使用 Hugging Face Transformers、Accelerate 和 bitsandbytes 對大規模 transformers 進行 8 位矩陣乘法的溫和介紹









導言
語言模型正在變得越來越大。撰寫本文時,PaLM 擁有 5400 億引數,OPT、GPT-3 和 BLOOM 擁有約 1760 億引數,而且我們正朝著更大的模型發展。下圖顯示了一些近期語言模型的大小。

因此,這些模型難以在易於獲取的裝置上執行。例如,僅在 BLOOM-176B 上進行推理,您就需要 8 個 80GB A100 GPU(每個約 15,000 美元)。要微調 BLOOM-176B,您需要 72 個這樣的 GPU!更大的模型,如 PaLM,將需要更多的資源。
由於這些龐大的模型需要如此多的 GPU 才能執行,我們需要尋找方法來減少這些需求,同時保持模型的效能。已經開發了各種技術來縮小模型大小,您可能聽說過量化和蒸餾,還有許多其他技術。
完成 BLOOM-176B 的訓練後,HuggingFace 和 BigScience 的我們正在尋找方法,使這個大型模型更容易在更少的 GPU 上執行。透過我們的 BigScience 社群,我們瞭解到 Int8 推理的研究,該研究不會降低大型模型的預測效能,並將大型模型的記憶體佔用減少 2 倍。很快,我們開始合作進行這項研究,最終將其完全整合到 Hugging Face transformers 中。透過這篇部落格文章,我們為所有 Hugging Face 模型提供了 LLM.int8() 整合,我們將在下面更詳細地解釋。如果您想了解更多關於我們研究的資訊,您可以閱讀我們的論文《LLM.int8():大規模 Transformer 的 8 位矩陣乘法》。
本文重點對這種量化技術進行高層次概述,闡述將其納入 transformers 庫的困難,並制定這種合作的長期目標。
在這裡您將瞭解到,究竟是什麼讓大型模型佔用如此多的記憶體?是什麼讓 BLOOM 達到 350GB?讓我們先逐步瞭解一些基本前提。
機器學習中常用的資料型別
我們首先基本理解不同的浮點資料型別,在機器學習語境中也稱為“精度”。
模型的大小取決於其引數的數量及其精度,通常為 float32、float16 或 bfloat16(下圖來自:https://blogs.nvidia.com/blog/2020/05/14/tensorfloat-32-precision-format/)。
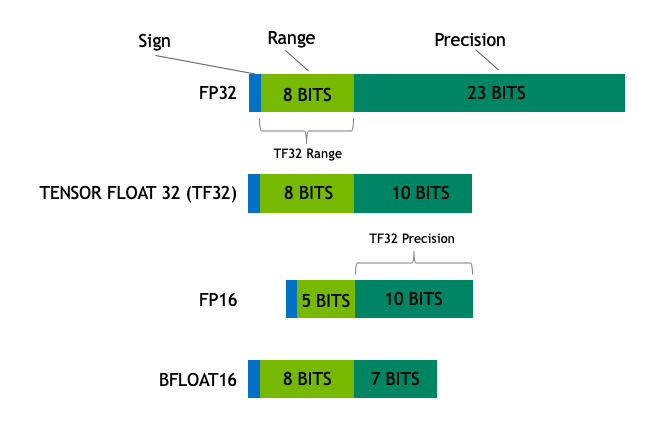
Float32(FP32)代表標準化的 IEEE 32 位浮點表示。使用這種資料型別可以表示廣泛的浮點數。在 FP32 中,8 位保留給“指數”,23 位保留給“尾數”,1 位保留給數字的符號。除此之外,大多數硬體都支援 FP32 操作和指令。
