使用 🤗 資料集進行影像搜尋





🤗
datasets 是一個讓訪問和共享資料集變得容易的庫。它還使得高效處理資料變得容易——包括處理不適合記憶體的資料。
當 datasets 首次釋出時,它主要與文字資料相關聯。然而,最近,datasets 增加了對音訊和影像的支援。特別是,現在有一個 datasets 影像特徵型別。之前的一篇部落格文章展示瞭如何將 datasets 與 🤗 transformers 結合使用來訓練影像分類模型。在這篇部落格文章中,我們將看到如何結合 datasets 和其他幾個庫來建立影像搜尋應用程式。
首先,我們將安裝 datasets。由於我們將處理影像,我們還將安裝 pillow。我們還需要 sentence_transformers 和 faiss。我們將在下面更詳細地介紹它們。我們還安裝了 rich——我們在這裡只會簡要使用它,但它是一個非常有用的軟體包,我真的建議進一步探索它!
!pip install datasets pillow rich faiss-gpu sentence_transformers
首先,讓我們看看影像特徵。我們可以使用出色的 rich 庫來檢視 Python 物件(函式、類等)。
from rich import inspect
import datasets
inspect(datasets.Image, help=True)
╭───────────────────────── <class 'datasets.features.image.Image'> ─────────────────────────╮ │ class Image(decode: bool = True, id: Union[str, NoneType] = None) -> None: │ │ │ │ Image feature to read image data from an image file. │ │ │ │ Input: The Image feature accepts as input: │ │ - A :obj:`str`: Absolute path to the image file (i.e. random access is allowed). │ │ - A :obj:`dict` with the keys: │ │ │ │ - path: String with relative path of the image file to the archive file. │ │ - bytes: Bytes of the image file. │ │ │ │ This is useful for archived files with sequential access. │ │ │ │ - An :obj:`np.ndarray`: NumPy array representing an image. │ │ - A :obj:`PIL.Image.Image`: PIL image object. │ │ │ │ Args: │ │ decode (:obj:`bool`, default ``True``): Whether to decode the image data. If `False`, │ │ returns the underlying dictionary in the format {"path": image_path, "bytes": │ │ image_bytes}. │ │ │ │ decode = True │ │ dtype = 'PIL.Image.Image' │ │ id = None │ │ pa_type = StructType(struct<bytes: binary, path: string>) │ ╰───────────────────────────────────────────────────────────────────────────────────────────╯
我們可以看到有幾種不同的方式可以傳入影像。我們稍後會再討論這個問題。
datasets 庫的一個非常好的功能(除了資料處理、記憶體對映等功能之外)是您可以“免費”獲得一些不錯的東西。其中之一是能夠將 faiss 索引新增到資料集中。faiss 是一個“用於密集向量高效相似性搜尋和聚類的庫”。
datasets 文件展示了一個使用 faiss 索引進行文字檢索的示例。在這篇文章中,我們將看看我們是否可以對影像做同樣的事情。
資料集:“數字化書籍——被識別為裝飾的影像。約 1510 年 - 約 1900 年”
這是一個影像資料集,這些影像是從大英圖書館數字化書籍集合中提取出來的。這些影像來自不同時期和廣泛領域的書籍。影像是利用每本書的 OCR 輸出中包含的資訊提取的。因此,可以知道影像來自哪本書,但不一定知道影像中顯示了什麼。
為幫助克服這一問題,一些嘗試包括將影像上傳到 Flickr。這使得人們可以對影像進行標記或將其分類到不同的類別中。
還有一些專案使用機器學習對資料集進行標記。這項工作使得按標籤搜尋成為可能,但我們可能希望獲得更“豐富”的搜尋能力。對於這個特定的實驗,我們將使用包含“裝飾”的集合的一個子集。這個資料集稍微小一些,所以更適合進行實驗。我們可以從大英圖書館的資料儲存庫獲取完整資料:https://doi.org/10.21250/db17。由於完整資料集仍然相當大,您可能需要從一個較小的樣本開始。
建立我們的資料集
我們的資料集包含一個資料夾,其中包含子目錄,子目錄中是影像。這是一種相當標準的影像資料集共享格式。得益於最近合併的拉取請求,我們可以直接使用 datasets 的 ImageFolder 載入器載入此資料集 🤯
from datasets import load_dataset
dataset = load_dataset("imagefolder", data_files="https://zenodo.org/record/6224034/files/embellishments_sample.zip?download=1")
讓我們看看我們得到了什麼。
dataset
DatasetDict({
train: Dataset({
features: ['image', 'label'],
num_rows: 10000
})
})
我們可以得到一個 DatasetDict,我們有一個帶有影像和標籤特徵的資料集。由於這裡沒有訓練/驗證拆分,我們來獲取資料集的訓練部分。我們再來看看資料集中的一個示例,看看它長什麼樣。
dataset = dataset["train"]
dataset[0]
{'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=358x461 at 0x7F9488DBB090>,
'label': 208}
讓我們從標籤列開始。它包含影像的父資料夾。在這種情況下,標籤列代表了影像所取書籍的出版年份。我們可以使用 dataset.features 檢視其對映。
dataset.features['label']
在這個特定的資料集中,影像檔名也包含了一些關於影像來源書籍的元資料。有幾種方法可以獲取這些資訊。
當我們檢視資料集中的一個示例時,image 特徵是一個 PIL.JpegImagePlugin.JpegImageFile。由於 PIL.Images 具有檔名屬性,因此獲取檔名的一種方法是訪問它。
dataset[0]['image'].filename
/root/.cache/huggingface/datasets/downloads/extracted/f324a87ed7bf3a6b83b8a353096fbd9500d6e7956e55c3d96d2b23cc03146582/embellishments_sample/1920/000499442_0_000579_1_[The Ring and the Book etc ]_1920.jpg
因為我們可能希望稍後輕鬆訪問此資訊,所以讓我們建立一個新列來提取檔名。為此,我們將使用 map 方法。
dataset = dataset.map(lambda example: {"fname": example['image'].filename.split("/")[-1]})
現在我們可以看一個例子,看看它是什麼樣子。
dataset[0]
{'fname': '000499442_0_000579_1_[The Ring and the Book etc ]_1920.jpg',
'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=358x461 at 0x7F94862A9650>,
'label': 208}
我們現在已經獲取了元資料。我們來看看一些圖片吧!如果訪問一個示例並索引到 image 列中,我們將看到我們的圖片 😃
dataset[10]['image']

