理解 BigBird 的塊稀疏注意力機制





簡介
基於 Transformer 的模型已被證明在許多 NLP 任務中非常有用。然而,基於 Transformer 的模型的一個主要限制是其 的時間和記憶體複雜度(其中 是序列長度)。因此,將基於 Transformer 的模型應用於長序列()在計算上非常昂貴。最近的一些論文,例如 Longformer、Performer、Reformer、Clustered attention 試圖透過近似完整的注意力矩陣來解決這個問題。如果你不熟悉這些模型,可以檢視 🤗 最近的這篇博文 post。
BigBird(在這篇論文中提出)是解決此問題的最新模型之一。BigBird 依賴於**塊稀疏注意力**(block sparse attention)而不是普通的注意力(即 BERT 的注意力),並且可以處理長達 **4096** 的序列,其計算成本遠低於 BERT。它在涉及非常長序列的各種任務上取得了 SOTA(State-of-the-Art)的成績,例如長文件摘要、長上下文問答。
類 BigBird RoBERTa 的模型現已在 🤗Transformers 中提供。這篇文章的目標是讓讀者**深入**理解 BigBird 的實現,並簡化在 🤗Transformers 中使用 BigBird 的過程。但在深入探討之前,重要的是要記住,BigBird 的注意力是對 BERT 完整注意力的一種近似,因此它並不追求**優於** BERT 的完整注意力,而是為了更高效。它只是使得基於 Transformer 的模型能夠應用於更長的序列,因為 BERT 的二次方記憶體需求很快變得無法承受。簡而言之,如果我們擁有的計算資源和的時間,BERT 的注意力會比塊稀疏注意力(我們將在本文中討論)更受青睞。
如果你想知道為什麼在處理更長序列時需要更多的計算資源,那麼這篇博文正適合你!
在使用標準的類 BERT 注意力時,人們可能會有的一些主要問題包括:
- 所有的 token 真的都需要關注所有其他的 token 嗎?
- 為什麼不只計算對重要 token 的注意力呢?
- 如何判斷哪些 token 是重要的?
- 如何以一種非常高效的方式只關注少數 token?
在這篇博文中,我們將嘗試回答這些問題。
哪些 token 應該被關注?
我們將透過一個實際例子來解釋注意力機制的工作原理,以句子 "BigBird is now available in HuggingFace for extractive question answering" 為例。在類 BERT 的注意力機制中,每個詞都會簡單地關注所有其他 token。用數學語言來說,這意味著每個查詢 token ,都會關注完整的鍵 token 列表 。
讓我們透過編寫一些虛擬碼來思考一下,對於一個查詢 token,哪些鍵 token 才是它真正應該關注的。我們將假設查詢的 token 是 `available`,併為其構建一個合理的鍵 token 列表。
>>> # let's consider following sentence as an example
>>> example = ['BigBird', 'is', 'now', 'available', 'in', 'HuggingFace', 'for', 'extractive', 'question', 'answering']
>>> # further let's assume, we're trying to understand the representation of 'available' i.e.
>>> query_token = 'available'
>>> # We will initialize an empty `set` and fill up the tokens of our interest as we proceed in this section.
>>> key_tokens = [] # => currently 'available' token doesn't have anything to attend
鄰近的 token 應該是重要的,因為在一個句子(詞序列)中,當前詞高度依賴於其相鄰的過去和未來 token。這種直覺是 `滑動注意力`(sliding attention)概念背後的思想。
>>> # considering `window_size = 3`, we will consider 1 token to left & 1 to right of 'available'
>>> # left token: 'now' ; right token: 'in'
>>> sliding_tokens = ["now", "available", "in"]
>>> # let's update our collection with the above tokens
>>> key_tokens.append(sliding_tokens)
長程依賴:對於某些任務來說,捕捉 token 之間的長程關係至關重要。例如,在“問答”任務中,模型需要將上下文的每個 token 與整個問題進行比較,以便找出上下文的哪一部分對正確答案有用。如果大部分上下文 token 只關注其他上下文 token,而不關注問題,那麼模型就很難從不太重要的上下文 token 中篩選出重要的上下文 token。
現在,`BigBird` 提出了兩種在保持計算效率的同時允許長程注意力依賴的方法。
- 全域性 token:引入一些 token,它們將關注每一個 token,並且被每一個 token 所關注。例如:“HuggingFace is building nice libraries for easy NLP”。現在,假設我們將“building”定義為一個全域性 token,而模型需要知道“NLP”和“HuggingFace”之間的關係以完成某個任務(注意:這兩個 token 位於句子的兩端);現在讓“building”全域性關注所有其他 token,這很可能會幫助模型將“NLP”與“HuggingFace”聯絡起來。
>>> # let's assume 1st & last token to be `global`, then
>>> global_tokens = ["BigBird", "answering"]
>>> # fill up global tokens in our key tokens collection
>>> key_tokens.append(global_tokens)
- 隨機 token:隨機選擇一些 token,它們透過將資訊傳遞給其他 token,而這些 token 又可以將資訊傳遞給其他 token,從而實現資訊傳遞。這可以降低資訊從一個 token 傳遞到另一個 token 的成本。
>>> # now we can choose `r` token randomly from our example sentence
>>> # let's choose 'is' assuming `r=1`
>>> random_tokens = ["is"] # Note: it is chosen compleletly randomly; so it can be anything else also.
