使用機器學習增強客戶服務


在這篇博文中,我們將模擬一個真實的客戶服務用例,並使用 Hugging Face 生態系統中的機器學習工具來解決它。
我們強烈建議使用此筆記本來作為模板/示例,以解決 你自己的 真實世界用例。
定義任務、資料集和模型
在進入實際編碼部分之前,清楚地定義你希望自動化或部分自動化的用例非常重要。一個清晰的用例定義有助於確定最合適的任務、要使用的資料集以及要應用的模型。
定義你的 NLP 任務
好了,讓我們深入研究一個我們希望使用自然語言處理模型解決的假設性問題。假設我們正在銷售一種產品,我們的客戶支援團隊每天會收到數千條資訊,包括反饋、投訴和問題,理想情況下這些資訊都應該得到回覆。
很快,我們就會發現客戶支援團隊根本無法回覆每一條訊息。因此,我們決定只回應那些最不滿意的客戶,併力求 100% 回覆這些訊息,因為與中性或積極的訊息相比,這些訊息可能更緊急。
假設 a) 非常不滿意的客戶訊息只佔所有訊息的一小部分,並且 b) 我們可以透過自動化的方式篩選出不滿意的訊息,那麼客戶支援團隊應該能夠實現這個目標。
為了以自動化的方式篩選出不滿意的訊息,我們計劃應用自然語言處理技術。
第一步是將我們的用例—— 篩選出不滿意的訊息 ——對映到一個機器學習任務。
Hugging Face Hub 上的任務頁面 是一個很好的起點,可以幫助你瞭解哪個任務最適合特定的場景。每個任務都有詳細的描述和潛在的用例。
尋找最不滿意客戶訊息的任務可以被建模為文字分類任務:將一條訊息分類為以下 5 個類別之一: 非常不滿意 、 不滿意 、 中性 、 滿意 或 非常滿意 。
尋找合適的資料集
在確定了任務之後,接下來我們應該找到模型訓練所需的資料。對於你的用例效能而言,這通常比選擇正確的模型架構更重要。請記住,一個模型的效能 取決於它所訓練的資料 。因此,我們在整理和/或選擇資料集時應該非常小心。
鑑於我們考慮的是 篩選出不滿意訊息 的假設性用例,讓我們看看有哪些可用的資料集。
對於你的真實世界用例,你 很可能 擁有最能代表你的 NLP 系統實際需要處理的資料的內部資料。因此,你應該使用這些內部資料來訓練你的 NLP 系統。不過,為了提高模型的泛化能力,包含一些公開可用的資料也可能是有幫助的。
讓我們看一下 Hugging Face Hub 上所有可用的資料集。在左側,你可以根據 任務類別 以及更具體的 任務 來篩選資料集。我們的用例對應於 文字分類 -> 情感分析,所以我們選擇 這些篩選條件 。在撰寫此筆記本時,我們篩選出了大約 80 個數據集。在選擇資料集時,應評估兩個方面:
- 質量 :資料集是否高質量?具體來說:資料是否與你用例中預期處理的資料相符?資料是否多樣化、無偏見……?
