使用英特爾 Sapphire Rapids 加速 PyTorch Transformer 模型,第二部分

在最近的一篇文章中,我們向您介紹了英特爾第四代至強 CPU,代號Sapphire Rapids,及其新的高階矩陣擴充套件 (AMX) 指令集。我們展示瞭如何結合在 Amazon EC2 上執行的 Sapphire Rapids 伺服器叢集和英特爾庫(如適用於 PyTorch 的英特爾擴充套件)來高效地大規模執行分散式訓練,與上一代至強處理器 (Ice Lake) 相比,速度提升了 8 倍,並實現了近乎線性的擴充套件。
在這篇文章中,我們將重點關注推理。我們將使用 PyTorch 實現的流行 Hugging Face Transformer 模型,首先測量它們在 Ice Lake 伺服器上針對短和長 NLP 序列的效能。然後,我們將在 Sapphire Rapids 伺服器和最新版本的 Hugging Face Optimum Intel(一個專用於英特爾平臺硬體加速的開源庫)上做同樣的事情。
我們開始吧!
為什麼應該考慮基於 CPU 的推理
在決定是在 CPU 還是 GPU 上執行深度學習推理時,需要考慮幾個因素。最重要的因素無疑是模型的大小。一般來說,較大的模型可能從 GPU 提供的額外計算能力中獲益更多,而較小的模型可以在 CPU 上高效執行。
需要考慮的另一個因素是模型和推理任務中的並行度。GPU 旨在擅長大規模並行處理,因此它們對於可以有效並行化的任務可能更高效。另一方面,如果模型或推理任務沒有很高的並行度,CPU 可能是更有效的選擇。
成本也是一個重要的考慮因素。GPU 可能很昂貴,而使用 CPU 可能是一個更具成本效益的選擇,特別是如果您的業務用例不需要極低的延遲。此外,如果您需要輕鬆擴充套件或縮小推理工作器數量的能力,或者您需要在各種硬體上執行推理,使用 CPU 可能是一個更靈活的選擇。
現在,讓我們設定我們的測試伺服器。
設定我們的測試伺服器
就像上一篇文章一樣,我們將使用 Amazon EC2 例項:
- 一個基於 Ice Lake 架構的
c6i.16xlarge例項, - 一個基於 Sapphire Rapids 架構的
r7iz.16xlarge-metal例項。您可以在 AWS 網站上閱讀更多關於新 r7iz 系列的資訊。
兩個例項都有 32 個物理核心(因此有 64 個 vCPU)。我們將以相同的方式設定它們:
- Ubuntu 22.04,核心版本 Linux 5.15.0 (
ami-0574da719dca65348), - PyTorch 1.13,帶有 Intel Extension for PyTorch 1.13,
- Transformers 4.25.1。
唯一的區別是 r7iz 例項上會額外新增 Optimum Intel Library。
以下是設定步驟。像往常一樣,我們建議使用虛擬環境來保持整潔。
sudo apt-get update
# Add libtcmalloc for extra performance
sudo apt install libgoogle-perftools-dev -y
export LD_PRELOAD="/usr/lib/x86_64-linux-gnu/libtcmalloc.so"
sudo apt-get install python3-pip -y
pip install pip --upgrade
export PATH=/home/ubuntu/.local/bin:$PATH
pip install virtualenv
virtualenv inference_env
source inference_env/bin/activate
pip3 install torch==1.13.0 -f https://download.pytorch.org/whl/cpu
pip3 install intel_extension_for_pytorch==1.13.0 -f https://developer.intel.com/ipex-whl-stable-cpu
pip3 install transformers
# Only needed on the r7iz instance
pip3 install optimum[intel]
在兩臺例項上完成這些步驟後,我們就可以開始執行測試了。
基準測試流行的自然語言處理模型
在此示例中,我們將在文字分類任務上對幾個 NLP 模型進行基準測試:distilbert-base-uncased、bert-base-uncased 和roberta-base。您可以在 Github 上找到完整指令碼。請隨意使用您的模型進行嘗試!
