透過 DeepSpeed 和 FairScale 使用 ZeRO: 塞下更多資料,訓練速度更快





Hugging Face 研究員 Stas Bekman 的客座博文
由於近年來機器學習模型的增長速度遠快於新發布顯示卡的 GPU 視訊記憶體增長速度,許多使用者無法在自己的硬體上訓練,甚至無法載入一些大型模型。雖然目前正在努力將這些大型模型蒸餾成更易於管理的大小,但這項工作的進展還不夠快,產出的模型也不夠小。
2019 年秋,Samyam Rajbhandari、Jeff Rasley、Olatunji Ruwase 和 Yuxiong He 發表了一篇論文:ZeRO: 面向萬億引數模型訓練的視訊記憶體最佳化技術,其中包含了大量巧妙的新思想,闡述瞭如何讓硬體發揮出遠超以往想象的效能。不久之後,DeepSpeed 釋出了,它向世界提供了該論文中大部分思想的開源實現(一些思想仍在開發中)。與此同時,Facebook 的一個團隊釋出了 FairScale,它也實現了 ZeRO 論文中的一些核心思想。
如果你使用 Hugging Face Trainer,從 transformers v4.2.0 版本開始,你將獲得對 DeepSpeed 和 FairScale 的 ZeRO 功能的實驗性支援。新的 --sharded_ddp 和 --deepspeed 命令列 Trainer 引數分別提供了 FairScale 和 DeepSpeed 的整合。這裡是完整的文件。
這篇博文將介紹如何利用 ZeRO,無論你擁有一塊 GPU 還是多塊 GPU。
多 GPU 設定下的巨大加速
讓我們用 t5-large 模型和 finetune_trainer.py 指令碼做一個小型的翻譯任務微調實驗,你可以在 transformers GitHub 倉庫的 examples/seq2seq 目錄下找到這個指令碼。
我們有 2 塊 24GB (Titan RTX) GPU 用於測試。
這只是一個概念驗證的基準測試,所以肯定還有進一步最佳化的空間。我們將在一個包含 2000 個訓練樣本和 500 個評估樣本的小資料集上進行基準測試,以便進行比較。評估預設使用大小為 4 的束搜尋 (beam search),所以它比同樣樣本數量的訓練要慢,這就是為什麼這些測試中評估樣本數量少了 4 倍。
以下是我們基準測試的關鍵命令列引數:
export BS=16
python -m torch.distributed.launch --nproc_per_node=2 ./finetune_trainer.py \
--model_name_or_path t5-large --n_train 2000 --n_val 500 \
--per_device_eval_batch_size $BS --per_device_train_batch_size $BS \
--task translation_en_to_ro [...]
對於基準測試,我們只使用了 DistributedDataParallel (DDP) 來提升效能,沒有使用其他任何技術。在出現記憶體不足 (OOM) 錯誤之前,我能夠將批處理大小 (BS) 設為 16。
注意,為了簡單和易於理解,我只展示了對這次演示重要的命令列引數。你可以在這篇文章中找到完整的命令列。
接下來,我們將每次新增以下一項重新執行基準測試:
--fp16--sharded_ddp(fairscale)--sharded_ddp --fp16(fairscale)--deepspeed(不帶 CPU 解除安裝)--deepspeed(帶 CPU 解除安裝)
由於這裡的關鍵最佳化是每種技術都更有效地利用了 GPU RAM,我們將嘗試不斷增加批處理大小,並期望訓練和評估能夠更快地完成(同時保持指標穩定甚至有所改善,但我們在這裡不關注這些)。
請記住,訓練和評估階段彼此非常不同,因為在訓練期間,模型權重會被修改,梯度會被計算,最佳化器狀態會被儲存。而在評估期間,這些都不會發生,但在翻譯這個特定任務中,模型會嘗試搜尋最佳假設,因此在滿意之前實際上需要進行多次執行。這就是為什麼它不快,尤其是在模型很大的情況下。
讓我們看看這六次測試執行的結果:
| 方法 | 最大批處理大小 (BS) | 訓練時間 | 評估時間 |
|---|---|---|---|
| 基準 | 16 | 30.9458 | 56.3310 |
| fp16 | 20 | 21.4943 | 53.4675 |
| sharded_ddp | 30 | 25.9085 | 47.5589 |
| sharded_ddp+fp16 | 30 | 17.3838 | 45.6593 |
| deepspeed (無 cpu 解除安裝) | 40 | 10.4007 | 34.9289 |
| deepspeed (有 cpu 解除安裝) | 50 | 20.9706 | 32.1409 |
很容易看出,FairScale 和 DeepSpeed 在總訓練和評估時間以及批處理大小方面都比基準有了很大的改進。截至本文撰寫之時,DeepSpeed 實現了更多的“魔法”,似乎是短期的贏家,但 Fairscale 更容易部署。對於 DeepSpeed,你需要編寫一個簡單的配置檔案並更改命令列的啟動器;而對於 Fairscale,你只需要新增 --sharded_ddp 命令列引數,所以你可能想先嚐試它,因為這是最容易實現的最佳化。
遵循 80:20 法則,我只在這些基準測試上花了幾小時,並沒有試圖透過最佳化命令列引數和配置來榨乾每一MB視訊記憶體和每一秒時間,因為從這個簡單的表格中可以很清楚地看出你接下來想嘗試什麼。當你面對一個將要執行數小時甚至數天的真實專案時,一定要花更多時間來確保你使用最優的超引數,以更快、成本最低的方式完成工作。
如果你想自己試驗這個基準測試,或者想了解更多關於執行它所使用的硬體和軟體的細節,請參考這篇文章。
將巨大模型裝入單個 GPU
雖然 Fairscale 只有在多 GPU 的情況下才能給我們帶來效能提升,但 DeepSpeed 即使對我們這些只有一個 GPU 的人來說也是一份禮物。
讓我們來嘗試一件不可能的事——在一張 24GB 的 RTX-3090 顯示卡上訓練 t5-3b。
首先,讓我們嘗試使用正常的單 GPU 設定來微調巨大的 t5-3b 模型。
export BS=1
CUDA_VISIBLE_DEVICES=0 ./finetune_trainer.py \
--model_name_or_path t5-3b --n_train 60 --n_val 10 \
--per_device_eval_batch_size $BS --per_device_train_batch_size $BS \
--task translation_en_to_ro --fp16 [...]
