在生產環境中最佳化LLM







注意:此部落格文章也可在Transformers上作為文件頁面獲取。
GPT3/4、Falcon和LLama等大型語言模型 (LLM) 在處理以人為中心的任務方面正在迅速發展,並已成為現代知識密集型行業的重要工具。然而,在實際任務中部署這些模型仍然具有挑戰性
- 為了展示接近人類的文字理解和生成能力,LLM目前需要由數十億個引數組成(參見Kaplan et al、Wei et. al)。這相應地增加了推理的記憶體需求。
- 在許多實際任務中,LLM需要獲得大量的上下文資訊。這就要求模型在推理過程中能夠管理非常長的輸入序列。
這些挑戰的關鍵在於增強LLM的計算和記憶體能力,尤其是在處理大量輸入序列時。
在這篇部落格文章中,我們將介紹在撰寫本文時最有效的技術,以解決這些挑戰,從而實現高效的LLM部署
更低精度:研究表明,使用較低的數值精度(即8位和4位)可以在不顯著降低模型效能的情況下獲得計算優勢。
Flash Attention: Flash Attention是注意力演算法的一種變體,它不僅提供了一種更節省記憶體的方法,而且由於最佳化的GPU記憶體利用率而提高了效率。
架構創新: 考慮到LLM在推理過程中總是以相同的方式部署,即具有長輸入上下文的自迴歸文字生成,因此已經提出了允許更高效推理的專用模型架構。模型架構中最重要的進展是Alibi、Rotary embeddings、Multi-Query Attention (MQA) 和 Grouped-Query-Attention (GQA)。
在本筆記本中,我們將從張量的角度分析自迴歸生成。我們將深入探討採用較低精度的優缺點,全面探索最新的注意力演算法,並討論改進的LLM架構。在此過程中,我們將執行實際示例,展示每個功能改進。
1. 利用低精度
LLM的記憶體需求可以透過將LLM視為一組權重矩陣和向量,並將文字輸入視為一系列向量來更好地理解。下面,權重定義將用於表示所有模型權重矩陣和向量。
在撰寫本文時,LLM至少包含數十億個引數。每個引數都由一個小陣列成,例如`4.5689`,通常以float32、bfloat16或float16格式儲存。這使我們能夠輕鬆計算將LLM載入到記憶體所需的記憶體量。
以float32精度載入具有X億引數的模型權重,大約需要4 * X GB的視訊記憶體
如今,模型很少以完整的float32精度進行訓練,通常以bfloat16精度或更不頻繁地以float16精度進行訓練。因此,經驗法則變為
以bfloat16/float16精度載入具有X億引數的模型權重,大約需要2 * X GB的視訊記憶體
對於較短的文字輸入(小於1024個token),推理的記憶體需求主要由載入權重所需的記憶體決定。因此,目前我們假設推理的記憶體需求等於將模型載入到GPU視訊記憶體所需的記憶體。
舉例說明,以bfloat16載入模型大致需要多少視訊記憶體
- GPT3需要2 * 175 GB = 350 GB 視訊記憶體
- Bloom 需要2 * 176 GB = 352 GB 視訊記憶體
- Llama-2-70b 需要2 * 70 GB = 140 GB 視訊記憶體
- Falcon-40b 需要2 * 40 GB = 80 GB 視訊記憶體
- MPT-30b 需要2 * 30 GB = 60 GB 視訊記憶體
- bigcode/starcoder 需要2 * 15.5 = 31 GB 視訊記憶體
截至本文撰寫時,市面上最大的GPU晶片是A100,提供80GB視訊記憶體。上述大多數模型僅載入就需要超過80GB,因此必然需要張量並行和/或流水線並行。
🤗 Transformers 不支援開箱即用的張量並行,因為它要求模型架構以特定的方式編寫。如果您有興趣以張量並行友好的方式編寫模型,請隨時檢視文字生成推理庫。
Naive pipeline parallelism (樸素流水線並行) 開箱即用。為此,只需使用 `device="auto"` 載入模型,它將自動將不同層放置在可用的 GPU 上,如此處所述。但請注意,雖然這種樸素流水線並行非常有效,但它並不能解決 GPU 閒置的問題。為此,需要更高階的流水線並行,如此處所述。
如果您可以使用8塊80GB A100節點,您可以按以下方式載入BLOOM
!pip install transformers accelerate bitsandbytes optimum
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("bigscience/bloom", device_map="auto", pad_token_id=0)
透過使用`device_map="auto"`,注意力層將平均分佈在所有可用GPU上。
在本筆記本中,我們將使用bigcode/octocoder,因為它可以在單個40GB A100 GPU裝置晶片上執行。請注意,我們接下來將應用的所有記憶體和速度最佳化同樣適用於需要模型並行或張量並行的模型。
由於模型以bfloat16精度載入,根據我們上面的經驗法則,我們預計執行`bigcode/octocoder`推理的記憶體需求約為31GB視訊記憶體。讓我們試一試。
我們首先載入模型和tokenizer,然後將兩者都傳遞給Transformers的pipeline物件。
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
import torch
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", torch_dtype=torch.bfloat16, device_map="auto", pad_token_id=0)
tokenizer = AutoTokenizer.from_pretrained("bigcode/octocoder")
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
prompt = "Question: Please write a function in Python that transforms bytes to Giga bytes.\n\nAnswer:"
