深度探究:Hugging Face Optimum Graphcore 上的 Vision Transformer

這篇部落格文章將展示如何在 Graphcore 智慧處理單元 (IPU) 上使用 Hugging Face Optimum 庫輕鬆地為您的資料集微調預訓練的 Transformer 模型。作為一個示例,我們將提供一個分步指南和一份筆記本,其中包含一個大型、廣泛使用的胸部 X 射線資料集,並訓練一個 Vision Transformer (ViT) 模型。
介紹 Vision Transformer (ViT) 模型
2017 年,一組 Google AI 研究人員發表了一篇論文,介紹了 Transformer 模型架構。Transformer 以其新穎的自注意力機制為特徵,被提出作為一種用於語言應用的新型高效模型組。事實上,在過去的五年中,Transformer 模型的受歡迎程度呈爆炸式增長,現在已被公認為自然語言處理 (NLP) 的事實標準。
用於語言的 Transformer 模型最顯著的代表可能是快速發展的 GPT 和 BERT 模型系列。兩者都可以在 Graphcore IPU 上輕鬆高效地執行,作為不斷增長的 Hugging Face Optimum Graphcore 庫的一部分。
顯示突出 Transformer 語言模型釋出時間表(圖片來源:Hugging Face)
關於 Transformer 模型架構的深入解釋(重點關注 NLP)可在 Hugging Face 網站上找到。
雖然 Transformer 模型最初在語言領域取得了成功,但它們用途極其廣泛,可用於一系列其他目的,包括計算機視覺 (CV),這正是我們將在本部落格文章中介紹的內容。
計算機視覺是一個卷積神經網路 (CNN) 無疑是最流行架構的領域。然而,Vision Transformer (ViT) 架構,最初由 Google Research 在 2021 年的一篇論文中提出,代表了影像識別領域的突破,並使用與 BERT 和 GPT 相同的自注意力機制作為其主要組成部分。
BERT 和其他基於 Transformer 的語言處理模型將句子(即單詞列表)作為輸入,而 ViT 模型將輸入影像分割成幾個小塊,相當於語言處理中的單個單詞。Transformer 模型將每個小塊線性編碼為可單獨處理的向量表示。這種將影像分割成小塊或視覺標記的方法與 CNN 使用的畫素陣列形成對比。
透過預訓練,ViT 模型學習影像的內部表示,然後可用於提取對下游任務有用的視覺特徵。例如,您可以透過在預訓練的視覺編碼器頂部放置一個線性層來在新標籤影像資料集上訓練分類器。通常將線性層放置在 [CLS] 標記的頂部,因為此標記的最後一個隱藏狀態可被視為整個影像的表示。
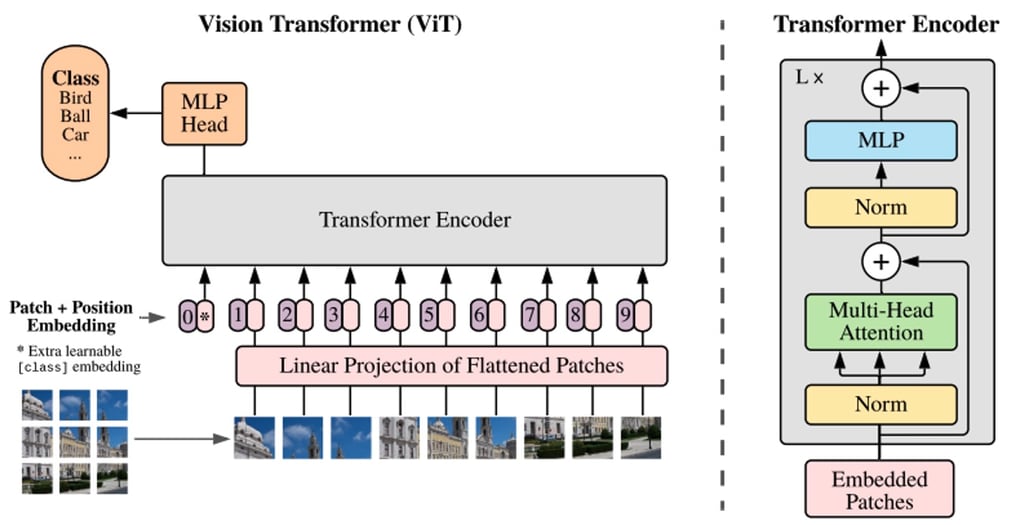
ViT 模型結構的概述,如 Google Research 2021 年原始論文中所述
與 CNN 相比,ViT 模型以更低的計算成本顯示出更高的識別精度,並應用於影像分類、目標檢測和分割等一系列應用。僅在醫療保健領域,用例就包括 COVID-19、股骨骨折、肺氣腫、乳腺癌 和 阿爾茨海默病 的檢測和分類等等。
ViT 模型 – IPU 的完美選擇