沒戲,即使批處理大小 (BS) 為 1,我們還是會得到
RuntimeError: CUDA out of memory. Tried to allocate 64.00 MiB (GPU 0; 23.70 GiB total capacity;
21.37 GiB already allocated; 45.69 MiB free; 22.05 GiB reserved in total by PyTorch)
注意,和之前一樣,我只展示了重要的部分,完整的命令列引數可以在這裡找到。
現在將你的 transformers 更新到 v4.2.0 或更高版本,然後安裝 DeepSpeed
pip install deepspeed
然後我們再試一次,這次在命令列中加入 DeepSpeed
export BS=20
CUDA_VISIBLE_DEVICES=0 deepspeed --num_gpus=1 ./finetune_trainer.py \
--model_name_or_path t5-3b --n_train 60 --n_val 10 \
--per_device_eval_batch_size $BS --per_device_train_batch_size $BS \
--task translation_en_to_ro --fp16 --deepspeed ds_config_1gpu.json [...]
瞧!我們成功地訓練了一個批處理大小為 20 的模型。我或許還能把它推得更高。程式在 BS=30 時因記憶體不足 (OOM) 而失敗。
以下是相關的結果:
2021-01-12 19:06:31 | INFO | __main__ | train_n_objs = 60
2021-01-12 19:06:31 | INFO | __main__ | train_runtime = 8.8511
2021-01-12 19:06:35 | INFO | __main__ | val_n_objs = 10
2021-01-12 19:06:35 | INFO | __main__ | val_runtime = 3.5329
我們無法將這些與基準進行比較,因為基準甚至無法啟動,並立即因記憶體不足 (OOM) 而失敗。
簡直太神奇了!
我只使用了一個非常小的樣本,因為我主要感興趣的是能夠用這個通常無法裝入 24GB GPU 的巨大模型進行訓練和評估。
如果你想自己試驗這個基準測試,或者想了解更多關於執行它所使用的硬體和軟體的細節,請參考這篇文章。
ZeRO 背後的魔法
由於 transformers 只是集成了這些出色的解決方案,而不是參與了它們的發明,我將分享一些資源,你可以從中發現所有細節。但這裡有幾個快速的見解,可能有助於理解 ZeRO 如何實現這些驚人的壯舉。
ZeRO 的關鍵特性是在大家非常熟悉的資料並行訓練概念中加入了分散式資料儲存。
每個 GPU 上的計算與資料並行訓練完全相同,但引數、梯度和最佳化器狀態以分散式/分割槽的方式儲存在所有 GPU 上,並且僅在需要時才獲取。
下圖來自這篇博文,說明了其工作原理。
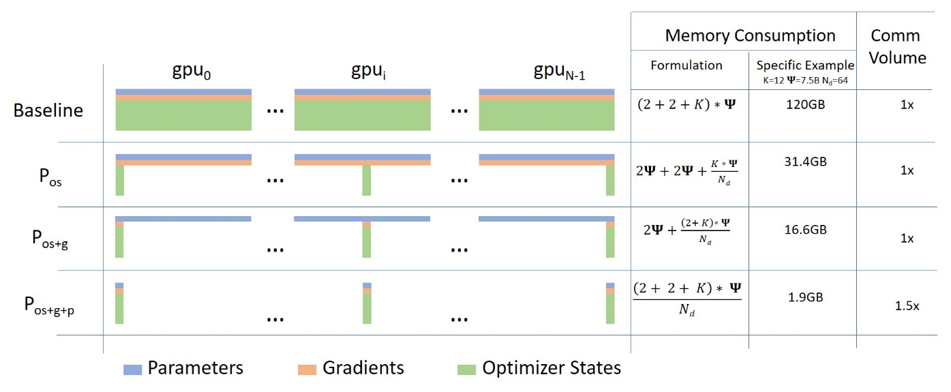
ZeRO 的巧妙方法是將引數、梯度和最佳化器狀態平均分配到所有 GPU 上,並給每個 GPU 僅一個分割槽(也稱為分片)。這導致 GPU 之間的資料儲存零重疊。在執行時,每個 GPU 透過請求其他參與的 GPU 傳送其缺少的資訊來動態構建每一層的資料。
這個想法可能很難理解,你可以在這裡找到我對此的解釋嘗試。
截至本文撰寫之時,FairScale 和 DeepSpeed 僅對最佳化器狀態和梯度進行分割槽(分片)。模型引數分片據說很快將在 DeepSpeed 和 FairScale 中推出。
另一個強大的功能是 ZeRO-Offload (論文)。此功能將部分處理和記憶體需求解除安裝到主機的 CPU,從而允許將更多內容裝入 GPU。您在成功在 24GB GPU 上執行 t5-3b 的案例中看到了它的巨大影響。