result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
result
輸出:
Here is a Python function that transforms bytes to Giga bytes:\n\n```python\ndef bytes_to_giga_bytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a single
很好,現在我們可以直接使用結果將位元組轉換為千兆位元組。
def bytes_to_giga_bytes(bytes):
return bytes / 1024 / 1024 / 1024
讓我們呼叫`torch.cuda.max_memory_allocated`來測量GPU記憶體峰值分配。
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
輸出:
29.0260648727417
與我們大致的計算結果足夠接近!我們可以看到這個數字不完全正確,因為從位元組到千位元組需要乘以1024而不是1000。因此,這個粗略的公式也可以理解為“最多X GB”的計算。請注意,如果嘗試以完整的float32精度執行模型,將需要高達64 GB的視訊記憶體。
現在幾乎所有模型都以 bfloat16 訓練,如果您的 GPU 支援 bfloat16,就沒有理由以完整的 float32 精度執行模型。Float32 不會提供比模型訓練時使用的精度更好的推理結果。
如果您不確定模型權重在Hub上以何種格式儲存,您總可以檢視檢查點配置中的`"torch_dtype"`,例如這裡。建議在載入時使用`from_pretrained(..., torch_dtype=...)`將模型設定為與配置中寫入的相同精度型別,除非原始型別為float32,在這種情況下,推理可以使用`float16`或`bfloat16`。
讓我們定義一個`flush(...)`函式來釋放所有已分配的記憶體,以便我們可以準確測量GPU記憶體峰值。
del pipe
del model
import gc
import torch
def flush():
gc.collect()
torch.cuda.empty_cache()
torch.cuda.reset_peak_memory_stats()
現在為下一個實驗呼叫它。
flush()
在最新版本的accelerate庫中,您還可以使用一個名為`release_memory()`的實用方法。
from accelerate.utils import release_memory
# ...
release_memory(model)
那麼,如果您的GPU沒有32 GB視訊記憶體怎麼辦?研究發現,模型權重可以量化為8位或4位,而不會顯著降低效能(參見Dettmers et al.)。如最近的GPTQ論文所示,模型甚至可以量化到3位或2位,且效能損失可接受🤯。
這裡不做過多細節討論,量化方案旨在降低權重的精度,同時儘量保持模型的推理結果儘可能準確(即儘可能接近bfloat16)。請注意,量化對於文字生成特別有效,因為我們只關心選擇*最有可能的下一個token集合*,而不太關心下一個token*對數*分佈的確切值。重要的是,下一個token*對數*分佈大致保持不變,以便argmax或topk操作給出相同的結果。
量化技術多種多樣,我們在此不作詳細討論,但總的來說,所有量化技術的工作原理如下:
- 將所有權重量化到目標精度
- 載入量化後的權重,並以bfloat16精度傳遞輸入向量序列
- 動態地將權重反量化為bfloat16,以便與bfloat16精度的輸入向量進行計算
- 在與輸入計算後,再次將權重量化到目標精度。
簡而言之,這意味著*輸入-權重矩陣*乘法,其中是*輸入*,是權重矩陣,是輸出
改變為
對於每一次矩陣乘法。去量化和再量化是針對所有權重矩陣按順序執行的,因為輸入會流經網路圖。
因此,使用量化權重時,推理時間通常**不會**縮短,反而會增加。理論足夠了,讓我們來試一試!要使用Transformers對權重進行量化,您需要確保已安裝`bitsandbytes`庫。
!pip install bitsandbytes
然後,我們可以透過簡單地在`from_pretrained`中新增`load_in_8bit=True`標誌來載入8位量化模型。
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", load_in_8bit=True, pad_token_id=0)
現在,讓我們再次執行示例並測量記憶體使用情況。
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
result
輸出:
Here is a Python function that transforms bytes to Giga bytes:\n\n```python\ndef bytes_to_giga_bytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a single
太好了,我們得到了和以前相同的結果,所以沒有精度損失!讓我們看看這次使用了多少記憶體。
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
輸出:
15.219234466552734
顯著減少!我們現在只剩下略高於15GB,因此可以在4090這樣的消費級GPU上執行此模型。我們看到了記憶體效率的顯著提升,並且模型輸出幾乎沒有退化。但是,我們也可以注意到推理過程中略有減慢。
我們刪除模型並再次重新整理記憶體。
del model
del pipe
flush()
讓我們看看4位量化能帶來的GPU記憶體峰值消耗。將模型量化到4位可以使用與之前相同的API - 這次透過傳遞`load_in_4bit=True`而不是`load_in_8bit=True`。
