訓練和微調 Sentence Transformers 模型







本指南僅適用於 v3.0 之前的 Sentence Transformers。請閱讀 使用 Sentence Transformers v3 訓練和微調嵌入模型 以獲取更新的指南。
檢視此教程和配套 Notebook: ![]()
訓練或微調 Sentence Transformers 模型高度依賴於可用資料和目標任務。關鍵在於兩點
- 瞭解如何將資料輸入模型並相應地準備資料集。
- 瞭解不同的損失函式以及它們與資料集的關係。
在本教程中,您將
- 透過“從零開始”建立或從 Hugging Face Hub 微調 Sentence Transformers 模型來了解其工作原理。
- 學習資料集可能具有的不同格式。
- 根據資料集格式回顧可以選擇的不同損失函式。
- 訓練或微調您的模型。
- 將您的模型分享到 Hugging Face Hub。
- 瞭解何時 Sentence Transformers 模型可能不是最佳選擇。
Sentence Transformers 模型的工作原理
在 Sentence Transformer 模型中,您將可變長度的文字(或影像畫素)對映到固定大小的嵌入,該嵌入表示輸入的含義。要開始使用嵌入,請檢視我們的之前的教程。本文主要關注文字。
Sentence Transformers 模型的工作原理如下
- 第一層 – 輸入文字透過預訓練的 Transformer 模型,該模型可以直接從 Hugging Face Hub 獲取。本教程將使用“distilroberta-base”模型。Transformer 的輸出是所有輸入 token 的語境化詞嵌入;想象一下文字中每個 token 的嵌入。
- 第二層 - 嵌入透過池化層,以獲取所有文字的單個固定長度嵌入。例如,均值池化(mean pooling)對模型生成的嵌入進行平均。
此圖總結了該過程
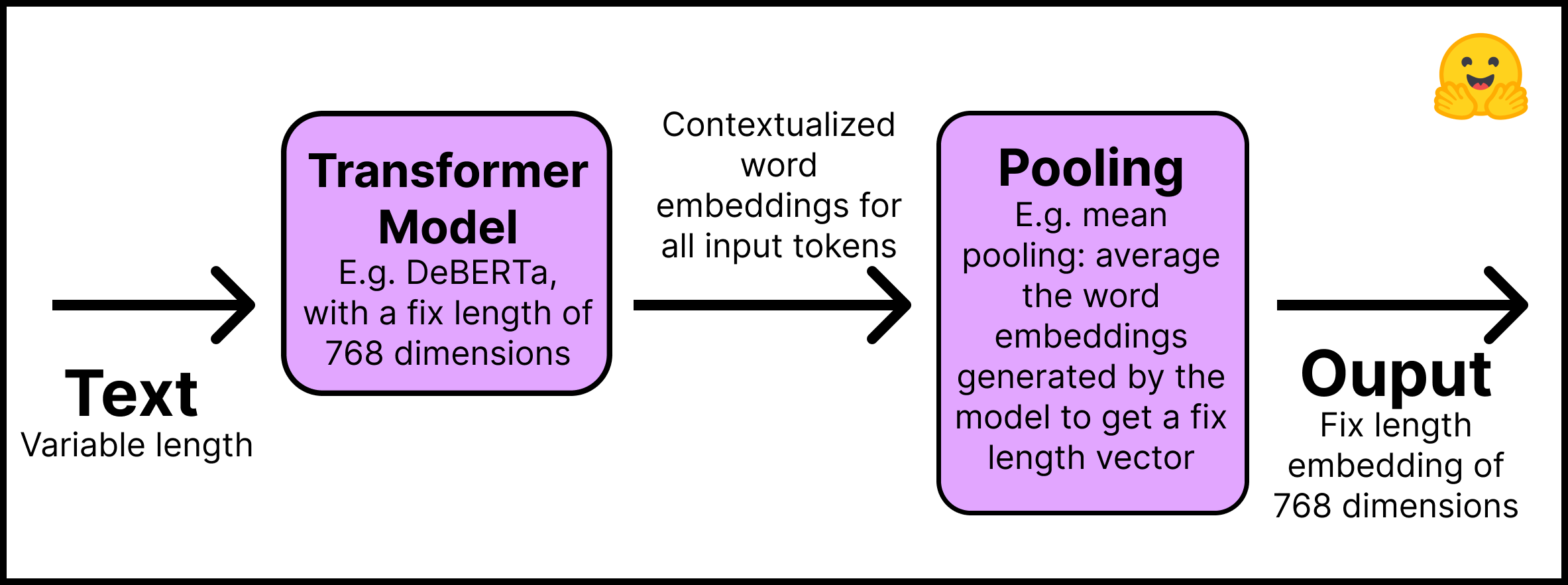
請記住使用 pip install -U sentence-transformers 安裝 Sentence Transformers 庫。在程式碼中,這個兩步過程很簡單
from sentence_transformers import SentenceTransformer, models
## Step 1: use an existing language model
word_embedding_model = models.Transformer('distilroberta-base')
## Step 2: use a pool function over the token embeddings
pooling_model = models.Pooling(word_embedding_model.get_word_embedding_dimension())
## Join steps 1 and 2 using the modules argument
model = SentenceTransformer(modules=[word_embedding_model, pooling_model])
從上面的程式碼可以看出,Sentence Transformers 模型由模組組成,即一系列按順序執行的層。輸入文字進入第一個模組,最終輸出來自最後一個元件。正如它看起來一樣簡單,上述模型是 Sentence Transformers 模型的典型架構。如有必要,可以新增額外的層,例如密集層、詞袋層和卷積層。
為什麼不直接使用像 BERT 或 Roberta 這樣的 Transformer 模型來為整個句子和文字建立嵌入呢?至少有兩個原因。