>>> # fill random tokens to our collection
>>> key_tokens.append(random_tokens)
>>> # it's time to see what tokens are in our `key_tokens` list
>>> key_tokens
{'now', 'is', 'in', 'answering', 'available', 'BigBird'}
# Now, 'available' (query we choose in our 1st step) will attend only these tokens instead of attending the complete sequence
這樣,查詢 token 只關注所有可能 token 的一個子集,同時可以很好地近似完整的注意力。同樣的方法也適用於所有其他查詢 token。但請記住,這裡的關鍵在於儘可能高效地近似 `BERT` 的完整注意力。簡單地讓每個查詢 token 像 BERT 那樣關注所有鍵 token,可以在現代硬體(如 GPU)上非常高效地計算為一系列矩陣乘法。然而,滑動、全域性和隨機注意力的組合似乎意味著稀疏矩陣乘法,這在現代硬體上難以高效實現。`BigBird` 的主要貢獻之一是提出了一種 `塊稀疏` 注意力機制,該機制可以有效地計算滑動、全域性和隨機注意力。讓我們深入瞭解一下!
透過圖理解全域性、滑動和隨機鍵的必要性
首先,讓我們使用圖來更好地理解 `全域性`、`滑動` 和 `隨機` 注意力,並嘗試理解這三種注意力機制的組合如何能很好地近似標準的 `Bert-like` 注意力。
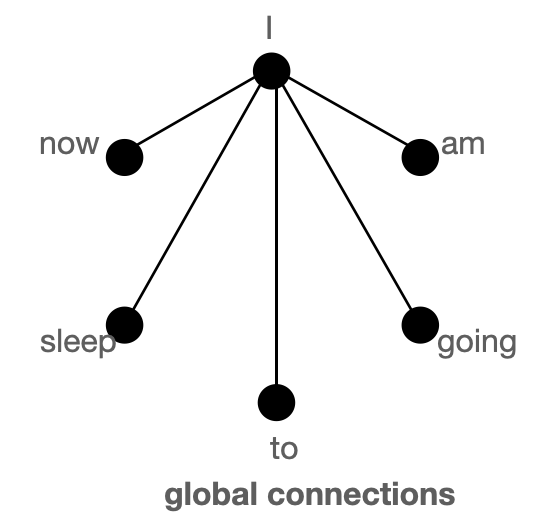
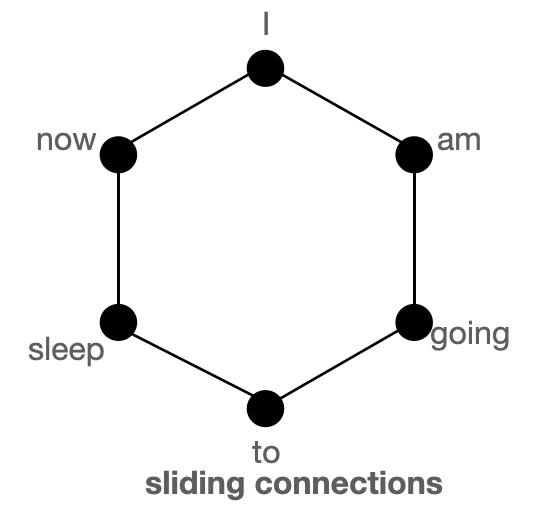
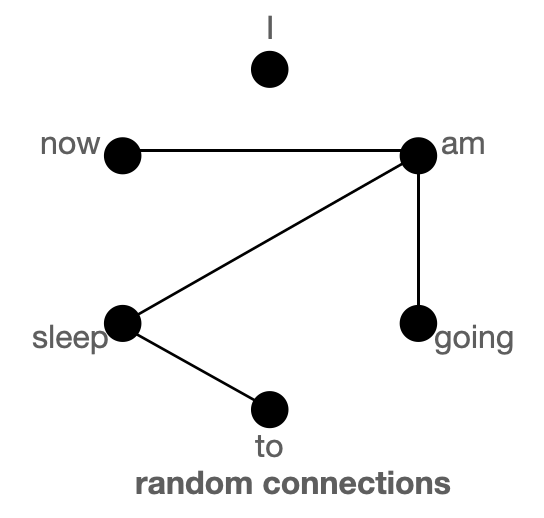
上圖分別以圖的形式展示了 `全域性`(左)、`滑動`(中)和 `隨機`(右)連線。每個節點對應一個 token,每條線代表一個注意力分數。如果兩個 token 之間沒有連線,則假定注意力分數為 0。

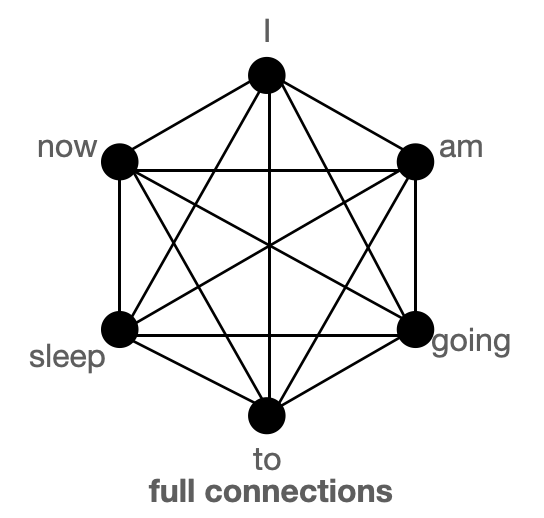
BigBird 塊稀疏注意力是滑動、全域性和隨機連線的組合(總共 10 個連線),如左側的 `gif` 所示。而一個**普通注意力**(右)的圖將擁有所有 15 個連線(注意:總共有 6 個節點)。你可以簡單地認為普通注意力是所有 token 都進行全域性關注。
普通注意力:模型可以在單層內直接將資訊從一個 token 傳遞到另一個 token,因為每個 token 都會查詢所有其他 token,並被所有其他 token 關注。讓我們考慮一個與上圖類似的例子。如果模型需要將“going”與“now”關聯起來,它可以在單層內簡單地做到這一點,因為有一條直接連線這兩個 token 的線。