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", load_in_4bit=True, low_cpu_mem_usage=True, pad_token_id=0)
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
result
輸出:
Here is a Python function that transforms bytes to Giga bytes:\n\n```\ndef bytes_to_gigabytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a single argument
我們幾乎看到了與之前相同的輸出文字 - 只是在程式碼片段之前缺少了`python`。讓我們看看需要多少記憶體。
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
輸出:
9.543574333190918
僅9.5GB!對於一個超過150億引數的模型來說,這確實不多。
雖然我們在此模型中看到了非常小的精度下降,但4位量化在實踐中通常會與8位量化或完整的`bfloat16`推理產生不同的結果。這取決於使用者去嘗試。
另請注意,與8位量化相比,這裡的推理速度再次稍慢,這是由於4位量化使用了更激進的量化方法,導致和在推理過程中花費的時間更長。
del model
del pipe
flush()
總而言之,我們發現以8位精度執行OctoCoder將所需的GPU視訊記憶體從32G GPU視訊記憶體減少到僅15GB,而以4位精度執行模型則將所需的GPU視訊記憶體進一步減少到略高於9GB。
4位量化允許模型在RTX3090、V100和T4等GPU上執行,這些GPU對於大多數人來說是相當容易獲得的。
有關量化的更多資訊以及如何將模型量化到比4位更少的GPU視訊記憶體,我們建議查閱`AutoGPTQ`實現。
總而言之,重要的是要記住,模型量化以提高記憶體效率為代價,有時會犧牲精度,在某些情況下還會犧牲推理時間。
如果GPU記憶體不是您用例的限制,通常無需研究量化。然而,許多GPU根本無法在沒有量化方法的情況下執行LLM,在這種情況下,4位和8位量化方案是極其有用的工具。
如需更詳細的使用資訊,我們強烈建議查閱Transformers 量化文件。接下來,讓我們看看如何透過使用更好的演算法和改進的模型架構來提高計算和記憶體效率。
2. Flash Attention:向前邁進的一大步
如今,效能最佳的LLM或多或少共享相同的基本架構,該架構由前饋層、啟用層、層歸一化層以及最關鍵的自注意力層組成。
自注意力層是大型語言模型(LLM)的核心,它們使模型能夠理解輸入token之間的上下文關係。然而,自注意力層的GPU記憶體峰值消耗在計算和記憶體複雜性方面都與輸入token數量(我們下面用表示)呈*二次方*增長。雖然這對於較短的輸入序列(最多1000個輸入token)來說並不明顯,但對於較長的輸入序列(大約16000個輸入token)來說就成為一個嚴重的問題。
我們再仔細看看。自注意力層對於長度為的輸入計算輸出的公式為
是注意力層的輸入序列。投影和都將由個向量組成,從而使的大小為。
LLM通常有多個注意力頭,因此可以並行進行多次自注意力計算。假設LLM有40個注意力頭,並以bfloat16精度執行,我們可以計算儲存矩陣所需的記憶體為位元組。對於,僅需要約50MB視訊記憶體,但是對於,我們將需要19GB視訊記憶體,而對於,我們將需要近1TB僅用於儲存矩陣。
長話短說,預設的自注意力演算法對於大型輸入上下文很快就變得記憶體開銷過大。
隨著LLM在文字理解和生成方面能力的提高,它們被應用於日益複雜的任務。模型曾經處理幾句話的翻譯或摘要,現在它們管理整個頁面,這要求其能夠處理大量輸入長度。
我們如何擺脫對大量輸入長度而言高昂的記憶體需求?我們需要一種新的方法來計算自注意力機制,以擺脫矩陣。Tri Dao 等人開發了這樣一種新演算法,並將其命名為**Flash Attention**。
簡而言之,Flash Attention將)計算拆開,轉而透過迭代多個softmax計算步驟來計算較小的輸出塊
其中和是某些softmax歸一化統計量,需要對每個和迭代重新計算。
請注意,整個Flash Attention更復雜一些,這裡為了避免超出本筆記本的範圍而做了很大的簡化。讀者如有興趣,可參閱編寫精良的Flash Attention論文瞭解更多細節。
主要收穫如下
透過跟蹤 softmax 歸一化統計資料並運用一些巧妙的數學方法,Flash Attention 能夠在記憶體消耗僅隨 線性增長的情況下,提供與預設自注意力層**數值相同**的輸出。
從公式上看,人們會直觀地認為Flash Attention應該比預設的自注意力公式慢得多,因為需要進行更多的計算。事實上,Flash Attention需要比普通注意力更多的浮點運算(FLOPs),因為softmax歸一化統計資訊必須不斷重新計算(如果感興趣,請參閱論文以瞭解更多細節)
然而,Flash Attention在推理速度上遠快於預設注意力,這得益於其能夠顯著降低對速度較慢、頻寬較高的GPU記憶體(VRAM)的需求,轉而專注於速度較快的片上記憶體(SRAM)。
本質上,Flash Attention 確保所有中間讀寫操作都可以使用快速的*片上*SRAM記憶體完成,而無需訪問較慢的VRAM記憶體來計算輸出向量。
實際上,目前如果Flash Attention可用,絕對沒有理由不使用它。該演算法在數學上給出相同的輸出,並且速度更快,記憶體效率更高。
我們來看一個實際的例子。
我們的OctoCoder模型現在收到一個明顯更長的輸入提示,其中包括一個所謂的*系統提示*。系統提示用於引導LLM成為更適合使用者任務的助手。下面,我們使用一個系統提示,它將使OctoCoder成為一個更好的編碼助手。
system_prompt = """Below are a series of dialogues between various people and an AI technical assistant.