- 預訓練的 Transformers 模型執行語義搜尋任務需要大量計算。例如,在 10,000 個句子的集合中找到最相似的對 使用 BERT 大約需要 5000 萬次推理計算(約 65 小時)。相比之下,BERT Sentence Transformers 模型將時間縮短到大約 5 秒。
- 一旦訓練,Transformers 模型開箱即用地建立的句子表示很差。BERT 模型將其 token 嵌入平均以建立句子嵌入 效能不如 2014 年開發的 GloVe 嵌入。
在本節中,我們正在從頭開始建立一個 Sentence Transformers 模型。如果您想微調現有的 Sentence Transformers 模型,可以跳過上面的步驟並從 Hugging Face Hub 匯入它。您可以在 “句子相似度” 任務中找到大多數 Sentence Transformers 模型。這裡我們載入“sentence-transformers/all-MiniLM-L6-v2”模型
from sentence_transformers import SentenceTransformer
model_id = "sentence-transformers/all-MiniLM-L6-v2"
model = SentenceTransformer(model_id)
現在是最關鍵的部分:資料集格式。
如何準備資料集以訓練 Sentence Transformers 模型
要訓練 Sentence Transformers 模型,您需要以某種方式告知它兩個句子具有一定的相似度。因此,資料中的每個示例都需要一個標籤或結構,以使模型能夠理解兩個句子是相似還是不同。
不幸的是,沒有一種方法可以準備資料來訓練 Sentence Transformers 模型。這在很大程度上取決於您的目標和資料結構。如果您沒有明確的標籤(這是最可能的情況),您可以從獲取句子的文件設計中推斷出來。例如,同一報告中的兩個句子可能比不同報告中的兩個句子更具可比性。相鄰的句子可能比不相鄰的句子更具可比性。
此外,資料結構將影響您可以使用哪種損失函式。這將在下一節中討論。
請記住,本帖的 配套 Notebook 已實現所有程式碼。
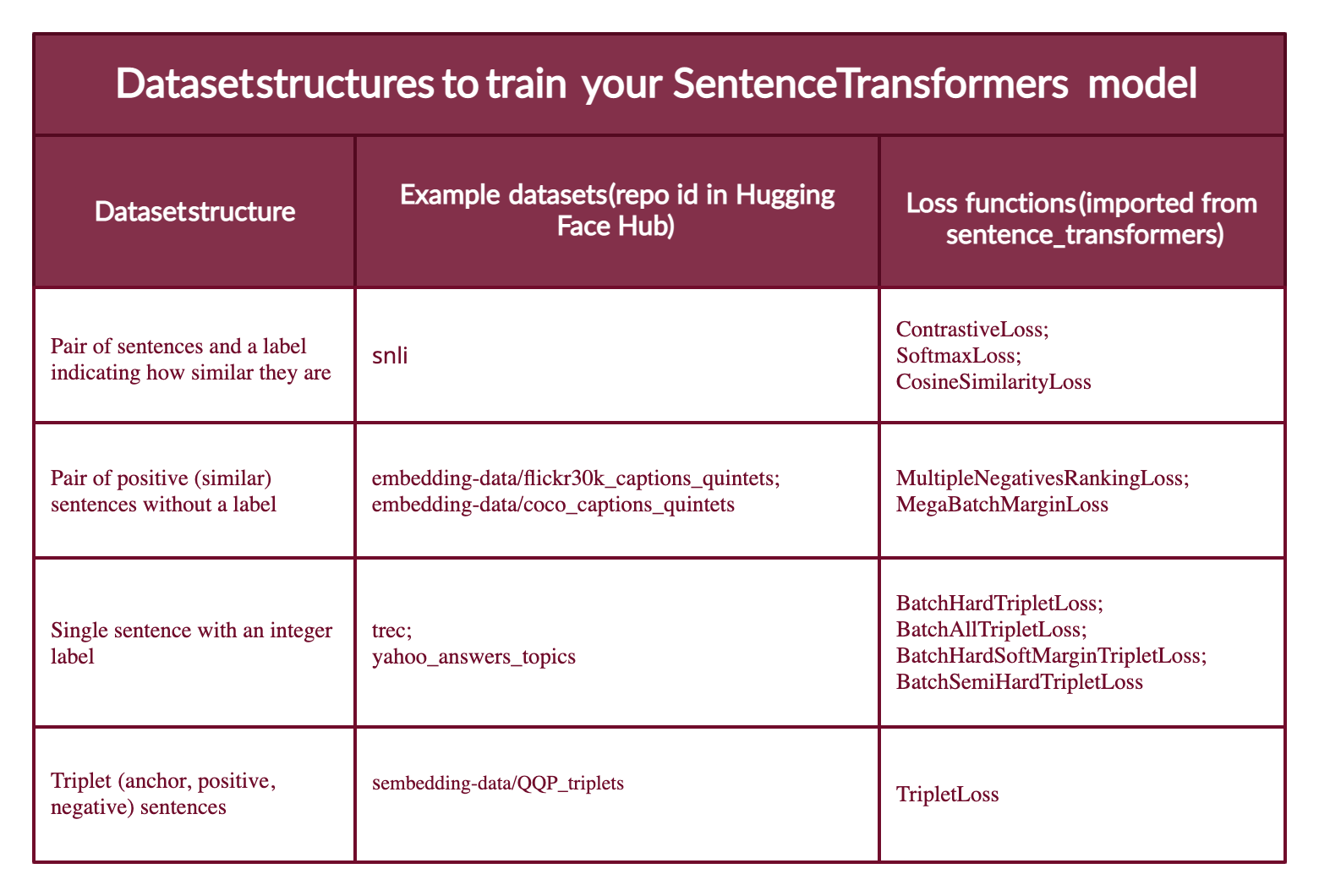
大多數資料集配置將採用以下四種形式之一(下面您將看到每個案例的示例)
- 案例 1:示例是一對句子和一個指示它們相似程度的標籤。標籤可以是整數或浮點數。此案例適用於最初為自然語言推理(NLI)準備的資料集,因為它們包含帶有標籤的句子對,指示它們是否相互推斷。
- 案例 2:示例是一對正(相似)句子,沒有標籤。例如,釋義對、全文及其摘要對、重複問題對、(
查詢,響應) 對,或 (源語言,目標語言) 對。自然語言推理資料集也可以透過配對推斷句子來以此方式格式化。將資料採用這種格式非常有用,因為您可以使用MultipleNegativesRankingLoss,它是 Sentence Transformers 模型最常用的損失函式之一。 - 案例 3:示例是一個帶整數標籤的句子。這種資料格式可以很容易地透過損失函式轉換為三個句子(三元組),其中第一個是“錨點”,第二個是與錨點相同類別的“正例”,第三個是不同類別的“負例”。每個句子都有一個整數標籤,指示其所屬的類別。
- 案例 4:示例是一個三元組(錨點、正例、負例),沒有句子的類別或標籤。
例如,在本教程中,您將使用第四種情況下的資料集訓練 Sentence Transformer。然後,您將使用第二種情況下的資料集配置對其進行微調(請參閱此部落格的 配套 Notebook)。