Graphcore IPU 特別適合 ViT 模型,因為它們能夠結合資料流水線和模型並行化來並行化訓練。透過 IPU 的 MIMD 架構及其以 IPU-Fabric 為中心的橫向擴充套件解決方案,加速這一大規模並行過程成為可能。
透過引入流水線並行化,可以增加每個資料並行例項可處理的批次大小,提高一個 IPU 處理的記憶體區域的訪問效率,並減少資料並行學習的引數聚合通訊時間。
由於開源 Hugging Face Optimum Graphcore 庫中添加了一系列預最佳化 Transformer 模型,因此在 IPU 上執行和微調 ViT 等模型時,實現高程度的效能和效率變得異常容易。
透過 Hugging Face Optimum,Graphcore 釋出了即用型 IPU 訓練的模型檢查點和配置檔案,以便輕鬆高效地訓練模型。這特別有用,因為 ViT 模型通常需要大量資料進行預訓練。這種整合允許您在 Hugging Face 模型中心使用原始作者釋出的檢查點,因此您無需自己訓練它們。透過讓使用者即插即用任何公共資料集,Optimum 縮短了 AI 模型的整體開發週期,並允許與 Graphcore 最先進的硬體無縫整合,從而加快了價值實現時間。
對於這篇部落格文章,我們將使用基於 Dosovitskiy 等人論文 An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale 在 ImageNet-21k 上預訓練的 ViT 模型。作為一個示例,我們將向您展示在 ChestX-ray14 資料集上使用 Optimum 微調 ViT 的過程。
ViT 模型對 X 射線分類的價值
與所有醫學成像任務一樣,放射科醫生需要多年時間才能可靠、高效地檢測問題並根據 X 射線影像做出初步診斷。在很大程度上,這種困難源於影像的微小差異和空間限制,這就是為什麼計算機輔助檢測和診斷 (CAD) 技術在改善臨床醫生工作流程和患者預後方面顯示出巨大的潛力。
同時,開發任何用於 X 射線分類的模型(無論是 ViT 還是其他)都將面臨其應有的挑戰:
- 從頭開始訓練模型需要大量帶標籤的資料;
- 高解析度和高容量要求意味著需要強大的計算能力來訓練此類模型;以及
- 由於疾病類別的數量,肺部診斷等多類別和多標籤問題的複雜性呈指數級增長。
如上所述,為了我們使用 Hugging Face Optimum 的演示目的,我們不需要從頭開始訓練 ViT。相反,我們將使用託管在 Hugging Face 模型中心的模型權重。
由於一張 X 射線影像可能包含多種疾病,我們將使用一個多標籤分類模型。該模型使用 google/vit-base-patch16-224-in21k 檢查點。它已從 TIMM 倉庫轉換而來,並在 ImageNet-21k 的 1400 萬張影像上進行了預訓練。為了並行化並最佳化 IPU 的任務,該配置已透過 Graphcore-ViT 模型卡提供。
如果您是第一次使用 IPU,請閱讀 IPU 程式設計師指南以瞭解基本概念。要在 IPU 上執行您自己的 PyTorch 模型,請參閱 Pytorch 基礎教程,並透過我們的 Hugging Face Optimum Notebooks 瞭解如何使用 Optimum。
在 ChestXRay-14 資料集上訓練 ViT
首先,我們需要下載美國國立衛生研究院 (NIH) 臨床中心 的 胸部 X 射線資料集。該資料集包含 1992 年至 2015 年期間 30,805 名患者的 112,120 張去識別化的正面 X 射線影像。該資料集涵蓋了基於使用 NLP 技術從放射報告文字中挖掘的標籤的 14 種常見疾病。
