在 🤗 Transformers 中使用 Wav2Vec2 處理大檔案實現自動語音識別







Tl;dr: This post explains how to use the specificities of the Connectionist
Temporal Classification (CTC) architecture in order to achieve very good
quality automatic speech recognition (ASR) even on arbitrarily long files or
during live inference.
Wav2Vec2 是一種流行的預訓練語音識別模型。該模型由 Meta AI Research 於 2020 年 9 月 釋出,其新穎的架構推動了語音識別自監督預訓練的進展,例如 G. Ng 等人,2021、Chen 等人,2021、Hsu 等人,2021 和 Babu 等人,2021。在 Hugging Face Hub 上,Wav2Vec2 最受歡迎的預訓練檢查點目前每月下載量超過 25 萬次。
Wav2Vec2 本質上是一個 transformers 模型,而 transformers 的一個缺點是它通常只能處理有限的序列長度。這可能是因為它使用 位置編碼(這裡不是這種情況),或者僅僅是因為 transformers 中注意力的成本實際上是序列長度的 O(n²),這意味著使用非常大的序列長度會導致複雜性/記憶體爆炸。因此,你無法在有限的硬體(即使是像 A100 這樣非常大的 GPU)上,直接對一小時長的檔案執行 Wav2Vec2。你的程式會崩潰。讓我們來試試看!
pip install transformers
from transformers import pipeline
# This will work on any of the thousands of models at
# https://huggingface.co/models?pipeline_tag=automatic-speech-recognition
pipe = pipeline(model="facebook/wav2vec2-base-960h")
# The Public Domain LibriVox file used for the test
#!wget https://ia902600.us.archive.org/8/items/thecantervilleghostversion_2_1501_librivox/thecantervilleghostversion2_01_wilde_128kb.mp3 -o very_long_file.mp3
pipe("very_long_file.mp3")
# Crash out of memory !
pipe("very_long_file.mp3", chunk_length_s=10)
# This works and prints a very long string !
# This whole blogpost will explain how to make things work
簡單分塊
在超長檔案上進行推理的最簡單方法是將原始音訊簡單地分塊成更短的樣本,比如說每個 10 秒,然後對這些樣本進行推理,最後進行最終的重建。這種方法計算效率高,但通常會導致次優結果,原因是模型為了進行良好的推理需要一些上下文,所以在分塊邊界附近,推理質量往往較差。
