Perceiver IO:一種可擴充套件的、全注意力模型,適用於任何模態







TLDR
我們已將 Perceiver IO 新增到 Transformers 中,這是第一個基於 Transformer 的神經網路,可處理各種模態(文字、影像、音訊、影片、點雲等)及其組合。請檢視以下 Spaces 以檢視一些示例
我們還提供了 幾個 Jupyter Notebook。
下面是模型的詳細技術解釋。
引言
Vaswani 等人於 2017 年首次引入的 Transformer 在人工智慧社群引發了一場革命,最初在機器翻譯領域提升了最先進 (SOTA) 的結果。2018 年,BERT 釋出,這是一種僅包含 Transformer 編碼器的模型,在自然語言處理 (NLP) 的基準測試中表現出色,其中最著名的是 GLUE 基準。
此後不久,人工智慧研究人員開始將 BERT 的思想應用於其他領域。舉幾個例子
- Facebook AI 的 Wav2Vec2 證明該架構可以擴充套件到音訊
- Google AI 的 Vision Transformer (ViT) 表明該架構在視覺方面表現出色
- 最近,Google AI 的 Video Vision Transformer (ViViT) 也將該架構應用於影片。
在所有這些領域中,得益於這種強大架構與大規模預訓練的結合,最先進的結果得到了顯著改善。
然而,Transformer 架構存在一個重要限制:由於其 自注意力機制,它在計算和記憶體方面的擴充套件性 非常差。在每個層中,所有輸入都用於生成查詢 (queries) 和鍵 (keys),並計算它們的點積。因此,如果不進行某種形式的預處理,就無法在高維資料上應用自注意力。例如,Wav2Vec2 透過使用特徵編碼器將原始波形轉換為基於時間的特徵序列來解決這個問題。Vision Transformer (ViT) 將影像分割成不重疊的影像塊序列,這些影像塊充當“token”。Video Vision Transformer (ViViT) 從影片中提取不重疊的時空“管”,這些“管”充當“token”。為了使 Transformer 在特定模態上工作,通常需要將其離散化為 token 序列。
Perceiver 模型
Perceiver 旨在透過對一組潛在變數而不是輸入資料應用自注意力機制來解決此限制。輸入資料(可以是文字、影像、音訊、影片)僅用於與潛在變數進行交叉注意力。這樣做的好處是,大部分計算發生在潛在空間中,計算成本較低(通常使用 256 或 512 個潛在變數)。由此產生的架構沒有輸入大小的二次依賴性:Transformer 編碼器僅線性依賴於輸入大小,而潛在注意力與輸入大小無關。在後續論文《Perceiver IO》中,作者擴充套件了這一思想,使 Perceiver 也能處理任意輸出。其思想類似:僅使用輸出與潛在變數進行交叉注意力。請注意,在本篇博文中,“Perceiver”和“Perceiver IO”這兩個術語將可互換地指代 Perceiver IO 模型。
在接下來的部分中,我們將更詳細地瞭解 Perceiver IO 的實際工作原理,透過其在 HuggingFace Transformers 中的實現進行講解。HuggingFace Transformers 是一個流行的庫,最初用於實現基於 Transformer 的 NLP 模型,但現在也開始在其他領域實現它們。在以下部分中,我們將透過張量的形狀,詳細解釋 Perceiver 實際如何對任何模態進行預處理和後處理。
HuggingFace Transformers 中的所有 Perceiver 變體都基於 `PerceiverModel` 類。要初始化 `PerceiverModel`,可以為模型提供 3 個額外的例項
- 一個預處理器
- 一個解碼器
- 一個後處理器。
請注意,這些都是可選的。只有當尚未自行嵌入 `inputs`(例如文字、影像、音訊、影片)時才需要 `preprocessor`。只有當需要將 Perceiver 編碼器的輸出(即潛在變數的最後隱藏狀態)解碼為更有用的東西,例如分類 logits 或光流時,才需要 `decoder`。只有當需要將解碼器的輸出轉換為特定特徵時才需要 `postprocessor`(這僅在進行自編碼時需要,我們稍後會看到)。架構概述如下圖所示。
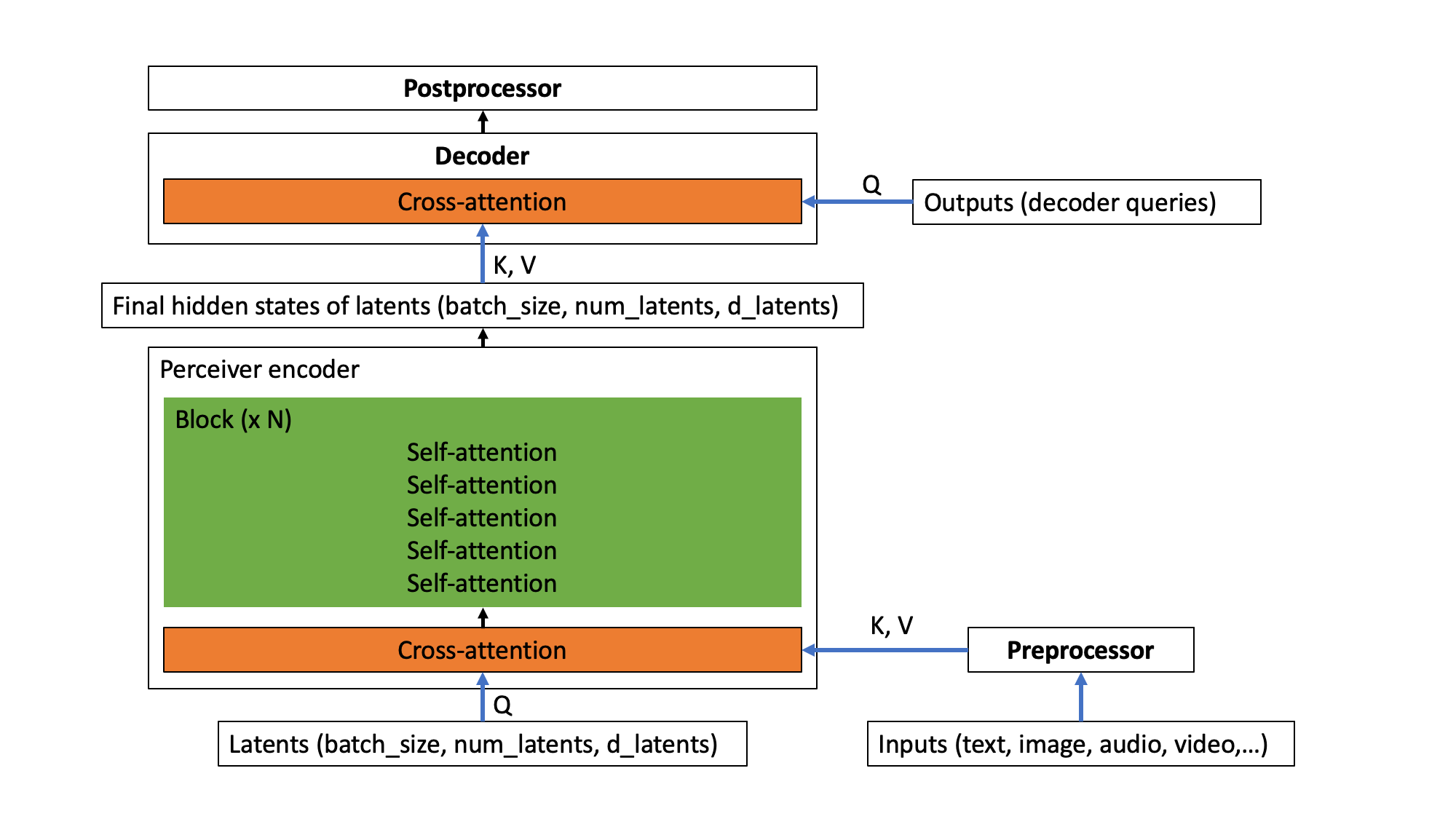
Perceiver 架構。