在 float16(FP16)資料型別中,5 位保留給指數,10 位保留給尾數。這使得 FP16 數字的可表示範圍遠低於 FP32。這使得 FP16 數字面臨溢位(嘗試表示一個非常大的數字)和下溢(表示一個非常小的數字)的風險。
例如,如果您執行 10k * 10k,最終得到 100M,這在 FP16 中無法表示,因為最大可能數字為 64k。因此,您將得到 NaN(非數字)結果,如果您像神經網路那樣進行順序計算,所有先前的工作都將被破壞。通常,使用損失縮放來克服這個問題,但它並不總是有效。
為了避免這些限制,建立了一種新格式 bfloat16 (BF16)。在 BF16 中,8 位用於指數(與 FP32 相同),7 位用於小數部分。
這意味著在 BF16 中,我們可以保留與 FP32 相同的動態範圍。但是我們相對於 FP16 損失了 3 位精度。現在對於大數字絕對沒有問題,但這裡的精度比 FP16 更差。
在 Ampere 架構中,NVIDIA 還引入了 TensorFloat-32 (TF32) 精度格式,結合了 BF16 的動態範圍和 FP16 的精度,僅使用 19 位。目前它僅在某些操作內部使用。
在機器學習術語中,FP32 稱為全精度(4 位元組),而 BF16 和 FP16 稱為半精度(2 位元組)。除此之外,int8(INT8)資料型別由 8 位表示組成,可以儲存 2^8 種不同的值(對於有符號整數,介於 [0, 255] 或 [-128, 127] 之間)。
雖然理想情況下訓練和推理應以 FP32 進行,但它比 FP16/BF16 慢兩倍,因此採用混合精度方法,其中權重以 FP32 形式作為精確的“主權重”參考,而前向和後向傳遞中的計算則以 FP16/BF16 進行,以提高訓練速度。然後使用 FP16/BF16 梯度更新 FP32 主權重。
在訓練過程中,主權重始終以 FP32 儲存,但實際上,半精度權重在推理過程中通常能提供與其 FP32 對應物相似的質量——只有當模型接收到多個梯度更新時才需要模型的精確參考。這意味著我們可以使用半精度權重,並使用一半的 GPU 來達到相同的效果。
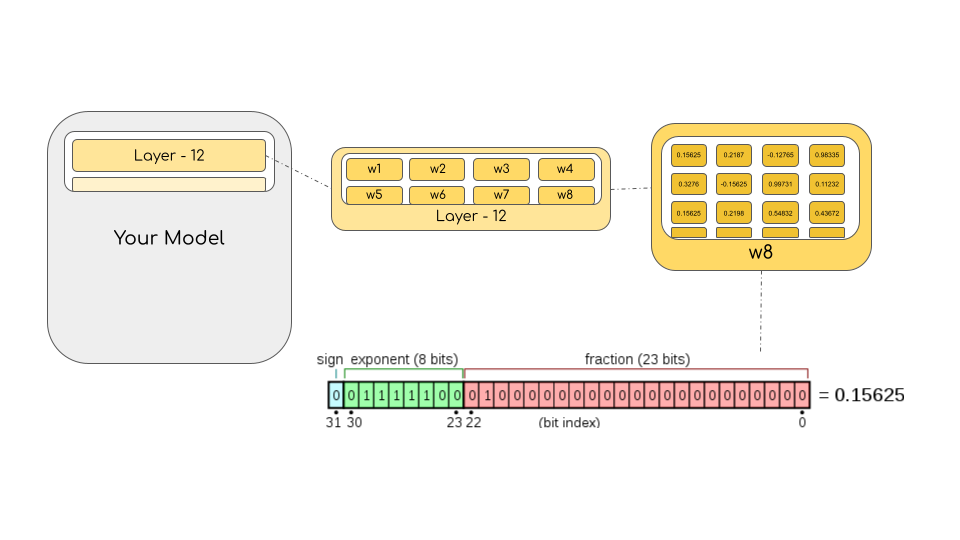
要計算模型的位元組大小,需要將引數數量乘以所選精度的位元組大小。例如,如果我們使用 BLOOM-176B 模型的 bfloat16 版本,我們有 176*10**9 x 2 位元組 = 352GB!如前所述,將其放入少量 GPU 中是一個相當大的挑戰。
但是,如果我們能使用不同的資料型別,用更少的記憶體儲存這些權重呢?一種稱為量化的方法已廣泛用於深度學習中。
模型量化介紹
實驗表明,我們發現使用 2 位元組的 BF16/FP16 半精度,可以獲得幾乎相同的推理結果,而模型大小減半。如果能進一步壓縮就太棒了,但在較低精度下推理質量開始急劇下降。
為了彌補這一點,我們引入了 8 位量化。這種方法使用四分之一精度,因此只需要模型大小的 1/4!但它不是透過簡單地丟棄一半的位元來完成的。
