我在 Google Cloud 上構建無伺服器 transformers pipeline 的歷程



社群成員 Maxence Dominici 的客座博文
本文將討論我將
transformers 情感分析 pipeline 部署到 Google Cloud 的歷程。我們將首先簡要介紹 transformers,然後進入技術實現部分。最後,我們將總結這個實現並回顧我們所取得的成就。
目標
 我想建立一個微服務,自動檢測在 Discord 中留下的客戶評論是正面的還是負面的。這將使我能夠相應地處理評論並改善客戶體驗。例如,如果評論是負面的,我可以建立一個功能來聯絡客戶,為服務質量不佳道歉,並告知他/她我們的支援團隊會盡快與他/她聯絡以提供幫助並希望解決問題。由於我計劃每月處理不超過 2,000 個請求,因此我對時間和可擴充套件性沒有施加任何效能約束。
我想建立一個微服務,自動檢測在 Discord 中留下的客戶評論是正面的還是負面的。這將使我能夠相應地處理評論並改善客戶體驗。例如,如果評論是負面的,我可以建立一個功能來聯絡客戶,為服務質量不佳道歉,並告知他/她我們的支援團隊會盡快與他/她聯絡以提供幫助並希望解決問題。由於我計劃每月處理不超過 2,000 個請求,因此我對時間和可擴充套件性沒有施加任何效能約束。
Transformers 庫
當我下載 .h5 檔案時,一開始有點困惑。我以為它會與 tensorflow.keras.models.load_model 相容,但事實並非如此。經過幾分鐘的研究,我發現該檔案是一個權重檢查點,而不是 Keras 模型。之後,我嘗試了 Hugging Face 提供的 API,並閱讀了更多關於他們提供的 pipeline 功能的資訊。由於 API 和 pipeline 的結果都很棒,我決定可以在我自己的伺服器上透過 pipeline 來提供模型服務。
以下是 Transformers GitHub 頁面上的官方示例。
from transformers import pipeline
# Allocate a pipeline for sentiment-analysis
classifier = pipeline('sentiment-analysis')
classifier('We are very happy to include pipeline into the transformers repository.')
[{'label': 'POSITIVE', 'score': 0.9978193640708923}]
將 transformers 部署到 Google Cloud
選擇 GCP 是因為它是我個人組織中使用的雲環境。
第 1 步 - 調研
我已經知道可以使用像 flask 這樣的 API 服務來提供 transformers 模型。我在 Google Cloud AI 文件中搜索,找到了一個託管 Tensorflow 模型的服務,名為 AI-Platform Prediction。我也在那裡找到了 App Engine 和 Cloud Run,但我擔心 App Engine 的記憶體使用情況,而且對 Docker 也不是很熟悉。
第 2 步 - 在 AI-Platform Prediction 上測試
由於該模型不是一個“純 TensorFlow”儲存的模型,而是一個檢查點,並且我無法將其轉換為“純 TensorFlow 模型”,我發現此頁面上的示例行不通。從那裡我看到我可以編寫一些自定義程式碼,這允許我載入 pipeline 而不必處理模型,這似乎更容易。我還了解到我可以定義一個預測前和預測後操作,這在將來對客戶需求的預處理或後處理資料可能很有用。我按照 Google 的指南操作,但遇到了一個問題,因為該服務仍處於測試階段,一切都不穩定。這個問題在這裡有詳細說明。
第 3 步 - 在 App Engine 上測試
我轉向了 Google 的 App Engine,因為這是我熟悉的一項服務,但由於缺少系統依賴檔案,遇到了 TensorFlow 的安裝問題。然後我嘗試了 PyTorch,它在 F4_1G 例項上可以工作,但它在同一個例項上無法處理超過 2 個請求,這在效能方面並不是很好。
第 4 步 - 在 Cloud Run 上測試
最後,我轉向使用 docker 映象的 Cloud Run。我按照這份指南來了解它的工作原理。在 Cloud Run 中,我可以配置更高的記憶體和更多的 vCPU 來用 PyTorch 執行預測。我放棄了 Tensorflow,因為 PyTorch 似乎載入模型更快。
無伺服器 pipeline 的實現
最終的解決方案由四個不同的元件組成
main.py處理對 pipeline 的請求Dockerfile用於建立將部署在 Cloud Run 上的映象。- 包含
pytorch_model.bin、config.json和vocab.txt的模型資料夾。- 模型:DistilBERT base uncased finetuned SST-2
- 要下載模型資料夾,請按照按鈕中的說明操作。
- 你不需要保留
rust_model.ot或tf_model.h5,因為我們將使用 PyTorch。
requirement.txt用於安裝依賴項
main.py 的內容非常簡單。其思想是接收一個包含兩個欄位的 GET 請求。首先是需要分析的評論,其次是用於“保護”服務的 API 金鑰。第二個引數是可選的,我用它來避免設定 Cloud Run 的 oAuth2。提供這些引數後,我們載入基於模型 distilbert-base-uncased-finetuned-sst-2-english(如上提供)構建的 pipeline。最後,將最佳匹配結果返回給客戶端。
import os
from flask import Flask, jsonify, request
from transformers import pipeline
app = Flask(__name__)
model_path = "./model"
@app.route('/')
def classify_review():
review = request.args.get('review')
api_key = request.args.get('api_key')
if review is None or api_key != "MyCustomerApiKey":
return jsonify(code=403, message="bad request")
classify = pipeline("sentiment-analysis", model=model_path, tokenizer=model_path)
return classify("that was great")[0]
if __name__ == '__main__':
