如何使用 Megatron-LM 訓練語言模型







在 PyTorch 中訓練大型語言模型需要的不僅僅是一個簡單的訓練迴圈。它通常分佈在多個裝置上,並採用許多最佳化技術以實現穩定高效的訓練。Hugging Face 🤗 Accelerate 庫旨在支援跨 GPU 和 TPU 的分散式訓練,並可非常輕鬆地整合到訓練迴圈中。🤗 Transformers 也透過 Trainer API 支援分散式訓練,該 API 在 PyTorch 中提供功能完整的訓練,甚至無需實現訓練迴圈。
研究人員預訓練大型 Transformer 模型的另一個常用工具是 Megatron-LM,這是一個由 NVIDIA 深度學習應用研究團隊開發的強大框架。與 `accelerate` 和 `Trainer` 不同,使用 Megatron-LM 不那麼直接,對初學者來說可能有點不知所措。但它針對 GPU 訓練進行了高度最佳化,可以提供一些加速。在這篇部落格文章中,您將學習如何使用 Megatron-LM 在 NVIDIA GPU 上訓練語言模型,並將其與 `transformers` 一起使用。
我們將嘗試分解此框架中訓練 GPT2 模型的不同步驟,包括:
- 環境設定
- 資料預處理
- 訓練
- 模型轉換為 🤗 Transformers
為什麼選擇 Megatron-LM?
在深入訓練細節之前,我們首先了解是什麼讓這個框架比其他框架更高效。本節受這篇關於使用 Megatron-DeepSpeed 訓練 BLOOM 的精彩部落格啟發,請參閱該部落格瞭解更多詳細資訊,因為這篇部落格旨在對 Megatron-LM 進行溫和的介紹。
資料載入器 (DataLoader)
Megatron-LM 配備了一個高效的 DataLoader,其中資料在訓練前被標記化和打亂。它還將資料分割成帶索引的編號序列,這些索引被儲存起來,這樣只需計算一次。為了構建索引,根據訓練引數計算 epoch 數量,然後建立並打亂排序。這與大多數情況下我們遍歷整個資料集直到耗盡,然後再重複第二個 epoch 的方式不同。這可以平滑學習曲線並在訓練期間節省時間。
融合 CUDA 核心 (Fused CUDA Kernels)
當在 GPU 上執行計算時,所需資料從記憶體中獲取,然後執行計算,結果再儲存回記憶體。簡單來說,融合核心的思想是,通常由 PyTorch 單獨執行的相似操作被組合成一個單一的硬體操作。因此,透過將多個離散計算合併為一個,它們減少了記憶體移動的次數。下圖說明了核心融合的思想。它受到這篇論文的啟發,該論文詳細討論了這一概念。
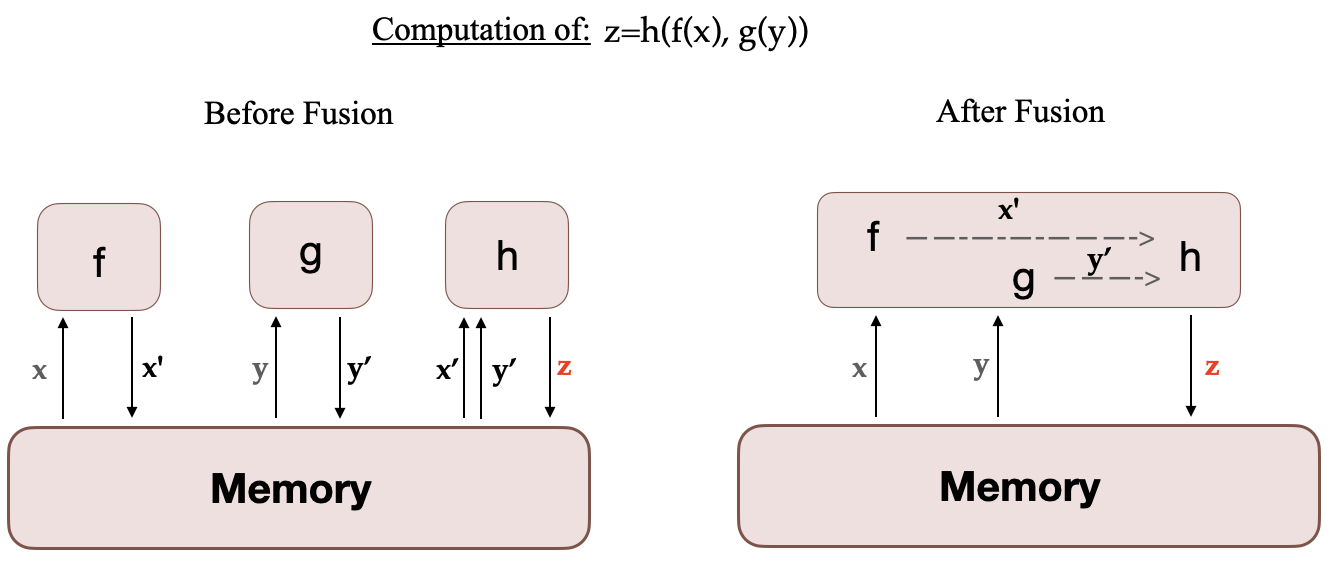
當 f、g 和 h 融合在一個核心中時,f 和 g 的中間結果 x' 和 y' 儲存在 GPU 暫存器中,並立即被 h 使用。但如果沒有融合,x' 和 y' 將需要複製到記憶體中,然後由 h 載入。因此,核心融合可以顯著加速計算。Megatron-LM 還使用了來自 Apex 的 AdamW 融合實現,它比 PyTorch 實現更快。
雖然可以像 Megatron-LM 那樣定製 DataLoader,並使用 Apex 的融合最佳化器與 `transformers`,但構建自定義的融合 CUDA 核心對於初學者來說並不友好。
現在您已經熟悉了這個框架以及它為什麼具有優勢,讓我們深入瞭解訓練細節!