注意:在這篇博文的早期版本中,下載和載入影像的步驟要複雜得多。新的 ImageFolder 載入器使這個過程變得容易得多 😀 特別是,我們不再需要擔心如何載入影像,因為資料集已經為我們處理了這一點。
將所有內容推送到中心!

🤗 生態系統中最棒的事情之一是 Hugging Face Hub。我們可以使用 Hub 來訪問模型和資料集。它通常用於與他人共享工作,但它也可以作為進行中工作的有用工具。datasets 最近添加了一個 push_to_hub 方法,允許您以最小的麻煩將資料集推送到 Hub。這可以透過讓您傳遞一個已經完成所有轉換等的資料集來提供很大幫助。
目前,我們將把資料集推送到 Hub,並暫時保持私有。
根據您執行程式碼的位置,您可能需要進行身份驗證。您可以使用 huggingface-cli login 命令進行身份驗證,或者,如果您在筆記本中執行,則使用 notebook_login。
from huggingface_hub import notebook_login
notebook_login()
dataset.push_to_hub('davanstrien/embellishments-sample', private=True)
注意:在這篇部落格文章的早期版本中,我們必須做更多步驟來確保在使用
push_to_hub時嵌入影像。得益於這個拉取請求,我們不再需要擔心這些額外的步驟。我們只需要確保embed_external_files=True(這是預設行為)。
切換機器
至此,我們已經建立了一個數據集並將其移動到 Hub。這意味著可以在其他地方繼續工作/使用資料集。
在這個特定的例子中,訪問 GPU 很重要。使用 Hub 作為傳遞資料的方式,我們可以在筆記型電腦上開始工作,然後在 Google Colab 上繼續工作。
如果我們將程式碼轉移到新機器上,我們可能需要重新登入。登入後,我們就可以載入資料集了。
from datasets import load_dataset
dataset = load_dataset("davanstrien/embellishments-sample", use_auth_token=True)
建立嵌入 🕸
我們現在有了一個包含大量影像的資料集。為了開始建立我們的影像搜尋應用程式,我們需要嵌入這些影像。有多種方法可以嘗試這樣做,但一種可能的方法是使用 sentence_transformers 庫透過 CLIP 模型。OpenAI 的 CLIP 模型學習影像和文字的聯合表示,這對於我們想要做的事情非常有用,因為我們想要輸入文字並獲得影像。
我們可以使用 SentenceTransformer 類下載模型。
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('clip-ViT-B-32')
該模型將以影像或文字作為輸入,並返回一個嵌入。我們可以使用 datasets 的 map 方法來使用該模型編碼所有影像。當我們呼叫 map 時,我們返回一個字典,其中鍵 embeddings 包含模型返回的嵌入。我們還在呼叫模型時傳遞 device='cuda';這確保我們在 GPU 上進行編碼。
ds_with_embeddings = dataset.map(
lambda example: {'embeddings':model.encode(example['image'], device='cuda')}, batched=True, batch_size=32)
我們可以透過使用 push_to_hub 推送回 Hub 來“儲存”我們的工作。
ds_with_embeddings.push_to_hub('davanstrien/embellishments-sample', private=True)
如果我們將程式碼遷移到不同的機器上,我們可以透過從 Hub 載入來重新獲取我們的工作 😃
from datasets import load_dataset
ds_with_embeddings = load_dataset("davanstrien/embellishments-sample", use_auth_token=True)
我們現在有一個新列,其中包含影像的嵌入。我們可以手動搜尋這些並將其與一些輸入嵌入進行比較,但資料集有一個 add_faiss_index 方法。它使用 faiss 庫來建立用於搜尋嵌入的高效索引。有關此庫的更多背景資訊,您可以觀看此 YouTube 影片。
ds_with_embeddings['train'].add_faiss_index(column='embeddings')
Dataset({
features: ['fname', 'year', 'path', 'image', 'embeddings'],
num_rows: 10000
})
影像搜尋
注意:這些示例是根據完整版資料集生成的,因此您可能會得到略微不同的結果。
我們現在擁有一切所需,可以建立一個簡單的影像搜尋。我們可以使用編碼影像的相同模型來編碼一些輸入文字。這將作為我們嘗試尋找相似示例的提示。讓我們從“蒸汽機”開始。
prompt = model.encode("A steam engine")
我們可以使用資料集庫中的另一個方法 get_nearest_examples 來獲取與我們輸入提示嵌入相似的影像。我們可以傳入我們想要返回的結果數量。
scores, retrieved_examples = ds_with_embeddings['train'].get_nearest_examples('embeddings', prompt, k=9)
我們可以索引到它檢索的第一個示例
retrieved_examples['image'][0]