量化是透過從一種資料型別“四捨五入”到另一種資料型別來完成的。例如,如果一種資料型別的範圍是 0..9,另一種是 0..4,那麼第一種資料型別中的值“4”將四捨五入為第二種資料型別中的“2”。但是,如果我們在第一種資料型別中得到值“3”,它介於第二種資料型別的 1 和 2 之間,那麼我們通常會四捨五入為“2”。這表明第一種資料型別中的值“4”和“3”在第二種資料型別中具有相同的值“2”。這突出表明,量化是一個嘈雜的過程,可能導致資訊丟失,一種有失真壓縮。
兩種最常見的 8 位量化技術是零點量化和絕對最大值(absmax)量化。零點量化和 absmax 量化將浮點值對映到更緊湊的 int8(1 位元組)值。首先,這些方法透過量化常數對其輸入進行縮放來對其進行歸一化。
例如,在零點量化中,如果我的範圍是 -1.0…1.0,並且我想量化到 -127…127 的範圍,我需要乘以 127 的因子,然後將其四捨五入到 8 位精度。要檢索原始值,您需要將 int8 值除以相同的量化因子 127。例如,值 0.3 將被縮放為 0.3*127 = 38.1。透過四捨五入,我們得到 38。如果我們反轉這個過程,我們得到 38/127=0.2992 – 在此示例中,我們有 0.008 的量化誤差。這些看似微小的誤差會隨著它們在模型層中傳播而累積和增長,從而導致效能下降。
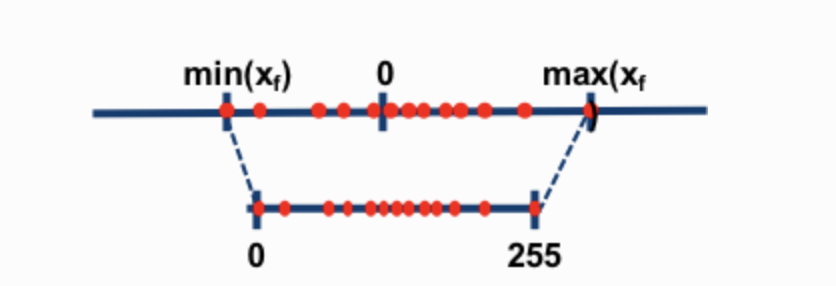
(圖片取自:這篇部落格文章)
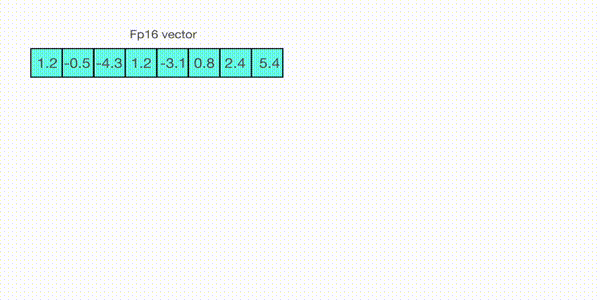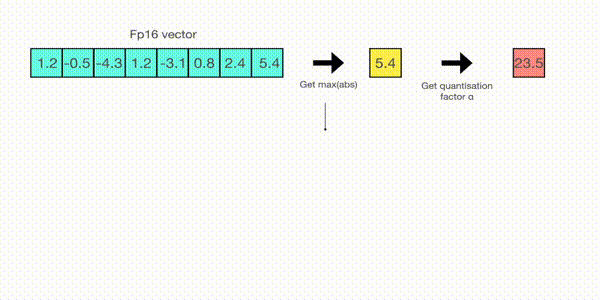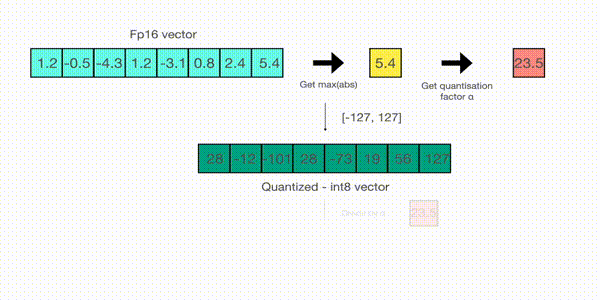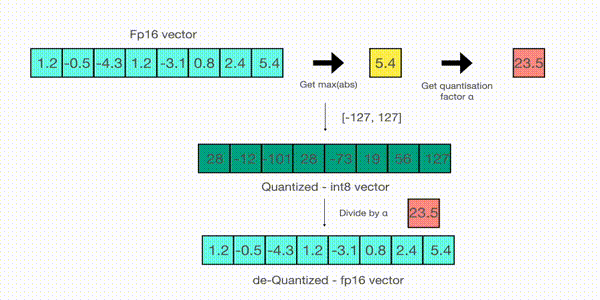
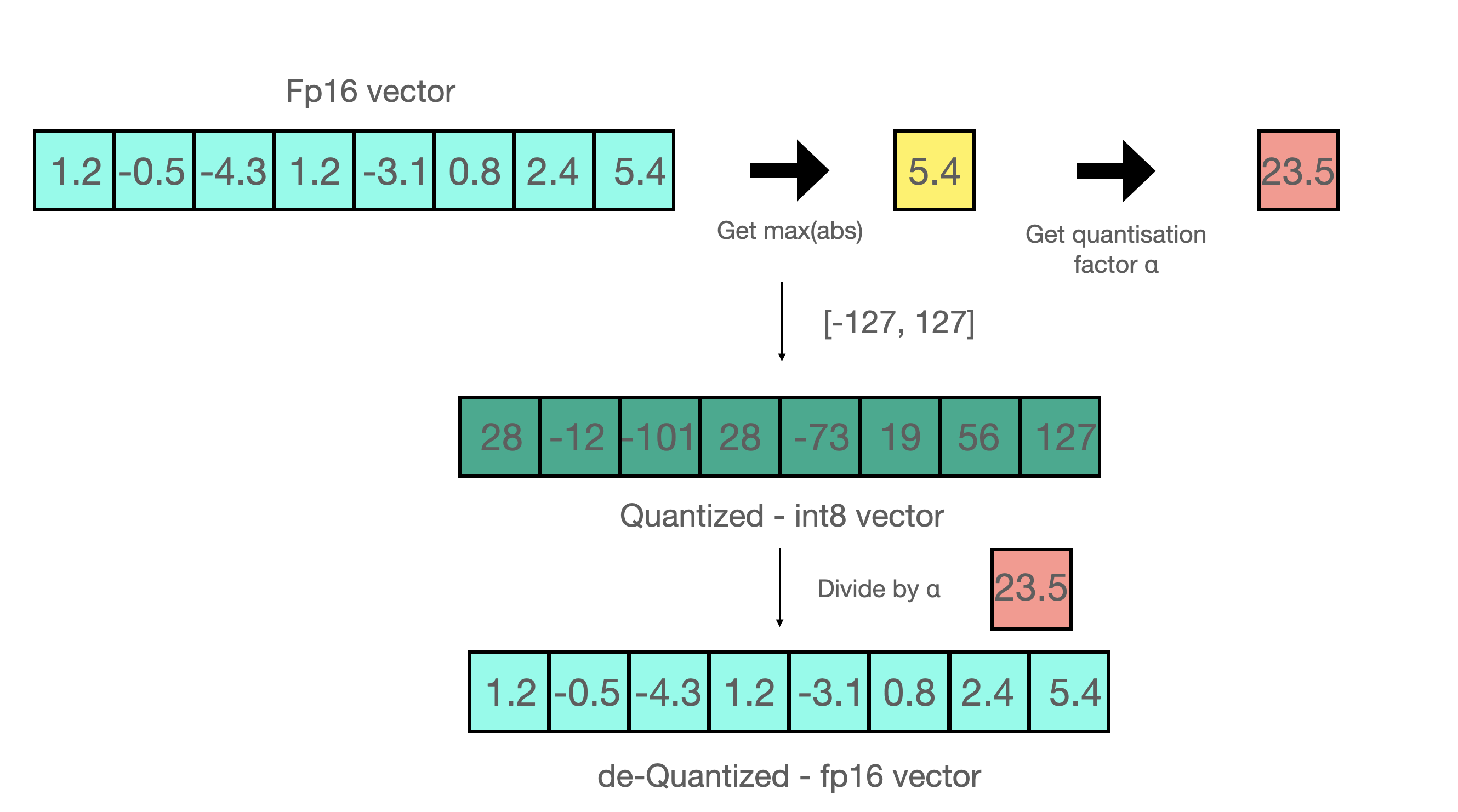
現在讓我們看看 absmax 量化的細節。要計算 fp16 數及其在 absmax 量化中對應的 int8 數之間的對映,您必須首先除以張量的絕對最大值,然後乘以資料型別的總範圍。
例如,假設您想在包含 [1.2, -0.5, -4.3, 1.2, -3.1, 0.8, 2.4, 5.4] 的向量中應用 absmax 量化。您從中提取絕對最大值,在本例中為 5.4。Int8 的範圍是 [-127, 127],因此我們將 127 除以 5.4,得到 23.5 作為縮放因子。因此,將原始向量乘以它會得到量化向量 [28, -12, -101, 28, -73, 19, 56, 127]。
要檢索最新的,只需用全精度將 int8 數除以量化因子即可,但由於上述結果是“四捨五入”的,因此會損失一些精度。
對於無符號 int8,我們將減去最小值並按絕對最大值縮放。這與零點量化的做法接近。它類似於 min-max 縮放,但後者以保持值尺度的方式進行,使得值“0”始終由整數表示,而沒有任何量化誤差。