models = ["distilbert-base-uncased", "bert-base-uncased", "roberta-base"]
使用 16-token 和 128-token 兩種長度的句子,我們將測量單次推理和批處理推理的平均預測延遲和 p99 預測延遲。這應該能讓我們很好地瞭解在實際場景中可以預期的速度提升。
sentence_short = "This is a really nice pair of shoes, I am completely satisfied with my purchase"
sentence_short_array = [sentence_short] * 8
sentence_long = "These Adidas Lite Racer shoes hit a nice sweet spot for comfort shoes. Despite being a little snug in the toe box, these are very comfortable to wear and provide nice support while wearing. I would stop short of saying they are good running shoes or cross-trainers because they simply lack the ankle and arch support most would desire in those type of shoes and the treads wear fairly quickly, but they are definitely comfortable. I actually walked around Disney World all day in these without issue if that is any reference. Bottom line, I use these as the shoes they are best; versatile, inexpensive, and comfortable, without expecting the performance of a high-end athletic sneaker or expecting the comfort of my favorite pair of slippers."
sentence_long_array = [sentence_long] * 8
基準測試函式非常簡單。經過幾次預熱迭代後,我們使用 pipeline API 執行 1,000 次預測,儲存預測時間,並計算它們的平均值和 p99 值。
import time
import numpy as np
def benchmark(pipeline, data, iterations=1000):
# Warmup
for i in range(100):
result = pipeline(data)
times = []
for i in range(iterations):
tick = time.time()
result = pipeline(data)
tock = time.time()
times.append(tock - tick)
return "{:.2f}".format(np.mean(times) * 1000), "{:.2f}".format(
np.percentile(times, 99) * 1000
)
在 c6i (Ice Lake) 例項上,我們只使用普通的 Transformers pipeline。
from transformers import pipeline
for model in models:
print(f"Benchmarking {model}")
pipe = pipeline("sentiment-analysis", model=model)
result = benchmark(pipe, sentence_short)
print(f"Transformers pipeline, short sentence: {result}")
result = benchmark(pipe, sentence_long)
print(f"Transformers pipeline, long sentence: {result}")
result = benchmark(pipe, sentence_short_array)
print(f"Transformers pipeline, short sentence array: {result}")
result = benchmark(pipe, sentence_long_array)
print(f"Transformers pipeline, long sentence array: {result}")
在 r7iz (Sapphire Rapids) 例項上,我們同時使用普通 pipeline 和 Optimum pipeline。在 Optimum pipeline 中,我們啟用 bfloat16 模式以利用 AMX 指令。我們還將 jit 設定為 True,以透過即時編譯進一步最佳化模型。
import torch
from optimum.intel import inference_mode
with inference_mode(pipe, dtype=torch.bfloat16, jit=True) as opt_pipe:
result = benchmark(opt_pipe, sentence_short)
print(f"Optimum pipeline, short sentence: {result}")
result = benchmark(opt_pipe, sentence_long)
print(f"Optimum pipeline, long sentence: {result}")
result = benchmark(opt_pipe, sentence_short_array)
print(f"Optimum pipeline, short sentence array: {result}")
result = benchmark(opt_pipe, sentence_long_array)
print(f"Optimum pipeline, long sentence array: {result}")
為簡潔起見,我們只檢視 distilbert-base-uncased 的 p99 結果。所有時間均以毫秒為單位。您可以在文章末尾找到完整結果。
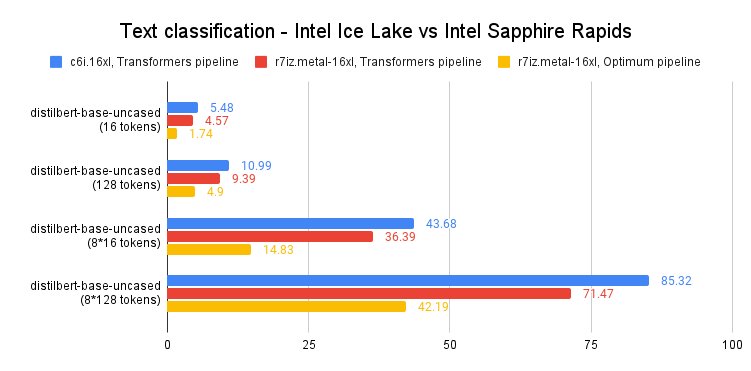
如上圖所示,單次預測執行速度比上一代至強 CPU 快 60-65%。換句話說,得益於 Intel Sapphire Rapids 和 Hugging Face Optimum 的結合,您只需對程式碼進行微小的更改,即可將預測速度提升 3 倍。
這讓您即使使用長文字序列,也能實現個位數預測延遲,這在以前只有 GPU 才能做到。
結論
第四代英特爾至強 CPU 提供了出色的推理效能,特別是與 Hugging Face Optimum 結合使用時。這是使深度學習更易於訪問和更具成本效益的又一步,我們期待與英特爾的朋友們繼續這項工作。
以下是一些可幫助您入門的額外資源:
- Intel IPEX 在 GitHub 上
- GitHub 上的 Hugging Face Optimum
如果您有任何問題或反饋,我們非常樂意在 Hugging Face 論壇上閱讀。
感謝閱讀!