換句話說,`inputs`(可以是任何模態,或它們的組合)首先透過 `preprocessor` 進行可選的預處理。接下來,預處理後的輸入與 Perceiver 編碼器的潛在變數執行交叉注意力操作。在此操作中,潛在變數生成查詢 (Q),而預處理後的輸入生成鍵和值 (KV)。此操作後,Perceiver 編碼器採用(可重複的)自注意力層塊來更新潛在變數的嵌入。編碼器最終將生成一個形狀為 (batch_size, num_latents, d_latents) 的張量,其中包含潛在變數的最後隱藏狀態。接下來,有一個可選的 `decoder`,可用於將潛在變數的最終隱藏狀態解碼為更有用的東西,例如分類 logits。這是透過執行交叉注意力操作完成的,其中可訓練的嵌入用於生成查詢 (Q),而潛在變數用於生成鍵和值 (KV)。最後,有一個可選的 `postprocessor`,可用於將解碼器輸出後處理為特定特徵。
讓我們首先展示 Perceiver 如何實現文字處理。
文字 Perceiver
假設我們想應用 Perceiver 進行文字分類。由於 Perceiver 自注意力機制的記憶體和時間需求不依賴於輸入的大小,我們可以直接向模型提供原始 UTF-8 位元組。這是有益的,因為熟悉的基於 Transformer 的模型(如 BERT 和 RoBERTa)都採用某種形式的顯式分詞,例如 WordPiece、BPE 或 SentencePiece,這 可能有害。為了與 BERT(使用 512 個子詞 token 的序列長度)進行公平比較,作者使用了 2048 位元組的輸入序列。假設我們還添加了一個批處理維度,那麼模型的 `inputs` 形狀為 (batch_size, 2048)。`inputs` 包含單個文字的位元組 ID(類似於 BERT 的 `input_ids`)。我們可以使用 `PerceiverTokenizer` 將文字轉換為位元組 ID 序列,並填充到 2048 的長度。
from transformers import PerceiverTokenizer
tokenizer = PerceiverTokenizer.from_pretrained("deepmind/language-perceiver")
text = "hello world"
inputs = tokenizer(text, padding="max_length", return_tensors="pt").input_ids
在這種情況下,我們為模型提供了 `PerceiverTextPreprocessor` 作為預處理器,它將負責嵌入 `inputs`(即將每個位元組 ID 轉換為相應的向量),並新增絕對位置嵌入。作為解碼器,我們為模型提供了 `PerceiverClassificationDecoder`(它將潛在變數的最後隱藏狀態轉換為分類 logits)。不需要後處理器。換句話說,用於文字分類的 Perceiver 模型(在 HuggingFace Transformers 中稱為 `PerceiverForSequenceClassification`)的實現如下:
from torch import nn
from transformers import PerceiverModel
from transformers.models.perceiver.modeling_perceiver import PerceiverTextPreprocessor, PerceiverClassificationDecoder
class PerceiverForSequenceClassification(nn.Module):
def __init__(self, config):
super().__init__(config)
self.perceiver = PerceiverModel(
config,
input_preprocessor=PerceiverTextPreprocessor(config),
decoder=PerceiverClassificationDecoder(
config,
num_channels=config.d_latents,
trainable_position_encoding_kwargs=dict(num_channels=config.d_latents, index_dims=1),
use_query_residual=True,
),
)
在這裡我們可以看到,解碼器是用可訓練的位置編碼引數初始化的。這是為什麼呢?好吧,讓我們詳細看看 Perceiver IO 究竟是如何工作的。在初始化時,`PerceiverModel` 在內部定義了一組潛在變數,如下所示
from torch import nn
