在 PyTorch / XLA TPU 上執行 Hugging Face:更快更便宜的訓練





使用 PyTorch / XLA 在雲 TPU 上訓練你最喜歡的 Transformers 模型
PyTorch-TPU 專案最初是 Facebook PyTorch 和 Google TPU 團隊的合作專案,並於 2019 年 PyTorch 開發者大會上正式啟動。從那時起,我們與 Hugging Face 團隊合作,為使用 PyTorch / XLA 在雲 TPU 上進行訓練提供了一流的支援。這項新的整合使得 PyTorch 使用者能夠在雲 TPU 上執行和擴充套件他們的模型,同時保持與 Hugging Face 訓練器完全相同的介面。
這篇博文概述了 Hugging Face 庫中所做的更改,PyTorch / XLA 庫的功能,一個讓你開始在雲 TPU 上訓練你最喜歡的 transformers 的例子,以及一些效能基準。如果你迫不及待地想開始使用 TPU,請直接跳到“在雲 TPU 上訓練你的 Transformer”部分——我們在 Trainer 模組中為你處理了所有 PyTorch / XLA 的機制!
XLA:TPU 裝置型別
PyTorch / XLA 為 PyTorch 添加了一種新的 xla 裝置型別。這種裝置型別的工作方式與其他 PyTorch 裝置型別一樣。例如,以下是如何建立和列印一個 XLA 張量
import torch
import torch_xla
import torch_xla.core.xla_model as xm
t = torch.randn(2, 2, device=xm.xla_device())
print(t.device)
print(t)
這段程式碼應該看起來很熟悉。PyTorch / XLA 使用與常規 PyTorch 相同的介面,並增加了一些內容。匯入 torch_xla 會初始化 PyTorch / XLA,而 xm.xla_device() 會返回當前的 XLA 裝置。根據你的環境,這可能是 CPU、GPU 或 TPU,但在本文中,我們將主要關注 TPU。
Trainer 模組利用一個 TrainingArguments 資料類來定義訓練的具體細節。它處理多個引數,從批次大小、學習率、梯度累積等,到所使用的裝置。基於以上內容,在 TrainingArguments._setup_devices() 中使用 XLA:TPU 裝置時,我們只需返回要由 Trainer 使用的 TPU 裝置即可。
@dataclass
class TrainingArguments:
...
@cached_property
@torch_required
def _setup_devices(self) -> Tuple["torch.device", int]:
...
elif is_torch_tpu_available():
device = xm.xla_device()
n_gpu = 0
...
return device, n_gpu
XLA 裝置上的單步計算
在典型的 XLA:TPU 訓練場景中,我們在多個 TPU 核心上並行訓練(一個雲 TPU 裝置包含 8 個 TPU 核心)。因此,我們需要確保透過合併梯度和執行最佳化器步驟,在資料並行副本之間交換所有梯度。為此,我們提供了 xm.optimizer_step(optimizer),它負責梯度合併和步進。在 Hugging Face 訓練器中,我們相應地更新了訓練步驟以使用 PyTorch / XLA API
class Trainer:
…
def train(self, *args, **kwargs):
...
if is_torch_tpu_available():
xm.optimizer_step(self.optimizer)
PyTorch / XLA 輸入管道
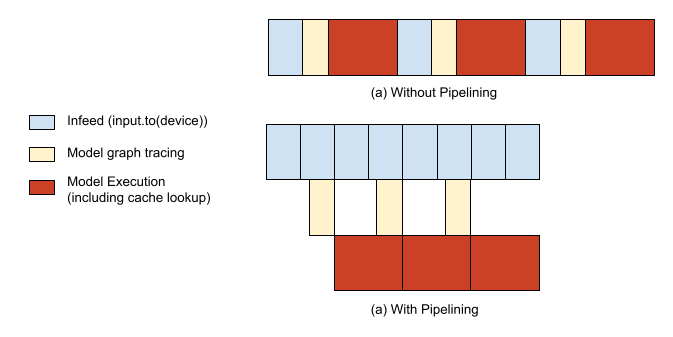
執行 PyTorch / XLA 模型主要有兩個部分:(1)惰性地追蹤和執行模型的計算圖(更深入的解釋請參考下面的 “PyTorch / XLA 庫” 部分)和(2)為你的模型提供資料。如果沒有任何最佳化,模型的追蹤/執行和輸入供給將序列執行,導致主機 CPU 和 TPU 加速器分別出現空閒時間段。為了避免這種情況,我們提供了一個 API,將這兩者流水線化,從而能夠在第 n 步仍在執行時,重疊進行第 n+1 步的追蹤。
import torch_xla.distributed.parallel_loader as pl
...
dataloader = pl.MpDeviceLoader(dataloader, device)
檢查點的寫入和載入
當一個張量從 XLA 裝置儲存為檢查點,然後從檢查點載入回來時,它將被載入回原始裝置。在為模型中的張量建立檢查點之前,你需要確保所有的張量都在 CPU 裝置上,而不是在 XLA 裝置上。這樣,當你載入回張量時,你會透過 CPU 裝置載入它們,然後有機會將它們放置到你希望的任何 XLA 裝置上。我們為此提供了 xm.save() API,它已經處理了只從每個主機上的一個程序(如果使用跨主機的共享檔案系統,則全域性只有一個)寫入儲存位置的問題。
class PreTrainedModel(nn.Module, ModuleUtilsMixin, GenerationMixin):
…
def save_pretrained(self, save_directory):
...