附錄:完整結果
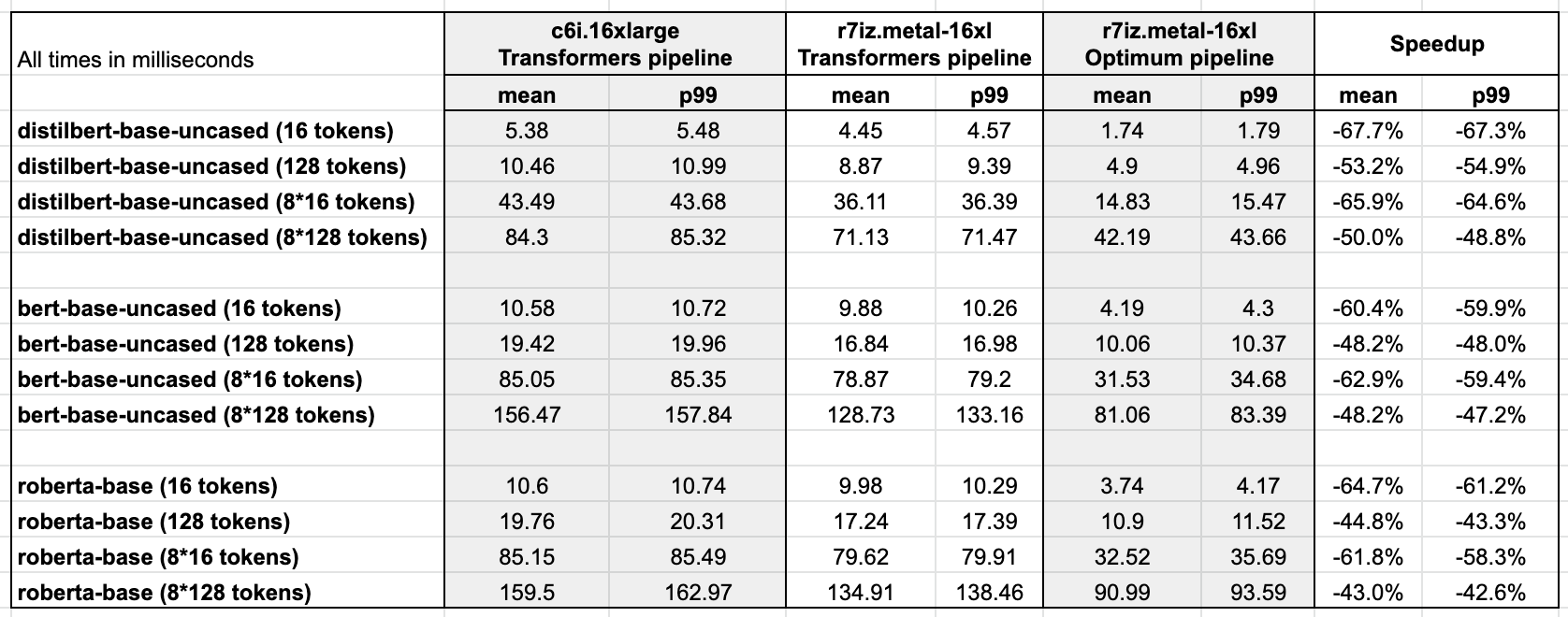
Ubuntu 22.04,帶 libtcmalloc,已打補丁支援 Intel AMX 的 Linux 5.15.0,PyTorch 1.13,帶 Intel Extension for PyTorch,Transformers 4.25.1,Optimum 1.6.1,Optimum Intel 1.7.0.dev0