- 規模 :資料集有多大?通常,我們可以肯定地說資料集越大越好。
高效地評估一個數據集是否高質量是相當棘手的,而瞭解資料集是否存在偏見以及偏見的程度則更具挑戰性。一個高效且合理的判斷高質量的經驗法則是檢視下載統計資料。下載次數越多,使用率越高,資料集質量高的可能性就越大。資料集的大小很容易評估,因為它通常可以快速查到。讓我們看看下載量最多的幾個資料集:
現在我們可以透過閱讀資料集卡片來更詳細地檢查這些資料集,理想情況下,資料集卡片應該提供所有相關和重要的資訊。此外,資料集檢視器 是一個非常強大的工具,可以用來檢查資料是否適合你的用例。
讓我們快速瀏覽一下上述模型的資料集卡片:
- GLUE 是一組小型資料集的集合,主要用於研究人員比較新的模型架構。這些資料集規模太小,且與我們的用例不夠匹配。
- Amazon polarity 是一個非常適合客戶反饋的大型資料集,因為資料涉及客戶評論。然而,它只有二元標籤(正面/負面),而我們正在尋找更細粒度的情感分類。
- Tweet eval 使用不同的表情符號作為標籤,這些標籤不容易對映到一個從不滿意到滿意的量表上。
- Amazon reviews multi 似乎是這裡最合適的資料集。我們有從 1 到 5 的情感標籤,對應於亞馬遜上的 1 到 5 星。這些標籤可以對映到 非常不滿意、不滿意、中性、滿意、非常滿意 。我們在 資料集檢視器 上檢查了一些示例,以驗證評論看起來與實際的客戶反饋評論非常相似,所以這似乎是一個非常好的資料集。此外,每個評論都有一個
product_category標籤,所以我們甚至可以只使用與我們工作領域相對應的產品類別的評論。這個資料集是多語言的,但我們目前只對英文版本感興趣。 - Yelp review full 看起來是一個非常合適的資料集。它規模大,包含產品評論和從 1 到 5 的情感標籤。遺憾的是,這裡的資料集檢視器無法使用,而且資料集卡片也相對稀疏,需要更多時間來檢查資料集。此時,我們應該閱讀相關論文,但考慮到這篇博文的時間限制,我們選擇使用 Amazon reviews multi 。綜上所述,讓我們專注於 Amazon reviews multi 資料集,並考慮所有訓練樣本。
最後一點,我們建議即使在處理私有資料集時也利用 Hub 的資料集功能。Hugging Face Hub、Transformers 和 Datasets 實現了無縫整合,這使得在訓練模型時將它們結合使用變得非常簡單。
此外,Hugging Face Hub 還提供:
尋找合適的模型
在確定了任務和最能描述我們用例的資料集之後,我們現在可以開始選擇要使用的模型了。
很可能你需要為自己的用例微調一個預訓練模型,但值得檢查一下 Hub 上是否已經有合適的、經過微調的模型。在這種情況下,你或許可以透過繼續在你自己的資料集上微調這樣的模型來獲得更高的效能。
讓我們看一下所有在 Amazon Reviews Multi 資料集上微調過的模型。你可以在右下角找到模型列表——點選 瀏覽在該資料集上訓練的模型,你可以看到 所有在該資料集上微調過的公開可用模型的列表。請注意,我們只對該資料集的英文版本感興趣,因為我們的客戶反饋將只使用英文。大多數下載量最高的模型都是在多語言版本的資料集上訓練的,而那些看起來不是多語言的模型資訊很少或效能較差。在這種情況下,微調一個純粹的預訓練模型可能比使用上面連結中顯示的那些已經微調過的模型更為明智。
好了,下一步是找到一個合適的預訓練模型用於微調。考慮到 Hugging Face Hub 上有大量的預訓練和微調模型,這實際上比看起來要困難。最好的選擇通常是簡單地嘗試各種不同的模型,看看哪個表現最好。在 Hugging Face,我們還沒有找到比較不同模型檢查點的完美方法,但我們提供了一些值得研究的資源:
然而,以上兩種資源目前都並非最佳選擇。模型摘要並非總能被作者及時更新。新模型架構釋出的速度以及舊模型架構過時的速度使得要有一個包含所有模型架構的最新摘要變得極其困難。同樣地,下載次數最多的模型檢查點並不一定就是最好的。例如,bert-base-cased 是下載次數最多的模型檢查點之一,但它已不再是效能最佳的檢查點了。
最好的方法是嘗試各種模型架構,透過關注該領域的專家來了解最新的模型架構,並檢視知名的排行榜。
對於文字分類,需要關注的重要基準是 GLUE 和 SuperGLUE。這兩個基準都在多種文字分類任務上評估預訓練模型,例如語法正確性、自然語言推理、是/否問答等,這些任務與我們的目標任務——情感分析非常相似。因此,為我們的任務選擇這些基準中的領先模型是合理的。
