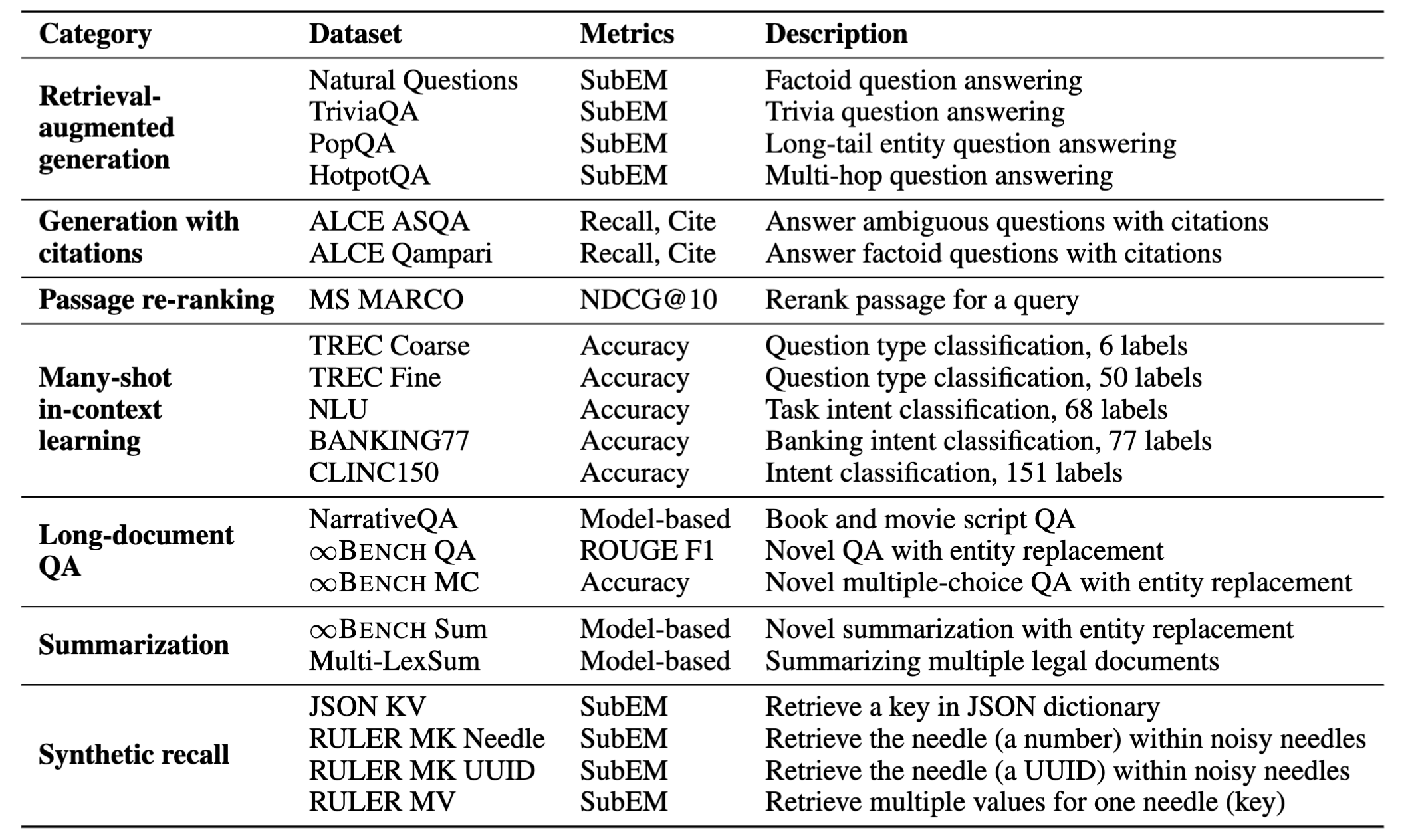
相對於現有基準的主要改進
廣泛覆蓋:HELMET包含一系列多樣化的任務,例如帶有真實檢索段落的檢索增強生成、帶引用的生成和摘要。我們精心選擇具有自然長上下文的資料集,以反映實際應用。這些資料集輔以可靠的評估設定,例如基於模型的評估和人工研究。
可控的長度和難度:評估LCLM時需要考慮的一個重要維度是輸入長度,因為更長的輸入可以提供更多資訊,同時挑戰模型處理嘈雜上下文的能力。在我們的任務中,我們可以透過更改檢索段落的數量(RAG、Cite、Re-rank)、演示的數量(ICL)或輸入文件的長度(LongQA、Summ)來控制輸入長度。雖然LongQA和Summ不能輕易擴充套件到更長的上下文,但我們特意選擇了具有自然文件長度遠大於100K個token的資料集,以便它們仍可用於評估前沿LCLM。