self.latents = nn.Parameter(torch.randn(config.num_latents, config.d_latents))
在 Perceiver IO 論文中,使用了 256 個潛在變數,並將潛在變數的維度設定為 1280。如果再新增一個批處理維度,則 Perceiver 的潛在變數形狀為 (batch_size, 256, 1280)。首先,預處理器(在初始化時提供)將負責將 UTF-8 位元組 ID 嵌入到嵌入向量中。因此,`PerceiverTextPreprocessor` 會將形狀為 (batch_size, 2048) 的 `inputs` 轉換為形狀為 (batch_size, 2048, 768) 的張量——假設每個位元組 ID 都轉換為大小為 768 的向量(這由 `PerceiverConfig` 的 `d_model` 屬性決定)。
在此之後,Perceiver IO 在形狀為 (batch_size, 256, 1280) 的潛在變數(生成查詢)與形狀為 (batch_size, 2048, 768) 的預處理輸入(生成鍵和值)之間應用交叉注意力。這個初始交叉注意力操作的輸出是一個與查詢(在這種情況下是潛在變數)形狀相同的張量。換句話說,交叉注意力操作的輸出形狀為 (batch_size, 256, 1280)。
接下來,應用一個(可重複的)自注意力層塊來更新潛在變數的表示。請注意,這些不依賴於您提供的輸入(即位元組)的長度,因為這些只在交叉注意力操作期間使用。在 Perceiver IO 論文中,一個包含 26 個自注意力層(每個自注意力層有 8 個注意力頭)的單個塊被用於更新文字模型的潛在變量表示。請注意,這 26 個自注意力層之後的輸出仍然具有與您最初提供給編碼器的輸入相同的形狀:(batch_size, 256, 1280)。這些也被稱為潛在變數的“最後隱藏狀態”。這與您提供給 BERT 的 token 的“最後隱藏狀態”非常相似。
好的,現在我們有了形狀為 (batch_size, 256, 1280) 的最終隱藏狀態。很棒,但我們實際上想把它們轉換成分類 logits,形狀為 (batch_size, num_labels)。我們如何讓 Perceiver 輸出這些呢?
這由 `PerceiverClassificationDecoder` 處理。其思想與將輸入對映到潛在空間時的操作非常相似:我們使用交叉注意力。但現在,潛在變數將生成鍵和值,而我們提供一個任何我們想要的形狀的張量——在這種情況下,我們將提供一個形狀為 (batch_size, 1, num_labels) 的張量,它將充當查詢(作者將其稱為“解碼器查詢”,因為它用於解碼器)。這個張量將在訓練開始時隨機初始化,並進行端到端訓練。正如我們所看到的,我們只是提供一個虛擬的序列長度維度為 1。請注意,QKV 注意力層的輸出始終與查詢的形狀相同——因此解碼器將輸出一個形狀為 (batch_size, 1, num_labels) 的張量。然後,解碼器簡單地壓縮此張量,使其形狀為 (batch_size, num_labels),然後就得到了分類 logits1。
很棒,不是嗎?Perceiver 作者還表明,對 Perceiver 進行掩碼語言建模預訓練非常簡單,類似於 BERT。該模型也已在 HuggingFace Transformers 中提供,並命名為 `PerceiverForMaskedLM`。與 `PerceiverForSequenceClassification` 的唯一區別是,它不使用 `PerceiverClassificationDecoder` 作為解碼器,而是使用 `PerceiverBasicDecoder`,將潛在變數解碼為形狀為 (batch_size, 2048, 1280) 的張量。在此之後,新增一個語言建模頭,將其轉換為形狀為 (batch_size, 2048, vocab_size) 的張量。Perceiver 的詞彙量只有 262,即 256 個 UTF-8 位元組 ID 以及 6 個特殊標記。透過在英文維基百科和 C4 上預訓練 Perceiver,作者表明在微調後,在 GLUE 上可以達到 81.8 的總分。
影像 Perceiver
現在我們已經瞭解瞭如何應用 Perceiver 進行文字分類,將 Perceiver 應用於影像分類也變得很簡單。唯一的區別是我們將為模型提供一個不同的 `preprocessor`,它將嵌入影像 `inputs`。Perceiver 作者實際上嘗試了 3 種不同的預處理方法
- 展平畫素值,應用核大小為 1 的卷積層,並新增學習到的絕對 1D 位置嵌入。
