介紹 LiveCodeBench 排行榜——對程式碼大型語言模型進行全面且無汙染的評估













我們很高興推出基於 LiveCodeBench 的 LiveCodeBench 排行榜,LiveCodeBench 是加州大學伯克利分校、麻省理工學院和康奈爾大學的研究人員開發的新基準,用於衡量大型語言模型的程式碼生成能力。
LiveCodeBench 從各種程式設計競賽平臺收集程式設計問題,並標註問題的釋出日期。標註用於評估模型在不同時間視窗釋出的題集上的表現,從而採用“隨時間評估”策略,有助於檢測和防止汙染。除了常見的程式碼生成任務外,LiveCodeBench 還評估自修復、測試輸出預測和程式碼執行,從而為下一代 AI 程式設計代理所需的程式設計能力提供更全面的視角。
LiveCodeBench 場景與評估
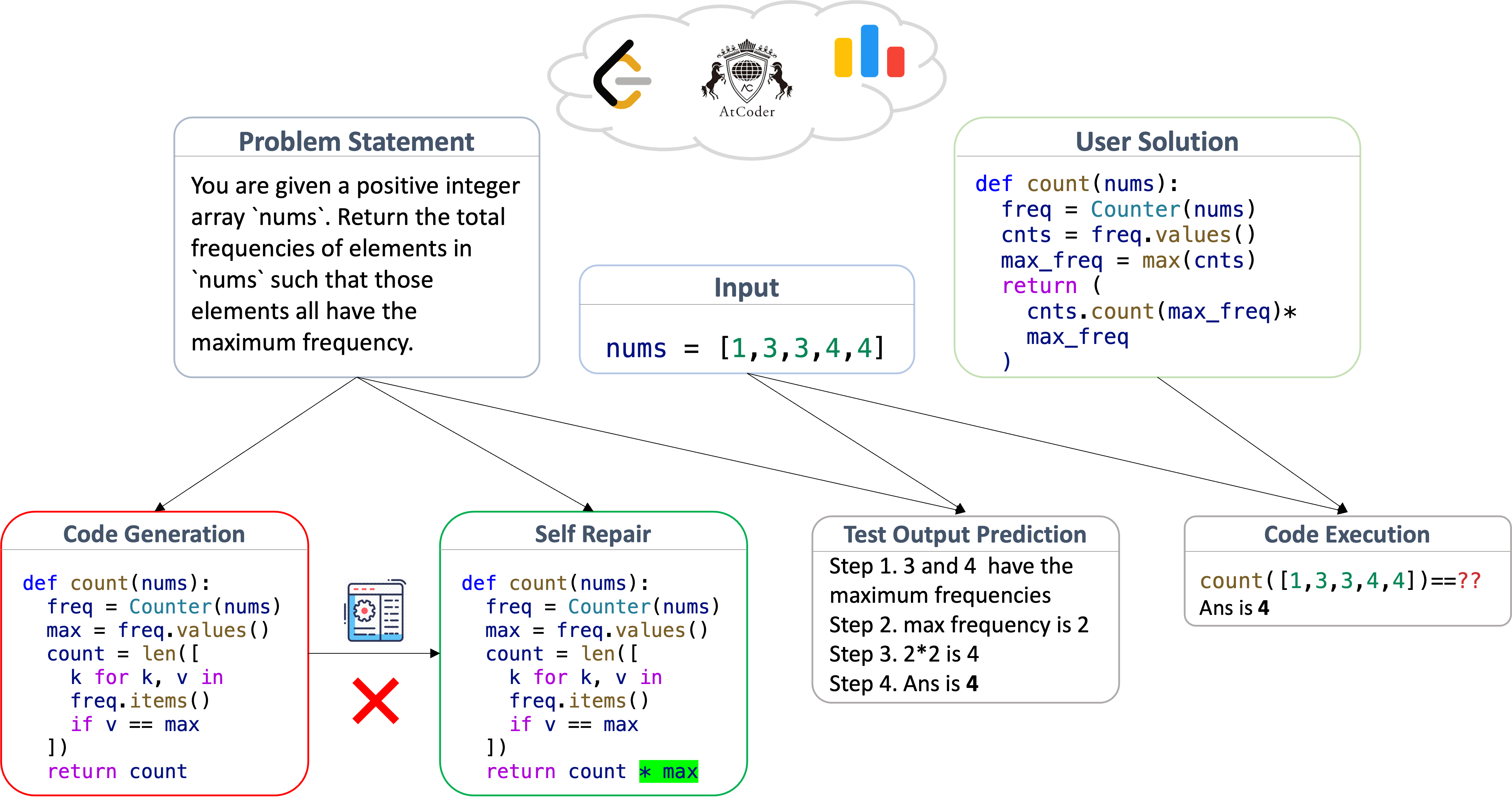
LiveCodeBench 問題來源於程式設計競賽平臺:LeetCode、AtCoder 和 CodeForces。這些網站定期舉辦競賽,其中包含評估參與者程式設計和解決問題能力的問題。問題包括自然語言的問題描述以及輸入-輸出示例,目標是編寫一個能夠透過一組隱藏測試的程式。成千上萬的參與者參加這些競賽,這確保了問題的清晰度和正確性都經過驗證。
LiveCodeBench 使用收集到的問題構建其四個程式設計場景
- 程式碼生成。模型被給定一個問題描述,包括自然語言描述和示例測試(輸入-輸出對),並被要求生成一個正確的解決方案。評估基於生成程式碼的功能正確性,這透過一組測試用例來確定。
- 自修復。模型被給定一個問題描述並生成一個候選程式,類似於上述程式碼生成場景。如果出現錯誤,模型將獲得錯誤反饋(異常訊息或失敗的測試用例),並被要求生成修復。評估使用與上述相同的功能正確性標準進行。
- 程式碼執行。模型被提供一個包含函式 (f) 和測試輸入的程式片段,並被要求預測程式在輸入測試用例上的輸出。評估基於執行的正確性指標:如果斷言
assert f(input) == generated_output透過,則認為模型的輸出是正確的。 - 測試輸出預測。模型被給定問題描述和測試用例輸入,並被要求生成輸入的預期輸出。測試僅根據問題描述生成,無需函式實現,輸出使用精確匹配檢查器進行評估。
對於每個場景,評估都使用 Pass@1 指標進行。該指標捕獲生成正確答案的機率,並根據正確答案的數量與總嘗試次數的比率計算,即 Pass@1 = total_correct / total_attempts。