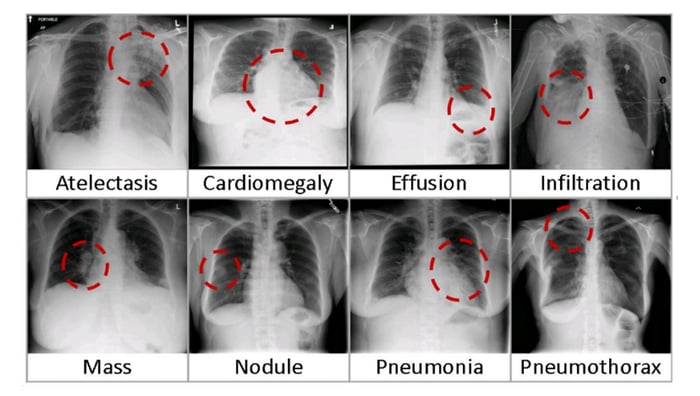
八個常見胸部疾病的視覺示例(圖片來源:NIC)
設定環境
以下是執行本演練的要求:
- 一個啟用最新 Poplar SDK 和 PopTorch 環境的 Jupyter Notebook 伺服器(請參閱我們關於 如何在 Jupyter notebooks 中使用 IPU 的指南)
- 來自 Graphcore Tutorials 倉庫的 ViT 訓練筆記本
Graphcore Tutorials 倉庫包含本指南中討論的分步教程筆記本和 Python 指令碼。克隆倉庫並啟動在 `tutorials/tutorials/pytorch/vit_model_training/` 中找到的 walkthrough.ipynb 筆記本。
我們甚至透過建立 HF Optimum Gradient 使其變得更容易,這樣您就可以在 Free IPU 中啟動入門教程。註冊並啟動執行時![]()
獲取資料集
下載資料集的 `/images` 目錄。您可以使用 `bash` 提取檔案:`for f in images*.tar.gz; do tar xfz "$f"; done`。
接下來,下載 `Data_Entry_2017_v2020.csv` 檔案,其中包含標籤。預設情況下,教程期望 `/images` 資料夾和 .csv 檔案與正在執行的指令碼位於同一資料夾中。
一旦您的 Jupyter 環境擁有資料集,您需要安裝並匯入最新的 Hugging Face Optimum Graphcore 包和 `requirements.txt` 中的其他依賴項。
%pip install -r requirements.txt
胸部 X 射線資料集中包含的檢查包括 X 射線影像(灰度,224x224 畫素)和相應的元資料:`Finding Labels, Follow-up #, Patient ID, Patient Age, Patient Gender, View Position, OriginalImage[Width Height] 和 OriginalImagePixelSpacing[x y]`。
接下來,我們定義已下載影像的位置以及要在獲取資料集中下載的標籤檔案。
我們將訓練 Graphcore Optimum ViT 模型來根據影像預測疾病(由“Finding Label”定義)。“Finding Label”可以是 14 種疾病中的任意一種,也可以是“No Finding”標籤,表示未檢測到疾病。為了與 Hugging Face 庫相容,文字標籤需要轉換為 N-hot 編碼陣列,表示分類每張影像所需的多個標籤。N-hot 編碼陣列將標籤表示為布林值列表,如果標籤與影像對應則為 true,否則為 false。
首先,我們確定資料集中的唯一標籤。
現在我們將標籤轉換為 N-hot 編碼陣列
使用 `datasets.load_dataset` 函式載入資料時,可以透過為每個標籤建立資料夾(請參閱“ImageFolder”文件)或使用 `metadata.jsonl` 檔案(請參閱“ImageFolder with metadata”文件)來提供標籤。由於此資料集中的影像可以有多個標籤,我們選擇使用 `metadata.jsonl` 檔案。我們將影像檔名及其相關標籤寫入 `metadata.jsonl` 檔案。