- 展平畫素值並新增固定的 2D 傅立葉位置嵌入。
- 應用 2D 卷積 + 最大池化層並新增固定的 2D 傅立葉位置嵌入。
這些都在 Transformers 庫中實現,分別稱為 `PerceiverForImageClassificationLearned`、`PerceiverForImageClassificationFourier` 和 `PerceiverForImageClassificationConvProcessing`。它們僅在 `PerceiverImagePreprocessor` 的配置上有所不同。讓我們仔細看看 `PerceiverForImageClassificationLearned`。它初始化 `PerceiverModel` 如下
from torch import nn
from transformers import PerceiverModel
from transformers.models.perceiver.modeling_perceiver import PerceiverImagePreprocessor, PerceiverClassificationDecoder
class PerceiverForImageClassificationLearned(nn.Module):
def __init__(self, config):
super().__init__(config)
self.perceiver = PerceiverModel(
config,
input_preprocessor=PerceiverImagePreprocessor(
config,
prep_type="conv1x1",
spatial_downsample=1,
out_channels=256,
position_encoding_type="trainable",
concat_or_add_pos="concat",
project_pos_dim=256,
trainable_position_encoding_kwargs=dict(num_channels=256, index_dims=config.image_size ** 2),
),
decoder=PerceiverClassificationDecoder(
config,
num_channels=config.d_latents,
trainable_position_encoding_kwargs=dict(num_channels=config.d_latents, index_dims=1),
use_query_residual=True,
),
)
可以看出,`PerceiverImagePreprocessor` 以 `prep_type = "conv1x1"` 初始化,並且添加了可訓練位置編碼的引數。那麼,這個預處理器究竟是如何工作的呢?假設我們向模型提供了一批影像。假設我們首先將影像中心裁剪到 224 解析度並對顏色通道進行歸一化,這樣 `inputs` 的形狀為 (batch_size, num_channels, height, width) = (batch_size, 3, 224, 224)。我們可以使用 `PerceiverImageProcessor` 來完成此操作,如下所示
from transformers import PerceiverImageProcessor
import requests
from PIL import Image
processor = PerceiverImageProcessor.from_pretrained("deepmind/vision-perceiver")
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(image, return_tensors="pt").pixel_values
`PerceiverImagePreprocessor`(使用上述設定)將首先應用一個核大小為 (1, 1) 的卷積層,將 `inputs` 轉換為形狀為 (batch_size, 256, 224, 224) 的張量——從而增加通道維度。然後它會將通道維度放在最後——所以現在我們有一個形狀為 (batch_size, 224, 224, 256) 的張量。接下來,它會展平空間(高 + 寬)維度,使我們得到一個形狀為 (batch_size, 50176, 256) 的張量。接下來,它將其與可訓練的 1D 位置嵌入連線。由於位置嵌入的維度定義為 256(參見上面的 `num_channels` 引數),我們得到一個形狀為 (batch_size, 50176, 512) 的張量。這個張量將用於與潛在變數進行交叉注意力操作。