請注意,Sentence Transformers 模型可以透過人工標註(案例 1 和 3)或透過文字格式自動推斷標籤(主要是案例 2;儘管案例 4 不需要標籤,但除非您像 MegaBatchMarginLoss 函式那樣處理它,否則很難找到三元組資料)。
Hugging Face Hub 上有針對上述每種情況的資料集。此外,Hub 中的資料集具有資料集預覽功能,允許您在下載資料集之前檢視其結構。以下是每個案例的示例資料集
案例 1:如果您有(或製造)一個指示兩個句子之間相似程度的標籤,例如 {0,1,2},其中 0 表示矛盾,2 表示蘊涵,則可以使用與自然語言推理相同的設定。請檢視 SNLI 資料集 的結構。
案例 2:句子壓縮資料集 包含由正向對組成的示例。如果您的資料集中每個示例有超過兩個正向句子,例如 COCO 標題 或 Flickr30k 標題 資料集中的五元組,您可以將示例格式化為具有不同的正向對組合。
案例 3:TREC 資料集 具有指示每個句子類別的整數標籤。Yahoo Answers Topics 資料集 中的每個示例都包含三個句子和一個指示其主題的標籤;因此,每個示例可以分為三部分。
案例 4:Quora Triplet 資料集 包含沒有標籤的三元組(錨點、正例、負例)。
下一步是將資料集轉換為 Sentence Transformers 模型可以理解的格式。模型不能接受原始字串列表。每個示例都必須轉換為 sentence_transformers.InputExample 類,然後轉換為 torch.utils.data.DataLoader 類以批次處理和打亂示例。
使用 pip install datasets 安裝 Hugging Face Datasets。然後使用 load_dataset 函式匯入資料集
from datasets import load_dataset
dataset_id = "embedding-data/QQP_triplets"
dataset = load_dataset(dataset_id)
本指南使用了一個無標籤的三元組資料集,即上述第四種情況。
使用 datasets 庫,您可以探索資料集
print(f"- The {dataset_id} dataset has {dataset['train'].num_rows} examples.")
print(f"- Each example is a {type(dataset['train'][0])} with a {type(dataset['train'][0]['set'])} as value.")
print(f"- Examples look like this: {dataset['train'][0]}")
輸出
- The embedding-data/QQP_triplets dataset has 101762 examples.
- Each example is a <class 'dict'> with a <class 'dict'> as value.
- Examples look like this: {'set': {'query': 'Why in India do we not have one on one political debate as in USA?', 'pos': ['Why can't we have a public debate between politicians in India like the one in US?'], 'neg': ['Can people on Quora stop India Pakistan debate? We are sick and tired seeing this everyday in bulk?'...]
