在至強(Xeon)平臺上藉助 🤗 Optimum Intel 實現 SetFit 的超快推理












如何處理訓練中標註資料不足的問題是建模中常見的一大挑戰,而 SetFit 是一個很有前景的解決方案。SetFit 由 Hugging Face 的研究合作伙伴 英特爾實驗室 和 UKP 實驗室 共同開發,是一個用於 Sentence Transformers 模型的小樣本微調的高效框架。
SetFit 只需少量標註資料就能實現高準確率——例如,在 Banking 77 金融意圖資料集上,SetFit 的 3-shot 效能 優於 GPT-3.5 的 3-shot prompt,而 5-shot 效能也優於 GPT-4 的 3-shot prompt。
與基於大語言模型(LLM)的方法相比,SetFit 有兩個獨特的優勢
🗣 無需提示詞(prompt)或言語化(verbaliser):基於大語言模型的小樣本上下文學習需要手工製作提示詞,這使得結果不穩定,對措辭敏感,且依賴於使用者的專業知識。SetFit 透過直接從少量帶標籤的文字示例中生成豐富的嵌入向量,完全省去了提示詞。
🏎 訓練速度快:SetFit 不依賴於 GPT-3.5 或 Llama2 等大語言模型來實現高準確率。因此,其訓練和推理速度通常快一個數量級(或更多)。
有關 SetFit 的更多詳細資訊,請檢視我們的論文、部落格、程式碼和資料。
Setfit 已被 AI 開發者社群廣泛採用,每月下載量約 10 萬次,Hub 上有約 1500 個 SetFit 模型,並且以平均每天約 4 個模型的速度增長!
更快!
在這篇博文中,我們將解釋如何透過使用 🤗 Optimum Intel 最佳化你的 SetFit 模型,在英特爾 CPU 上將 SetFit 的推理速度提升 7.8 倍。我們將展示如何透過對模型進行簡單的訓練後量化步驟來實現巨大的吞吐量提升。這使得在英特爾至強(Xeon)CPU 上部署生產級的 SetFit 解決方案成為可能。
Optimum Intel 是一個開源庫,可在英特爾硬體上加速使用 Hugging Face 庫構建的端到端流水線。Optimum Intel 包含多種加速模型的技術,如低位元量化、模型權重剪枝、蒸餾和加速執行時。
Optimum Intel 中包含的執行時和最佳化利用了英特爾 CPU 上的英特爾® 高階向量擴充套件 512(Intel® AVX-512)、向量神經網路指令(VNNI)和英特爾® 高階矩陣擴充套件(Intel® AMX)來加速模型。具體來說,它在每個核心中都內建了 BFloat16 (bf16) 和 int8 GEMM 加速器,以加速深度學習訓練和推理工作負載。AMX 加速推理在 PyTorch 2.0 和 Intel Extension for PyTorch (IPEX) 中引入,此外還為各種常見運算元提供了其他最佳化。
使用 Optimum Intel 可以輕鬆最佳化預訓練模型;許多簡單的示例可以在這裡找到。我們的部落格附帶了一個notebook,提供了逐步的演練。
第一步:使用 🤗 Optimum Intel 量化 SetFit 模型
為了最佳化我們的 SetFit 模型,我們將使用 Optimum Intel 的一部分——英特爾神經壓縮器 (Intel Neural Compressor, INC),對模型主體進行量化。
量化是一種非常流行的深度學習模型最佳化技術,用於提高推理速度。它透過將一組高精度數值轉換為低位元資料表示(例如 INT8),來最小化表示神經網路中權重和/或啟用值所需的位元數。此外,量化可以在較低精度下實現更快的計算。
具體來說,我們將應用訓練後靜態量化(Post-Training Static Quantization, PTQ)。PTQ 可以在僅使用一個小的未標記校準集且無需任何訓練的情況下,減少記憶體佔用和推理延遲,同時保持模型的準確性。在開始之前,請確保你已安裝所有必要的庫,並且你的 Optimum Intel 版本至少是 1.14.0,因為該功能是在此版本中引入的。
pip install --upgrade-strategy eager optimum[ipex]
準備校準資料集
校準資料集應該能夠代表未見資料的分佈。一般來說,準備 100 個樣本就足以進行校準。在我們的案例中,我們將使用 rotten_tomatoes 資料集,因為它由電影評論組成,與我們的目標資料集 sst2 類似。
首先,我們將從該資料集中載入 100 個隨機樣本。然後,為了準備用於量化的資料集,我們需要對每個示例進行分詞。我們不需要 “text” 和 “label” 列,所以將它們移除。