如何使用 Megatron-LM 進行訓練?
設定
設定環境最簡單的方法是從 NGC 拉取一個預裝所有必要元件的 NVIDIA PyTorch 容器。更多詳情請參閱文件。如果您不想使用此容器,則需要安裝最新的 PyTorch、CUDA、NCCL 和 NVIDIA APEX 版本以及 `nltk` 庫。
安裝 Docker 後,您可以使用以下命令執行容器(`xx.xx` 表示您的 Docker 版本),然後在其內部克隆 Megatron-LM 倉庫
docker run --gpus all -it --rm nvcr.io/nvidia/pytorch:xx.xx-py3
git clone https://github.com/NVIDIA/Megatron-LM
您還需要將 tokenizer 的詞彙檔案 `vocab.json` 和合並表 `merges.txt` 新增到容器的 Megatron-LM 資料夾中。這些檔案可以在模型的儲存庫中與權重一起找到,請參閱 GPT2 的此儲存庫。您也可以使用 `transformers` 訓練自己的 tokenizer。您可以檢視 CodeParrot 專案以獲取實際示例。現在,如果您想將這些資料從容器外部複製到容器內部,可以使用以下命令:
sudo docker cp vocab.json CONTAINER_ID:/workspace/Megatron-LM
sudo docker cp merges.txt CONTAINER_ID:/workspace/Megatron-LM
資料預處理
在本教程的其餘部分,我們將使用 CodeParrot 模型和資料作為示例。
訓練資料需要一些預處理。首先,您需要將其轉換為鬆散的 JSON 格式,每行一個 JSON 包含一個文字樣本。如果您使用的是 🤗 Datasets,下面是如何操作的示例(始終在 Megatron-LM 資料夾內部)
from datasets import load_dataset
train_data = load_dataset('codeparrot/codeparrot-clean-train', split='train')
train_data.to_json("codeparrot_data.json", lines=True)
然後使用以下命令將資料進行標記化、打亂並處理成二進位制格式以進行訓練:
#if nltk isn't installed
pip install nltk
python tools/preprocess_data.py \
--input codeparrot_data.json \
--output-prefix codeparrot \
--vocab vocab.json \
--dataset-impl mmap \
--tokenizer-type GPT2BPETokenizer \
--merge-file merges.txt \
--json-keys content \
--workers 32 \
--chunk-size 25 \
--append-eod
`workers` 和 `chunk_size` 選項分別指預處理中使用的 worker 數量以及分配給每個 worker 的資料塊大小。`dataset-impl` 指的是索引資料集的實現模式,來自 ['lazy', 'cached', 'mmap']。這將輸出兩個檔案 `codeparrot_content_document.idx` 和 `codeparrot_content_document.bin`,它們用於訓練。
訓練
您可以按照如下所示配置模型架構和訓練引數,或將其放入您將執行的 bash 指令碼中。此命令在 8 個 GPU 上執行 1.1 億引數 CodeParrot 模型的預訓練。請注意,資料預設按 969:30:1 的比例劃分為訓練/驗證/測試集。
GPUS_PER_NODE=8
MASTER_ADDR=localhost
MASTER_PORT=6001
NNODES=1
NODE_RANK=0
WORLD_SIZE=$(($GPUS_PER_NODE*$NNODES))
DISTRIBUTED_ARGS="--nproc_per_node $GPUS_PER_NODE --nnodes $NNODES --node_rank $NODE_RANK --master_addr $MASTER_ADDR --master_port $MASTER_PORT"
CHECKPOINT_PATH=/workspace/Megatron-LM/experiments/codeparrot-small
VOCAB_FILE=vocab.json
MERGE_FILE=merges.txt
DATA_PATH=codeparrot_content_document
GPT_ARGS="--num-layers 12
--hidden-size 768
--num-attention-heads 12
--seq-length 1024
--max-position-embeddings 1024
--micro-batch-size 12
--global-batch-size 192
--lr 0.0005
--train-iters 150000
--lr-decay-iters 150000
--lr-decay-style cosine
--lr-warmup-iters 2000
--weight-decay .1
--adam-beta2 .999
--fp16
--log-interval 10
--save-interval 2000
--eval-interval 200
