無需真實資料的高效表格預訓練:TAPEX 簡介

近年來,語言模型預訓練透過利用大規模文字資料取得了巨大成功。透過採用諸如掩碼語言建模之類的預訓練任務,這些模型在若干下游任務上展現了驚人的效能。然而,預訓練任務(例如,語言建模)和下游任務(例如,表格問答)之間的巨大差距使得現有的預訓練效率不夠高。在實踐中,我們通常需要 極其大量 的預訓練資料才能獲得有希望的改進,即使對於領域自適應預訓練也是如此。我們如何設計一個預訓練任務來縮小這一差距,從而加速預訓練呢?
概覽
在《TAPEX: Table Pre-training via Learning a Neural SQL Executor》一文中,我們探索了在預訓練期間 使用合成數據作為真實資料的代理,並透過 TAPEX(Table Pre-training via Execution,透過執行進行表格預訓練) 作為一個例子來展示其強大之處。在 TAPEX 中,我們表明表格預訓練可以透過在合成語料庫上學習一個神經 SQL 執行器來實現。
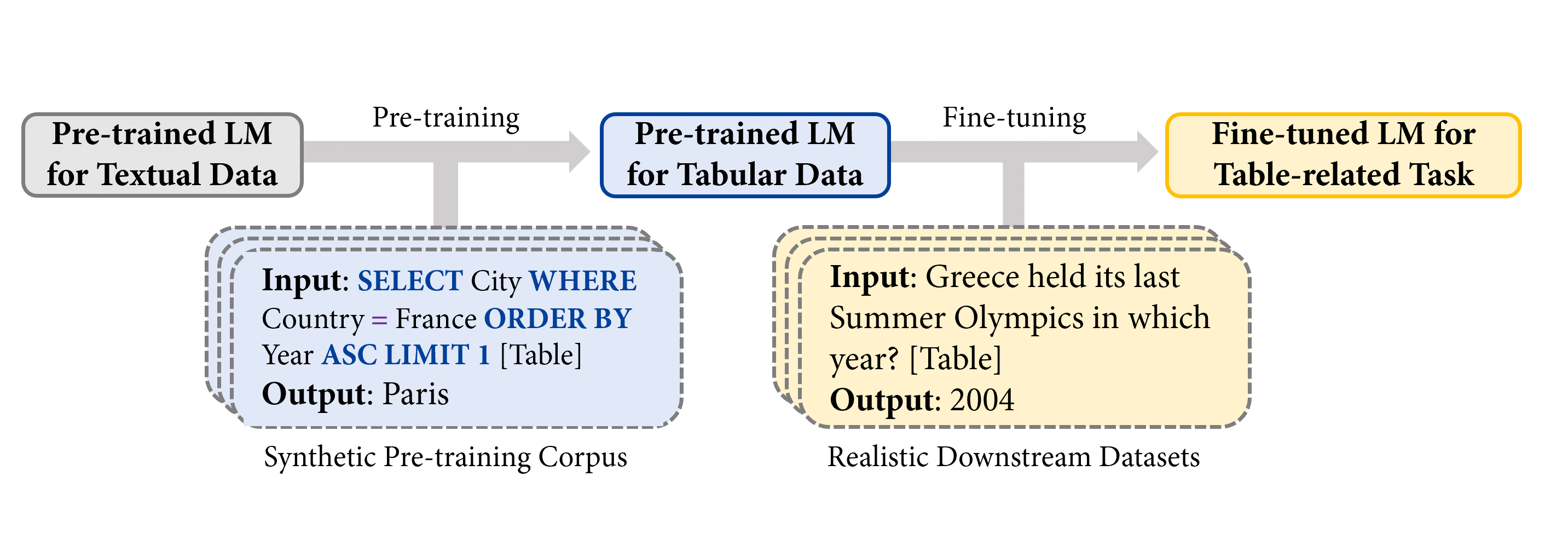
注意:[Table] 是輸入中使用者提供表格的佔位符。
如上圖所示,透過系統地取樣表格上的 可執行 SQL 查詢及其執行輸出,TAPEX 首先合成了一個人造的非自然語言預訓練語料庫。然後,它繼續預訓練一個語言模型(例如,BART),使其輸出 SQL 查詢的執行結果,這模仿了一個神經 SQL 執行器的過程。
預訓練
下圖說明了預訓練過程。在每一步,我們首先從網上獲取一個表格。示例表格是關於奧運會的。然後我們可以取樣一個可執行的 SQL 查詢 SELECT City WHERE Country = France ORDER BY Year ASC LIMIT 1。透過一個現成的 SQL 執行器(例如,MySQL),我們可以得到查詢的執行結果 Paris。類似地,透過將 SQL 查詢和扁平化表格的拼接作為輸入提供給模型(例如,BART 編碼器),執行結果則作為監督訊號提供給模型(例如,BART 解碼器)作為輸出。

為什麼使用諸如 SQL 查詢之類的程式而不是自然語言句子作為預訓練的來源?最大的優勢在於,與不可控的自然語言句子相比,程式的多樣性和規模可以得到系統性的保證。因此,我們可以透過取樣 SQL 查詢輕鬆地合成一個多樣化、大規模且高質量的預訓練語料庫。