這不太像蒸汽機,但也不是完全奇怪的結果。我們可以繪製其他結果,看看返回了什麼。
import matplotlib.pyplot as plt
plt.figure(figsize=(20, 20))
columns = 3
for i in range(9):
image = retrieved_examples['image'][i]
plt.subplot(9 / columns + 1, columns, i + 1)
plt.imshow(image)

其中一些結果看起來與我們的輸入提示相當接近。我們可以將其封裝在一個函式中,以便更輕鬆地嘗試不同的提示。
def get_image_from_text(text_prompt, number_to_retrieve=9):
prompt = model.encode(text_prompt)
scores, retrieved_examples = ds_with_embeddings['train'].get_nearest_examples('embeddings', prompt, k=number_to_retrieve)
plt.figure(figsize=(20, 20))
columns = 3
for i in range(9):
image = retrieved_examples['image'][i]
plt.title(text_prompt)
plt.subplot(9 / columns + 1, columns, i + 1)
plt.imshow(image)
get_image_from_text("An illustration of the sun behind a mountain")

嘗試一堆提示 ✨
現在我們有了一個獲取一些結果的函式,我們可以嘗試各種不同的提示。
其中一些我會選擇寬泛的“類別”提示,例如“樂器”或“動物”,而另一些則是具體的,例如“吉他”。
出於興趣,我還嘗試了一個布林運算子:“貓或狗的插圖”。
最後我嘗試了一些更抽象的東西:“一個空虛的深淵”
prompts = ["A musical instrument", "A guitar", "An animal", "An illustration of a cat or a dog", "an empty abyss"]
for prompt in prompts:
get_image_from_text(prompt)