可靠評估:許多現有基準仍使用基於n-gram的指標,例如ROUGE,儘管它們與人類判斷的相關性很差(Goyal et al., 2023)。我們採用基於模型的評估,該評估在模型之間和不同輸入長度之間顯示出更好的可區分性(圖3)。此外,我們的人工研究表明,我們的指標與人類判斷具有高度一致性。

穩健的提示:現有的長上下文基準通常要求模型遵循指令,但許多模型開發都圍繞基礎模型展開,這些模型必須依靠合成任務或困惑度進行評估。因此,我們透過上下文學習示例支援我們的部分任務的基礎模型。這大大提高了基礎模型的效能,更能反映實際應用。
LCLM在實際任務中仍有很長的路要走
我們的實驗和分析包括一套全面的59個LCLM。據我們所知,這是對長上下文模型在不同應用上最徹底和最受控的比較。這些模型涵蓋了領先的專有模型和開源模型,我們還考慮了具有不同架構(例如全注意力Transformer、混合架構)和位置外推技術的模型。在本節中,我們將重點介紹我們實驗中的幾個關鍵發現。
評估長上下文能力需要多樣化的評估
長上下文基準通常是針對特定應用(例如摘要或問答)構建的,這限制了對更廣泛背景下LCLM的理解。我們檢查了模型在廣泛真實任務中的表現,發現不同類別之間並不總是相關聯(圖4)。
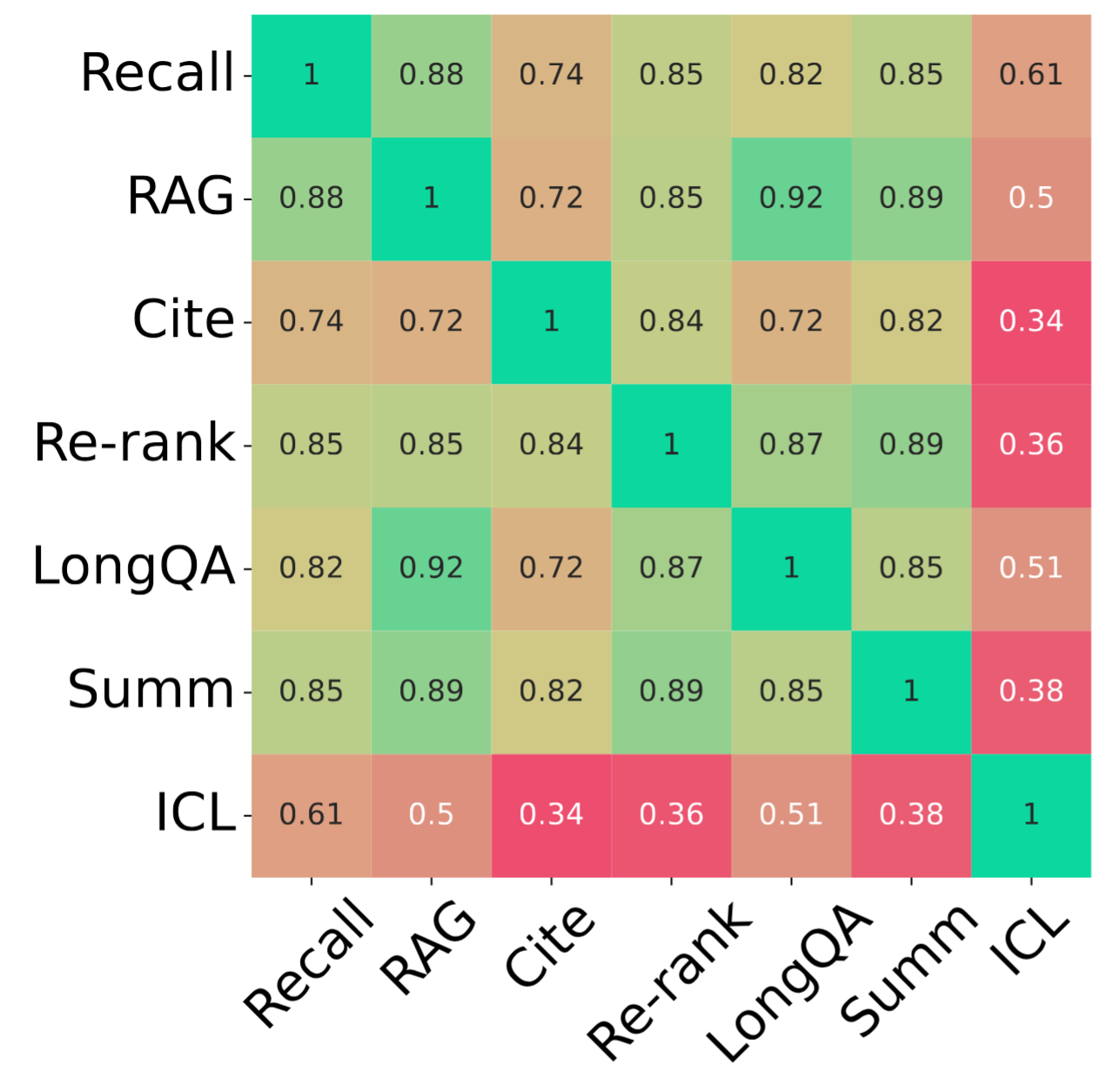
儘管某些任務(例如RAG和MS-MARCO)由於其基於檢索的性質而彼此適度相關,但其他任務(例如Summ和Cite)則顯示出很少的相關性。值得注意的是,ICL與其他任務的相關性最低,這表明它是一個獨特的任務,需要模型具備不同的能力。因此,模型開發者應該在這些不同的軸上進行評估,以更全面地瞭解模型的能力。
模型效能隨長度和任務複雜度的增加而下降