塊稀疏注意力:如果模型需要在兩個節點(或 token)之間共享資訊,對於某些 token,資訊將不得不沿著路徑上的其他各個節點傳播;因為並非所有節點都在單層內直接連線。例如,假設模型需要將“going”與“now”關聯起來,那麼如果只有滑動注意力存在,這兩個 token 之間的資訊流將由路徑:`going -> am -> i -> now` 定義(即資訊必須經過另外兩個 token)。因此,我們可能需要多層來捕捉序列的全部資訊。而普通注意力可以在單層內捕捉到這一點。在極端情況下,這可能意味著需要與輸入 token 數量一樣多的層。然而,如果我們引入一些全域性 token,資訊可以透過路徑:`going -> i -> now`(更短)傳播。如果我們再引入隨機連線,資訊可以透過:`going -> am -> now` 傳播。藉助隨機連線和全域性連線,資訊可以非常迅速地(只需幾層)從一個 token 傳遞到下一個 token。
如果我們有很多全域性 token,那麼我們可能就不需要隨機連線了,因為將會有多條短路徑可以供資訊傳播。這就是在處理 BigBird 的一個變體 ETC(稍後會詳細介紹)時,將 `num_random_tokens = 0` 的原因。
在這些圖形中,我們假設注意力矩陣是對稱的,**即** ,因為在圖中如果某個 token **A** 關注 **B**,那麼 **B** 也會關注 **A**。從下一節展示的注意力矩陣圖中可以看出,這個假設對於 BigBird 中的大多數 token 是成立的。
| 注意力型別 | 全域性 token |
滑動 token |
隨機 token |
|---|---|---|---|
原始完整注意力 |
n |
0 | 0 |
塊稀疏注意力 |
2 x block_size |
3 x block_size |
num_random_blocks x block_size |
original_full 代表 `BERT` 的注意力,而 `block_sparse` 代表 `BigBird` 的注意力。想知道 `block_size` 是什麼嗎?我們將在後面的章節中介紹。現在,為簡單起見,可以將其視為 1。
BigBird 塊稀疏注意力
BigBird 塊稀疏注意力只是我們上面討論內容的一種高效實現。每個 token 只關注一些**全域性 token**、**滑動 token** 和**隨機 token**,而不是關注**所有**其他 token。作者為多個查詢元件分別硬編碼了注意力矩陣,並使用了一個巧妙的技巧來加速在 GPU 和 TPU 上的訓練/推理。
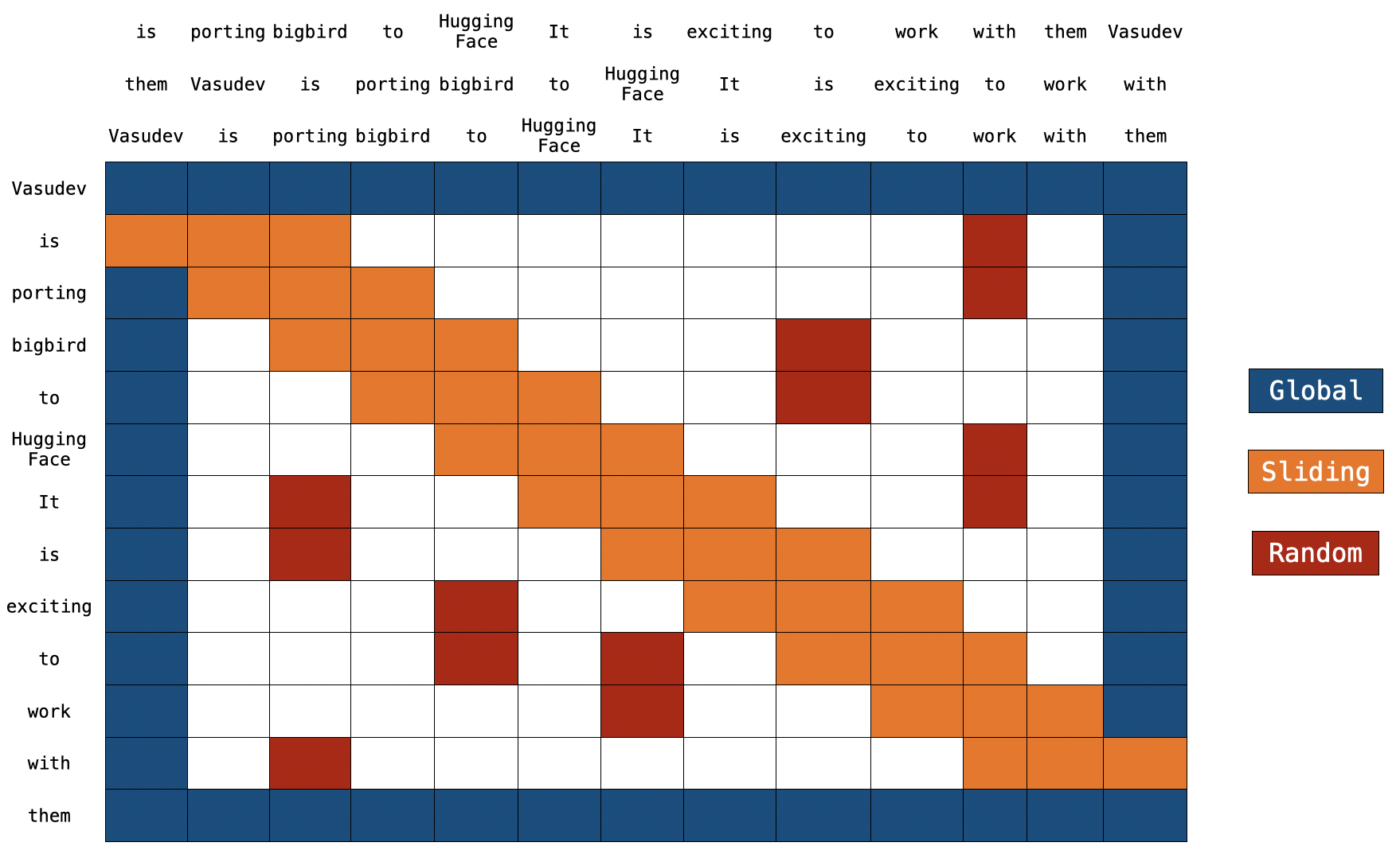 注意:在頂部,我們有兩個額外的句子。正如你所注意到的,在兩個句子中,每個 token 都只移動了一個位置。這就是滑動注意力的實現方式。當 `q[i]` 與 `k[i,0:3]` 相乘時,我們將得到 `q[i]` 的滑動注意力分數(其中 `i` 是序列中元素的索引)。