--eval-iters 10
"
TENSORBOARD_ARGS="--tensorboard-dir experiments/tensorboard"
python3 -m torch.distributed.launch $DISTRIBUTED_ARGS \
pretrain_gpt.py \
--tensor-model-parallel-size 1 \
--pipeline-model-parallel-size 1 \
$GPT_ARGS \
--vocab-file $VOCAB_FILE \
--merge-file $MERGE_FILE \
--save $CHECKPOINT_PATH \
--load $CHECKPOINT_PATH \
--data-path $DATA_PATH \
$TENSORBOARD_ARGS
在此設定下,訓練大約需要 12 小時。
此設定使用資料並行,但對於不適合單個 GPU 的超大型模型,也可以使用模型並行。第一種選擇是張量並行,它將單個 Transformer 模組的執行分散到多個 GPU 上,您需要將 `tensor-model-parallel-size` 引數更改為所需的 GPU 數量。第二種選擇是流水線並行,其中 Transformer 模組被分成大小相等的階段。引數 `pipeline-model-parallel-size` 決定了將模型分成多少個階段。有關更多詳細資訊,請參閱這篇部落格
將模型轉換為 🤗 Transformers
訓練完成後,我們希望在 `transformers` 中使用該模型,例如用於評估或部署到生產環境。您可以按照此教程將其轉換為 `transformers` 模型。例如,訓練結束後,您可以複製最後一次迭代的權重(150k),並將 `model_optim_rng.pt` 檔案轉換為 `transformers` 支援的 `pytorch_model.bin` 檔案,使用以下命令:
# to execute outside the container:
mkdir -p nvidia/megatron-codeparrot-small
# copy the weights from the container
sudo docker cp CONTAINER_ID:/workspace/Megatron-LM/experiments/codeparrot-small/iter_0150000/mp_rank_00/model_optim_rng.pt nvidia/megatron-codeparrot-small
git clone https://github.com/huggingface/transformers.git
git clone https://github.com/NVIDIA/Megatron-LM.git
export PYTHONPATH=Megatron-LM
python transformers/src/transformers/models/megatron_gpt2/convert_megatron_gpt2_checkpoint.py nvidia/megatron-codeparrot-small/model_optim_rng.pt
請注意,如果您打算從那裡載入 tokenizer,則需要在轉換後用我們之前介紹的原始檔案替換生成的詞彙檔案和合並表。
別忘了將您的模型推送到 Hub 並與社群分享,只需三行程式碼 🤗
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("nvidia/megatron-codeparrot-small")
# this creates a repository under your username with the model name codeparrot-small
model.push_to_hub("codeparrot-small")
您還可以輕鬆地用它來生成文字
from transformers import pipeline
pipe = pipeline("text-generation", model="your_username/codeparrot-small")
outputs = pipe("def hello_world():")
print(outputs[0]["generated_text"])
def hello_world():
print("Hello World!")
Transformers 也能高效處理大型模型推理。如果您訓練了一個非常大的模型(例如使用模型並行),您可以使用以下命令輕鬆地將其用於推理:
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("your_username/codeparrot-large", device_map="auto")
這將在幕後使用 accelerate 庫,自動將模型權重分配到您可用的裝置(GPU、CPU RAM)上。
免責宣告:我們已經展示了任何人都可以使用 Megatron-LM 訓練語言模型。問題是什麼時候使用它。由於額外的預處理和轉換步驟,這個框架顯然會增加一些時間開銷。因此,您決定哪個框架更適合您的情況和模型大小很重要。我們建議將其用於模型預訓練或擴充套件微調,但可能不適用於中等大小模型的較短微調。`Trainer` API 和 `accelerate` 庫也非常方便模型訓練,它們是裝置無關的,併為使用者提供了顯著的靈活性。
恭喜 🎉 現在您知道如何使用 Megatron-LM 訓練 GPT2 模型並使其受 `transformers` 支援了!