The assistant tries to be helpful, polite, honest, sophisticated, emotionally aware, and humble but knowledgeable.
The assistant is happy to help with code questions and will do their best to understand exactly what is needed.
It also tries to avoid giving false or misleading information, and it caveats when it isn't entirely sure about the right answer.
That said, the assistant is practical really does its best, and doesn't let caution get too much in the way of being useful.
The Starcoder models are a series of 15.5B parameter models trained on 80+ programming languages from The Stack (v1.2) (excluding opt-out requests).
The model uses Multi Query Attention, was trained using the Fill-in-the-Middle objective, and with 8,192 tokens context window for a trillion tokens of heavily deduplicated data.
-----
Question: Write a function that takes two lists and returns a list that has alternating elements from each input list.
Answer: Sure. Here is a function that does that.
def alternating(list1, list2):
results = []
for i in range(len(list1)):
results.append(list1[i])
results.append(list2[i])
return results
Question: Can you write some test cases for this function?
Answer: Sure, here are some tests.
assert alternating([10, 20, 30], [1, 2, 3]) == [10, 1, 20, 2, 30, 3]
assert alternating([True, False], [4, 5]) == [True, 4, False, 5]
assert alternating([], []) == []
Question: Modify the function so that it returns all input elements when the lists have uneven length. The elements from the longer list should be at the end.
Answer: Here is the modified function.
def alternating(list1, list2):
results = []
for i in range(min(len(list1), len(list2))):
results.append(list1[i])
results.append(list2[i])
if len(list1) > len(list2):
results.extend(list1[i+1:])
else:
results.extend(list2[i+1:])
return results
-----
"""
為了演示目的,我們將系統複製十次,以便輸入長度足夠長,可以觀察Flash Attention的記憶體節省。我們附加原始文字提示`"Question: Please write a function in Python that transforms bytes to Giga bytes.\n\nAnswer: Here"`
long_prompt = 10 * system_prompt + prompt
我們再次以bfloat16精度例項化模型。
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", torch_dtype=torch.bfloat16, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("bigcode/octocoder")
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
現在,讓我們像以前一樣**不使用Flash Attention**執行模型,並測量GPU記憶體峰值需求和推理時間。
import time
start_time = time.time()
result = pipe(long_prompt, max_new_tokens=60)[0]["generated_text"][len(long_prompt):]
print(f"Generated in {time.time() - start_time} seconds.")
result
輸出:
Generated in 10.96854019165039 seconds.
Sure. Here is a function that does that.\n\ndef bytes_to_giga(bytes):\n return bytes / 1024 / 1024 / 1024\n\nAnswer: Sure. Here is a function that does that.\n\ndef
我們得到了與之前相同的輸出,但是這次,模型重複了多次答案,直到達到60個token的截止。這並不奇怪,因為我們為了演示目的將系統提示重複了十次,從而提示模型重複自身。
注意,在實際應用中,系統提示不應重複十次——一次就夠了!
讓我們測量一下GPU記憶體峰值需求。
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
輸出:
37.668193340301514
正如我們所看到的,GPU記憶體峰值需求現在明顯高於開始時,這主要是由於輸入序列更長。而且生成時間現在也超過了一分鐘。
我們呼叫`flush()`來釋放GPU記憶體,以便進行下一個實驗。
flush()
為了比較,我們執行相同的函式,但啟用 Flash Attention。為此,我們將模型轉換為BetterTransformers,從而啟用 PyTorch 的SDPA 自注意力,而 SDPA 自注意力又基於 Flash Attention。
model.to_bettertransformer()
現在我們執行與之前完全相同的程式碼片段,Transformers 將在後臺使用 Flash Attention。
start_time = time.time()
with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
result = pipe(long_prompt, max_new_tokens=60)[0]["generated_text"][len(long_prompt):]
print(f"Generated in {time.time() - start_time} seconds.")
result
輸出:
Generated in 3.0211617946624756 seconds.