在撰寫這篇博文時,效能最佳的模型都是引數超過 100 億的非常大的模型,其中大多數並未開源,例如 ST-MoE-32B、Turing NLR v5 或 ERNIE 3.0。排名靠前且易於獲取的模型之一是 DeBERTa。因此,讓我們嘗試一下 DeBERTa 最新的基礎版本——即 microsoft/deberta-v3-base。
使用 🤗 Transformers 和 🤗 Datasets 訓練/微調模型
在本節中,我們將深入探討如何端到端地微調一個模型,以便能夠自動篩選出非常不滿意的客戶反饋訊息。
太棒了!讓我們先安裝所有必要的 pip 包並設定我們的程式碼環境,然後研究如何預處理資料集,最後開始訓練模型。
以下筆記本可以在啟用 GPU 執行時環境的 Google Colab Pro 中線上執行。
安裝所有必要的軟體包
首先,讓我們安裝 git-lfs,這樣我們就可以在訓練過程中自動將訓練好的檢查點上傳到 Hub。
apt install git-lfs
此外,我們安裝 🤗 Transformers 和 🤗 Datasets 庫來執行這個筆記本。由於我們將在本博文中使用 DeBERTa,我們還需要為其分詞器安裝 sentencepiece 庫。
pip install datasets transformers[sentencepiece]
接下來,讓我們登入我們的 Hugging Face 賬戶,以便模型能以你的使用者名稱正確上傳。
from huggingface_hub import notebook_login
notebook_login()
輸出
Login successful
Your token has been saved to /root/.huggingface/token
Authenticated through git-credential store but this isn't the helper defined on your machine.
You might have to re-authenticate when pushing to the Hugging Face Hub. Run the following command in your terminal in case you want to set this credential helper as the default
git config --global credential.helper store
預處理資料集
在我們開始訓練模型之前,我們應該將資料集轉換成模型可以理解的格式。
幸運的是,正如你將在接下來的單元格中看到的, 🤗 Datasets 庫使這一切變得極其簡單。
load_dataset 函式會載入資料集,將其整齊地組織成預定義的屬性,如 review_body 和 stars,最後使用 Arrow 格式 將新整理的資料儲存在磁碟上。Arrow 格式允許快速且記憶體高效的資料讀寫。
讓我們載入並準備 amazon_reviews_multi 資料集的英文版本。
from datasets import load_dataset
amazon_review = load_dataset("amazon_reviews_multi", "en")
輸出
Downloading and preparing dataset amazon_reviews_multi/en (download: 82.11 MiB, generated: 58.69 MiB, post-processed: Unknown size, total: 140.79 MiB) to /root/.cache/huggingface/datasets/amazon_reviews_multi/en/1.0.0/724e94f4b0c6c405ce7e476a6c5ef4f87db30799ad49f765094cf9770e0f7609...
Dataset amazon_reviews_multi downloaded and prepared to /root/.cache/huggingface/datasets/amazon_reviews_multi/en/1.0.0/724e94f4b0c6c405ce7e476a6c5ef4f87db30799ad49f765094cf9770e0f7609. Subsequent calls will reuse this data.