注意:在頂部,我們有兩個額外的句子。正如你所注意到的,在兩個句子中,每個 token 都只移動了一個位置。這就是滑動注意力的實現方式。當 `q[i]` 與 `k[i,0:3]` 相乘時,我們將得到 `q[i]` 的滑動注意力分數(其中 `i` 是序列中元素的索引)。
你可以在這裡找到 `block_sparse` 注意力的實際實現。現在看起來可能很嚇人😨😨。但這篇文章肯定會讓你更容易理解這段程式碼。
全域性注意力
對於全域性注意力,每個查詢都簡單地關注序列中的所有其他 token,並被所有其他 token 關注。讓我們假設 `Vasudev`(第一個 token)和 `them`(最後一個 token)是全域性的(如上圖所示)。你可以看到這些 token 直接連線到所有其他 token(藍色方框)。
# pseudo code
Q -> Query martix (seq_length, head_dim)
K -> Key matrix (seq_length, head_dim)
# 1st & last token attends all other tokens
Q[0] x [K[0], K[1], K[2], ......, K[n-1]]
Q[n-1] x [K[0], K[1], K[2], ......, K[n-1]]
# 1st & last token getting attended by all other tokens
K[0] x [Q[0], Q[1], Q[2], ......, Q[n-1]]
K[n-1] x [Q[0], Q[1], Q[2], ......, Q[n-1]]
滑動注意力
將鍵 token 序列複製 2 次,其中一個副本中的每個元素向右移動,另一個副本中的每個元素向左移動。現在,如果我們將查詢序列向量與這 3 個序列向量相乘,我們就能覆蓋所有的滑動 token。計算複雜度僅為 `O(3xn) = O(n)`。參考上圖,橙色方框代表滑動注意力。你可以在圖的頂部看到 3 個序列,其中 2 個被移動了一個 token(一個向左,一個向右)。
# what we want to do
Q[i] x [K[i-1], K[i], K[i+1]] for i = 1:-1
# efficient implementation in code (assume dot product multiplication 👇)
[Q[0], Q[1], Q[2], ......, Q[n-2], Q[n-1]] x [K[1], K[2], K[3], ......, K[n-1], K[0]]
[Q[0], Q[1], Q[2], ......, Q[n-1]] x [K[n-1], K[0], K[1], ......, K[n-2]]
[Q[0], Q[1], Q[2], ......, Q[n-1]] x [K[0], K[1], K[2], ......, K[n-1]]