作者對所有影像模型使用 512 個潛在變數,並將潛在變數的維度設定為 1024。因此,潛在變數的形狀為 (batch_size, 512, 1024) - 假設我們添加了批處理維度。交叉注意力層接收形狀為 (batch_size, 512, 1024) 的查詢和形狀為 (batch_size, 50176, 512) 的鍵+值作為輸入,並生成一個與查詢形狀相同的張量,因此輸出一個形狀為 (batch_size, 512, 1024) 的新張量。接下來,重複應用一個包含 6 個自注意力層(每個自注意力層有 8 個注意力頭)的塊(8 次),以生成形狀為 (batch_size, 512, 1024) 的潛在變數的最終隱藏狀態。為了將這些轉換為分類 logits,使用 `PerceiverClassificationDecoder`,其工作原理與文字分類的解碼器類似:它將潛在變數用作鍵+值,並使用形狀為 (batch_size, 1, num_labels) 的可訓練位置嵌入作為查詢。交叉注意力操作的輸出是一個形狀為 (batch_size, 1, num_labels) 的張量,將其壓縮後得到形狀為 (batch_size, num_labels) 的分類 logits。
Perceiver 作者表明,與主要為影像分類設計的模型(如 ResNet 或 ViT)相比,該模型能夠取得出色的結果。在 JFT 上進行大規模預訓練後,使用 conv+maxpool 預處理(`PerceiverForImageClassificationConvProcessing`)的模型在 ImageNet 上達到了 84.5 的 top-1 準確率。值得注意的是,`PerceiverForImageClassificationLearned`(僅使用 1D 完全學習的位置編碼的模型)達到了 72.7 的 top-1 準確率,儘管它沒有關於影像 2D 結構的特權資訊。
光流 Perceiver
作者們表明,Perceiver 也很容易應用於光流,這是一個計算機視覺領域存在數十年的問題,具有許多更廣泛的應用。有關光流的介紹,請參閱這篇部落格文章。給定同一場景的兩幅影像(例如,影片的兩個連續幀),任務是估計第一幅影像中每個畫素的二維位移。現有演算法通常是手工設計且複雜,但使用 Perceiver,這變得相對簡單。該模型已在 Transformers 庫中實現,並作為 `PerceiverForOpticalFlow` 提供。其實現如下
from torch import nn
from transformers import PerceiverModel
from transformers.models.perceiver.modeling_perceiver import PerceiverImagePreprocessor, PerceiverOpticalFlowDecoder
class PerceiverForOpticalFlow(nn.Module):
def __init__(self, config):
super().__init__(config)
fourier_position_encoding_kwargs_preprocessor = dict(
num_bands=64,
max_resolution=config.train_size,
sine_only=False,
concat_pos=True,
)
fourier_position_encoding_kwargs_decoder = dict(
concat_pos=True, max_resolution=config.train_size, num_bands=64, sine_only=False
)
image_preprocessor = PerceiverImagePreprocessor(
config,
prep_type="patches",
spatial_downsample=1,
conv_after_patching=True,
conv_after_patching_in_channels=54,
temporal_downsample=2,
position_encoding_type="fourier",
# position_encoding_kwargs
fourier_position_encoding_kwargs=fourier_position_encoding_kwargs_preprocessor,
)