# This is used when running locally only. When deploying to Google Cloud
# Run, a webserver process such as Gunicorn will serve the app.
app.run(debug=False, host="0.0.0.0", port=int(os.environ.get("PORT", 8080)))
然後是 DockerFile,它將用於建立服務的 docker 映象。我們指定我們的服務運行於 python:3.7,並且需要安裝我們的依賴項。然後我們使用 gunicorn 在埠 5000 上處理我們的程序。
# Use Python37
FROM python:3.7
# Allow statements and log messages to immediately appear in the Knative logs
ENV PYTHONUNBUFFERED True
# Copy requirements.txt to the docker image and install packages
COPY requirements.txt /
RUN pip install -r requirements.txt
# Set the WORKDIR to be the folder
COPY . /app
# Expose port 5000
EXPOSE 5000
ENV PORT 5000
WORKDIR /app
# Use gunicorn as the entrypoint
CMD exec gunicorn --bind :$PORT main:app --workers 1 --threads 1 --timeout 0
需要注意引數 --workers 1 --threads 1,這意味著我只想在一個 worker(= 1 個程序)上用單個執行緒執行我的應用程式。這是因為我不想同時啟動 2 個例項,因為這可能會增加賬單。一個缺點是,如果服務同時收到兩個請求,處理時間會更長。之後,由於將模型載入到 pipeline 中所需的記憶體使用量,我將限制設定為一個執行緒。如果我使用 4 個執行緒,我可能只有 4 Gb / 4 = 1 Gb 來執行完整的流程,這不夠用,會導致記憶體錯誤。
最後是 requirement.txt 檔案
Flask==1.1.2
torch===1.7.1
transformers~=4.2.0
gunicorn>=20.0.0
部署說明
首先,您需要滿足一些要求,例如在 Google Cloud 上有一個專案、啟用計費並安裝 gcloud cli。您可以在 Google 的指南 - 準備工作中找到更多詳細資訊。