這些技巧可以透過多種方式組合,例如,在矩陣乘法中進行逐行或逐向量量化,以獲得更準確的結果。觀察矩陣乘法 A*B=C,與透過每個張量的絕對最大值進行歸一化的常規量化不同,逐向量量化找到 A 的每一行和 B 的每一列的絕對最大值。然後,我們透過除以這些向量來歸一化 A 和 B。然後我們計算 A*B 得到 C。最後,為了恢復 FP16 值,我們透過計算 A 和 B 的絕對最大值向量的外積來進行反歸一化。有關此技術的更多詳細資訊,請參閱 LLM.int8() 論文 或 Tim 部落格上關於 量化和湧現特徵的部落格文章。
雖然這些基本技術使我們能夠量化深度學習模型,但它們通常會導致大型模型精度下降。我們整合到 Hugging Face Transformers 和 Accelerate 庫中的 LLM.int8() 實現是第一種即使對於擁有 176B 引數(例如 BLOOM)的大型模型也不會降低效能的技術。
LLM.int8() 溫和總結:大型語言模型的零精度損失矩陣乘法
在 LLM.int8() 中,我們已經證明,為了理解為什麼傳統量化在大型模型中失敗,理解 transformer 的規模依賴湧現特性至關重要。我們證明,效能下降是由異常特徵引起的,我們將在下一節中解釋。LLM.int8() 演算法本身可以解釋如下。
本質上,LLM.int8() 旨在透過三個步驟完成矩陣乘法計算
- 從輸入隱藏狀態中,按列提取異常值(即大於某個閾值的值)。
- 以 FP16 格式對異常值進行矩陣乘法,並以 int8 格式對非異常值進行矩陣乘法。
- 對非異常值結果進行反量化,並將異常值和非異常值結果相加,以獲得 FP16 格式的完整結果。
這些步驟可以總結為以下動畫

異常特徵的重要性
異常值通常指超出某些數字全域性分佈範圍的值。異常值檢測已在現有文獻中廣泛使用和涵蓋,並且事先了解特徵的分佈有助於異常值檢測任務。更具體地說,我們觀察到大規模經典量化對於基於 transformer 的模型(引數大於 6B)失敗。雖然小型模型中也存在大型異常特徵,但我們觀察到,達到某個閾值後,這些異常值會形成高度系統化的模式,這些模式存在於 transformer 的每一層中。有關這些現象的更多詳細資訊,請參閱 LLM.int8() 論文 和 關於量化和湧現特徵的部落格文章。
如前所述,8 位精度受到極大限制,因此對包含多個大值的向量進行量化可能會產生嚴重錯誤的結果。此外,由於基於 Transformer 的架構的內建特性將所有元素連線在一起,這些誤差在透過多層傳播時會趨於複合。因此,為了促進對這些極端異常值進行高效量化,開發了混合精度分解技術。接下來將對此進行討論。
MatMul 內部
計算完隱藏狀態後,我們使用自定義閾值提取異常值,並如上所述將矩陣分解為兩部分。我們發現,以這種方式提取所有大小為 6 或更大的異常值可以恢復完整的推理效能。異常值部分以 fp16 完成,因此它是經典的矩陣乘法,而 8 位矩陣乘法透過使用向量量化將權重和隱藏狀態量化為 8 位精度——即,隱藏狀態逐行量化,權重矩陣逐列量化。在此步驟之後,結果被反量化並以半精度返回,以便將其新增到第一次矩陣乘法中。