建立資料集
我們現在準備建立 PyTorch 資料集並將其分割為訓練集和驗證集。此步驟將資料集轉換為 Arrow 檔案格式,該格式允許在訓練和驗證期間快速載入資料(關於 Arrow 和 Hugging Face)。由於整個資料集正在載入和預處理,因此可能需要幾分鐘。
我們將從檢查點 `google/vit-base-patch16-224-in21k` 匯入 ViT 模型。該檢查點是 Hugging Face 託管的標準模型,不受 Graphcore 管理。
為了微調預訓練模型,新資料集必須與用於預訓練的原始資料集具有相同的屬性。在 Hugging Face 中,原始資料集資訊在透過 `AutoImageProcessor` 載入的配置檔案中提供。對於此模型,X 射線影像被調整為正確的解析度 (224x224),從灰度轉換為 RGB,並使用平均值 (0.5, 0.5, 0.5) 和標準差 (0.5, 0.5, 0.5) 在 RGB 通道上進行歸一化。
為了使模型高效執行,影像需要進行批次處理。為此,我們定義了 `vit_data_collator` 函式,該函式按照 Transformers Data Collator 中的 `default_data_collator` 模式,以字典形式返回影像和標籤的批次。
視覺化資料集
為了檢查資料集,我們顯示了前 10 行元資料。
我們還繪製了一些來自驗證集的影像及其關聯標籤。
這些影像是胸部 X 射線,標籤是患者被診斷出的肺部疾病。這裡,我們展示了轉換後的影像。
我們的資料集現在可以使用了。
準備模型
要在 IPU 上訓練模型,我們需要從 Hugging Face Hub 匯入它,並使用 IPUTrainer 類定義一個訓練器。IPUTrainer 類接受與原始 Transformer Trainer 相同的引數,並與 IPUConfig 物件協同工作,該物件指定了在 IPU 上編譯和執行的行為。
現在我們從 Hugging Face 匯入 ViT 模型。
要在 IPU 上使用此模型,我們需要載入 IPU 配置 `IPUConfig`,它控制 Graphcore IPU 特定的所有引數(現有的 IPU 配置可在此處找到)。我們將使用 `Graphcore/vit-base-ipu`。
讓我們使用 `IPUTrainingArguments` 設定我們的訓練超引數。這繼承了 Hugging Face `TrainingArguments` 類,並添加了 IPU 及其執行特性特有的引數。
實現用於評估的自定義效能指標
多標籤分類模型的效能可以使用 ROC(受試者工作特徵)曲線下面積(AUC_ROC)進行評估。AUC_ROC 是不同類別在不同閾值下的真陽性率 (TPR) 與假陽性率 (FPR) 的曲線圖。這是多標籤分類任務中常用的效能指標,因為它對類別不平衡不敏感且易於解釋。