if getattr(self.config, "xla_device", False):
import torch_xla.core.xla_model as xm
if xm.is_master_ordinal():
# Save configuration file
model_to_save.config.save_pretrained(save_directory)
# xm.save takes care of saving only from master
xm.save(state_dict, output_model_file)
class Trainer:
…
def train(self, *args, **kwargs):
...
if is_torch_tpu_available():
xm.rendezvous("saving_optimizer_states")
xm.save(self.optimizer.state_dict(),
os.path.join(output_dir, "optimizer.pt"))
xm.save(self.lr_scheduler.state_dict(),
os.path.join(output_dir, "scheduler.pt"))
PyTorch / XLA 庫
PyTorch / XLA 是一個 Python 包,它使用 XLA 線性代數編譯器將 PyTorch 深度學習框架與 XLA 裝置(包括 CPU、GPU 和雲 TPU)連線起來。以下部分內容也見於我們的 API_GUIDE.md。
PyTorch / XLA 張量是惰性的
使用 XLA 張量和裝置只需要更改幾行程式碼。然而,儘管 XLA 張量的行為很像 CPU 和 CUDA 張量,但它們的內部機制是不同的。CPU 和 CUDA 張量會立即或“急切地”啟動操作。而 XLA 張量則是“惰性”的。它們會將操作記錄在一個圖中,直到需要結果時才執行。像這樣延遲執行可以讓 XLA 對其進行最佳化。一個由多個獨立操作組成的圖可能會被融合成一個單一的最佳化操作。
惰性執行對呼叫者來說通常是不可見的。PyTorch / XLA 會自動構建圖,將它們傳送到 XLA 裝置,並在 XLA 裝置和 CPU 之間複製資料時進行同步。在執行最佳化器步驟時插入一個屏障會顯式地同步 CPU 和 XLA 裝置。
這意味著當你呼叫 model(input) 進行前向傳播,計算損失 loss.backward(),並執行最佳化步驟 xm.optimizer_step(optimizer) 時,所有操作的圖都在後臺構建。只有當你顯式地評估張量(例如列印張量或將其移動到 CPU 裝置)或標記一個步驟(每次迭代 MpDeviceLoader 時都會這樣做)時,完整的步驟才會被執行。
追蹤、編譯、執行,並重復
從使用者的角度來看,在 PyTorch / XLA 上執行模型的典型訓練方案包括執行前向傳播、後向傳播和最佳化器步驟。從 PyTorch / XLA 庫的角度來看,情況略有不同。
當用戶執行他們的前向和後向傳播時,一箇中間表示(IR)圖會動態地被追蹤。通向每個根/輸出張量的 IR 圖可以如下檢查
>>> import torch
>>> import torch_xla
>>> import torch_xla.core.xla_model as xm
>>> t = torch.tensor(1, device=xm.xla_device())
>>> s = t*t
>>> print(torch_xla._XLAC._get_xla_tensors_text([s]))
IR {
%0 = s64[] prim::Constant(), value=1
%1 = s64[] prim::Constant(), value=0
%2 = s64[] xla::as_strided_view_update(%1, %0), size=(), stride=(), storage_offset=0
%3 = s64[] aten::as_strided(%2), size=(), stride=(), storage_offset=0
%4 = s64[] aten::mul(%3, %3), ROOT=0
}
當用戶程式執行前向和後向傳播時,這個即時圖會不斷累積,一旦呼叫 xm.mark_step()(由 pl.MpDeviceLoader 間接呼叫),即時張量的圖就會被切斷。這種截斷標誌著一個步驟的完成,隨後我們將 IR 圖降級為 XLA 高階操作(HLO),這是 XLA 的 IR 語言。
然後,這個 HLO 圖被編譯成 TPU 二進位制檔案,並隨後在 TPU 裝置上執行。然而,這個編譯步驟可能成本很高,通常比單個步驟耗時更長,所以如果我們每一步都編譯使用者的程式,開銷會很大。為了避免這種情況,我們有快取來儲存已編譯的 TPU 二進位制檔案,這些二進位制檔案以其 HLO 圖的唯一雜湊識別符號為鍵。因此,一旦這個 TPU 二進位制快取 populated 在第一步被填充,後續的步驟通常不必重新編譯新的 TPU 二進位制檔案;相反,它們可以簡單地從快取中查詢必要的二進位制檔案。
由於 TPU 編譯通常比步驟執行時間慢得多,這意味著如果圖的形狀不斷變化,我們將會出現快取未命中並過於頻繁地編譯。為了最小化編譯成本,我們建議儘可能保持張量形狀的靜態。Hugging Face 庫的形狀大部分已經是靜態的,輸入標記會進行適當的填充,因此在整個訓練過程中,快取應該會持續命中。這可以使用 PyTorch / XLA 提供的除錯工具來檢查。在下面的例子中,你可以看到編譯只發生了 5 次(CompileTime),而執行則在 1220 個步驟中的每一步都發生了(ExecuteTime)。
>>> import torch_xla.debug.metrics as met
>>> print(met.metrics_report())
Metric: CompileTime
TotalSamples: 5
Accumulator: 28s920ms153.731us
ValueRate: 092ms152.037us / second
Rate: 0.0165028 / second