0 精度損失意味著什麼?
我們如何正確評估這種方法的效能下降?在使用 8 位模型時,我們在生成質量方面損失了多少?
我們使用 lm-eval-harness 運行了幾個常見基準測試,並報告了 8 位模型和原生模型的結果。
對於 OPT-175B
| 基準 | - | - | - | - | 差異 - 值 |
|---|---|---|---|---|---|
| 名稱 | 指標 | 值 - int8 | 值 - fp16 | 標準誤差 - fp16 | - |
| hellaswag | acc_norm | 0.7849 | 0.7849 | 0.0041 | 0 |
| hellaswag | acc | 0.5921 | 0.5931 | 0.0049 | 0.001 |
| piqa | acc | 0.7965 | 0.7959 | 0.0094 | 0.0006 |
| piqa | acc_norm | 0.8101 | 0.8107 | 0.0091 | 0.0006 |
| lambada | ppl | 3.0142 | 3.0152 | 0.0552 | 0.001 |
| lambada | acc | 0.7464 | 0.7466 | 0.0061 | 0.0002 |
| winogrande | acc | 0.7174 | 0.7245 | 0.0125 | 0.0071 |
對於 BLOOM-176
| 基準 | - | - | - | - | 差異 - 值 |
|---|---|---|---|---|---|
| 名稱 | 指標 | 值 - int8 | 值 - bf16 | 標準誤差 - bf16 | - |
| hellaswag | acc_norm | 0.7274 | 0.7303 | 0.0044 | 0.0029 |
| hellaswag | acc | 0.5563 | 0.5584 | 0.005 | 0.0021 |
| piqa | acc | 0.7835 | 0.7884 | 0.0095 | 0.0049 |
| piqa | acc_norm | 0.7922 | 0.7911 | 0.0095 | 0.0011 |
| lambada | ppl | 3.9191 | 3.931 | 0.0846 | 0.0119 |
| lambada | acc | 0.6808 | 0.6718 | 0.0065 | 0.009 |
| winogrande | acc | 0.7048 | 0.7048 | 0.0128 | 0 |
我們確實觀察到這些模型沒有效能下降,因為指標的絕對差異都低於標準誤差(BLOOM-int8 除外,它在 lambada 上略優於原生模型)。有關與最先進方法進行更詳細的效能評估,請參閱論文!
它比原生模型更快嗎?