你可以在 🤗 Transformers 中嘗試訓練好的神經 SQL 執行器,如下所示
from transformers import TapexTokenizer, BartForConditionalGeneration
import pandas as pd
tokenizer = TapexTokenizer.from_pretrained("microsoft/tapex-large-sql-execution")
model = BartForConditionalGeneration.from_pretrained("microsoft/tapex-large-sql-execution")
data = {
"year": [1896, 1900, 1904, 2004, 2008, 2012],
"city": ["athens", "paris", "st. louis", "athens", "beijing", "london"]
}
table = pd.DataFrame.from_dict(data)
# tapex accepts uncased input since it is pre-trained on the uncased corpus
query = "select year where city = beijing"
encoding = tokenizer(table=table, query=query, return_tensors="pt")
outputs = model.generate(**encoding)
print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
# ['2008']
微調
在微調期間,我們將自然語言問題和扁平化表格的拼接作為輸入提供給模型,標註者標記的答案則作為監督訊號提供給模型作為輸出。想自己微調 TAPEX 嗎?你可以在這裡檢視微調指令碼,它已經正式整合到 🤗 Transformers 4.19.0 中!
截至目前,所有可用的 TAPEX 模型都已獲得 Huggingface 官方支援的互動式小部件!你可以嘗試回答一些問題,如下所示。
| 程式碼庫 | 收藏數 (Stars) | 貢獻者 | 程式語言 |
|---|---|---|---|
| Transformers | 36542 | 651 | Python |
| 資料集 | 4512 | 77 | Python |
| Tokenizers | 3934 | 34 | Rust、Python 和 NodeJS |
實驗
我們在四個基準資料集上評估 TAPEX,包括 WikiSQL (Weak)、WikiTableQuestions、SQA 和 TabFact。前三個資料集是關於表格問答的,而最後一個是關於表格事實核查的,兩者都需要對錶格和自然語言進行聯合推理。以下是一些來自最具挑戰性的資料集 WikiTableQuestions 的例子:
| 問題 | 回答 |
|---|---|
| 根據表格,Spicy Horse 製作的最後一個遊戲是什麼? | Akaneiro: Demon Hunters |
| 科爾雷恩學術學院和皇家鄧甘農學校的亞軍人數有何差異? | 20 |
| 格林斯特里特參演的第一部和最後一部電影分別是什麼? | 馬耳他之鷹,馬來亞 |
| 在哪屆奧運會上,阿薩伊·通迪凱沒有進入前 20 名? | 2012 |
| 哪個廣播公司主持了 3 個節目,但每個節目只有 1 集? | 第 4 頻道 |
實驗結果表明,TAPEX 的效能大幅優於以往的表格預訓練方法,並且 ⭐在所有這些資料集上都取得了新的最先進(SOTA)結果⭐。這包括:弱監督的 WikiSQL 指稱準確率提升至 89.6%(比 SOTA 高 2.3%,比 BART 高 3.8%),TabFact 準確率提升至 84.2%(比 SOTA 高 3.2%,比 BART 高 3.0%),SQA 指稱準確率提升至 74.5%(比 SOTA 高 3.5%,比 BART 高 15.9%),以及 WikiTableQuestion 指稱準確率提升至 57.5%(比 SOTA 高 4.8%,比 BART 高 19.5%)。據我們所知,這是首個利用合成可執行程式進行預訓練並在各種下游任務上取得新的最先進成果的工作。