# Each sequence is getting multiplied by only 3 sequences to keep `window_size = 3`.
# Some computations might be missing; this is just a rough idea.
隨機注意力
隨機注意力確保每個查詢 token 也會關注一些隨機的 token。對於實際實現來說,這意味著模型會隨機收集一些 token 並計算它們的注意力分數。
# r1, r2, r are some random indices; Note: r1, r2, r3 are different for each row 👇
Q[1] x [K[r1], K[r2], ......, K[r]]
.
.
.
Q[n-2] x [K[r1], K[r2], ......, K[r]]
# leaving 0th & (n-1)th token since they are already global
注意:當前的實現進一步將序列劃分為塊(block),每個符號都是相對於塊而不是 token 來定義的。我們將在下一節更詳細地討論這一點。
實現
回顧:在常規的 BERT 注意力機制中,一個 token 序列,即 ,透過一個全連線層投影成 ,注意力分數 的計算公式為 。在 BigBird 塊稀疏注意力中,使用的是相同的演算法,但只使用部分選定的查詢和鍵向量。
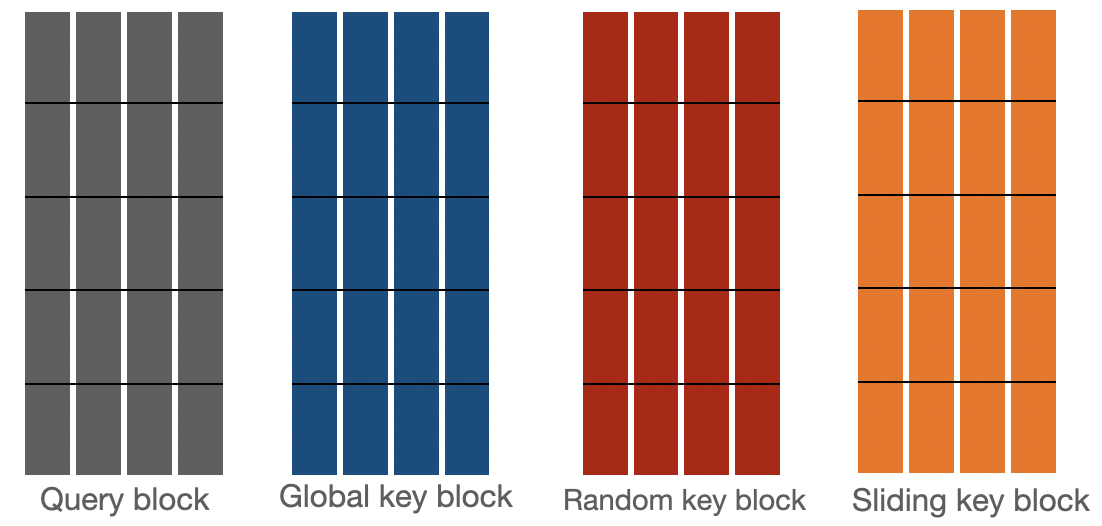
讓我們來看看 bigbird 塊稀疏注意力是如何實現的。首先,我們假設 分別代表 `block_size`(塊大小)、`num_random_blocks`(隨機塊數)、`num_sliding_blocks`(滑動塊數)、`num_global_blocks`(全域性塊數)。在視覺上,我們可以用 來說明 big bird 塊稀疏注意力的組成部分,如下所示:
的注意力分數是分別計算的,如下所述:
由 表示的 的注意力分數,其中 ,這其實就是第一個塊中的所有 token 與序列中所有其他 token 之間的注意力分數。
 代表第一個塊, 代表第 個塊。我們只是在 和 (即所有的鍵)之間執行普通的注意力操作。
代表第一個塊, 代表第 個塊。我們只是在 和 (即所有的鍵)之間執行普通的注意力操作。
為了計算第二個塊中 token 的注意力分數,我們收集前三個塊、最後一個塊和第五個塊。然後我們可以計算 。
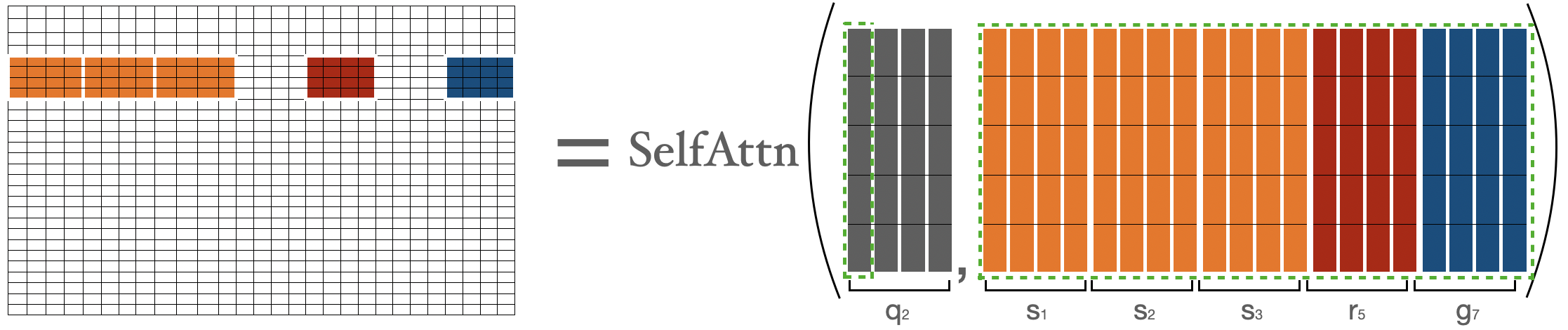
我用 來表示 token,只是為了明確地表示它們的性質(即顯示全域性、隨機、滑動 token),否則它們都只是 。
為了計算 的注意力分數,我們將收集全域性、滑動、隨機鍵,並對 和收集到的鍵執行普通的注意力操作。請注意,滑動鍵是使用前面在滑動注意力部分討論過的特殊移動技巧收集的。