LLM.int8() 方法的主要目的是在不降低效能的情況下使大型模型更易於訪問。但如果該方法速度很慢,則用處不大。因此,我們對多個模型的生成速度進行了基準測試。我們發現使用 LLM.int8() 的 BLOOM-176B 比 fp16 版本慢約 15% 到 23%——這仍然是相當可以接受的。我們發現對於較小的模型,如 T5-3B 和 T5-11B,減速更大。我們努力加快這些小型模型的速度。一天之內,我們將 T5-3B 的每令牌推理時間從 312 毫秒提高到 173 毫秒,將 T5-11B 的每令牌推理時間從 45 毫秒提高到 25 毫秒。此外,已經發現了問題,LLM.int8() 在即將釋出的版本中可能會對小型模型更快。目前,當前數字如下表所示。
| 精度 | 引數數量 | 硬體 | 批次大小為 1 時每令牌的時間(毫秒) | 批次大小為 8 時每令牌的時間(毫秒) | 批次大小為 32 時每令牌的時間(毫秒) |
|---|---|---|---|---|---|
| bf16 | 176B | 8xA100 80GB | 239 | 32 | 9.9 |
| int8 | 176B | 4xA100 80GB | 282 | 37.5 | 10.2 |
| bf16 | 176B | 14xA100 40GB | 285 | 36.5 | 10.4 |
| int8 | 176B | 5xA100 40GB | 367 | 46.4 | oom |
| fp16 | 11B | 2xT4 15GB | 11.7 | 1.7 | 0.5 |
| int8 | 11B | 1xT4 15GB | 43.5 | 5.3 | 1.3 |
| fp32 | 3B | 2xT4 15GB | 45 | 7.2 | 3.1 |
| int8 | 3B | 1xT4 15GB | 312 | 39.1 | 10.2 |
這 3 個模型是 BLOOM-176B、T5-11B 和 T5-3B。
Hugging Face transformers 整合細微之處
接下來讓我們討論 Hugging Face transformers 整合的具體細節。讓我們看看用法以及您在設定時可能遇到的常見問題。
用法
本部落格文章中描述的所有神奇功能都由名為 Linear8bitLt 的模組負責,您可以輕鬆地從 bitsandbytes 庫中匯入它。它派生自經典的 torch.nn 模組,可以輕鬆地使用下面的程式碼在您的架構中使用和部署。
以下是以下用例的分步示例:假設您想使用 bitsandbytes 將一個小模型轉換為 int8。
- 首先,我們需要正確的匯入!
import torch
import torch.nn as nn
import bitsandbytes as bnb
from bnb.nn import Linear8bitLt
- 然後您可以定義自己的模型。請注意,您可以將任何精度的檢查點或模型轉換為 8 位(FP16、BF16 或 FP32),但目前,模型的輸入必須是 FP16 才能使我們的 Int8 模組工作。因此,我們在這裡將模型視為 fp16 模型。
fp16_model = nn.Sequential(
nn.Linear(64, 64),
nn.Linear(64, 64)
)
- 假設您已經在您最喜歡的資料集和任務上訓練了您的模型!現在是時候儲存模型了
[... train the model ...]
torch.save(fp16_model.state_dict(), "model.pt")
- 現在您的
state_dict已儲存,讓我們定義一個 int8 模型
int8_model = nn.Sequential(
Linear8bitLt(64, 64, has_fp16_weights=False),
Linear8bitLt(64, 64, has_fp16_weights=False)
)
這裡非常重要的是要新增 has_fp16_weights 標誌。預設情況下,這設定為 True,用於以混合 Int8/FP16 精度進行訓練。但是,我們感興趣的是記憶體高效推理,為此我們需要使用 has_fp16_weights=False。
- 現在是時候以 8 位載入模型了!
int8_model.load_state_dict(torch.load("model.pt"))
int8_model = int8_model.to(0) # Quantization happens here
請注意,量化步驟是在模型設定到 GPU 上後第二行完成的。如果您在呼叫 .to 函式之前列印 int8_model[0].weight,您會得到
int8_model[0].weight
Parameter containing:
tensor([[ 0.0031, -0.0438, 0.0494, ..., -0.0046, -0.0410, 0.0436],
[-0.1013, 0.0394, 0.0787, ..., 0.0986, 0.0595, 0.0162],
[-0.0859, -0.1227, -0.1209, ..., 0.1158, 0.0186, -0.0530],
...,
[ 0.0804, 0.0725, 0.0638, ..., -0.0487, -0.0524, -0.1076],
[-0.0200, -0.0406, 0.0663, ..., 0.0123, 0.0551, -0.0121],
[-0.0041, 0.0865, -0.0013, ..., -0.0427, -0.0764, 0.1189]],
dtype=torch.float16)
而在呼叫第二行之後列印,您會得到
int8_model[0].weight
Parameter containing:
tensor([[ 3, -47, 54, ..., -5, -44, 47],
[-104, 40, 81, ..., 101, 61, 17],
[ -89, -127, -125, ..., 120, 19, -55],
...,
[ 82, 74, 65, ..., -49, -53, -109],
[ -21, -42, 68, ..., 13, 57, -12],
[ -4, 88, -1, ..., -43, -78, 121]],
device='cuda:0', dtype=torch.int8, requires_grad=True)
正如我們在前幾節解釋量化時所看到的,權重值是“截斷”的。此外,值似乎分佈在 [-127, 127] 之間。您可能還會想,如何檢索 FP16 權重以執行 fp16 中的異常值 MatMul?您只需執行以下操作
(int8_model[0].weight.CB * int8_model[0].weight.SCB) / 127
你會得到
tensor([[ 0.0028, -0.0459, 0.0522, ..., -0.0049, -0.0428, 0.0462],
[-0.0960, 0.0391, 0.0782, ..., 0.0994, 0.0593, 0.0167],
[-0.0822, -0.1240, -0.1207, ..., 0.1181, 0.0185, -0.0541],
...,
[ 0.0757, 0.0723, 0.0628, ..., -0.0482, -0.0516, -0.1072],
[-0.0194, -0.0410, 0.0657, ..., 0.0128, 0.0554, -0.0118],
[-0.0037, 0.0859, -0.0010, ..., -0.0423, -0.0759, 0.1190]],
device='cuda:0')
這與原始的 FP16 值(上方列印的兩個值)足夠接近!