很多人在 PyTorch 論壇上抱怨的另一個問題是 GPU 視訊記憶體碎片化。人們經常會遇到類似這樣的 OOM 錯誤:
RuntimeError: CUDA out of memory. Tried to allocate 1.48 GiB (GPU 0; 23.65 GiB total capacity;
16.22 GiB already allocated; 111.12 MiB free; 22.52 GiB reserved in total by PyTorch)
程式想要分配約 1.5GB 的記憶體,而 GPU 仍有約 6-7GB 的未使用記憶體,但它報告只有約 100MB 的連續可用記憶體,並因此出現 OOM 錯誤。這種情況發生是因為不同大小的記憶體塊被反覆分配和釋放,隨著時間的推移,會產生空洞,導致記憶體碎片化,即有很多未使用的記憶體,但沒有所需大小的連續記憶體塊。在上面的例子中,程式可能可以分配 100MB 的連續記憶體,但顯然無法獲得 1.5GB 的單個記憶體塊。
DeepSpeed 透過自行管理 GPU 記憶體來解決這個問題,並確保長期記憶體分配不與短期記憶體分配混合,從而大大減少了碎片化。雖然論文沒有詳細說明,但原始碼是可用的,因此可以瞭解 DeepSpeed 是如何實現這一點的。
由於 ZeRO 代表零冗餘最佳化器 (Zero Redundancy Optimizer),很容易看出它名副其實。
未來
除了 DeepSpeed 即將推出的對模型引數分片的支援外,它已經發布了我們尚未探索的新功能。這些功能包括 DeepSpeed 稀疏注意力和 1-bit Adam,它們應該能減少記憶體使用並顯著降低 GPU 間的通訊開銷,從而實現更快的訓練並支援更大的模型。
我相信我們也會看到 FairScale 團隊的新禮物。我想他們也在開發 ZeRO 第三階段。
更令人興奮的是,ZeRO 正在被整合到 PyTorch 中。
部署
如果您覺得這篇博文中分享的結果很吸引人,請訪問這裡,瞭解如何將 DeepSpeed 和 FairScale 與 transformers Trainer 結合使用的詳細資訊。
當然,你也可以根據每個專案的說明修改你自己的訓練器來整合 DeepSpeed 和 FairScale,或者你可以“抄作業”,看看我們是如何在 transformers Trainer 中實現的。如果你選擇後者,可以在原始碼中用 grep 搜尋 deepspeed 和/或 sharded_ddp 來找到相關程式碼。
好訊息是 ZeRO 不需要修改模型。唯一需要的修改是在訓練程式碼中。
問題
如果您在整合這兩個專案時遇到任何問題,請在 transformers 中提交一個 Issue。
但是,如果您在 DeepSpeed 和 FairScale 的安裝、配置和部署方面遇到問題,您需要向其領域的專家求助,因此,請改用 DeepSpeed Issue 或 FairScale Issue。
資源
雖然您並不真的需要了解這些專案的工作原理,可以直接透過 transformers Trainer 來部署它們,但如果您想弄清楚其中的原因和方式,請參考以下資源。
論文:ZeRO: 面向萬億引數模型訓練的視訊記憶體最佳化技術。這篇論文非常有趣,但非常簡潔。
這是一個很好的影片討論,帶有圖示,對論文進行了解釋
論文:ZeRO-Offload: 讓十億級模型訓練大眾化。剛剛發表 - 這篇論文詳細介紹了 ZeRO Offload 功能。
DeepSpeed 配置和教程
除了論文,我強烈推薦閱讀以下帶有圖表的詳細博文
DeepSpeed GitHub 上的示例
致謝
在我們致力於將這些專案整合到 transformers 的過程中,FairScale 和 DeepSpeed 開發團隊給予了我們驚人水平的支援,我們對此感到非常驚訝。
我特別想感謝
- Benjamin Lefaudeux @blefaudeux
- Mandeep Baines @msbaines
來自 FairScale 團隊,以及
來自 DeepSpeed 團隊,感謝你們慷慨而周到的支援,以及迅速解決我們遇到的問題。
並感謝 HuggingFace 提供了執行基準測試的硬體。