為了計算倒數第二個塊中 token 的注意力分數(即 ),我們收集第一個塊、最後三個塊和第三個塊。然後我們可以應用公式 。這與我們對 所做的非常相似。
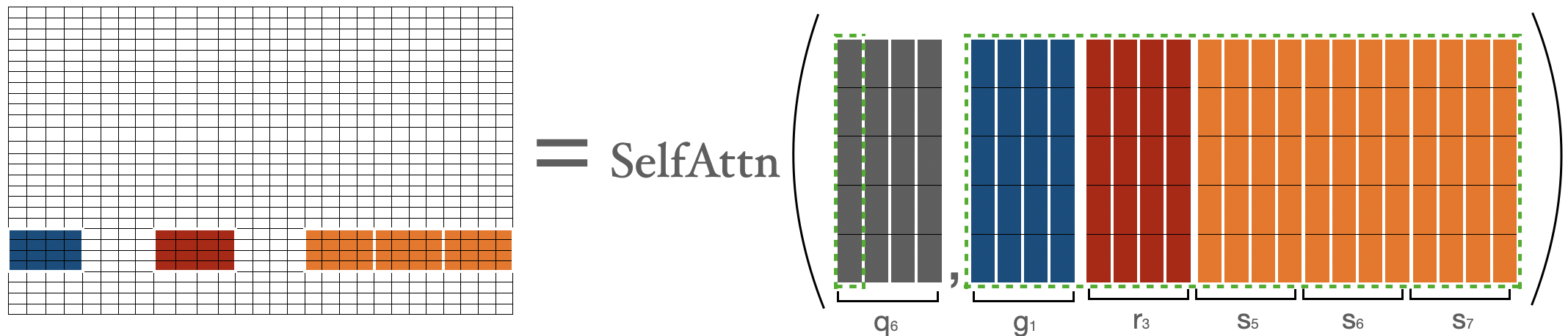
的注意力分數由 表示,其中 ,這其實就是最後一個塊中的所有 token 與序列中所有其他 token 之間的注意力分數。這與我們對 所做的非常相似。

讓我們結合上述矩陣來得到最終的注意力矩陣。這個注意力矩陣可以用來獲得所有 token 的表示。
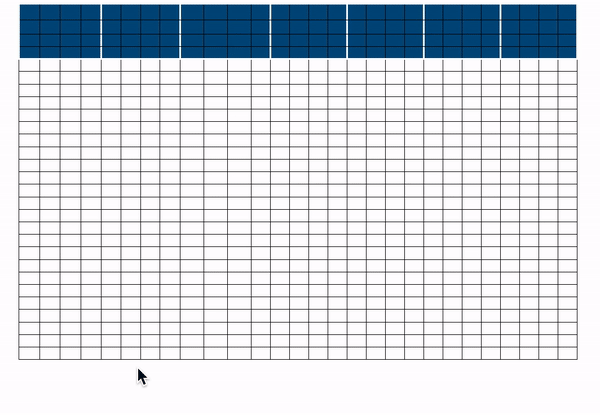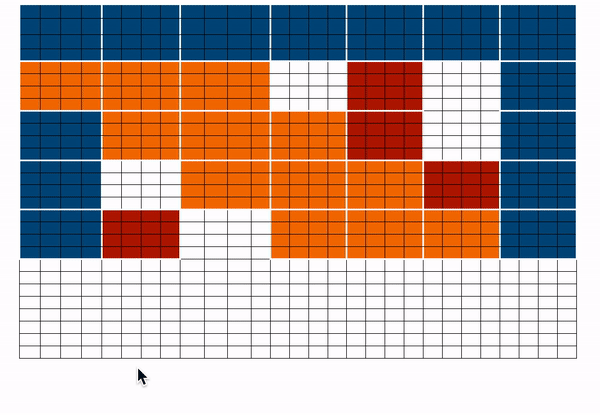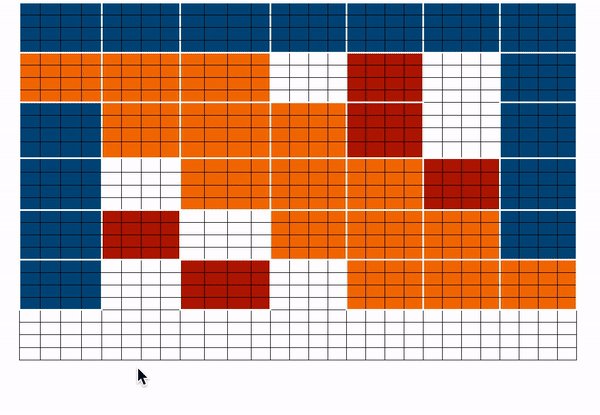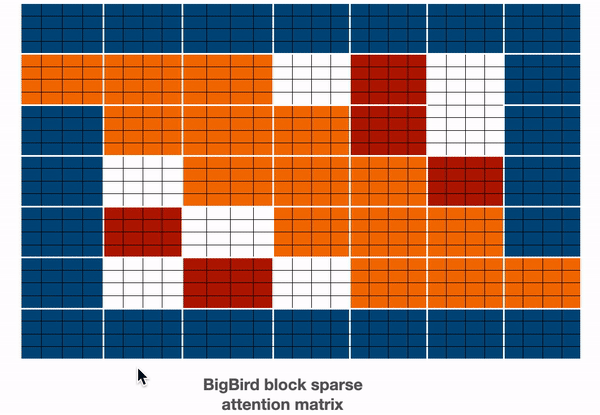
`藍色 -> 全域性塊`,`紅色 -> 隨機塊`,`橙色 -> 滑動塊`。這個注意力矩陣僅用於說明。在前向傳播過程中,我們不會儲存 `白色` 塊,而是如上所述,直接為每個分離的元件計算一個加權值矩陣(即每個 token 的表示)。
現在,我們已經介紹了塊稀疏注意力最難的部分,即其實現。希望你現在對理解實際程式碼有了更好的背景知識。歡迎深入研究程式碼,並將程式碼的每個部分與上述元件之一聯絡起來。
時間與記憶體複雜度
| 注意力型別 | 序列長度 | 時間與記憶體複雜度 |
|---|---|---|
原始完整注意力 |
512 | T |
| 1024 | 4 x `T` | |
| 4096 | 64 x `T` | |
塊稀疏注意力 |
1024 | 2 x `T` |
| 4096 | 8 x `T` |
BERT 注意力與 BigBird 塊稀疏注意力的時間與空間複雜度比較。
展開此程式碼段以檢視計算過程
BigBird time complexity = O(w x n + r x n + g x n)
BERT time complexity = O(n^2)
Assumptions:
w = 3 x 64
r = 3 x 64
g = 2 x 64
When seqlen = 512
=> **time complexity in BERT = 512^2**
When seqlen = 1024
=> time complexity in BERT = (2 x 512)^2
=> **time complexity in BERT = 4 x 512^2**
=> time complexity in BigBird = (8 x 64) x (2 x 512)
=> **time complexity in BigBird = 2 x 512^2**
When seqlen = 4096