- 現在您可以安全地使用您的模型進行推理,確保您的輸入在正確的 GPU 上且為 FP16
input_ = torch.randn((1, 64), dtype=torch.float16)
hidden_states = int8_model(input_.to(torch.device('cuda', 0)))
檢視 示例指令碼 獲取完整的最小程式碼!
另外,您應該注意,這些模組與 nn.Linear 模組略有不同,因為它們的引數來自 bnb.nn.Int8Params 類而不是 nn.Parameter 類。您稍後會發現,這在我們的旅程中提出了額外的障礙!
現在是時候瞭解如何將其整合到 transformers 庫中了!
accelerate 是您所需要的一切
在處理大型模型時,accelerate 庫包含許多有用的實用工具。init_empty_weights 方法特別有用,因為任何模型,無論大小,都可以使用此方法作為上下文管理器進行初始化,而無需為模型權重分配任何記憶體。
import torch.nn as nn
from accelerate import init_empty_weights
with init_empty_weights():
model = nn.Sequential([nn.Linear(100000, 100000) for _ in range(1000)]) # This will take ~0 RAM!
初始化後的模型將放置在 PyTorch 的 meta 裝置上,這是一種底層機制,用於表示形狀和資料型別而無需分配記憶體。這多酷啊!
最初,此函式在 .from_pretrained 函式內部被呼叫,並將所有引數覆蓋為 torch.nn.Parameter。這不符合我們的要求,因為我們希望在 Linear8bitLt 模組的案例中保留 Int8Params 類,如上所述。我們設法在 以下 PR 中解決了這個問題,該 PR 修改了
module._parameters[name] = nn.Parameter(module._parameters[name].to(torch.device("meta")))
到
param_cls = type(module._parameters[name])
kwargs = module._parameters[name].__dict__
module._parameters[name] = param_cls(module._parameters[name].to(torch.device("meta")), **kwargs)
現在這個問題已經解決了,我們可以輕鬆利用這個上下文管理器,並透過自定義函式替換 meta 裝置上初始化的所有 nn.Linear 模組為 bnb.nn.Linear8bitLt,而無需任何記憶體開銷!
def replace_8bit_linear(model, threshold=6.0, module_to_not_convert="lm_head"):
for name, module in model.named_children():
if len(list(module.children())) > 0:
replace_8bit_linear(module, threshold, module_to_not_convert)
if isinstance(module, nn.Linear) and name != module_to_not_convert:
with init_empty_weights():
model._modules[name] = bnb.nn.Linear8bitLt(
module.in_features,
module.out_features,
module.bias is not None,
has_fp16_weights=False,
threshold=threshold,
)
return model
此函式遞迴地將給定模型在 meta 裝置上初始化的所有 nn.Linear 層替換為 Linear8bitLt 模組。屬性 has_fp16_weights 必須設定為 False,以便直接載入 int8 中的權重以及量化統計資訊。
我們還放棄了對某些模組(這裡是 lm_head)的替換,因為我們希望它們保持其原生精度,以獲得更精確和穩定的結果。
但是還沒結束!上述函式在 init_empty_weights 上下文管理器下執行,這意味著新模型仍將位於 meta 裝置中。對於在此上下文管理器下初始化的模型,accelerate 將手動載入每個模組的引數並將其移動到正確的裝置。在 bitsandbytes 中,設定 Linear8bitLt 模組的裝置是一個關鍵步驟(如果您好奇,可以檢視 這裡的程式碼片段),正如我們在玩具指令碼中看到的那樣。
這裡,當兩次呼叫時,量化步驟會失敗。我們不得不實現 accelerate 的 set_module_tensor_to_device 函式(稱為 set_module_8bit_tensor_to_device),以確保我們不會兩次呼叫它。讓我們在下面詳細討論這個問題!
