使用Streamlit在Hugging Face Spaces上託管您的模型和資料集







使用 Streamlit 在 Hugging Face Spaces 上展示您的資料集和模型
Streamlit 允許您以簡潔的方式視覺化資料集並構建機器學習模型演示。在這篇博文中,我們將引導您在 Hugging Face Spaces 中託管模型和資料集,並提供 Streamlit 應用程式。
為您的模型構建演示
您可以使用 Streamlit 載入任何 Hugging Face 模型並構建炫酷的 UI。在這個特殊的例子中,我們將一起重現 “與 Transformer 一起寫作”。它是一個允許您使用 GPT-2 和 XLNet 等 Transformer 編寫任何內容的應用程式。
我們不會深入探討推理的工作原理。您只需要知道,對於這個特定的應用程式,您需要指定一些超引數值。Streamlit 提供了許多 元件,讓您可以輕鬆實現自定義應用程式。我們將使用其中的一些元件來接收推理程式碼中必要的超引數。
.text_area元件建立了一個漂亮的區域,用於輸入要完成的句子。- Streamlit 的
.sidebar方法允許您在側邊欄中接受變數。 slider用於獲取連續值。不要忘記給slider一個步長,否則它會將值視為整數。- 您可以使用
number_input讓終端使用者輸入整數值。
import streamlit as st
# adding the text that will show in the text box as default
default_value = "See how a modern neural network auto-completes your text 🤗 This site, built by the Hugging Face team, lets you write a whole document directly from your browser, and you can trigger the Transformer anywhere using the Tab key. Its like having a smart machine that completes your thoughts 😀 Get started by typing a custom snippet, check out the repository, or try one of the examples. Have fun!"
sent = st.text_area("Text", default_value, height = 275)
max_length = st.sidebar.slider("Max Length", min_value = 10, max_value=30)
temperature = st.sidebar.slider("Temperature", value = 1.0, min_value = 0.0, max_value=1.0, step=0.05)