防止基準汙染
汙染是當前 LLM 評估中的主要瓶頸之一。即使在 LLM 編碼評估中,也已有證據表明 HumanEval 等標準基準存在汙染和過擬合的報告([1] 和 [2])。
因此,我們在 LiveCodeBench 中標註了問題的釋出日期:這樣,對於訓練截止日期為 D 的新模型,我們可以在 D 之後釋出的問題上計算分數,以衡量它們在未見問題上的泛化能力。
LiveCodeBench 透過“隨時間滾動”功能將其形式化,該功能允許您選擇特定時間視窗內的問題。您可以在上面的排行榜中嘗試一下!
發現
我們發現
- 雖然模型效能在不同場景中存在相關性,但在我們使用的 4 個場景中,相對效能和排名可能有所不同
GPT-4-Turbo在大多數場景中表現最佳。此外,它在自修復任務上的優勢更大,這突出了其接受編譯器反饋的能力。Claude-3-Opus在測試輸出預測場景中超越了GPT-4-Turbo,這突出了其更強的自然語言推理能力。Mistral-Large在測試輸出預測和程式碼執行等自然語言推理任務中表現更好。

如何提交?
要評估您的程式碼模型在 LiveCodeBench 上的表現,您可以遵循以下步驟:
- 環境設定:您可以使用 conda 建立一個新環境,並安裝 LiveCodeBench
git clone https://github.com/LiveCodeBench/LiveCodeBench.git
cd LiveCodeBench
pip install poetry
poetry install
- 要評估新的 Hugging Face 模型,您可以輕鬆地使用以下方式進行評估:
python -m lcb_runner.runner.main --model {model_name} --scenario {scenario_name}
針對不同的場景。對於新的模型家族,我們實現了一個可擴充套件的框架,您可以透過修改 lcb_runner/lm_styles.py 和 lcb_runner/prompts 來支援新的模型,具體說明請參閱 github README。
- 生成結果後,您可以透過填寫 此表單 進行提交。
如何貢獻
最後,我們正在為 LiveCodeBench 尋找合作者和建議。資料集和程式碼都已線上提供,因此請透過提交問題或傳送電子郵件至 naman_jain@berkeley.edu 與我們聯絡。