使用 accelerate 設定裝置時要非常小心
在這裡,我們與 accelerate 庫玩了一場非常微妙的平衡遊戲!一旦您載入模型並將其設定到正確的裝置上,有時您仍然需要呼叫 set_module_tensor_to_device 來將模型與鉤子一起分派到所有裝置。這是在 accelerate 的 dispatch_model 函式內部完成的,這可能涉及多次呼叫 .to,這是我們想要避免的。為了實現我們的目標,需要兩個拉取請求!最初的 PR 此處 提出,但此 PR 成功修復了所有問題!
總結
因此,最終的方案是
- 在
meta裝置上使用正確的模組初始化模型 - 逐個將引數設定到正確的 GPU 裝置上,並確保不要重複此過程!
- 將新的關鍵字引數放置在正確的位置,並新增一些不錯的文件
- 新增非常詳盡的測試!檢視我們的測試此處瞭解更多詳情。這聽起來很簡單,但我們一起經歷了許多艱難的除錯會話,通常涉及 CUDA 核心!
總而言之,這次整合之旅非常有趣;從深入研究和對不同庫進行一些“手術”到協調一切並使其正常工作!
現在是時候瞭解如何從這次整合中受益以及如何成功地在 transformers 中使用它了!
如何在 transformers 中使用
硬體要求
CPU 不支援 8 位張量核心。bitsandbytes 可以在支援 8 位張量核心的硬體上執行,例如 Turing 和 Ampere GPU(RTX 20s、RTX 30s、A40-A100、T4+)。例如,Google Colab GPU 通常是 NVIDIA T4 GPU,它們的最新一代 GPU 支援 8 位張量核心。我們的演示基於 Google Colab,請在下面檢視!
安裝
只需使用以下命令安裝最新版本的庫(確保您使用的是 python>=3.8),然後執行以下命令進行嘗試
pip install accelerate
pip install bitsandbytes
pip install git+https://github.com/huggingface/transformers.git
示例演示 - 在 Google Colab 上執行 T5 11b
檢視在 BLOOM-3B 模型上執行 8 位模型的 Google Colab 演示!
這是執行 T5-11B 的演示。T5-11B 模型檢查點為 FP32,佔用 42GB 記憶體,不適合在 Google Colab 上執行。使用我們的 8 位模組,它僅佔用 11GB,輕鬆執行
![]()
或者這是 BLOOM-3B 的演示
![]()
改進範圍
在我們看來,這種方法極大地提高了對大型模型的訪問能力。在不降低效能的情況下,它使計算能力較低的使用者能夠訪問以前無法訪問的模型。我們發現了一些未來可以改進的領域,以使這種方法對大型模型更好!
小型模型的更快的推理速度
正如我們在基準測試部分所看到的,我們可以將小型模型(<=6B 引數)的執行時速度提高近 2 倍。然而,儘管 BLOOM-176B 等大型模型的推理速度穩定,但小型模型仍有改進空間。我們已經確定了問題,並且很可能恢復與 fp16 相同的效能,或者獲得小幅加速。您將在未來幾周內看到這些更改整合。
支援 Kepler GPU(GTX 1080 等)
雖然我們支援過去四年內的所有 GPU,但一些舊的 GPU(如 GTX 1080)仍在使用。雖然這些 GPU 沒有 Int8 張量核心,但它們確實有 Int8 向量單元(一種“弱”張量核心)。因此,這些 GPU 也可以體驗到 Int8 加速。然而,它需要一個完全不同的軟體堆疊才能實現快速推理。儘管我們確實計劃整合對 Kepler GPU 的支援,以使 LLM.int8() 功能更廣泛地可用,但由於其複雜性,實現這一點將需要一些時間。
在 Hub 上儲存 8 位狀態字典
目前,8 位狀態字典無法在推送到 Hub 後直接載入到 8 位模型中。這是因為模型計算的統計資料(記住 weight.CB 和 weight.SCB)目前未儲存或未在狀態字典中考慮,並且 Linear8bitLt 模組尚不支援此功能。我們認為能夠儲存並推送到 Hub 可能會有助於提高可訪問性。
CPU 支援
如本部落格文章開頭所述,CPU 裝置不支援 8 位核心。但是,我們能否克服這一點?在 CPU 上執行此模組也將顯著提高可用性和可訪問性。
在其他模態上進行擴充套件
目前,語言模型在大型模型中佔據主導地位。隨著這些模型在未來幾年變得更易於訪問,將此方法應用於大型視覺、音訊和多模態模型可能是一個有趣的選擇,以提高可訪問性。
鳴謝
衷心感謝以下為提高文章可讀性以及為 transformers 的整合過程做出貢獻的人士(按字母順序排列):JustHeuristic (Yozh)、Michael Benayoun、Stas Bekman、Steven Liu、Sylvain Gugger、Tim Dettmers






