AMD + 🤗: 基於 AMD GPU 的大語言模型開箱即用加速









今年早些時候,AMD 和 Hugging Face 宣佈建立合作伙伴關係,在 AMD 的 AI Day 活動中加速 AI 模型。我們一直致力於將這一願景變為現實,讓 Hugging Face 社群能夠輕鬆地在 AMD 硬體上以最佳效能執行最新的 AI 模型。
AMD 正在為世界上一些最強大的超級計算機提供動力,包括歐洲最快的超級計算機 LUMI,它擁有超過 10,000 個 MI250X AMD GPU。在此次活動中,AMD 釋出了其最新一代的伺服器 GPU,即 AMD Instinct™ MI300 系列加速器,該系列加速器將很快普遍上市。
在這篇博文中,我們將介紹我們在為 AMD GPU 提供出色的開箱即用支援以及改進最新伺服器級 AMD Instinct GPU 的互操作性方面取得的進展。
開箱即用加速
你能在下面找到 AMD 特定的程式碼更改嗎?別費勁了,與在 NVIDIA GPU 上執行相比,這裡根本沒有 AMD 特定的程式碼 🤗。
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "01-ai/Yi-6B"
tokenizer = AutoTokenizer.from_pretrained(model_id)
with torch.device("cuda"):
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.float16)
inp = tokenizer(["Today I am in Paris and"], padding=True, return_tensors="pt").to("cuda")
res = model.generate(**inp, max_new_tokens=30)
print(tokenizer.batch_decode(res))
我們一直在努力的一個主要方面是能夠無需任何程式碼更改即可執行 Hugging Face Transformers 模型。我們現在支援所有 Transformers 模型和 AMD Instinct GPU 上的任務。我們的合作不會止步於此,因為我們正在探索對 Diffusers 模型和其他庫以及其他 AMD GPU 的開箱即用支援。