太棒了,速度真快 🔥。讓我們看一下資料集的結構。
print(amazon_review)
輸出
{.output .execute_result execution_count="5"}
DatasetDict({
train: Dataset({
features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
num_rows: 200000
})
validation: Dataset({
features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
num_rows: 5000
})
test: Dataset({
features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
num_rows: 5000
})
})
我們有 200,000 個訓練樣本,以及 5000 個驗證和測試樣本。這對於訓練來說聽起來很合理!我們真正感興趣的只是將 "review_body" 列作為輸入,"stars" 列作為目標。
讓我們來看一個隨機的例子。
random_id = 34
print("Stars:", amazon_review["train"][random_id]["stars"])
print("Review:", amazon_review["train"][random_id]["review_body"])
輸出
Stars: 1
Review: This product caused severe burning of my skin. I have used other brands with no problems
資料集是人類可讀的格式,但現在我們需要將其轉換為“機器可讀”的格式。讓我們定義模型倉庫,其中包含預處理和微調我們所選檢查點所需的所有工具。
model_repository = "microsoft/deberta-v3-base"
接下來,我們載入模型倉庫的分詞器,它是一個 DeBERTa 的分詞器。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_repository)
如前所述,我們將使用 "review_body" 作為模型的輸入,"stars" 作為模型的目標。接下來,我們利用分詞器將輸入轉換為模型可以理解的詞元 ID 序列。分詞器正是做這個的,它還可以幫助你將輸入資料限制在一定的長度內,以避免記憶體問題。在這裡,我們將最大長度限制為 128 個詞元,對於 DeBERTa 來說,這大約對應 100 個單詞,也就是大約 5-7 個句子。再次檢視 資料集檢視器,我們可以看到這幾乎覆蓋了所有的訓練樣本。重要提示:這並不意味著我們的模型不能處理更長的輸入序列,只是意味著我們在訓練時使用 128 的最大長度,因為它覆蓋了 99% 的訓練資料,而且我們不想浪費記憶體。Transformer 模型在訓練後已被證明能夠很好地泛化到更長的序列。
如果你想了解更多關於分詞的知識,請檢視 分詞器文件。
標籤很容易轉換,因為它們在原始形式下已經對應於數字,即從 1 到 5 的範圍。在這裡,我們只是將標籤移到 0 到 4 的範圍內,因為索引通常從 0 開始。
很好,讓我們把想法寫成程式碼。我們將定義一個 preprocess_function,並將其應用於每個資料樣本。
def preprocess_function(example):
output_dict = tokenizer(example["review_body"], max_length=128, truncation=True)
output_dict["labels"] = [e - 1 for e in example["stars"]]
return output_dict
要將此函式應用於我們資料集中的所有資料樣本,我們使用我們之前建立的 amazon_review 物件的 map 方法。這將在 amazon_review 中所有拆分的所有元素上應用該函式,因此我們的訓練、驗證和測試資料將透過一個命令進行預處理。我們在 batched=True 模式下執行對映函式以加快處理速度,並刪除所有列,因為我們不再需要它們進行訓練。
tokenized_datasets = amazon_review.map(preprocess_function, batched=True, remove_columns=amazon_review["train"].column_names)
我們來看看新的結構。
tokenized_datasets
輸出
DatasetDict({
train: Dataset({
features: ['input_ids', 'token_type_ids', 'attention_mask', 'labels'],
num_rows: 200000
})
validation: Dataset({
features: ['input_ids', 'token_type_ids', 'attention_mask', 'labels'],
num_rows: 5000
})
test: Dataset({
features: ['input_ids', 'token_type_ids', 'attention_mask', 'labels'],
num_rows: 5000
})
})
我們可以看到,結構的外層保持不變,但列的命名發生了變化。讓我們看一下我們之前看過的同一個隨機樣本,只不過現在是預處理過的。
print("Input IDS:", tokenized_datasets["train"][random_id]["input_ids"])
print("Labels:", tokenized_datasets["train"][random_id]["labels"])
輸出
Input IDS: [1, 329, 714, 2044, 3567, 5127, 265, 312, 1158, 260, 273, 286, 427, 340, 3006, 275, 363, 947, 2]
Labels: 0
好的,輸入文字被轉換成了一個整數序列,這個序列可以被模型轉換成詞嵌入,而標籤索引則簡單地減去了 1。
微調模型