Sure. Here is a function that does that.\n\ndef bytes_to_giga(bytes):\n return bytes / 1024 / 1024 / 1024\n\nAnswer: Sure. Here is a function that does that.\n\ndef
我們得到了與之前完全相同的結果,但由於 Flash Attention,我們可以觀察到非常顯著的速度提升。
讓我們最後一次測量記憶體消耗。
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
輸出:
32.617331981658936
我們幾乎回到了最初的29GB GPU記憶體峰值。
我們可以觀察到,使用Flash Attention傳遞非常長的輸入序列,與最初傳遞短輸入序列相比,我們只多使用了大約100MB的GPU記憶體。
flush()
3. LLM架構背後的科學:長文字輸入和聊天的策略選擇
到目前為止,我們已經研究瞭如何透過以下方式提高計算和記憶體效率:
- 將權重轉換為較低精度格式
- 用更節省記憶體和計算效率的版本替換自注意力演算法
現在,讓我們看看如何更改LLM的架構,使其最有效地處理需要長文字輸入的任務,例如
- 檢索增強問答,
- 摘要,
- 聊天
請注意,*聊天*不僅要求LLM處理長文字輸入,還需要LLM能夠高效處理使用者和助手之間的來回對話(例如ChatGPT)。
一旦訓練完成,基礎LLM架構就難以更改,因此提前考慮LLM的任務並相應地最佳化模型架構非常重要。模型架構中有兩個重要元件,對於大型輸入序列,它們會迅速成為記憶體和/或效能瓶頸。
- 位置嵌入
- 鍵值快取
讓我們更詳細地介紹每個元件
3.1 改進LLM的位置嵌入
自注意力將每個token相互關聯。例如,文字輸入序列“Hello”、“I”、“love”、“you”的矩陣可能如下所示
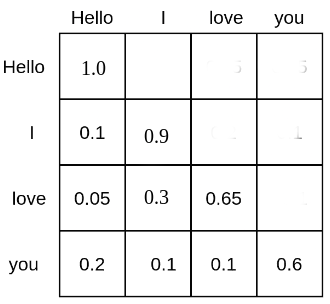
每個詞token都被賦予一個機率質量,表示它關注所有其他詞token的程度,因此與其他所有詞token相關聯。例如,“love”這個詞關注“Hello”5%,關注“I”30%,關注自身65%。
基於自注意力但不帶位置嵌入的LLM在理解文字輸入相互位置方面會遇到很大困難。這是因為由計算的機率得分,將每個詞token與所有其他詞token以的計算方式相關聯,無論它們之間的相對位置距離如何。因此,對於沒有位置嵌入的LLM,每個token似乎與所有其他token具有相同的距離,例如,區分“Hello I love you”和“You love I hello”將非常具有挑戰性。
為了讓LLM理解句子順序,需要額外的*線索*,通常以*位置編碼*(或*位置嵌入*)的形式應用。位置編碼將每個token的位置編碼成LLM可以利用的數值表示,以更好地理解句子順序。
《Attention Is All You Need》論文的作者引入了正弦位置嵌入。其中每個向量都作為其位置的正弦函式計算。然後,位置編碼簡單地新增到輸入序列向量 = ,從而引導模型更好地學習句子順序。
與使用固定位置嵌入不同,其他研究者(如Devlin et al.)使用了學習型位置編碼,其中位置嵌入在訓練期間學習。
正弦和學習型位置嵌入曾是LLM中編碼句子順序的主要方法,但發現了與這些位置編碼相關的一些問題:
- 正弦和學習型位置嵌入都是絕對位置嵌入,即為每個位置ID編碼一個唯一的嵌入:。正如Huang et al.和Su et al.所展示的,絕對位置嵌入會導致LLM在處理長文字輸入時效能不佳。對於長文字輸入,如果模型學習了輸入token之間相對位置距離而不是它們的絕對位置,將更有優勢。
- 當使用學習型位置嵌入時,LLM必須以固定的輸入長度進行訓練,這使得難以推廣到比訓練時更長的輸入長度。
最近,可以解決上述問題的相對位置嵌入變得更受歡迎,其中最值得關注的是:
RoPE和ALiBi都認為,最好直接在自注意力演算法中提示LLM句子順序,因為詞元正是在那裡相互關聯的。更具體地說,句子順序應該透過修改計算來提示。
不贅述太多細節,RoPE 指出位置資訊可以編碼到查詢-鍵對中,例如 和 ,透過將每個向量旋轉角度 和 (其中 描述了每個向量的句子位置)。
因此表示一個旋轉矩陣。 在訓練期間不學習,而是設定為一個預定義值,該值取決於訓練期間的最大輸入序列長度。
透過這樣做, 和 之間的機率分數僅在 時受到影響,並且僅取決於相對距離 ,而與每個向量的具體位置 和 無關。
RoPE 被用於當今最重要的多個大型語言模型(LLM)中,例如:
作為替代方案,ALiBi 提出了一種更簡單的相對位置編碼方案。輸入 token 之間的相對距離以負整數形式,乘以預定義值 m,新增到 矩陣的每個查詢-鍵條目中,緊接著 softmax 計算。
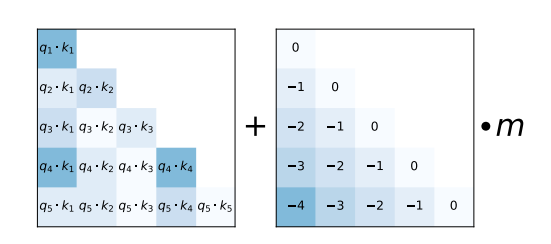
如 ALiBi 論文所示,這種簡單的相對位置編碼使得模型即使在非常長的文字輸入序列中也能保持高效能。
ALiBi 被用於當今最重要的多個大型語言模型(LLM)中,例如:
RoPE 和 ALiBi 位置編碼都可以外推到訓練期間未見的輸入長度,儘管研究表明 ALiBi 的外推效果比 RoPE 更好。對於 ALiBi,只需增加下三角位置矩陣的值以匹配輸入序列的長度。對於 RoPE,如果使用訓練期間相同的 值,當輸入文字長度遠超訓練時,會導致糟糕的結果,參見 Press et al.。然而,社群已經發現了一些有效的技巧來調整 ,從而使 RoPE 位置嵌入在外推文字輸入序列中也能表現良好(參見此處)。
RoPE 和 ALiBi 都是相對位置嵌入,它們在訓練期間不學習,而是基於以下直覺:
- 文字輸入的定位線索應直接提供給自注意力層的 矩陣
- LLM 應該被激勵去學習位置編碼之間的一種恆定的相對距離。
- 文字輸入 token 之間的距離越遠,其查詢-值機率就越低。RoPE 和 ALiBi 都會降低相距較遠的 token 的查詢-鍵機率。RoPE 透過增加查詢-鍵向量之間的角度來減小其向量積。ALiBi 透過向向量積新增大的負數來實現。
總之,旨在處理大型文字輸入任務的 LLM 最好使用相對位置嵌入進行訓練,例如 RoPE 和 ALiBi。還要注意,即使 LLM 使用 RoPE 和 ALiBi 並且僅在固定長度(例如 )上進行了訓練,它仍然可以透過外推位置嵌入來處理遠大於 的文字輸入,例如 。
3.2 鍵值快取
LLM 的自迴歸文字生成工作原理是:迭代地輸入一個序列,取樣下一個 token,將下一個 token 附加到輸入序列中,並持續這樣做直到 LLM 生成一個表示生成完成的 token。
請查閱 Transformer 的文字生成教程,以獲得關於自迴歸生成工作原理的更直觀解釋。
讓我們快速執行一段程式碼,以展示自迴歸在實踐中是如何工作的。我們將簡單地透過 torch.argmax 獲取最可能的下一個 token。
input_ids = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda")
for _ in range(5):
next_logits = model(input_ids)["logits"][:, -1:]
next_token_id = torch.argmax(next_logits,dim=-1)
input_ids = torch.cat([input_ids, next_token_id], dim=-1)
print("shape of input_ids", input_ids.shape)
generated_text = tokenizer.batch_decode(input_ids[:, -5:])
generated_text
輸出:
shape of input_ids torch.Size([1, 21])
shape of input_ids torch.Size([1, 22])
shape of input_ids torch.Size([1, 23])
shape of input_ids torch.Size([1, 24])
shape of input_ids torch.Size([1, 25])
[' Here is a Python function']
我們可以看到,每次我們都會透過剛剛取樣的 token 來增加文字輸入 token 的長度。
除了極少數例外,LLM 都使用因果語言建模目標進行訓練,因此會掩蓋注意力分數矩陣的右上三角——這就是上面兩個圖中注意力分數留空(即機率為 0)的原因。有關因果語言建模的快速回顧,您可以參考圖解自注意力部落格。
因此,token 從不依賴未來的 token,更具體地說,如果 ,則 向量永遠不會與任何鍵值向量 建立關係。相反, 只關注先前的鍵值向量 。為了減少不必要的計算,可以快取每個層的所有先前時間步的鍵值向量。
接下來,我們將告訴 LLM 利用鍵值快取,並在每次前向傳遞時檢索和轉發它。在 Transformers 中,我們可以透過將 use_cache 標誌傳遞給 forward 呼叫來檢索鍵值快取,然後將其與當前 token 一起傳遞。
past_key_values = None # past_key_values is the key-value cache
generated_tokens = []
next_token_id = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda")
for _ in range(5):
next_logits, past_key_values = model(next_token_id, past_key_values=past_key_values, use_cache=True).to_tuple()
next_logits = next_logits[:, -1:]
next_token_id = torch.argmax(next_logits, dim=-1)
print("shape of input_ids", next_token_id.shape)