實現這一里程碑是我們團隊和公司之間的一項重大努力和合作。為了維持對 Hugging Face 社群的支援和效能,我們已經在我們的資料中心構建了 Hugging Face 開源庫在 AMD Instinct GPU 上的整合測試——並能夠與 Verne Global 合作,在冰島部署 AMD Instinct 伺服器,從而最大程度地減少這些新工作負載的碳影響。
除了原生支援,我們合作的另一個主要方面是為 AMD GPU 上可用的最新創新和功能提供整合。透過 Hugging Face 團隊、AMD 工程師和開源社群成員的合作,我們很高興地宣佈支援:
- AMD 開源專案 ROCmSoftwarePlatform/flash-attention 中的 Flash Attention v2 已原生整合到 Transformers 和 Text Generation Inference 中。
- 來自 vLLM 的 Paged Attention,以及 Text Generation Inference 中用於 ROCm 的各種融合核心。
- 使用 Transformers 在 ROCm 驅動的 GPU 上執行 DeepSpeed 現已正式驗證並支援。
- GPTQ 是一種常用的權重壓縮技術,用於減少模型記憶體需求,透過與 AutoGPTQ 和 Transformers 直接整合,在 ROCm GPU 上得到支援。
- Optimum-Benchmark,一個用於輕鬆測試 AMD GPU 上 Transformers 效能的實用工具,支援正常和分散式設定,以及受支援的最佳化和量化方案。
- 使用 Optimum 庫,透過 ROCMExecutionProvider 在 ROCm 驅動的 GPU 上執行 ONNX 模型。
我們非常高興能將這些最先進的加速工具提供給 Hugging Face 使用者,並且易於使用,並透過我們針對 AMD Instinct GPU 的新持續整合和開發管道提供持續的支援和效能。
一個具有 128 GB 高頻寬記憶體的 AMD Instinct MI250 GPU 具有兩個獨立的 ROCm 裝置(GPU 0 和 1),每個裝置具有 64 GB 高頻寬記憶體。
這意味著,只需一張 MI250 GPU 卡,我們就可以擁有兩個 PyTorch 裝置,可以非常方便地使用張量和資料並行來實現更高的吞吐量和更低的延遲。