我們展示了前沿專有模型以及少數開源模型在HELMET上的結果。更多結果可在論文和網站上找到。
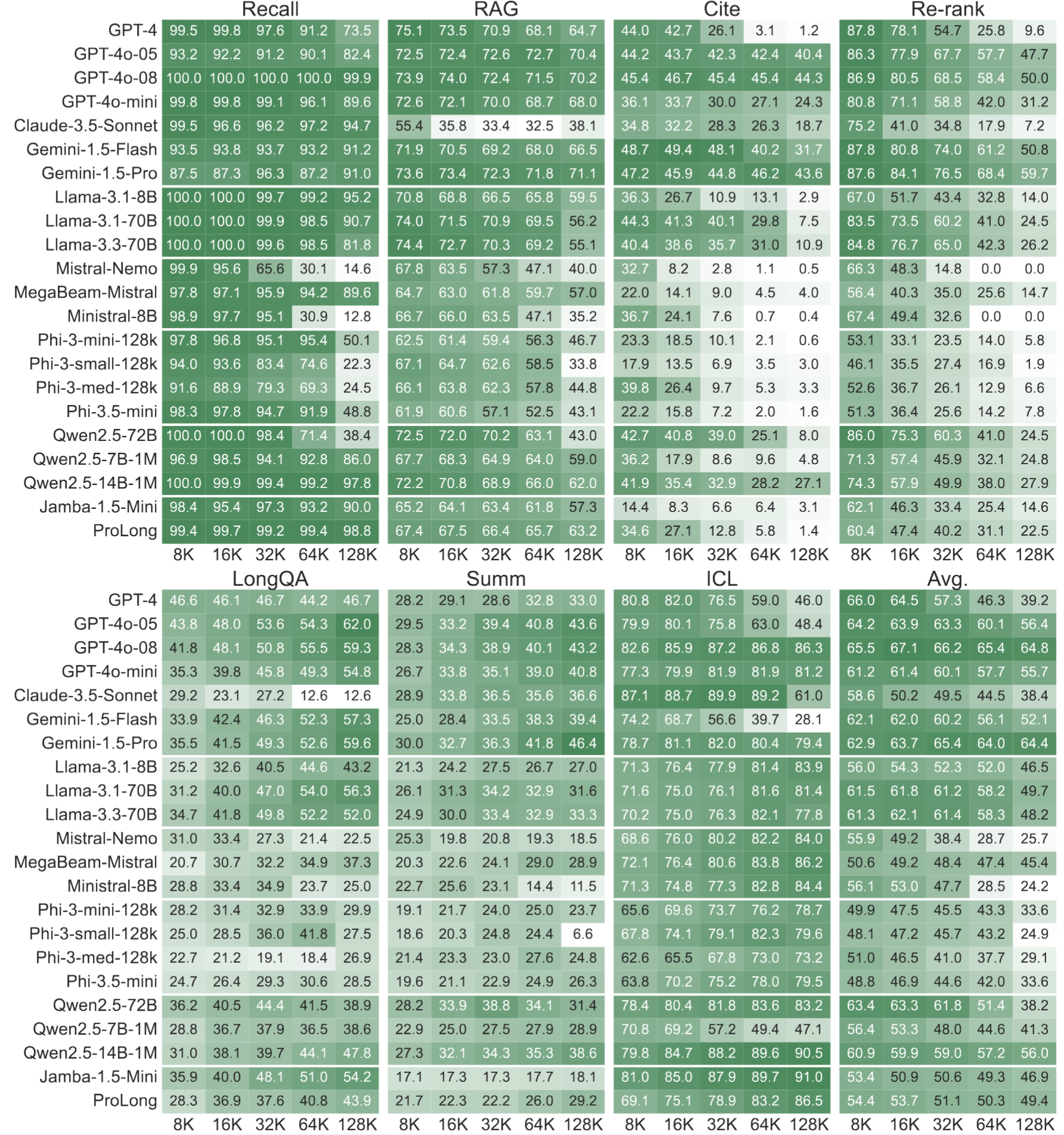
首先,我們觀察到開源模型在複雜任務上落後於閉源模型。儘管在召回等簡單任務上差距似乎很小,但在引用等更復雜的任務上差距會擴大。
此外,效能隨長度增加而下降是取決於類別的。即使是最先進的模型,如GPT-4o和Gemini,在重新排序等任務上效能也會顯著下降。這種效能變化無法透過簡單地檢視合成任務效能來觀察。
最後,在所有類別中沒有明顯的贏家,因此需要跨不同軸進行評估。更多分析,例如不同位置外推方法的效能和“中間遺失”現象,可以在論文中找到。
使用HELMET進行未來開發
如何執行HELMET
使用HELMET非常簡單!只需克隆我們的GitHub倉庫,設定好環境後即可執行!