self.perceiver = PerceiverModel(
config,
input_preprocessor=image_preprocessor,
decoder=PerceiverOpticalFlowDecoder(
config,
num_channels=image_preprocessor.num_channels,
output_image_shape=config.train_size,
rescale_factor=100.0,
use_query_residual=False,
output_num_channels=2,
position_encoding_type="fourier",
fourier_position_encoding_kwargs=fourier_position_encoding_kwargs_decoder,
),
)
如您所見,`PerceiverImagePreprocessor` 用作預處理器(即,準備 2 幅影像以進行與潛在變數的交叉注意力操作),`PerceiverOpticalFlowDecoder` 用作解碼器(即,將潛在變數的最終隱藏狀態解碼為實際預測流)。對於這 2 幀中的每一幀,作者提取每個畫素周圍的 3 x 3 影像塊,從而為每個畫素產生 3 x 3 x 3 = 27 個值(因為每個畫素也有 3 個顏色通道)。作者使用 (368, 496) 的訓練解析度。如果將每個訓練示例的 2 幀大小 (368, 496) 堆疊在一起,則模型的 `inputs` 形狀為 (batch_size, 2, 27, 368, 496)。
預處理器(使用上述設定)將首先沿通道維度連線幀,得到形狀為 (batch_size, 368, 496, 54) 的張量——假設還將通道維度移動到最後。作者在論文(第 8 頁)中解釋了為什麼沿通道維度連線是有意義的。接下來,空間維度被展平,得到形狀為 (batch_size, 368*496, 54) = (batch_size, 182528, 54) 的張量。然後,連線位置嵌入(每個位置嵌入的維度為 258),得到最終預處理後的輸入形狀為 (batch_size, 182528, 322)。這些將用於與潛在變數進行交叉注意力。
作者對光流模型使用 2048 個潛在變數(是的,2048 個!),每個潛在變數的維度為 512。因此,潛在變數的形狀為 (batch_size, 2048, 512)。在交叉注意力之後,我們再次得到一個相同形狀的張量(因為潛在變數充當查詢)。接下來,應用一個包含 24 個自注意力層(每個自注意力層有 16 個注意力頭)的單個塊來更新潛在變數的嵌入。
為了將潛在變數的最終隱藏狀態解碼為實際預測流,`PerceiverOpticalFlowDecoder` 只是將形狀為 (batch_size, 182528, 322) 的預處理輸入用作交叉注意力操作的查詢。接下來,將這些投影到形狀為 (batch_size, 182528, 2) 的張量。最後,我們將其重新縮放並重塑回原始影像大小,以獲得形狀為 (batch_size, 368, 496, 2) 的預測流。作者聲稱,在 AutoFlow(一個包含 400,000 對帶註釋影像的大型合成數據集)上進行訓練時,該模型在包括 Sintel 和 KITTI 在內的重要基準上取得了最先進的結果。
以下影片展示了兩個示例上的預測流。

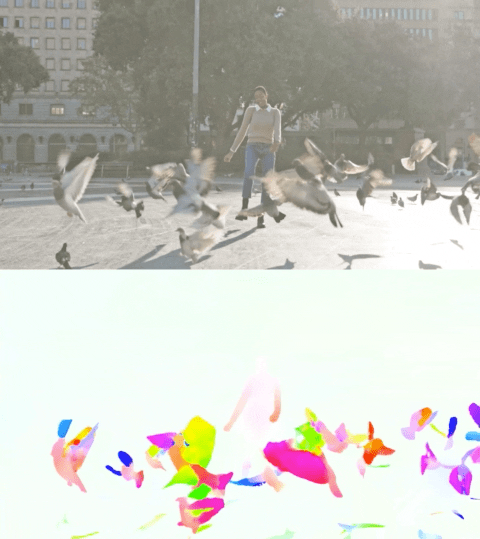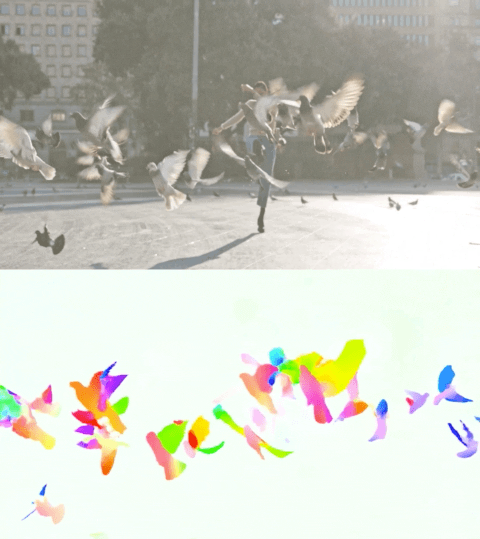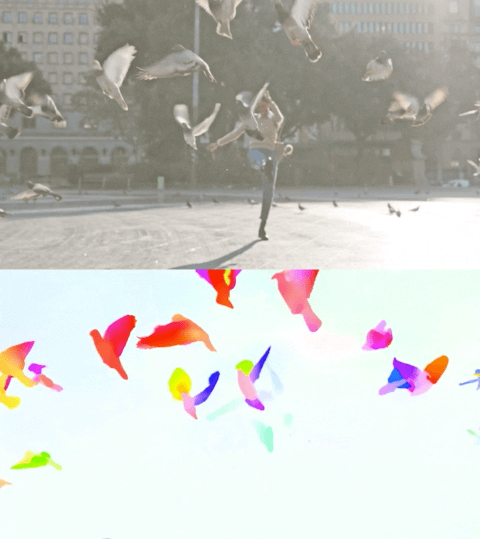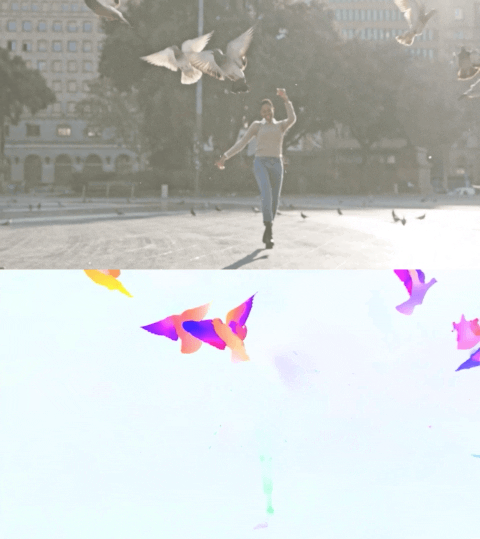
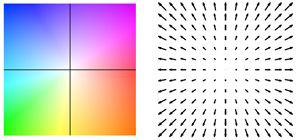
Perceiver IO 的光流估計。每個畫素的顏色表示模型估計的運動方向和速度,如右側圖例所示。
多模態自編碼 Perceiver
作者還使用 Perceiver 進行多模態自編碼。多模態自編碼的目標是學習一個模型,該模型能夠在架構瓶頸存在的情況下準確地重建多模態輸入。作者在 Kinetics-700 資料集上訓練模型,其中每個示例都包含一系列影像(即幀)、音訊和一個類別標籤(700 個可能的標籤之一)。該模型也已在 HuggingFace Transformers 中實現,並作為 `PerceiverForMultimodalAutoencoding` 提供。為簡潔起見,我將省略定義此模型的程式碼,但重要的是要注意,它使用 `PerceiverMultimodalPreprocessor` 為模型準備 `inputs`。此預處理器將首先分別使用每種模態(影像、音訊、標籤)各自的預處理器。假設影片有 16 幀,解析度為 224x224,以及 30,720 個音訊樣本,則模態預處理如下