在部落格文章的其餘部分,我們報告了透過大型語言模型進行文字生成所涉及的兩個步驟的效能結果:
- 預填充延遲:模型計算使用者提供的輸入或提示表示所需的時間(也稱為“首個 token 的時間”)。
- 每 token 解碼延遲:在預填充步驟之後,以自迴歸方式生成每個新 token 所需的時間。
- 解碼吞吐量:在解碼階段每秒生成的 token 數量。
使用 `optimum-benchmark` 並在 MI250 和 A100 GPU 上執行推理基準測試,有無最佳化,我們得到以下結果:
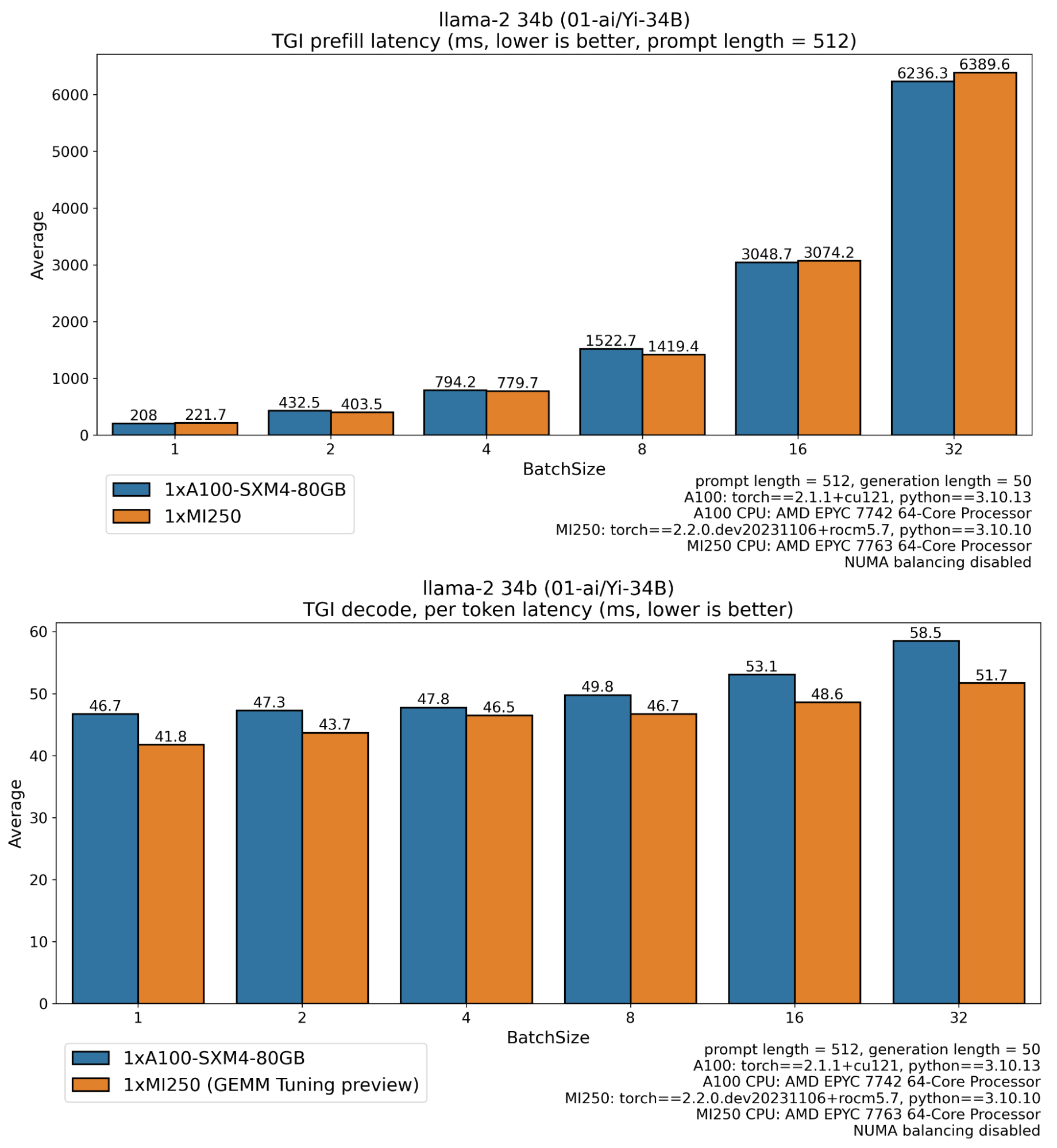
在上面的圖表中,我們可以看到 MI250 的效能表現,特別是在生產環境中,當請求以大批次處理時,MI250 比 A100 卡多輸出 2.33 倍以上的 token(解碼吞吐量),並且首個 token 的時間(預填充延遲)減少了一半。
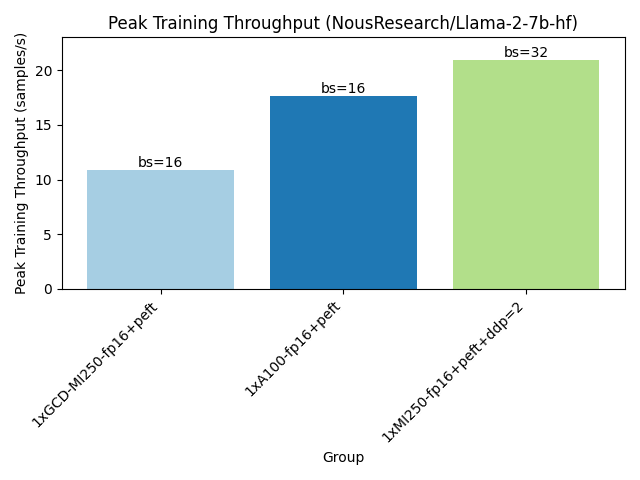
如下所示,執行訓練基準測試時,一張 MI250 卡可以容納更大的訓練樣本批次,並實現更高的訓練吞吐量。
生產解決方案
我們合作的另一個重要重點是為 Hugging Face 生產解決方案構建支援,從 Text Generation Inference (TGI) 開始。TGI 提供了一個端到端的解決方案,用於大規模部署大型語言模型進行推理。
最初,TGI 主要面向 Nvidia GPU,利用了對 Ampere 架構後進行的最新最佳化,例如 Flash Attention v1 和 v2、GPTQ 權重量化和 Paged Attention。
今天,我們很高興地宣佈 TGI 對 AMD Instinct MI210 和 MI250 GPU 的初步支援,利用上面詳細介紹的所有出色的開源工作,整合到一個完整的端到端解決方案中,隨時可以部署。
在效能方面,我們花費了大量時間在 AMD Instinct GPU 上對文字生成推理進行基準測試,以驗證並發現我們應該關注的最佳化點。因此,在 AMD GPU 工程師的支援下,我們已經能夠實現與 TGI 已提供效能相匹配的效能。
在此背景下,以及我們正在 AMD 和 Hugging Face 之間建立的長期關係,我們一直在整合和測試 AMD GeMM Tuner 工具,該工具允許我們調整 TGI 中使用的 GeMM(矩陣乘法)核心,以找到實現更高效能的最佳設定。GeMM Tuner 工具預計將在即將釋出的 PyTorch 版本中作為 PyTorch 的一部分釋出,供所有人受益。