=> time complexity in BERT = (8 x 512)^2
=> **time complexity in BERT = 64 x 512^2**
=> compute in BigBird = (8 x 64) x (8 x 512)
=> compute in BigBird = 8 x (512 x 512)
=> **time complexity in BigBird = 8 x 512^2**
ITC vs ETC
BigBird 模型可以使用兩種不同的策略進行訓練:**ITC** 和 **ETC**。ITC (internal transformer construction,內部 Transformer 構建) 就是我們上面討論的內容。在 ETC (extended transformer construction,擴充套件 Transformer 構建) 中,一些額外的 token 被設為全域性,這樣它們將關注所有 token,並被所有 token 關注。
ITC 需要較少的計算資源,因為只有很少的 token 是全域性的,同時模型仍能捕捉到足夠的全域性資訊(也藉助了隨機注意力)。另一方面,ETC 對於那些需要大量全域性 token 的任務非常有用,例如“問答”,其中整個問題應該被上下文全域性關注,以便能夠將上下文與問題正確關聯起來。
注意:Big Bird 論文中表明,在許多 ETC 實驗中,隨機塊的數量被設定為 0。根據我們在圖部分的討論,這是合理的。
下表總結了 ITC 和 ETC
| ITC | ETC | |
|---|---|---|
| 帶全域性注意力的注意力矩陣 | ||
全域性 token |
2 x block_size |
extra_tokens + 2 x block_size |
隨機 token |
num_random_blocks x block_size |
num_random_blocks x block_size |
滑動 token |
3 x block_size |
3 x block_size |
在 🤗Transformers 中使用 BigBird
你可以像使用其他 🤗 模型一樣使用 BigBirdModel。下面我們來看一些程式碼示例。
from transformers import BigBirdModel
# loading bigbird from its pretrained checkpoint
model = BigBirdModel.from_pretrained("google/bigbird-roberta-base")
# This will init the model with default configuration i.e. attention_type = "block_sparse" num_random_blocks = 3, block_size = 64.