# past_key_values are a tuple (one for each Transformer layer) of tuples (one for the keys, one for the values)
# cached keys and values each are of shape (batch_size, num_heads, sequence_length, embed_size_per_head)
# hence let's print how many cached keys and values we have for the first Transformer layer
print("number of cached keys of the first Transformer layer", len(past_key_values[0][0][0,0,:,:]))
print("number of cached values of the first Transformer layer", len(past_key_values[0][1][0,0,:,:]))
generated_tokens.append(next_token_id.item())
generated_text = tokenizer.batch_decode(generated_tokens)
generated_text
輸出:
shape of input_ids torch.Size([1, 1])
number of cached keys of the first Transformer layer: 20
number of cached values of the first Transformer layer: 20
shape of input_ids torch.Size([1, 1])
number of cached keys of the first Transformer layer: 21
number of cached values of the first Transformer layer: 21
shape of input_ids torch.Size([1, 1])
number of cached keys of the first Transformer layer: 22
number of cached values of the first Transformer layer: 22
shape of input_ids torch.Size([1, 1])
number of cached keys of the first Transformer layer: 23
number of cached values of the first Transformer layer: 23
shape of input_ids torch.Size([1, 1])
number of cached keys of the first Transformer layer: 24
number of cached values of the first Transformer layer: 24
[' Here', ' is', ' a', ' Python', ' function']
可以看出,在使用鍵值快取時,文字輸入 token 的長度不會增加,而是一個單一的輸入向量。另一方面,鍵值快取的長度在每個解碼步驟都會增加一個。
使用鍵值快取意味著 基本上簡化為 ,其中 是當前傳遞的輸入 token 的查詢投影,它總是一個單一向量。
使用鍵值快取有兩大優勢:
- 計算效率顯著提高,因為與計算完整的 矩陣相比,執行的計算量更少。這使得推理速度得以提升。
- 所需的最大記憶體不再隨生成 token 的數量呈二次方增加,而只呈線性增加。
應該始終使用鍵值快取,因為它能帶來相同的結果,並且對於較長的輸入序列而言,能顯著提升速度。在 Transformers 中,使用文字管道或
generate方法時,鍵值快取預設啟用。
需要注意的是,鍵值快取對於需要處理大量文字輸入的應用程式(例如聊天)尤其有用。讓我們看一個例子。
User: How many people live in France?
Assistant: Roughly 75 million people live in France
User: And how many are in Germany?
Assistant: Germany has ca. 81 million inhabitants
在此聊天中,LLM 執行兩次自迴歸解碼
- 第一次,鍵值快取為空,輸入提示為
"User: 法國有多少人口?",模型自迴歸生成文字"大約有 7500 萬人居住在法國",同時在每個解碼步驟增加鍵值快取。
- 第一次,鍵值快取為空,輸入提示為
- 第二次,輸入提示是
"使用者:法國有多少人口?\n助手:大約有 7500 萬人居住在法國\n使用者:那德國有多少人?"。得益於快取,前兩句話的所有鍵值向量都已計算。因此,輸入提示只包含"使用者:那德國有多少人?"。在處理縮短的輸入提示時,它計算出的鍵值向量會連線到第一次解碼的鍵值快取中。助手第二次的回答"德國大約有 8100 萬居民"隨後透過包含"使用者:法國有多少人口?\n助手:大約有 7500 萬人居住在法國\n使用者:那德國有多少人?"編碼的鍵值向量的鍵值快取進行自迴歸生成。