請看下圖:
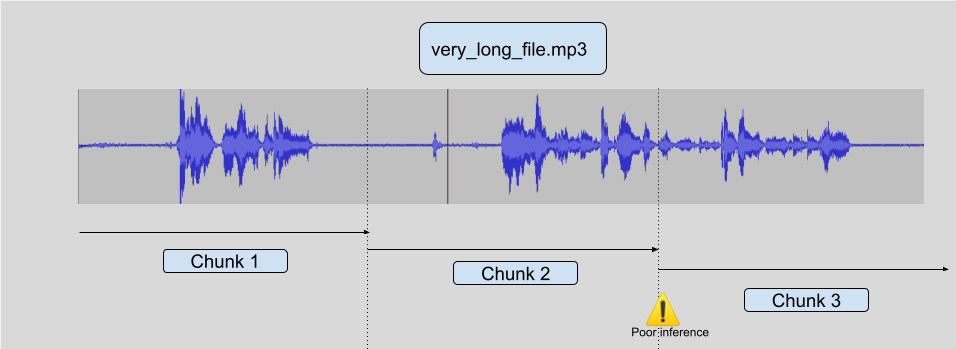
有一些方法可以嘗試普遍解決這個問題,但它們從來都不是完全可靠的。你可以嘗試只在遇到靜音時進行分塊,但你可能會長時間遇到非靜音音訊(一首歌,或嘈雜的咖啡館音訊)。你也可以嘗試只在沒有語音時進行切割,但這需要另一個模型,而且這不是一個完全解決的問題。你也可能會長時間持續發聲。
事實證明,Wav2Vec2 所使用的 CTC 結構可以被利用,以實現在超長檔案上也非常強大的語音識別,而不會陷入這些陷阱。
帶步長的分塊
Wav2Vec2 使用 CTC 演算法,這意味著音訊的每一幀都對映到一個字母預測(logit)。
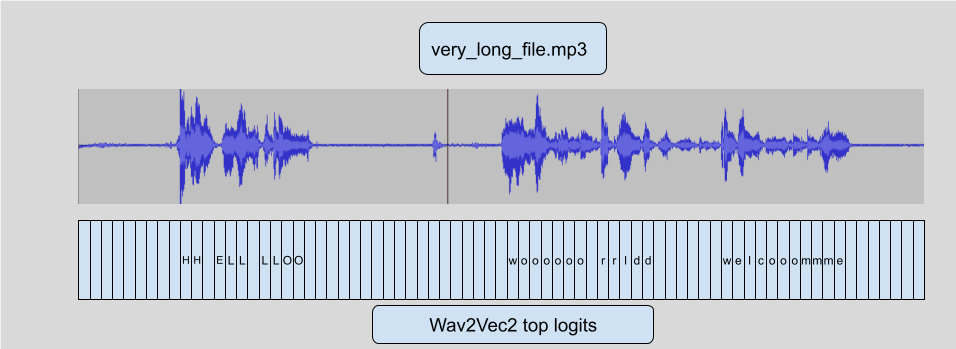
這是我們將用於新增 `stride` 的主要功能。這個 連結 在影像上下文中解釋了它,但對於音訊來說是相同的概念。由於這個特性,我們可以:
- 開始對**重疊**的塊進行推理,以便模型在中心實際具有適當的上下文。
- **丟棄**側面的推理 logits。
- 連結**logits**,不包含它們丟棄的側面,以恢復與模型在完整長度音訊上預測的結果極其相似的內容。
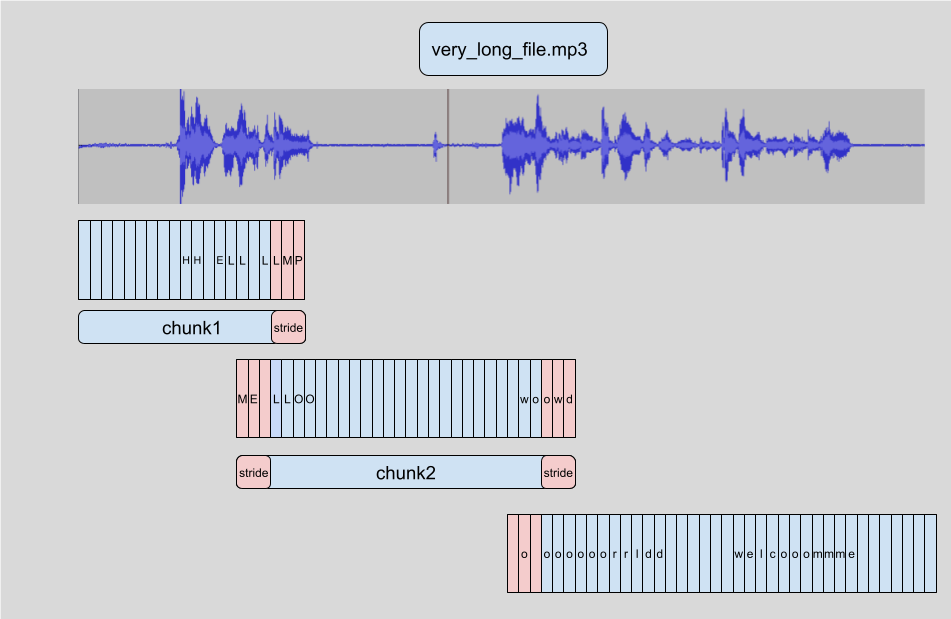
這在**技術上**與在整個檔案上執行模型不完全相同,因此預設情況下未啟用,但正如您在前面的示例中看到的,您只需在 `pipeline` 中新增 `chunk_length_s` 即可使其工作。
在實踐中,我們觀察到大多數不良推理都保留在步長內,這些步長在推理之前被丟棄,從而導致對完整文字的正確推理。
請注意,您可以選擇此技術的所有引數
from transformers import pipeline
pipe = pipeline(model="facebook/wav2vec2-base-960h")
# stride_length_s is a tuple of the left and right stride length.
# With only 1 number, both sides get the same stride, by default
# the stride_length on one side is 1/6th of the chunk_length_s
output = pipe("very_long_file.mp3", chunk_length_s=10, stride_length_s=(4, 2))
在 LM 增強模型上帶步長的分塊
在 transformers 中,我們還增加了對 Wav2Vec2 新增 LM 的支援,以在不進行微調的情況下提高模型的 WER 效能。請參閱這篇出色的部落格文章,瞭解其工作原理。
事實證明,LM 直接作用於 logits 本身,因此我們可以不加任何修改地應用與之前完全相同的技術!因此,在這些 LM 增強模型上對大檔案進行分塊仍然可以直接使用。
即時推理
使用 Wav2vec2 這樣的 CTC 模型有一個非常好的優點,那就是它是一個單程模型,所以速度**非常**快。尤其是在 GPU 上。我們可以利用這一點進行即時推理。
原理與常規步進完全相同,但這次我們可以**在資料傳入時**將資料饋送到管道,並簡單地對長度為 10 秒的完整塊使用步進,例如 1 秒的步進,以獲得適當的上下文。
這需要比簡單的檔案分塊執行更多的推理步驟,但它可以大大改善即時體驗,因為模型可以在您說話時列印內容,而無需等待 X 秒才能看到顯示內容。