# But You can freely change these arguments with any checkpoint. These 3 arguments will just change the number of tokens each query token is going to attend.
model = BigBirdModel.from_pretrained("google/bigbird-roberta-base", num_random_blocks=2, block_size=16)
# By setting attention_type to `original_full`, BigBird will be relying on the full attention of n^2 complexity. This way BigBird is 99.9 % similar to BERT.
model = BigBirdModel.from_pretrained("google/bigbird-roberta-base", attention_type="original_full")
在撰寫本文時,🤗Hub 中總共有 3 個檢查點可用:bigbird-roberta-base、bigbird-roberta-large、bigbird-base-trivia-itc。前兩個檢查點來自使用 masked_lm loss 預訓練 BigBirdForPretraining;而最後一個是在 trivia-qa 資料集上微調 BigBirdForQuestionAnswering 後的檢查點。
讓我們看一些你可以編寫的最簡程式碼(如果你喜歡使用自己的 PyTorch 訓練器),以使用 🤗 的 BigBird 模型來微調你的任務。
# let's consider our task to be question-answering as an example
from transformers import BigBirdForQuestionAnswering, BigBirdTokenizer
import torch
device = torch.device("cpu")
if torch.cuda.is_available():
device = torch.device("cuda")
# lets initialize bigbird model from pretrained weights with randomly initialized head on its top
model = BigBirdForQuestionAnswering.from_pretrained("google/bigbird-roberta-base", block_size=64, num_random_blocks=3)
tokenizer = BigBirdTokenizer.from_pretrained("google/bigbird-roberta-base")
model.to(device)
dataset = "torch.utils.data.DataLoader object"
optimizer = "torch.optim object"
epochs = ...
# very minimal training loop
for e in range(epochs):
for batch in dataset:
model.train()
batch = {k: batch[k].to(device) for k in batch}
# forward pass
output = model(**batch)
# back-propogation
output["loss"].backward()
optimizer.step()
optimizer.zero_grad()
# let's save final weights in a local directory
model.save_pretrained("<YOUR-WEIGHTS-DIR>")
# let's push our weights to 🤗Hub
from huggingface_hub import ModelHubMixin
ModelHubMixin.push_to_hub("<YOUR-WEIGHTS-DIR>", model_id="<YOUR-FINETUNED-ID>")
# using finetuned model for inference
question = ["How are you doing?", "How is life going?"]
context = ["<some big context having ans-1>", "<some big context having ans-2>"]
batch = tokenizer(question, context, return_tensors="pt")
batch = {k: batch[k].to(device) for k in batch}
model = BigBirdForQuestionAnswering.from_pretrained("<YOUR-FINETUNED-ID>")
model.to(device)
with torch.no_grad():
start_logits, end_logits = model(**batch).to_tuple()
# now decode start_logits, end_logits with what ever strategy you want.
# Note:
# This was very minimal code (in case you want to use raw PyTorch) just for showing how BigBird can be used very easily
# I would suggest using 🤗Trainer to have access for a lot of features
在使用 BigBird 時,務必牢記以下幾點:
- 序列長度必須是塊大小的倍數,即
seqlen % block_size = 0。你無需擔心,因為如果批次序列長度不是block_size的倍數,🤗Transformers 會自動進行<pad>(填充到大於序列長度的最小塊大小倍數)。 - 目前,HuggingFace 版本不支援 ETC,因此只有第一個和最後一個塊是全域性的。
- 當前的實現不支援
num_random_blocks = 0。 - 作者建議在序列長度小於 1024 時設定
attention_type = "original_full"。 - 必須滿足以下條件:
seq_length > global_token + random_tokens + sliding_tokens + buffer_tokens,其中global_tokens = 2 x block_size、sliding_tokens = 3 x block_size、random_tokens = num_random_blocks x block_size和buffer_tokens = num_random_blocks x block_size。如果你未能滿足此條件,🤗Transformers 會自動將attention_type切換為original_full並顯示一條警告。 - 當使用 BigBird 作為解碼器(或使用
BigBirdForCasualLM)時,attention_type應該是original_full。但你無需擔心,如果你忘記設定,🤗Transformers 會自動將attention_type切換為original_full。
下一步是什麼?
@patrickvonplaten 製作了一個非常酷的 notebook,介紹瞭如何在 trivia-qa 資料集上評估 BigBirdForQuestionAnswering。歡迎使用該 notebook 來體驗 BigBird。
你很快就會在庫中找到類似 BigBird Pegasus 的模型,用於長文件摘要任務💥。