預處理完資料集後,我們接下來可以微調模型。我們將使用廣受歡迎的 Hugging Face Trainer,它讓我們只需幾行程式碼就能開始訓練。Trainer 幾乎可以用於 PyTorch 中的所有任務,並且透過處理大量訓練所需的樣板程式碼而極其方便。
讓我們開始使用便捷的 AutoModelForSequenceClassification 來載入模型檢查點。由於模型倉庫的檢查點只是一個預訓練的檢查點,我們應該透過傳遞 num_labels=5 (因為我們有 5 個情感類別) 來定義分類頭的大小。
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(model_repository, num_labels=5)
Some weights of the model checkpoint at microsoft/deberta-v3-base were not used when initializing DebertaV2ForSequenceClassification: ['mask_predictions.classifier.bias', 'mask_predictions.LayerNorm.bias', 'mask_predictions.dense.weight', 'mask_predictions.dense.bias', 'mask_predictions.LayerNorm.weight', 'lm_predictions.lm_head.dense.bias', 'lm_predictions.lm_head.bias', 'lm_predictions.lm_head.LayerNorm.weight', 'lm_predictions.lm_head.dense.weight', 'lm_predictions.lm_head.LayerNorm.bias', 'mask_predictions.classifier.weight']
- This IS expected if you are initializing DebertaV2ForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing DebertaV2ForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of DebertaV2ForSequenceClassification were not initialized from the model checkpoint at microsoft/deberta-v3-base and are newly initialized: ['pooler.dense.bias', 'classifier.weight', 'classifier.bias', 'pooler.dense.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
接下來,我們載入一個數據整理器(data collator)。資料整理器 負責確保在訓練過程中每個批次都得到正確的填充,這應該是動態發生的,因為訓練樣本在每個週期之前都會被重新打亂。
from transformers import DataCollatorWithPadding
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
在訓練過程中,監控模型在留出的驗證集上的效能非常重要。為此,我們應該向 Trainer 傳遞一個 compute_metrics 函式,該函式將在訓練期間的每個驗證步驟被呼叫。
文字分類任務最簡單的度量標準是 準確率,它簡單地表示被正確分類的訓練樣本的百分比。然而,如果驗證或測試資料非常不平衡,使用 準確率 度量標準可能會有問題。讓我們透過計算每個標籤的出現次數來快速驗證情況是否如此。
from collections import Counter
print("Validation:", Counter(tokenized_datasets["validation"]["labels"]))
print("Test:", Counter(tokenized_datasets["test"]["labels"]))
輸出
Validation: Counter({0: 1000, 1: 1000, 2: 1000, 3: 1000, 4: 1000})
Test: Counter({0: 1000, 1: 1000, 2: 1000, 3: 1000, 4: 1000})
驗證集和測試集儘可能地平衡,所以我們在這裡可以安全地使用準確率!
讓我們透過 datasets 庫載入 準確率指標。
from datasets import load_metric
accuracy = load_metric("accuracy")
接下來,我們定義 compute_metrics 函式,該函式將應用於模型的預測輸出,其型別為 EvalPrediction,因此可以訪問模型的預測值和真實標籤。我們透過取模型預測值的 argmax 來計算預測的標籤類別,然後將其與真實標籤一起傳遞給準確率指標。
import numpy as np
def compute_metrics(pred):
pred_logits = pred.predictions
pred_classes = np.argmax(pred_logits, axis=-1)
labels = np.asarray(pred.label_ids)
acc = accuracy.compute(predictions=pred_classes, references=labels)
return {"accuracy": acc["accuracy"]}
太好了,現在訓練所需的所有元件都準備好了,剩下的就是定義 Trainer 的超引數。我們需要確保在訓練期間將模型檢查點上傳到 Hugging Face Hub。透過設定 push_to_hub=True,這將在每個 save_steps 步驟透過方便的 push_to_hub 方法自動完成。
此外,我們還定義了一些標準的超引數,如學習率、預熱步數和訓練週期。我們將每 500 步記錄一次損失,並每 5000 步進行一次評估。