綜上所述,我們很高興展示第一批效能資料,這些資料展示了最新的 AMD 技術,使 AMD GPU 上的文字生成推理在 Llama 模型系列的推理解決方案中處於領先地位。
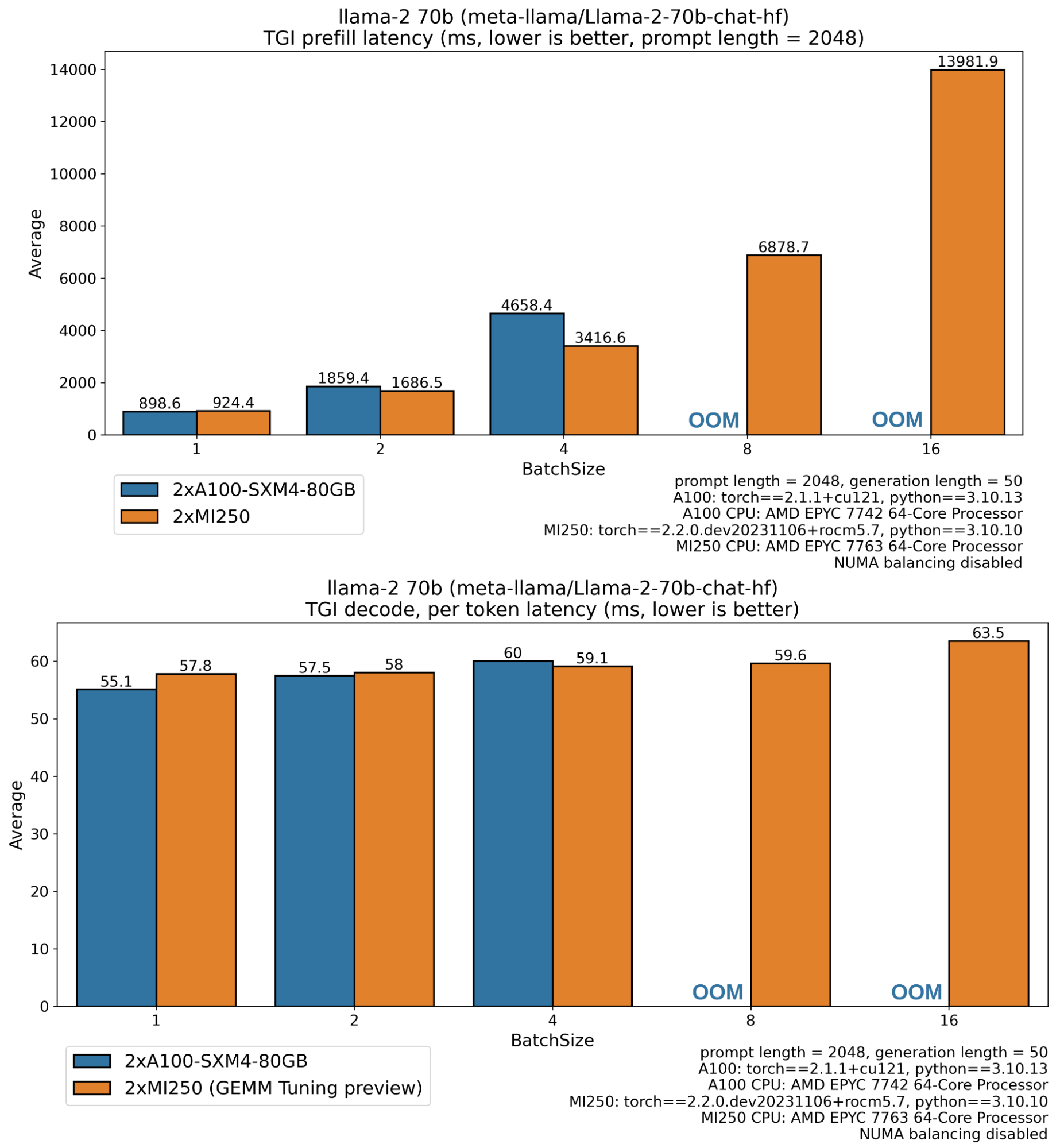
A100 缺失的條形圖對應於記憶體不足錯誤,因為 Llama 70B 的權重在 float16 中為 138 GB,並且中間啟用、KV 快取緩衝區(序列長度 2048、批次大小 8 時 >5GB)、CUDA 上下文等需要足夠的空閒記憶體。Instinct MI250 GPU 具有 128 GB 全域性記憶體,而 A100 具有 80GB,這解釋了 MI250 能夠執行更大工作負載(更長序列、更大批次)的原因。
Text Generation Inference 已準備就緒,可透過 docker 映象 `ghcr.io/huggingface/text-generation-inference:1.2-rocm` 在 AMD Instinct GPU 上部署到生產環境。請務必參閱文件,瞭解支援及其限制。
接下來是什麼?
我們希望這篇博文能像我們 Hugging Face 一樣,讓你對與 AMD 的合作感到興奮。當然,這僅僅是我們旅程的開始,我們期待在更多 AMD 硬體上實現更多用例。
在接下來的幾個月裡,我們將致力於為 AMD Radeon GPU 帶來更多支援和驗證,這些 GPU 可以用於你的桌上型電腦進行本地使用,從而降低了可訪問性障礙,併為我們的使用者帶來了更大的多功能性。
當然,我們很快就會為 MI300 系列產品進行效能最佳化,確保開源和解決方案都能以我們在 Hugging Face 一直追求的最高穩定水平提供最新的創新。
我們的另一個重點領域將是 AMD Ryzen AI 技術,該技術為最新一代 AMD 筆記本 CPU 提供動力,允許在邊緣裝置上執行 AI。在編碼助手、影像生成工具和個人助手越來越廣泛可用的時代,提供能夠滿足隱私需求以利用這些強大工具的解決方案至關重要。在這種背景下,Ryzen AI 相容模型已在 Hugging Face Hub 上可用,我們正在與 AMD 密切合作,在未來幾個月內帶來更多模型。