Hugging Face 閱讀會,2021 年 2 月——長程 Transformer




由 Teven Le Scao、Patrick Von Platen、Suraj Patil、Yacine Jernite 和 Victor Sanh 共同撰寫。
每個月,我們將選擇一個主題進行深入閱讀,閱讀該主題的四篇最新論文。然後,我們將撰寫一篇簡短的部落格文章,總結它們的發現、共同趨勢以及我們閱讀後對後續工作的疑問。2021 年 1 月的第一個主題是稀疏性和剪枝,2021 年 2 月我們探討了 Transformer 中的長程注意力。
簡介
2018 年和 2019 年大型 Transformer 模型興起後,很快出現了兩種趨勢來降低其計算要求。首先,條件計算、量化、蒸餾和剪枝為計算受限環境中的大型模型推理提供了可能性;我們已在上次閱讀小組帖子中部分提及。然後,研究社群開始著手降低預訓練的成本。
特別是,一個問題一直是工作的核心:Transformer 模型在記憶體和時間上隨序列長度呈二次方成本。為了高效訓練超大型模型,2020 年湧現了大量論文來解決這個瓶頸,並將 Transformer 擴充套件到年初 NLP 領域預設的 512 或 1024 序列長度之外。
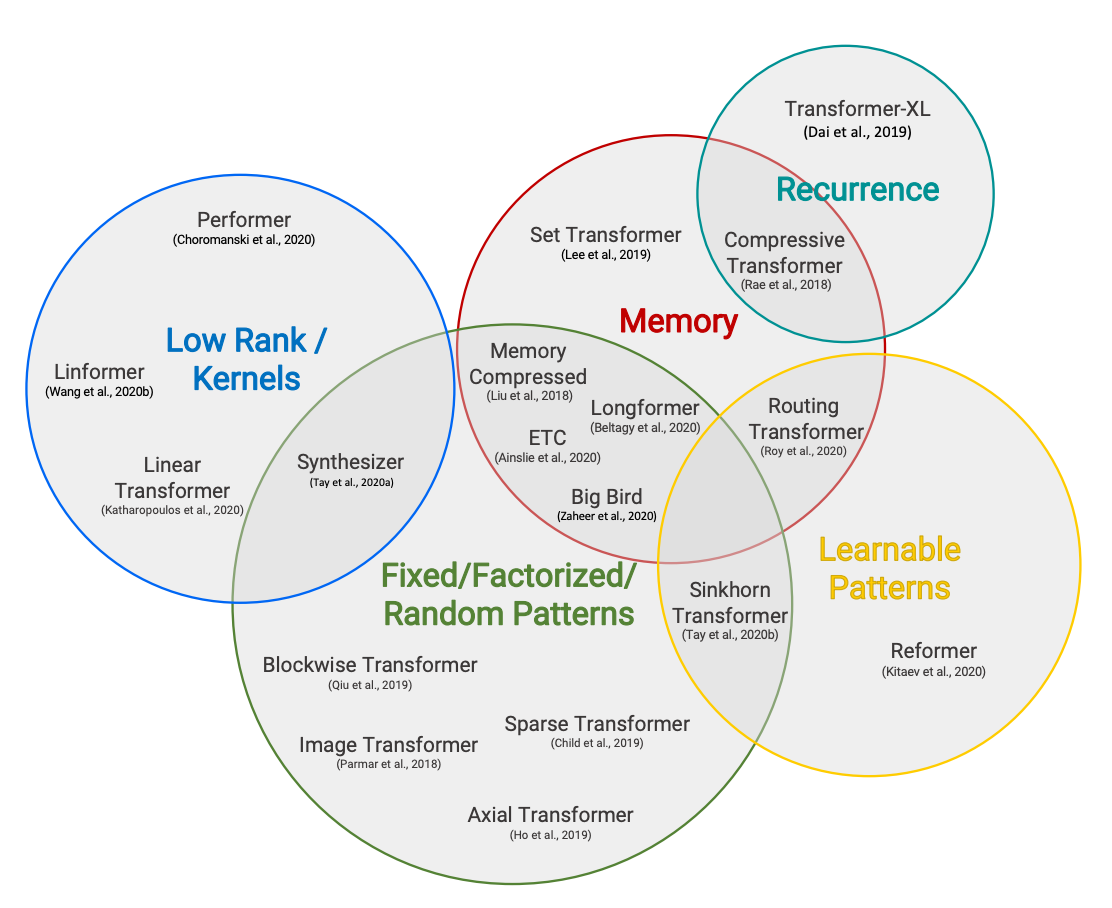
這個主題從一開始就是我們研究討論的關鍵部分,我們自己的 Patrick Von Platen 已經為 Reformer 撰寫了 4 部分系列文章。在這個閱讀小組中,我們不會試圖涵蓋所有方法(太多了!),而是將重點放在四個主要思想上:
- 自定義注意力模式(使用 Longformer)
- 迴圈(使用 Compressive Transformer)
- 低秩近似(使用 Linformer)
- 核函式近似(使用 Performer)
有關該主題的詳盡觀點,請查閱 高效 Transformer:一項調查 和 長程競技場。
摘要
Longformer - 長文件 Transformer
Iz Beltagy, Matthew E. Peters, Arman Cohan