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir="deberta_amazon_reviews_v1",
num_train_epochs=2,
learning_rate=2e-5,
warmup_steps=200,
logging_steps=500,
save_steps=5000,
eval_steps=5000,
push_to_hub=True,
evaluation_strategy="steps",
)
將所有內容整合在一起,我們最終可以透過傳遞所有必需的元件來例項化 Trainer。我們將使用 "validation" 拆分作為訓練期間的留出資料集。
from transformers import Trainer
trainer = Trainer(
args=training_args,
compute_metrics=compute_metrics,
model=model,
tokenizer=tokenizer,
data_collator=data_collator,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"]
)
訓練器已準備就緒 🚀 你可以透過呼叫 trainer.train() 開始訓練。
train_metrics = trainer.train().metrics
trainer.save_metrics("train", train_metrics)
輸出
***** Running training *****
Num examples = 200000
Num Epochs = 2
Instantaneous batch size per device = 8
Total train batch size (w. parallel, distributed & accumulation) = 8
Gradient Accumulation steps = 1
Total optimization steps = 50000
輸出
| 步驟 | 訓練損失 | 驗證損失 | 準確率 |
| 5000 | 0.931200 | 0.979602 | 0.585600 |
| 10000 | 0.931600 | 0.933607 | 0.597400 |
| 15000 | 0.907600 | 0.917062 | 0.602600 |
| 20000 | 0.902400 | 0.919414 | 0.604600 |
| 25000 | 0.879400 | 0.910928 | 0.608400 |
| 30000 | 0.806700 | 0.933923 | 0.609200 |
| 35000 | 0.826800 | 0.907260 | 0.616200 |
| 40000 | 0.820500 | 0.904160 | 0.615800 |
| 45000 | 0.795000 | 0.918947 | 0.616800 |
| 50000 | 0.783600 | 0.907572 | 0.618400 |
輸出
***** Running Evaluation *****
Num examples = 5000
Batch size = 8
Saving model checkpoint to deberta_amazon_reviews_v1/checkpoint-50000
Configuration saved in deberta_amazon_reviews_v1/checkpoint-50000/config.json
Model weights saved in deberta_amazon_reviews_v1/checkpoint-50000/pytorch_model.bin
tokenizer config file saved in deberta_amazon_reviews_v1/checkpoint-50000/tokenizer_config.json
Special tokens file saved in deberta_amazon_reviews_v1/checkpoint-50000/special_tokens_map.json
added tokens file saved in deberta_amazon_reviews_v1/checkpoint-50000/added_tokens.json
Training completed. Do not forget to share your model on huggingface.co/models =)
酷,我們看到模型似乎學到了一些東西!訓練損失和驗證損失都在下降,準確率最終也遠高於隨機猜測(20%)。有趣的是,我們看到僅在 5000 步後準確率就達到了約 58.6 %,之後並沒有太大提升。選擇一個更大的模型或訓練更長時間可能會得到更好的結果,但這對於我們假設的用例來說已經足夠好了!
好了,最後讓我們將模型檢查點上傳到 Hub。
trainer.push_to_hub()
輸出
Saving model checkpoint to deberta_amazon_reviews_v1
Configuration saved in deberta_amazon_reviews_v1/config.json
Model weights saved in deberta_amazon_reviews_v1/pytorch_model.bin
tokenizer config file saved in deberta_amazon_reviews_v1/tokenizer_config.json
Special tokens file saved in deberta_amazon_reviews_v1/special_tokens_map.json
added tokens file saved in deberta_amazon_reviews_v1/added_tokens.json
Several commits (2) will be pushed upstream.
The progress bars may be unreliable.