您可以看到 `query` (錨點) 只有一個句子,`pos` (正例) 是一個句子列表 (我們列印的只有一個句子),`neg` (負例) 有多個句子列表。
將示例轉換為 InputExample。為簡單起見,(1) 在 embedding-data/QQP_triplets 資料集中將只使用一個正例和一個負例。(2) 我們將只使用可用示例的 1/2。透過增加示例數量,您可以獲得更好的結果。
from sentence_transformers import InputExample
train_examples = []
train_data = dataset['train']['set']
# For agility we only 1/2 of our available data
n_examples = dataset['train'].num_rows // 2
for i in range(n_examples):
example = train_data[i]
train_examples.append(InputExample(texts=[example['query'], example['pos'][0], example['neg'][0]]))
將訓練示例轉換為 Dataloader。
from torch.utils.data import DataLoader
train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=16)
下一步是選擇與資料格式相容的合適損失函式。
訓練 Sentence Transformers 模型的損失函式
還記得您的資料可能有四種不同格式嗎?每種格式都將對應一個不同的損失函式。
案例 1:句子對和一個指示它們相似程度的標籤。損失函式進行最佳化,使得 (1) 標籤最接近的句子在向量空間中距離較近,(2) 標籤最遠的句子距離儘可能遠。損失函式取決於標籤的格式。如果它是整數,使用 ContrastiveLoss 或 SoftmaxLoss;如果它是浮點數,您可以使用 CosineSimilarityLoss。
案例 2:如果只有兩個相似的句子(兩個正例)且沒有標籤,則可以使用 MultipleNegativesRankingLoss 函式。MegaBatchMarginLoss 也可以使用,它會將您的示例轉換為三元組 (anchor_i, positive_i, positive_j),其中 positive_j 用作負例。
案例 3:當您的樣本是 [錨點, 正例, 負例] 形式的三元組,並且每個樣本都有一個整數標籤時,損失函式會最佳化模型,使錨點和正例句子在向量空間中比錨點和負例句子更接近。您可以使用 BatchHardTripletLoss,它要求資料用整數標記(例如,標籤 1、2、3),假設相同標籤的樣本是相似的。因此,錨點和正例必須具有相同的標籤,而負例必須具有不同的標籤。或者,您可以使用 BatchAllTripletLoss、BatchHardSoftMarginTripletLoss 或 BatchSemiHardTripletLoss。它們之間的區別超出了本教程的範圍,但可以在 Sentence Transformers 文件中檢視。
案例 4:如果三元組中的每個句子都沒有標籤,則應使用 TripletLoss。此損失函式旨在最小化錨點和正例句子之間的距離,同時最大化錨點和負例句子之間的距離。
此圖總結了不同型別的資料集格式、Hub 中的示例資料集及其合適的損失函式。
最困難的部分是概念上選擇合適的損失函式。在程式碼中,只有兩行