calibration_set = load_dataset("rotten_tomatoes", split="train").shuffle(seed=42).select(range(100))
def tokenize(examples):
return tokenizer(examples["text"], padding="max_length", max_length=512, truncation=True)
tokenizer = setfit_model.model_body.tokenizer
calibration_set = calibration_set.map(tokenize, remove_columns=["text", "label"])
執行量化
在執行量化之前,我們需要定義所需的量化過程——在我們的案例中是靜態訓練後量化(Static Post Training Quantization),並使用 optimum.intel 在我們的校準資料集上執行量化。
from optimum.intel import INCQuantizer
from neural_compressor.config import PostTrainingQuantConfig
setfit_body = setfit_model.model_body[0].auto_model
quantizer = INCQuantizer.from_pretrained(setfit_body)
optimum_model_path = "/tmp/bge-small-en-v1.5_setfit-sst2-english_opt"
quantization_config = PostTrainingQuantConfig(approach="static", backend="ipex", domain="nlp")
quantizer.quantize(
quantization_config=quantization_config,
calibration_dataset=calibration_set,
save_directory=optimum_model_path,
batch_size=1,
)
tokenizer.save_pretrained(optimum_model_path)
就是這樣!我們現在有了一個本地的量化 SetFit 模型副本。讓我們來測試一下吧。
第二步:推理效能基準測試
在我們的 notebook 中,我們設定了一個 PerformanceBenchmark 類來計算模型的延遲和吞吐量,以及準確率指標。讓我們用它來對我們的 Optimum Intel 模型與其他兩種常用方法進行基準測試。
- 使用 PyTorch 和 🤗 Transformers 庫(fp32)。
- 使用 Intel Extension for PyTorch (IPEX) 執行時(bf16),並使用 TorchScript 跟蹤模型。
載入我們的測試資料集 sst2,並使用 PyTorch 和 🤗 Transformers 庫執行基準測試。
from datasets import load_dataset
from setfit import SetFitModel
test_dataset = load_dataset("SetFit/sst2")["validation"]
model_path = "dkorat/bge-small-en-v1.5_setfit-sst2-english"
setfit_model = SetFitModel.from_pretrained(model_path)
pb = PerformanceBenchmark(
model=setfit_model,
dataset=test_dataset,
optim_type="bge-small (transformers)",
)
perf_metrics = pb.run_benchmark()
對於第二個基準測試,我們將使用 Intel Extension for PyTorch (IPEX),採用 bf16 精度和 TorchScript 跟蹤。要使用 IPEX,我們只需匯入 IPEX 庫,並對目標模型應用 ipex.optimize(),在我們的案例中,目標模型是 SetFit 的(transformer)模型主體。
dtype = torch.bfloat16
body = ipex.optimize(setfit_model.model_body, dtype=dtype)