- 使用 `PerceiverImagePreprocessor` 將影像(實際是一系列幀),形狀為 (batch_size, 16, 3, 224, 224),轉換為形狀為 (batch_size, 50176, 243) 的張量。這是一個“空間到深度”的轉換,之後連線固定的 2D 傅立葉位置嵌入。
- 音訊的形狀為 (batch_size, 30720, 1),使用 `PerceiverAudioPreprocessor`(它將固定的傅立葉位置嵌入連線到原始音訊)將其轉換為形狀為 (batch_size, 1920, 401) 的張量。
- 類別標籤的形狀為 (batch_size, 700),使用 `PerceiverOneHotPreprocessor` 轉換為形狀為 (batch_size, 1, 700) 的張量。換句話說,此預處理器只是添加了一個虛擬的時間(索引)維度。請注意,在評估期間,將類別標籤初始化為零張量,以便模型充當影片分類器。
接下來,`PerceiverMultimodalPreprocessor` 將使用模態特定的可訓練嵌入對預處理後的模態進行填充,以實現在時間維度上的連線。在這種情況下,通道維度最高的模態是類別標籤(它有 700 個通道)。作者強制最小填充大小為 4,因此每種模態都將填充到 704 個通道。然後可以連線它們,因此最終預處理後的輸入是一個形狀為 (batch_size, 50176 + 1920 + 1, 704) = (batch_size, 52097, 704) 的張量。
作者使用 784 個潛在變數,每個潛在變數的維度為 512。因此,潛在變數的形狀為 (batch_size, 784, 512)。在交叉注意力之後,我們再次得到一個相同形狀的張量(因為潛在變數充當查詢)。接下來,應用一個包含 8 個自注意力層(每個自注意力層有 8 個注意力頭)的單個塊來更新潛在變數的嵌入。
接下來是 `PerceiverMultimodalDecoder`,它將首先為每個模態單獨建立輸出查詢。然而,由於無法在單個前向傳播中解碼整個影片,作者轉而分塊自編碼。每個塊將對每個模態的某些索引維度進行子取樣。假設我們將影片處理成 128 個塊,那麼解碼器查詢將按如下方式生成
- 對於影像模態,解碼器查詢的總大小為 16x3x224x224 = 802,816。然而,在自編碼第一個塊時,我們對前 802,816/128 = 6272 個值進行子取樣。影像輸出查詢的形狀為 (batch_size, 6272, 195)——195 來自於使用了固定的傅立葉位置嵌入。
- 對於音訊模態,總輸入有 30,720 個值。但是,我們只對前 30720/128/16 = 15 個值進行子取樣。因此,音訊查詢的形狀為 (batch_size, 15, 385)。這裡,385 來自於使用了固定的傅立葉位置嵌入。
- 對於類別標籤模態,不需要進行子取樣。因此,子取樣索引設定為 1。標籤輸出查詢的形狀為 (batch_size, 1, 1024)。查詢使用可訓練的位置嵌入(大小為 1024)。
與預處理器類似,`PerceiverMultimodalDecoder` 將不同模態填充到相同的通道數,以使模態特定查詢可以在時間維度上進行連線。在這裡,類別標籤再次擁有最高的通道數 (1024),並且作者強制最小填充大小為 2,因此每個模態都將填充到 1026 個通道。連線後,最終解碼器查詢的形狀為 (batch_size, 6272 + 15 + 1, 1026) = (batch_size, 6288, 1026)。這個張量在交叉注意力操作中生成查詢,而潛在變數充當鍵和值。因此,交叉注意力操作的輸出是形狀為 (batch_size, 6288, 1026) 的張量。接下來,`PerceiverMultimodalDecoder` 使用一個線性層來減少輸出通道,得到形狀為 (batch_size, 6288, 512) 的張量。
最後,是 `PerceiverMultimodalPostprocessor`。該類對解碼器輸出進行後處理,以生成每種模態的實際重建。它首先根據不同的模態拆分解碼器輸出的時間維度:影像為 (batch_size, 6272, 512),音訊為 (batch_size, 15, 512),類別標籤為 (batch_size, 1, 512)。接下來,應用每種模態各自的後處理器