top_k = st.sidebar.slider("Top-k", min_value = 0, max_value=5, value = 0)
top_p = st.sidebar.slider("Top-p", min_value = 0.0, max_value=1.0, step = 0.05, value = 0.9)
num_return_sequences = st.sidebar.number_input('Number of Return Sequences', min_value=1, max_value=5, value=1, step=1)
推理程式碼返回生成的輸出,您可以使用簡單的 st.write 列印輸出。st.write(generated_sequences[-1])
這是我們複製的版本。 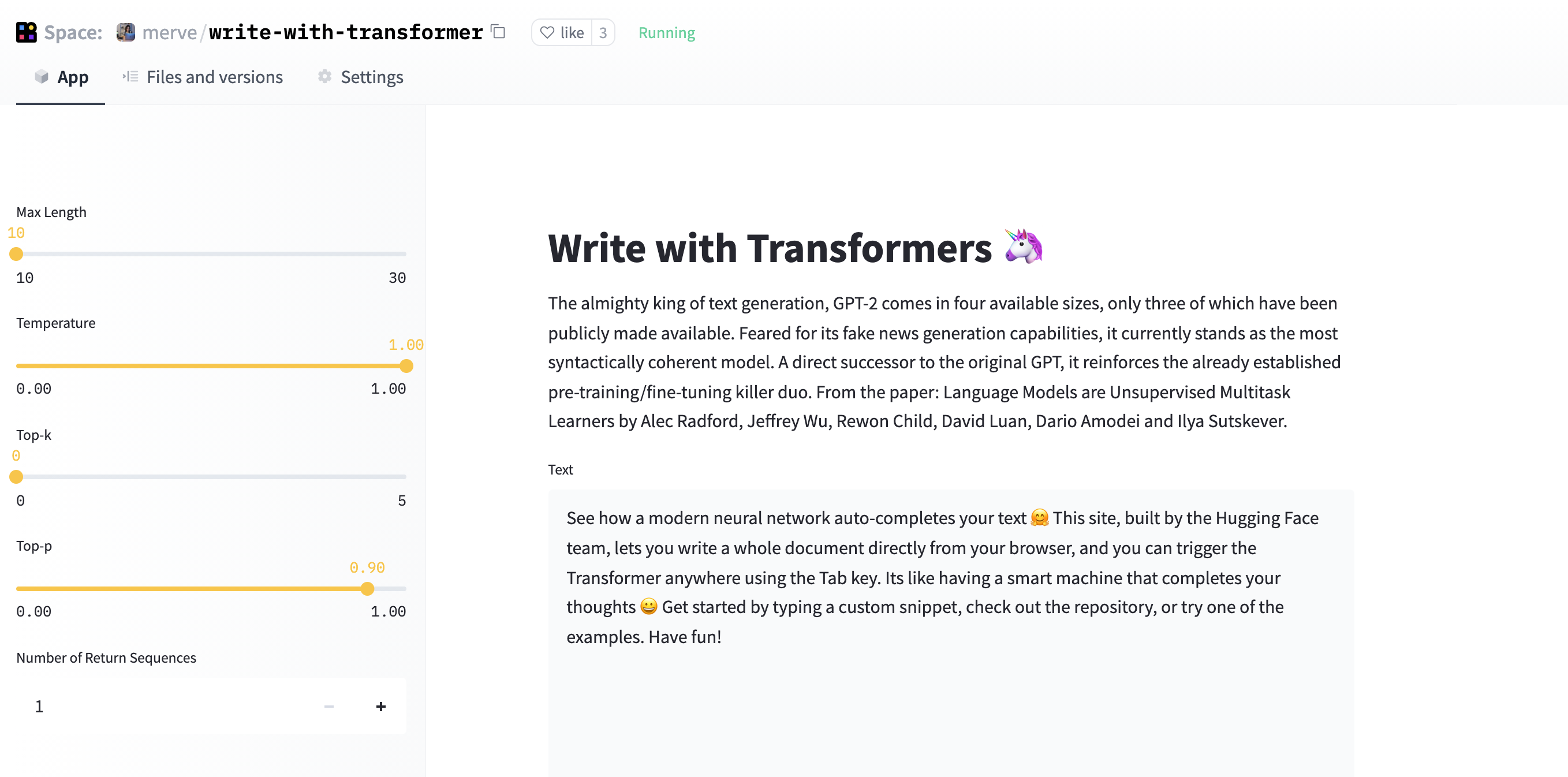
您可以在此處檢視完整程式碼。
展示您的資料集和資料視覺化
Streamlit 提供了許多元件來幫助您視覺化資料集。它與 🤗 Datasets、pandas 以及 matplotlib、seaborn 和 bokeh 等視覺化庫無縫協作。
讓我們從載入資料集開始。Datasets 中的一項新功能,稱為流式傳輸,允許您立即處理非常大的資料集,無需下載所有示例並將其載入到記憶體中。
from datasets import load_dataset
import streamlit as st
dataset = load_dataset("merve/poetry", streaming=True)
df = pd.DataFrame.from_dict(dataset["train"])
如果您有像我這樣的結構化資料,您可以簡單地使用 st.dataframe(df) 來顯示您的資料集。Streamlit 有許多元件可以互動式地繪製資料。其中一個元件是 st.barchart(),我用它來視覺化詩歌內容中最常用的單詞。
st.write("Most appearing words including stopwords")
st.bar_chart(words[0:50])
如果您想使用 matplotlib、seaborn 或 bokeh 等庫,您所要做的就是在繪圖指令碼的末尾加上 st.pyplot()。
st.write("Number of poems for each author")
sns.catplot(x="author", data=df, kind="count", aspect = 4)
plt.xticks(rotation=90)
st.pyplot()
您可以在下面看到互動式條形圖、資料框元件以及託管的 matplotlib 和 seaborn 視覺化。您可以在此處檢視程式碼。

在 Hugging Face Spaces 中託管您的專案
您可以簡單地拖放您的檔案,如下所示。請注意,您需要在 requirements.txt 中包含您的附加依賴項。另請注意,您本地的 Streamlit 版本是相同的。為了無縫使用,請參閱 Spaces API 參考。