from sentence_transformers import losses
train_loss = losses.TripletLoss(model=model)
一旦資料集採用所需格式並設定了合適的損失函式,擬合和訓練 Sentence Transformers 就很簡單了。
如何訓練或微調 Sentence Transformer 模型
“SentenceTransformers 的設計宗旨是讓您輕鬆地微調自己的句子/文字嵌入模型。它提供了大多數構建塊,您可以將它們組合起來,為您的特定任務調整嵌入。” - Sentence Transformers 文件。
訓練或微調過程如下所示
model.fit(train_objectives=[(train_dataloader, train_loss)], epochs=10)
請記住,如果您正在微調現有的 Sentence Transformers 模型(請參閱 配套 Notebook),您可以直接呼叫其 fit 方法。如果這是一個新的 Sentence Transformers 模型,您必須首先像在“Sentence Transformers 模型的工作原理”一節中那樣定義它。
就是這樣;您已經擁有了一個新的或改進的 Sentence Transformers 模型!您想將其分享到 Hugging Face Hub 嗎?
首先,登入到 Hugging Face Hub。您需要在您的 賬戶設定 中建立一個 write 令牌。然後有兩種登入方式
在終端中輸入
huggingface-cli login並輸入您的令牌。如果在 Python Notebook 中,您可以使用
notebook_login。
from huggingface_hub import notebook_login
notebook_login()
然後,您可以透過呼叫訓練模型的 save_to_hub 方法來分享您的模型。預設情況下,模型將上傳到您的帳戶。但是,您可以透過在 organization 引數中傳遞組織名稱來上傳到組織。save_to_hub 會自動生成模型卡、推理小部件、示例程式碼片段和更多詳細資訊。您可以使用引數 train_datasets 自動將您用於訓練模型的資料集列表新增到 Hub 的模型卡中
model.save_to_hub(
"distilroberta-base-sentence-transformer",
organization= # Add your username
train_datasets=["embedding-data/QQP_triplets"],
)
在 配套 Notebook 中,我使用 embedding-data/sentence-compression 資料集和 MultipleNegativesRankingLoss 損失函式微調了相同的模型。
Sentence Transformers 的侷限性是什麼?
Sentence Transformers 模型在語義搜尋方面比簡單的 Transformers 模型效果好得多。然而,Sentence Transformers 模型在哪些方面表現不佳呢?如果您的任務是分類,那麼使用句子嵌入是錯誤的方法。在這種情況下,🤗 Transformers 庫 將是更好的選擇。
額外資源
- 嵌入式入門.
- 理解語義搜尋.
- 開始您的第一個 Sentence Transformers 模型.
- 使用 Sentence Transformers 生成播放列表.
- Hugging Face + Sentence Transformers 文件.
感謝閱讀!祝您嵌入愉快。