Percentiles: 1%=428ms053.505us; 5%=428ms053.505us; 10%=428ms053.505us; 20%=03s640ms888.060us; 50%=03s650ms126.150us; 80%=11s110ms545.595us; 90%=11s110ms545.595us; 95%=11s110ms545.595us; 99%=11s110ms545.595us
Metric: DeviceLockWait
TotalSamples: 1281
Accumulator: 38s195ms476.007us
ValueRate: 151ms051.277us / second
Rate: 4.54374 / second
Percentiles: 1%=002.895us; 5%=002.989us; 10%=003.094us; 20%=003.243us; 50%=003.654us; 80%=038ms978.659us; 90%=192ms495.718us; 95%=208ms893.403us; 99%=221ms394.520us
Metric: ExecuteTime
TotalSamples: 1220
Accumulator: 04m22s555ms668.071us
ValueRate: 923ms872.877us / second
Rate: 4.33049 / second
Percentiles: 1%=045ms041.018us; 5%=213ms379.757us; 10%=215ms434.912us; 20%=217ms036.764us; 50%=219ms206.894us; 80%=222ms335.146us; 90%=227ms592.924us; 95%=231ms814.500us; 99%=239ms691.472us
Counter: CachedCompile
Value: 1215
Counter: CreateCompileHandles
Value: 5
...
在雲 TPU 上訓練你的 Transformer
要配置您的 VM 和雲 TPU,請遵循 “設定計算引擎例項” 和 “啟動雲 TPU 資源”(撰寫本文時為 pytorch-1.7 版本)部分。一旦您建立了 VM 和雲 TPU,使用它們就像透過 SSH 連線到您的 GCE VM 並執行以下命令來啟動 bert-large-uncased 訓練一樣簡單(批次大小適用於 v3-8 裝置,在 v2-8 上可能會記憶體溢位)
conda activate torch-xla-1.7
export TPU_IP_ADDRESS="ENTER_YOUR_TPU_IP_ADDRESS" # ex. 10.0.0.2
export XRT_TPU_CONFIG="tpu_worker;0;$TPU_IP_ADDRESS:8470"
git clone -b v4.2.2 https://github.com/huggingface/transformers.git
cd transformers && pip install .
pip install datasets==1.2.1
python examples/xla_spawn.py \
--num_cores 8 \
examples/language-modeling/run_mlm.py \
--dataset_name wikitext \
--dataset_config_name wikitext-103-raw-v1 \
--max_seq_length 512 \
--pad_to_max_length \
--logging_dir ./tensorboard-metrics \
--cache_dir ./cache_dir \
--do_train \
--do_eval \
--overwrite_output_dir \
--output_dir language-modeling \
--overwrite_cache \
--tpu_metrics_debug \
--model_name_or_path bert-large-uncased \
--num_train_epochs 3 \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 8 \
--save_steps 500000
上述訓練應在大約不到 200 分鐘內完成,評估困惑度約為 3.25。
效能基準測試
下表顯示了在執行 PyTorch / XLA 的 v3-8 雲 TPU 系統(包含 4 個 TPU v3 晶片)上訓練 bert-large-uncased 的效能。所有基準測試測量使用的資料集是 WikiText103 資料集,我們使用 Hugging Face 示例中提供的 run_mlm.py 指令碼。為確保工作負載不受主機 CPU 限制,我們在這些測試中使用了 n1-standard-96 CPU 配置,但您也可以使用較小的配置而不會影響效能。
| 名稱 | 資料集 | 硬體 | 全域性批次大小 | 精度 | 訓練時間(分鐘) |
|---|---|---|---|---|---|
| bert-large-uncased | WikiText103 | 4 個 TPUv3 晶片 (即 v3-8) | 64 | FP32 | 178.4 |
| bert-large-uncased | WikiText103 | 4 個 TPUv3 晶片 (即 v3-8) | 128 | BF16 | 106.4 |
開始在 TPU 上使用 PyTorch / XLA
請參閱 Hugging Face 示例下的 “在 TPU 上執行” 部分以開始使用。有關我們 API 的更詳細描述,請檢視我們的 API 指南,有關效能最佳實踐,請參閱我們的 故障排除指南。對於通用的 PyTorch / XLA 示例,請執行我們提供的 Colab 筆記本,它們提供免費的雲 TPU 訪問。要直接在 GCP 上執行,請參閱我們文件網站上標記為“PyTorch”的教程。
還有其他問題嗎?請在 https://github.com/huggingface/transformers/issues 或直接在 https://github.com/pytorch/xla/issues 上提出問題。