評估/分析模型
現在我們已經微調了模型,我們需要非常仔細地分析它的效能。請注意,像 準確率 這樣的標準指標對於瞭解模型的總體效能很有用,但可能不足以評估模型在你的實際用例中的表現。更好的方法是找到一個最能描述模型實際用例的指標,並在訓練期間和之後精確地衡量這個指標。
讓我們深入評估模型 🤿。
模型在訓練後已經上傳到了 Hub 的 deberta_v3_amazon_reviews 下,所以第一步,讓我們再次從那裡下載它。
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained("patrickvonplaten/deberta_v3_amazon_reviews")
Trainer 不僅是訓練模型的絕佳類,也是在資料集上評估模型的絕佳類。讓我們用與之前相同的例項和函式來例項化 Trainer,但這次不需要傳遞訓練資料集。
trainer = Trainer(
args=training_args,
compute_metrics=compute_metrics,
model=model,
tokenizer=tokenizer,
data_collator=data_collator,
)
我們使用 Trainer 的 predict 函式在測試資料集上使用相同的指標評估模型。
prediction_metrics = trainer.predict(tokenized_datasets["test"]).metrics
prediction_metrics
輸出
***** Running Prediction *****
Num examples = 5000
Batch size = 8
輸出
{'test_accuracy': 0.608,
'test_loss': 0.9637690186500549,
'test_runtime': 21.9574,
'test_samples_per_second': 227.714,
'test_steps_per_second': 28.464}
結果與在驗證資料集上的表現非常相似,這通常是一個好跡象,因為它表明模型沒有過擬合測試資料集。
然而,對於一個 5 分類問題來說,60% 的準確率遠非完美,但我們是否需要對所有類別都有很高的準確率呢?
由於我們主要關注的是非常負面的客戶反饋,讓我們只關注模型在分類最不滿意客戶的評論方面的表現。我們還決定幫助模型一下——所有被分類為 非常不滿意 或 不滿意 的反饋都將由我們處理——以捕捉到接近 99% 的 非常不滿意 的訊息。同時,我們還衡量了透過這種方式我們能回答多少 不滿意 的訊息,以及我們透過回答中性、滿意和非常滿意的客戶訊息做了多少不必要的工作。
太好了,讓我們寫一個新的 compute_metrics 函式。
import numpy as np
def compute_metrics(pred):
pred_logits = pred.predictions
pred_classes = np.argmax(pred_logits, axis=-1)
labels = np.asarray(pred.label_ids)
# First let's compute % of very unsatisfied messages we can catch
very_unsatisfied_label_idx = (labels == 0)
very_unsatisfied_pred = pred_classes[very_unsatisfied_label_idx]
# Now both 0 and 1 labels are 0 labels the rest is > 0
very_unsatisfied_pred = very_unsatisfied_pred * (very_unsatisfied_pred - 1)
# Let's count how many labels are 0 -> that's the "very unsatisfied"-accuracy
true_positives = sum(very_unsatisfied_pred == 0) / len(very_unsatisfied_pred)
# Second let's compute how many satisfied messages we unnecessarily reply to
satisfied_label_idx = (labels > 1)
satisfied_pred = pred_classes[satisfied_label_idx]
# how many predictions are labeled as unsatisfied over all satisfied messages?
false_positives = sum(satisfied_pred <= 1) / len(satisfied_pred)
return {"%_unsatisfied_replied": round(true_positives, 2), "%_satisfied_incorrectly_labels": round(false_positives, 2)}
我們再次例項化 Trainer 以便輕鬆執行評估。
trainer = Trainer(
args=training_args,
compute_metrics=compute_metrics,
model=model,
tokenizer=tokenizer,
data_collator=data_collator,
)
然後讓我們用我們新的、更適合我們用例的指標計算方法再次執行評估。
prediction_metrics = trainer.predict(tokenized_datasets["test"]).metrics
prediction_metrics
輸出
***** Running Prediction *****
Num examples = 5000
Batch size = 8
輸出
{'test_%_satisfied_incorrectly_labels': 0.11733333333333333,
'test_%_unsatisfied_replied': 0.949,
'test_loss': 0.9637690186500549,
'test_runtime': 22.8964,
'test_samples_per_second': 218.375,
'test_steps_per_second': 27.297}
酷!這已經描繪出了一幅相當不錯的圖景。我們自動捕捉了大約 95% 的 非常不滿意 的客戶,代價是在 10% 的滿意訊息上浪費了我們的精力。
讓我們快速計算一下。我們每天大約收到 10,000 條訊息,其中我們預計約有 500 條是非常負面的。使用這種自動篩選,我們不再需要回復所有 10,000 條訊息,而只需檢視 500 + 0.12 * 10,000 = 1700 條訊息,並且只需回覆 475 條訊息,同時錯誤地漏掉了 5% 的訊息。相當不錯——在只漏掉 5% 非常不滿意的客戶的情況下,人力減少了 83%!