我們提供了多種載入模型的方式,可在配置檔案中進行配置:
- 使用HuggingFace的
transformers庫 - 使用HuggingFace的TGI在您的機器上啟動模型端點
- 使用HuggingFace的Inference Endpoints啟動遠端模型端點
- 使用vllm在您的機器上啟動模型端點。注意:您可以在Intel Gaudi加速器上啟動vllm端點。
- 使用模型提供商的API
選項1. 使用HuggingFace的transformers庫
只需使用我們倉庫中的config yamls,然後執行以下評估:
python eval.py --config configs/rag.yaml --model_name_or_path <model_name>
在幕後,使用了HuggingFace的transformers庫,並自動支援本地和遠端模型。
選項2. 使用HuggingFace的TGI
首先,按照TGI github上的說明啟動模型端點。然後,在您的配置檔案中,指定端點URL。例如,您可以有一個config.yaml,如下所示:
input_max_length: 131072
datasets: kilt_nq
generation_max_length: 20
test_files: data/kilt/nq-dev-multikilt_1000_k1000_dep6.jsonl
demo_files: data/kilt/nq-train-multikilt_1000_k3_dep6.jsonl
use_chat_template: true
max_test_samples: 100
shots: 2
stop_new_line: true
model_name_or_path: tgi:meta-llama/Llama-3.1-8B-Instruct # need to add "tgi:" prefix
use_tgi_serving: true # add this line in your config
然後使用下面的命令執行基準測試:
export LLM_ENPOINT=<your-tgi-endpoint> # example: "https://10.10.10.1:8080/v1"
python eval.py --config configs/config.yaml --endpoint_url $LLM_ENDPOINT
選項3. 使用HuggingFace的推理端點
首先按照此處的說明設定端點。獲取端點URL和您的API金鑰。然後使用與選項2中相同的config yaml,並執行以下命令:
export LLM_ENPOINT=<your-hf-inference-endpoint> # example: "https://XXXX.us-east-1.aws.endpoints.huggingface.cloud/v1"
export API_KEY=<your-hf-api-key>
python eval.py --config configs/config.yaml --endpoint_url $LLM_ENDPOINT --api_key $API_KEY
選項4. 使用VLLM
您可以在系統上使用vllm啟動模型端點,包括Intel Gaudi2和Gaudi3加速器。有關如何使用vllm在Intel Gaudi加速器上執行HELMET的說明,請參見此處。
您可以使用與選項2相同的示例config.yaml,除了兩行更改,如下所示:
model_name_or_path: meta-llama/Llama-3.1-8B-Instruct # no prefix needed
use_vllm_serving: true # use vllm instead of tgi
然後使用下面的命令執行基準測試:
export LLM_ENPOINT=<your-vllm-endpoint>
python eval.py --config configs/config.yaml --endpoint_url $LLM_ENDPOINT
選項5. 使用模型提供商的API
我們支援來自OpenAI、Anthropic、Google和TogetherAI的API。請參考我們倉庫中的說明。
更快地開發
我們建議在模型開發過程中使用Recall和RAG任務進行快速迭代。這些任務在快速評估和與其他實際任務的相關性之間取得了良好的平衡。您可以透過以下方式輕鬆執行這些評估:
python eval.py --config configs/rag.yaml --model_name_or_path <model_name>
與現有模型的快速比較
評估LCLM通常很昂貴,尤其是在長上下文情況下,考慮到它們的計算和記憶體成本。例如,在一個70B模型上以所有長度執行HELMET需要一個擁有8*80GB GPU的節點,耗時數百個GPU小時,這可能成本高昂。透過在HELMET上進行評估,研究人員只需參考我們的結果即可直接將其模型與現有模型進行比較,我們的結果涵蓋了59個不同大小和架構的模型。您可以在我們的網站上找到排行榜。
展望未來
HELMET是朝著更全面評估長上下文語言模型邁出的一步,但LCLM仍有許多令人興奮的應用。例如,我們最近釋出了LongProc,這是一個用於評估LCLM在長篇生成和遵循程式方面的基準,這對於開發能夠以思維步驟生成數萬個token的推理模型至關重要。儘管摘要任務具有較長的輸出(最多1K個token),但LongProc專注於更長的輸出,最多8K個token。與HELMET類似,LongProc也採用可靠的評估設定和多樣化的任務設計。我們正在努力將LongProc整合到HELMET的評估套件中,並希望這將為LCLM在長篇任務上的評估提供更全面的視角。
致謝
我們感謝夏夢舟、Howard Chen、葉曦、何映輝、Lucy He、Alexander Wettig、Sadhika Malladi、Adithya Bhaskar、Joie Zhang以及普林斯頓語言與智慧(PLI)小組的其他成員提供的寶貴反饋。這項工作得到了微軟加速基礎模型研究(AFMR)提供的Azure OpenAI積分和英特爾資助的大力支援。
引用
如果您覺得HELMET有用,請考慮引用我們的論文:
@inproceedings{yen2025helmet,
title={HELMET: How to Evaluate Long-Context Language Models Effectively and Thoroughly},
author={Howard Yen and Tianyu Gao and Minmin Hou and Ke Ding and Daniel Fleischer and Peter Izsak and Moshe Wasserblat and Danqi Chen},
year={2025},
booktitle={International Conference on Learning Representations (ICLR)},
}