- 影像後處理器(在 Transformers 中稱為 `PerceiverProjectionPostprocessor`)簡單地將 (batch_size, 6272, 512) 張量轉換為形狀為 (batch_size, 6272, 3) 的張量——即它將最終維度投影到 RGB 值。
- `PerceiverAudioPostprocessor` 將 (batch_size, 15, 512) 張量轉換為形狀為 (batch_size, 240) 的張量。
- `PerceiverClassificationPostprocessor` 簡單地獲取第一個(也是唯一的)索引,得到形狀為 (batch_size, 700) 的張量。
所以現在我們得到了包含影像、音訊和類別標籤模態重建的張量。由於我們分塊自編碼整個影片,因此需要連線每個塊的重建,以獲得整個影片的最終重建。下圖顯示了一個示例


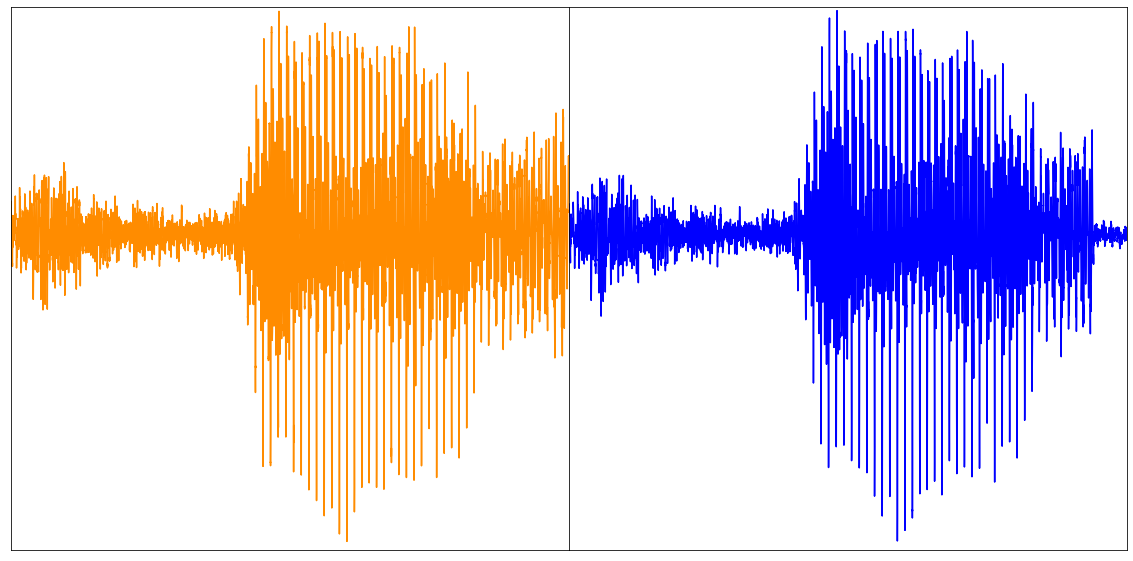
上圖:原始影片(左),前 16 幀的重建(右)。影片取自 UCF101 資料集。下圖:重建音訊(取自論文)。
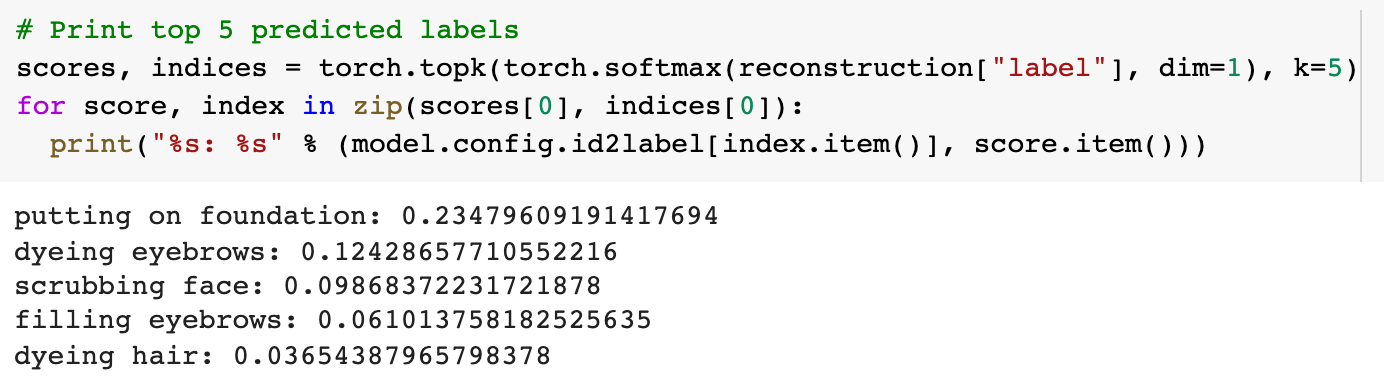
上述影片的預測標籤前 5 名。透過掩碼類別標籤,Perceiver 變成了一個影片分類器。
透過這種方法,模型學習了 3 種模態的聯合分佈。作者指出,由於潛在變數在模態之間共享且未明確分配,因此每種模態的重建質量對其損失項的權重和其他訓練超引數敏感。透過更強調分類準確性,他們能夠在影片中達到 45% 的 top-1 準確性,同時保持 20.7 PSNR(峰值信噪比)。
Perceiver 的其他應用
請注意,Perceiver 的應用沒有限制!在最初的 Perceiver 論文中,作者展示了該架構可用於處理 3D 點雲——這是配備雷射雷達感測器的自動駕駛汽車的常見問題。他們在 ModelNet40(一個包含 40 種物體類別的 3D 三角網格派生點雲資料集)上訓練了該模型。結果表明,該模型在測試集上達到了 85.7% 的 top-1 準確率,與 PointNet++(一個高度專業化、使用額外幾何特徵並執行更高階增強的模型)相媲美。
作者還用 Perceiver 替換了 AlphaStar(用於複雜遊戲《星際爭霸 II》的最先進強化學習系統)中的原始 Transformer。在不調整任何額外引數的情況下,作者觀察到由此產生的代理達到了與原始 AlphaStar 代理相同的效能水平,在人類資料上進行行為克隆後,與精英機器人對戰的勝率達到 87%。
重要的是,目前實現的模型(如 `PerceiverForImageClassificationLearned`、`PerceiverForOpticalFlow`)只是您可以使用 Perceiver 實現的示例。這些都是 `PerceiverModel` 的不同例項,只是使用了不同的預處理器和/或解碼器(以及可選的後處理器,例如多模態自編碼)。人們可以提出新的預處理器、解碼器和後處理器,使模型解決不同的問題。例如,可以將 Perceiver 擴充套件到執行命名實體識別 (NER) 或問答(類似於 BERT),音訊分類(類似於 Wav2Vec2)或目標檢測(類似於 DETR)。
結論
在這篇部落格文章中,我們回顧了 Perceiver IO 的架構,它是 Google Deepmind Perceiver 的一個擴充套件,並展示了其處理各種模態的通用性。Perceiver 的最大優勢在於,自注意力機制的計算和記憶體需求不依賴於輸入和輸出的大小,因為大部分計算發生在潛在空間中(一組不太大的向量)。儘管其架構與任務無關,但該模型能夠有效地處理語言、視覺、多模態資料和點雲等模態。未來,同時訓練一個單一的(共享的)Perceiver 編碼器處理多種模態,並使用模態特定的預處理器和後處理器,可能會很有趣。正如 Karpathy 所說,這種架構很可能能夠將所有模態統一到一個共享空間中,並配備一個編碼器/解碼器庫。
說到庫,該模型自今天起可在 HuggingFace Transformers 中使用。它將令人興奮地看到人們用它構建什麼,因為它的應用似乎無窮無盡!
附錄
HuggingFace Transformers 中的實現基於原始的 JAX/Haiku 實現,可在此處找到。
HuggingFace Transformers 中 Perceiver IO 模型的文件可在此處找到。
關於多種模態 Perceiver 的教程筆記本可在此處找到。
腳註
1 請注意,在官方論文中,作者使用了一個兩層 MLP 來生成輸出 logits,這裡為簡潔起見省略了。 ↩