對於 TorchScript 跟蹤,我們根據模型的最大輸入長度生成一個隨機序列,其中的詞符(token)從分詞器的詞彙表中取樣。
tokenizer = setfit_model.model_body.tokenizer
d = generate_random_sequences(batch_size=1, length=tokenizer.model_max_length, vocab_size=tokenizer.vocab_size)
body = torch.jit.trace(body, (d,), check_trace=False, strict=False)
setfit_model.model_body = torch.jit.freeze(body)
現在讓我們用量化後的 Optimum 模型來執行基準測試。我們首先需要為我們的 SetFit 模型定義一個包裝器,該包裝器在推理時插入我們量化後的模型主體(而不是原始的模型主體)。然後,我們可以使用這個包裝器來執行基準測試。
from optimum.intel import IPEXModel
class OptimumSetFitModel:
def __init__(self, setfit_model, model_body):
model_body.tokenizer = setfit_model.model_body.tokenizer
self.model_body = model_body
self.model_head = setfit_model.model_head
optimum_model = IPEXModel.from_pretrained(optimum_model_path)
optimum_setfit_model = OptimumSetFitModel(setfit_model, model_body=optimum_model)
pb = PerformanceBenchmark(
model=optimum_setfit_model,
dataset=test_dataset,
optim_type=f"bge-small (optimum-int8)",
model_path=optimum_model_path,
autocast_dtype=torch.bfloat16,
)
perf_metrics.update(pb.run_benchmark())
結果
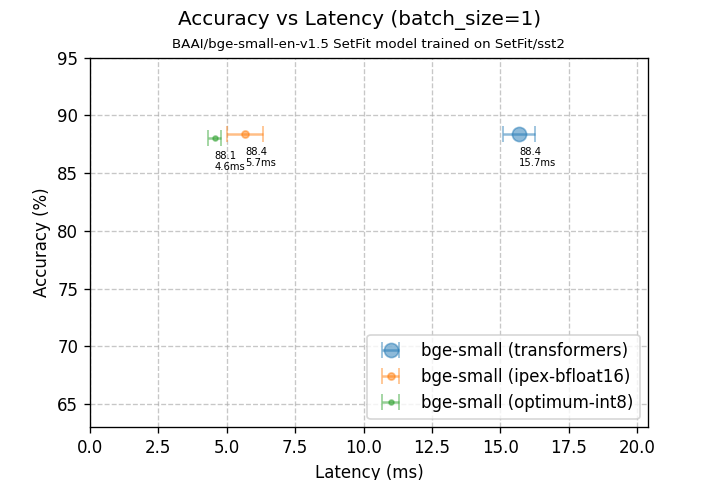
批處理大小=1 時的準確率 vs 延遲
| bge-small (transformers) | bge-small (ipex-bfloat16) | bge-small (optimum-int8) | |
|---|---|---|---|
| 模型大小 | 127.32 MB | 63.74 MB | 44.65 MB |
| 在測試集上的準確率 | 88.4% | 88.4% | 88.1% |
| 延遲 (bs=1) | 15.69 +/- 0.57 毫秒 | 5.67 +/- 0.66 毫秒 | 4.55 +/- 0.25 毫秒 |
在批處理大小為 1 的情況下,我們最佳化後的模型延遲降低了 3.45 倍。請注意,這是在幾乎沒有準確率下降的情況下實現的!還值得一提的是,模型大小縮小了 2.85 倍。
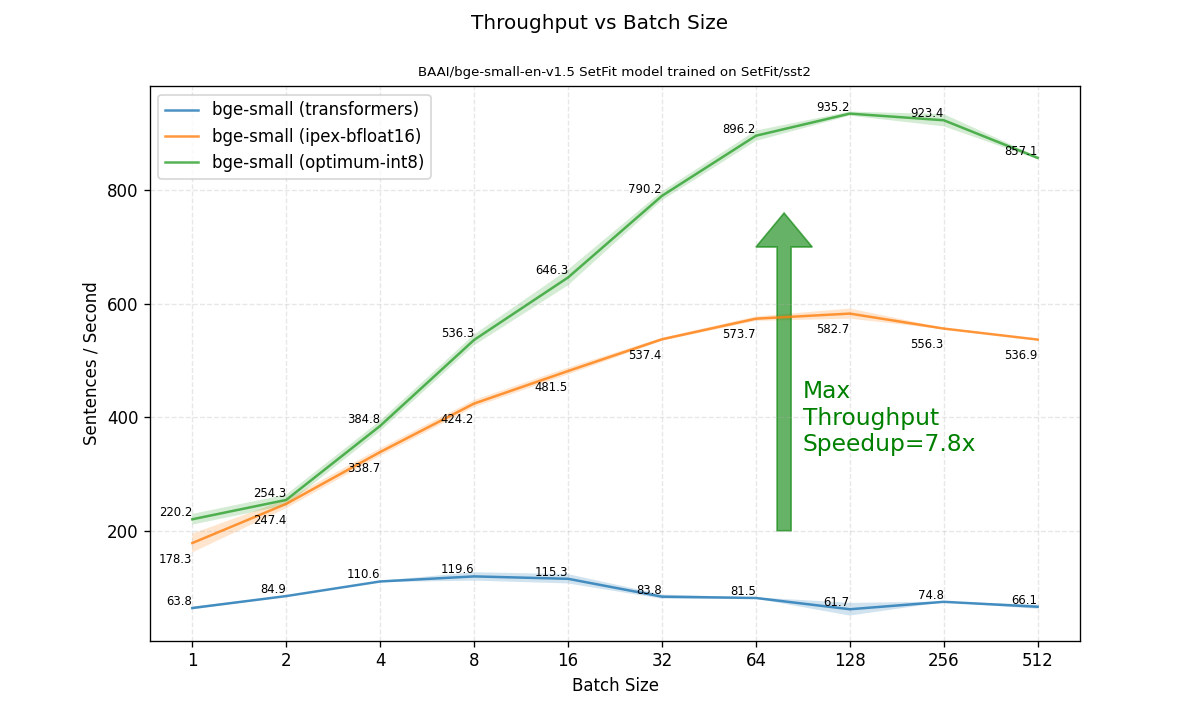
接下來我們關注的重點是在不同批處理大小下的吞吐量。在這裡,最佳化帶來了更大的速度提升。當比較可達到的最高吞吐量(在任何批處理大小下)時,最佳化後的模型比原始的 transformers fp32 模型快了 7.8 倍!
總結
在這篇博文中,我們展示瞭如何使用 🤗 Optimum Intel 中的量化功能來最佳化 SetFit 模型。在運行了一個快速簡便的訓練後量化過程後,我們觀察到準確率水平得到了保持,而推理吞吐量則提高了 7.8 倍。這種最佳化方法可以輕鬆應用於任何在英特爾至強(Xeon)上執行的現有 SetFit 部署。
參考文獻
- Lewis Tunstall, Nils Reimers, Unso Eun Seo Jo, Luke Bates, Daniel Korat, Moshe Wasserblat, Oren Pereg, 2022. "Efficient Few-Shot Learning Without Prompts". https://arxiv.org/abs/2209.11055