我們可以看到這些結果並非總是正確的,但通常是合理的。這似乎已經對在該資料集中搜索影像的語義內容有用。然而,我們可能暫時不會按原樣分享它……
建立 Hugging Face Space?🤷🏼
這種專案下一步顯而易見的行動是建立一個 Hugging Face Space 演示。我已經在其他模型上這樣做了。
從我們目前所達到的階段開始,設定一個 Gradio 應用程式是一個相當簡單的過程。這是該應用程式的螢幕截圖。
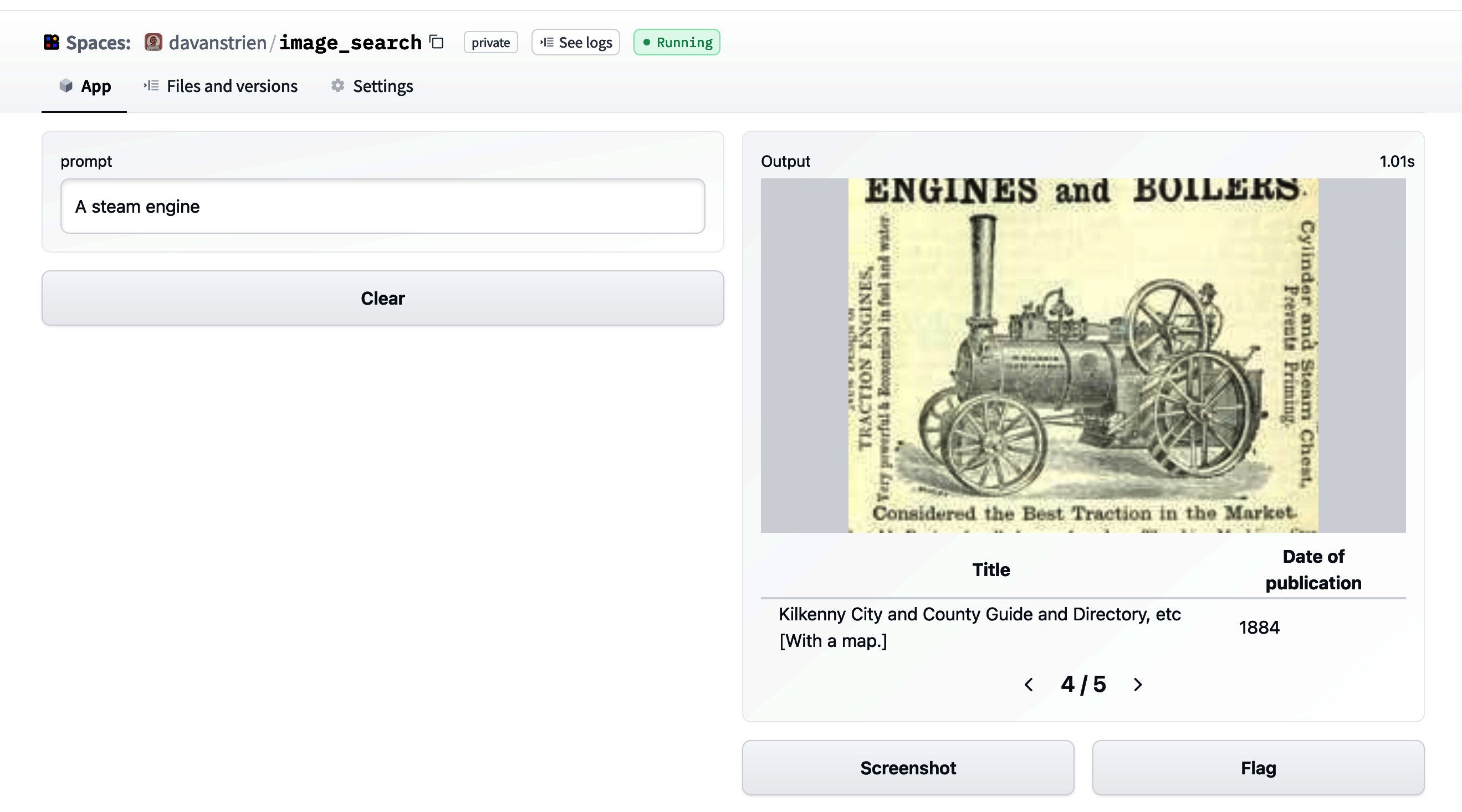
然而,我對立即公開它有點猶豫。檢視 CLIP 模型的模型卡,我們可以瞭解其主要預期用途。
主要預期用途
我們主要設想該模型將由研究人員使用,以便更好地瞭解計算機視覺模型的魯棒性、泛化能力以及其他功能、偏見和限制。來源
這與我們在此感興趣的內容相當接近。特別是,我們可能對模型如何處理我們資料集中的影像(主要是 19 世紀書籍中的插圖)感興趣。我們資料集中的影像與訓練資料(可能)大相徑庭。一些影像也包含文字的事實可能對 CLIP 有幫助,因為它顯示出一定的OCR 能力。
然而,檢視模型卡中超出範圍的用例
超出範圍的用例
該模型的任何部署用例——無論是商業的還是非商業的——目前都超出了範圍。非部署用例,例如在受限環境中的影像搜尋,也不建議使用,除非對具有特定固定類分類法的模型進行徹底的域內測試。這是因為我們的安全評估表明,由於 CLIP 效能隨不同類分類法的變化而變化,因此對任務特定測試的需求很高。這使得未經測試和不受限制地部署該模型在任何用例中目前都可能有害。> 來源
這表明“部署”不是一個好主意。雖然我得到的結果很有趣,但我還沒有對模型進行足夠的測試(也沒有進行更系統的評估以瞭解其效能和偏差),因此對“部署”它沒有信心。另一個額外的考慮是目標資料集本身。影像取自涵蓋各種主題和時間段的書籍。有大量書籍代表殖民態度,因此其中包含的一些影像可能會以負面方式代表某些人群。這可能與允許任意文字輸入編碼為提示的工具結合起來造成不良後果。
也許有辦法解決這個問題,但這需要更多的思考。
結論
儘管我們沒有一個漂亮的演示來展示,但我們已經看到了如何使用 datasets 來
- 將影像載入到新的
Image特徵型別中 - 使用
push_to_hub“儲存”我們的工作,並用它在機器/會話之間移動資料 - 為影像建立
faiss索引,我們可以用它從文字(或影像)輸入中檢索影像。