顯然,這些數字並不能代表一個實際用例所獲得的價值,但只要有足夠高質量的真實世界示例訓練資料,我們就能接近這個目標!
讓我們儲存結果
trainer.save_metrics("prediction", prediction_metrics)
然後再次將所有內容上傳到 Hub。
trainer.push_to_hub()
輸出
Saving model checkpoint to deberta_amazon_reviews_v1
Configuration saved in deberta_amazon_reviews_v1/config.json
Model weights saved in deberta_amazon_reviews_v1/pytorch_model.bin
tokenizer config file saved in deberta_amazon_reviews_v1/tokenizer_config.json
Special tokens file saved in deberta_amazon_reviews_v1/special_tokens_map.json
added tokens file saved in deberta_amazon_reviews_v1/added_tokens.json
To https://huggingface.co/patrickvonplaten/deberta_amazon_reviews_v1
599b891..ad77e6d main -> main
Dropping the following result as it does not have all the necessary fields:
{'task': {'name': 'Text Classification', 'type': 'text-classification'}}
To https://huggingface.co/patrickvonplaten/deberta_amazon_reviews_v1
ad77e6d..13e5ddd main -> main
資料現在儲存在 這裡。
今天就到這裡 😎。作為最後一步,在實際的真實世界資料上嘗試這個模型也很有意義。這可以直接在 模型卡片 的推理小部件上完成。
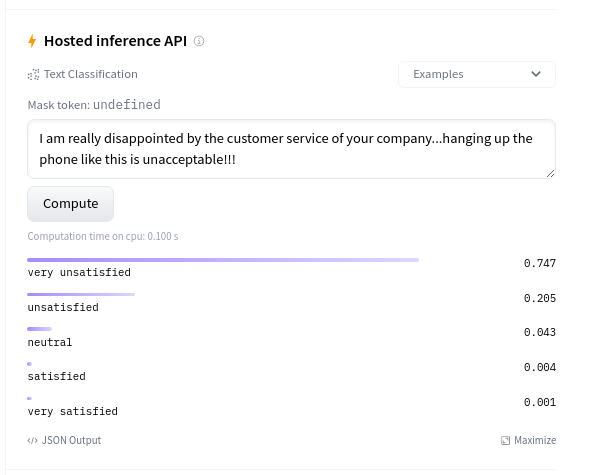
它似乎能很好地泛化到真實世界的資料 🔥
最佳化
一旦你認為模型的效能足夠好可以投入生產,關鍵就在於讓模型儘可能地節省記憶體並且執行得快。
有一些顯而易見的解決方案,比如選擇最合適的加速硬體,例如 更好的 GPU,確保在前向傳播過程中不計算梯度,或者降低精度,例如 降至 float16。
更高階的最佳化方法包括使用開源加速器庫,如 ONNX Runtime、量化,以及像 Triton 這樣的推理伺服器。
在 Hugging Face,我們一直在努力簡化模型的最佳化,特別是透過我們的開源 Optimum 庫。Optimum 使得最佳化大多數 🤗 Transformers 模型變得極其簡單。
如果你正在尋找不需要任何技術知識的 高度最佳化 解決方案,你可能會對 推理 API 感興趣,這是一個即插即用的解決方案,可以在生產環境中為各種機器學習任務提供服務,包括情感分析。
此外,如果你正在為 你的自定義用例尋求支援,Hugging Face 的專家團隊可以幫助加速你的機器學習專案!我們的團隊在你的機器學習之旅中,從研究到生產,隨時回答問題並尋找解決方案。請訪問 瞭解更多資訊並索取報價。