對於此資料集,AUC_ROC 代表模型區分不同疾病的能力。0.5 的分數意味著正確診斷疾病的可能性為 50%,而 1 的分數意味著它可以完美區分疾病。此指標在 Datasets 中不可用,因此我們需要自己實現它。HuggingFace Datasets 包允許透過 `load_metric()` 函式進行自定義指標計算。我們定義一個 `compute_metrics` 函式,並將其暴露給 Transformer 的評估函式,就像透過 datasets 包支援的其他指標一樣。`compute_metrics` 函式接受 ViT 模型預測的標籤,並計算 ROC 曲線下面積。`compute_metrics` 函式接受一個 `EvalPrediction` 物件(一個帶有 `predictions` 和 `label_ids` 欄位的命名元組),並且必須返回一個字串到浮點數的字典。
為了訓練模型,我們使用 `IPUTrainer` 類定義了一個訓練器,該類負責將模型編譯到 IPU 上執行,並執行訓練和評估。`IPUTrainer` 類的工作方式與 Hugging Face Trainer 類相同,但接受額外的 `ipu_config` 引數。
執行訓練
為了加速訓練,如果存在,我們將載入最後一個檢查點。
現在我們準備開始訓練了。
繪製收斂圖
現在我們已經完成了訓練,我們可以格式化並繪製訓練器輸出以評估訓練行為。
我們繪製訓練損失和學習率。
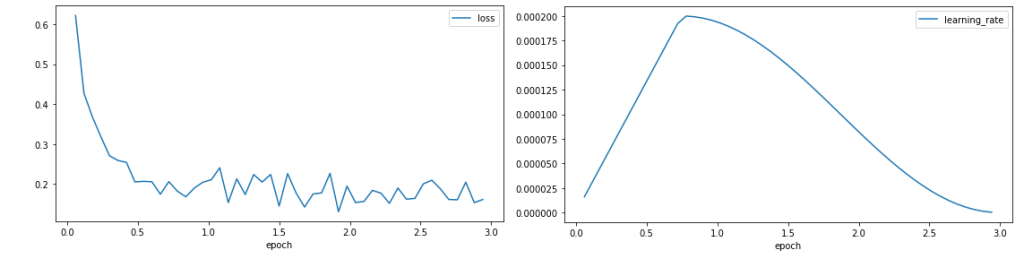 損失曲線顯示,訓練開始時損失迅速下降,然後穩定在 0.1 左右,表明模型正在學習。學習率在訓練期的 25% 預熱階段增加,然後遵循餘弦衰減。
損失曲線顯示,訓練開始時損失迅速下降,然後穩定在 0.1 左右,表明模型正在學習。學習率在訓練期的 25% 預熱階段增加,然後遵循餘弦衰減。
執行評估
現在我們已經訓練了模型,我們可以使用驗證資料集評估其預測未見資料標籤的能力。
這些指標顯示了教程在 3 個 epoch 後達到的驗證 AUC_ROC 分數。
有幾個方向可以探索以提高模型的準確性,包括更長的訓練。驗證效能也可以透過更改最佳化器、學習率、學習率排程、損失縮放或使用自動損失縮放來提高。
免費試用 IPU 上的 Hugging Face Optimum
在這篇文章中,我們介紹了 ViT 模型,並提供了使用本地資料集在 IPU 上訓練 Hugging Face Optimum 模型的教程。
得益於 Graphcore 與 Paperspace 的新合作關係,上述整個過程現在可以在幾分鐘內免費端到端執行。該服務於今日啟動,將透過 Paperspace 基於網路的 Jupyter Notebooks——Gradient,提供對由 Graphcore IPU 提供支援的部分 Hugging Face Optimum 模型(包括 ViT、BERT、RoBERTa 等)的訪問。
![]()
如果您有興趣在 Paperspace Gradient 上免費試用包含 ViT、BERT、RoBERTa 等模型的 Hugging Face Optimum with IPU,您可以在此處註冊,並在此處找到入門指南。
IPU 上 Hugging Face Optimum 的更多資源
如果沒有 Graphcore 的 Eva Woodbridge、James Briggs、Jinchen Ge、Alexandre Payot、Thorin Farnsworth 和所有其他貢獻者,以及 Hugging Face 的 Jeff Boudier、Julien Simon 和 Michael Benayoun 的大力支援、指導和見解,本次深度探究將無法實現。