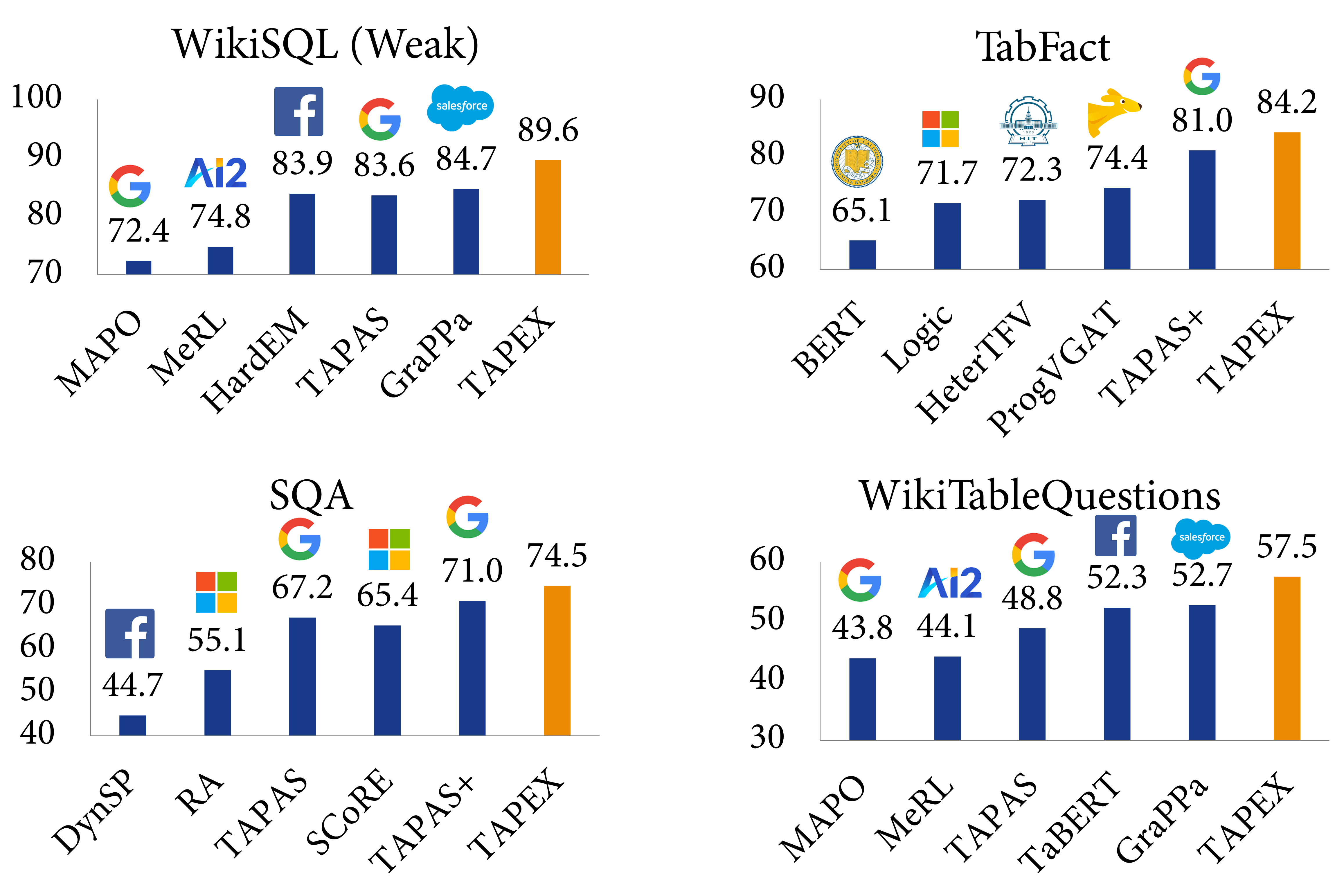
與以往表格預訓練的比較
最早的表格預訓練工作,如來自 Google Research 的 TAPAS(同樣在 🤗 Transformers 中可用)和來自 Meta AI 的 TaBERT,已經揭示了收集更多 領域自適應 的資料可以提升下游效能。然而,這些先前的工作主要採用 通用 的預訓練任務,例如語言建模或其變體。TAPEX 探索了一條不同的道路,它犧牲了預訓練源的自然性,以獲得一個 領域自適應 的預訓練任務,即 SQL 執行。下面是 BERT、TAPAS/TaBERT 和我們的 TAPEX 的圖形化比較。

我們認為 SQL 執行任務更接近於下游的表格問答任務,特別是從結構化推理能力的角度來看。想象一下你面對一個 SQL 查詢 SELECT City ORDER BY Year 和一個自然語言問題 按年份對所有城市進行排序。SQL 查詢和問題所需的推理路徑是相似的,只是 SQL 比自然語言更刻板一些。如果一個語言模型能夠被預訓練來忠實地“執行” SQL 查詢併產生正確的結果,那麼它應該對具有相似意圖的自然語言有深刻的理解。
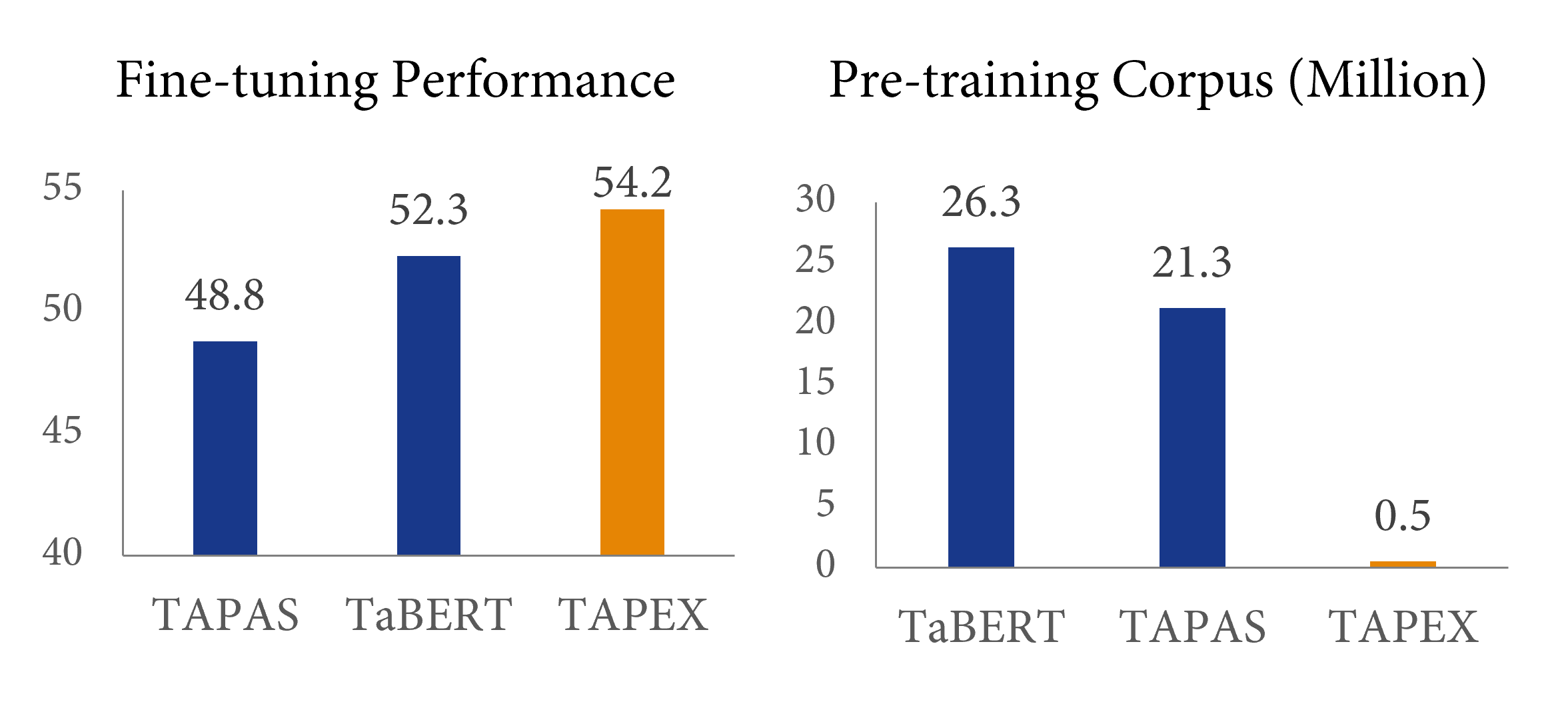
效率如何?與之前的預訓練方法相比,這種預訓練方法的效率有多高?答案在上圖中給出:與之前的表格預訓練方法 TaBERT 相比,TAPEX 僅使用 2% 的預訓練語料庫就能產生 2% 的效能提升,實現了近 50 倍的加速!使用更大的預訓練語料庫(例如,500 萬個
結論
在這篇部落格中,我們介紹了 TAPEX,一種表格預訓練方法,其語料庫透過取樣 SQL 查詢及其執行結果自動合成。TAPEX 透過在一個多樣化、大規模且高質量的合成語料庫上學習一個神經 SQL 執行器,解決了表格預訓練中的資料稀缺挑戰。在四個下游資料集上的實驗結果表明,TAPEX 的效能大幅優於以往的表格預訓練方法,並且預訓練效率更高。
要點
我們能從 TAPEX 的成功中學到什麼?我建議,特別是如果你想進行高效的持續預訓練,你可以嘗試以下選項:
- 合成一個精確且小型的語料庫,而不是從網際網路上挖掘一個龐大但嘈雜的語料庫。
- 透過程式模擬領域自適應的技能,而不是透過自然語言句子進行通用的語言建模。