- 第二次,輸入提示是
這裡有兩點需要注意:
- 對於部署在聊天中的 LLM 來說,保持所有上下文至關重要,這樣 LLM 才能理解對話的所有先前上下文。例如,對於上面的例子,LLM 需要理解使用者在詢問
"那德國有多少人"時指的是人口。 - 鍵值快取對於聊天非常有用,因為它允許我們持續增長編碼的聊天曆史,而不必從頭開始重新編碼聊天曆史(例如,在使用編碼器-解碼器架構時就會出現這種情況)。
然而,這裡有一個問題。雖然 矩陣所需的峰值記憶體顯著減少,但對於長輸入序列或多輪聊天來說,將鍵值快取儲存在記憶體中可能會非常耗記憶體。請記住,鍵值快取需要儲存所有先前輸入向量 的鍵值向量,適用於所有自注意力層和所有注意力頭。
讓我們計算一下之前使用過的 LLM bigcode/octocoder 的鍵值快取中需要儲存的浮點值數量。浮點值數量是序列長度乘以注意力頭數乘以注意力頭維度再乘以層數的兩倍。假設輸入序列長度為 16000,對我們的 LLM 進行計算,結果如下:
config = model.config
2 * 16_000 * config.n_layer * config.n_head * config.n_embd // config.n_head
輸出:
7864320000
大約 80 億個浮點值!以 float16 精度儲存 80 億個浮點值大約需要 15 GB 記憶體,這大約是模型權重本身的一半!研究人員提出了兩種方法,可以顯著降低儲存鍵值快取的記憶體成本:
多查詢注意力(Multi-Query-Attention, MQA)由 Noam Shazeer 在其論文《快速 Transformer 解碼:一個寫頭足矣》(Fast Transformer Decoding: One Write-Head is All You Need)中提出。正如標題所示,Noam 發現,可以使用一組單一的鍵值投影權重,並在所有注意力頭之間共享,而不會顯著降低模型效能。
透過使用一個單一的頭值投影權重對,鍵值向量 在所有注意力頭中必須相同,這意味著我們只需在快取中儲存 1 個鍵值投影對,而不是
n_head個。
由於大多數 LLM 使用 20 到 100 個注意力頭,MQA 顯著降低了鍵值快取的記憶體消耗。對於本筆記本中使用的 LLM,在輸入序列長度為 16000 時,我們可以將所需的記憶體消耗從 15 GB 減少到不足 400 MB。
除了節省記憶體外,MQA 還提高了計算效率,具體解釋如下。在自迴歸解碼中,每次迭代都需要重新載入大型鍵值向量,並與當前的鍵值向量對連線,然後將其輸入到 計算中。對於自迴歸解碼,不斷重新載入所需的記憶體頻寬可能成為嚴重的時間瓶頸。透過減小鍵值向量的大小,訪問的記憶體量減少,從而減輕了記憶體頻寬瓶頸。欲瞭解更多詳情,請查閱 Noam 的論文。
這裡需要理解的重要一點是,將鍵值注意力頭數減少到 1 僅在使用了鍵值快取時才有意義。在不使用鍵值快取的情況下,模型在單次前向傳遞中的峰值記憶體消耗保持不變,因為每個注意力頭仍然具有唯一的查詢向量,因此每個注意力頭仍然具有不同的 矩陣。
MQA 已被社群廣泛採用,並被許多最流行的 LLM 使用。
此外,本筆記本中使用的檢查點——bigcode/octocoder——也使用了 MQA。
分組查詢注意力(Grouped-Query-Attention,GQA)由 Google 的 Ainslie 等人提出,他們發現與使用傳統的多鍵值頭投影相比,使用 MQA 經常會導致質量下降。該論文認為,透過不那麼大幅度地減少查詢頭投影權重的數量,可以保持更多的模型效能。不只使用一個鍵值投影權重,而應該使用 n < n_head 個鍵值投影權重。透過將 n 選擇為一個遠小於 n_head 的值,例如 2、4 或 8,可以保留 MQA 幾乎所有的記憶體和速度優勢,同時犧牲更少的模型容量,從而可以說效能下降也更少。
此外,GQA 的作者發現,現有的模型檢查點可以透過僅相當於原始預訓練計算量 5% 的計算量來升級到 GQA 架構。雖然 5% 的原始預訓練計算量仍然可能是一個巨大的數字,但 GQA 升級允許現有檢查點可用於更長的輸入序列。
GQA 最近才被提出,因此在撰寫本筆記本時,其採用率較低。GQA 最顯著的應用是 Llama-v2。
綜上所述,如果 LLM 被部署用於自迴歸解碼並需要處理大型輸入序列(例如聊天),強烈建議使用 GQA 或 MQA。
結論
研究社群不斷提出新穎巧妙的方法來加速日益龐大的 LLM 的推理時間。例如,一個有前景的研究方向是推測解碼,其中“容易的 token”由較小、較快的語言模型生成,只有“困難的 token”才由 LLM 本身生成。深入細節超出了本筆記本的範圍,但可以在這篇精彩的部落格文章中閱讀更多內容。
GPT3/4、Llama-2-70b、Claude、PaLM 等大型 LLM 之所以能在 Hugging Face Chat 或 ChatGPT 等聊天介面中執行如此之快,很大程度上歸功於上述在精度、演算法和架構方面的改進。展望未來,GPU、TPU 等加速器只會越來越快並提供更多的記憶體,但無論如何,仍應始終確保使用最佳可用演算法和架構,以獲得最大的效益 🤗