其次,我們需要構建 docker 映象並將其部署到 cloud run,方法是選擇正確的專案(替換 PROJECT-ID)並設定例項的名稱,例如 ai-customer-review。您可以在 Google 的指南 - 部署到中找到有關部署的更多資訊。
gcloud builds submit --tag gcr.io/PROJECT-ID/ai-customer-review
gcloud run deploy --image gcr.io/PROJECT-ID/ai-customer-review --platform managed
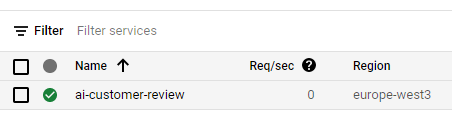
幾分鐘後,您還需要將分配給 Cloud Run 例項的記憶體從 256 MB 升級到 4 Gb。為此,請前往您專案的 Cloud Run 控制檯。
在那裡您應該能找到您的例項,點選它。
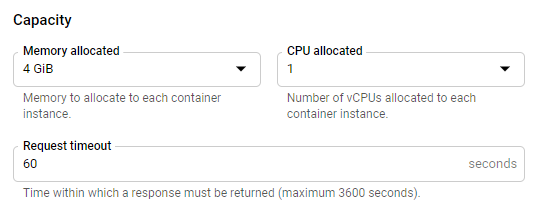
之後,您將在螢幕頂部看到一個藍色的“編輯和部署新修訂版本”按鈕,點選它,您將被提示輸入許多配置欄位。在底部,您應該會找到一個“容量”部分,您可以在其中指定記憶體。
效能
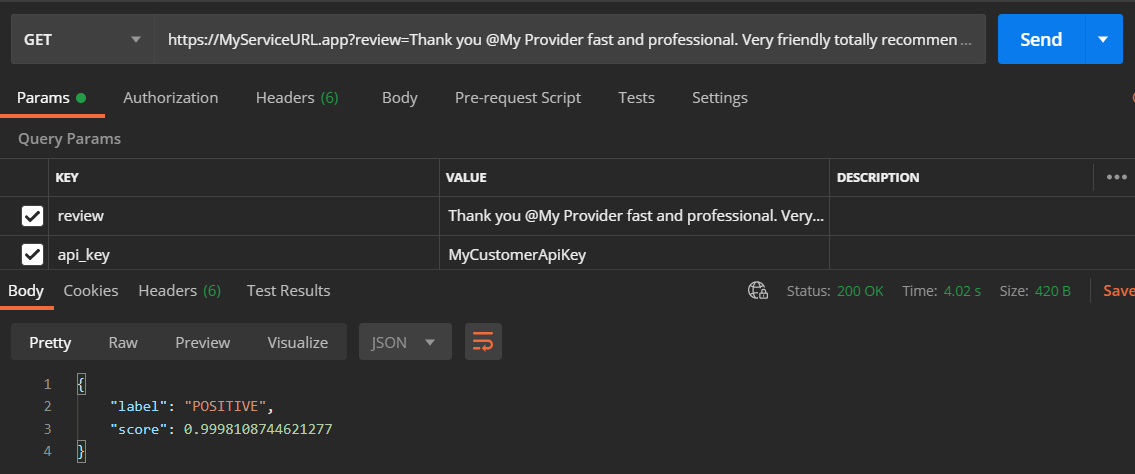
從您傳送請求的那一刻起,處理一個請求的時間不到五秒,包括將模型載入到 pipeline 和預測。冷啟動可能需要額外 10 秒左右的時間。
我們可以透過預熱模型來提高請求處理效能,即在啟動時而不是在每個請求時載入它(例如使用全域性變數),透過這樣做,我們節省了時間和記憶體使用。
成本
我使用 Google 定價模擬器根據 Cloud Run 例項配置模擬了成本 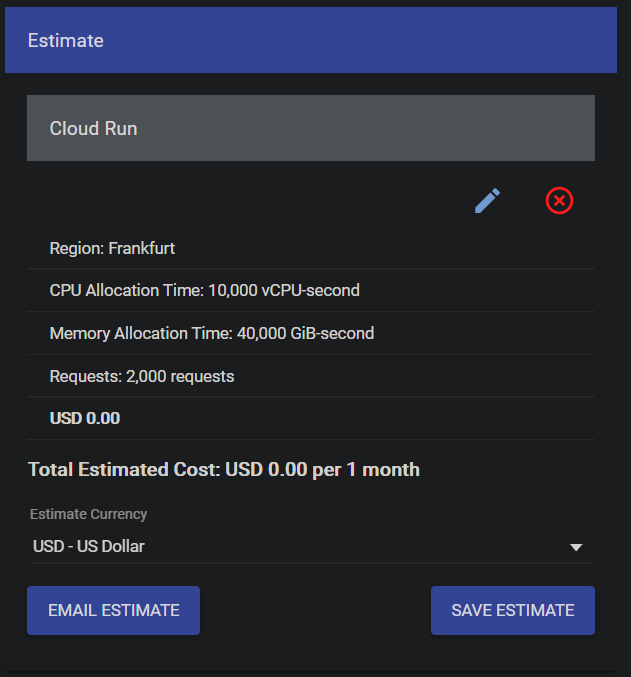
對於我的微服務,我計劃每月接近 1,000 個請求,這是樂觀的估計。對於我的使用情況,500 個可能更現實。這就是為什麼我在設計我的微服務時將 2,000 個請求視為上限。由於請求數量少,我沒有太多地考慮可伸縮性,但如果我的賬單增加,我可能會重新考慮這個問題。
然而,需要強調的是,您將為構建映象的每個 GB 支付儲存費用。每月大約是每 Gb 0.10 歐元,如果您不在雲上保留所有版本,這是可以接受的,因為我的版本略高於 1 Gb(Pytorch 佔 700 Mb,模型佔 250 Mb)。
結論
透過使用 Transformers 的情感分析 pipeline,我節省了不可忽視的時間。我不需要訓練/微調模型,而是找到了一個可以用於生產的模型,並開始在我的系統中進行部署。我將來可能會對其進行微調,但正如我的測試所示,準確性已經非常驚人了!我希望能有一個“純 TensorFlow”模型,或者至少有一種在沒有 Transformers 依賴的情況下將其載入到 TensorFlow 中的方法,以便使用 AI 平臺。如果能有一個精簡版也會很棒。