Longformer 透過將傳統的自注意力機制替換為視窗化/區域性/稀疏(參考 稀疏 Transformer (2019))注意力與全域性注意力的組合,解決了 Transformer 的記憶體瓶頸,使其計算複雜度隨序列長度線性增長。與之前的長程 Transformer 模型(例如 Transformer-XL (2019)、Reformer (2020)、自適應注意力跨度 (2019))不同,Longformer 的自注意力層被設計為標準自注意力的直接替代品,從而可以利用預訓練的檢查點進行進一步的預訓練和/或在長序列任務上進行微調。
標準自注意力矩陣(圖 a)隨輸入長度呈二次方增長。
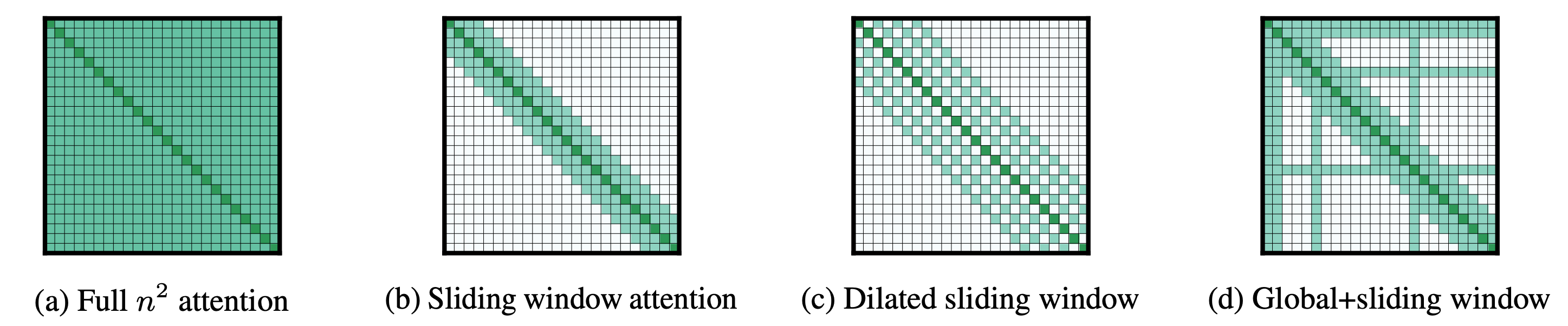
Longformer 對自迴歸語言建模、編碼器預訓練和微調以及序列到序列任務使用不同的注意力模式。
- 對於自迴歸語言建模,透過將因果自注意力(如 GPT2)替換為膨脹視窗式自注意力(圖 c)獲得最佳結果。其中 是序列長度, 是視窗長度,這種注意力模式將記憶體消耗從 減少到 ,在 的假設下,記憶體消耗隨序列長度線性增長。
- 對於編碼器預訓練,Longformer 將雙向自注意力(如 BERT)替換為區域性視窗化自注意力和全域性雙向自注意力(圖 d)的組合。這將記憶體消耗從 減少到 ,其中 是全域性關注的 token 數量,同樣隨序列長度線性增長。
- 對於序列到序列模型,只有編碼器層(如 BART)被替換為區域性和全域性雙向自注意力的組合(圖 d),因為對於大多數 seq2seq 任務,只有編碼器處理非常大的輸入(例如摘要)。因此,記憶體消耗從 減少到 ,其中 和 分別是源(編碼器輸入)和目標(解碼器輸入)長度。為了使 Longformer 編碼器-解碼器高效,假定 遠大於 。
主要發現
- 作者提出了膨脹視窗自注意力(圖 c),並表明它在語言建模方面比單純的視窗式/稀疏自注意力(圖 b)能產生更好的結果。視窗大小在各層之間逐漸增加。這種模式在下游基準測試中進一步超越了以前的架構(如 Transformer-XL 或自適應跨度注意力)。
- 全域性注意力允許資訊流經整個序列,並且將全域性注意力應用於任務相關令牌(例如 QA 中的問題令牌,句子分類的 CLS 令牌)可以帶來更強的下游任務效能。使用這種全域性模式,Longformer 可以成功應用於遷移學習設定中的文件級 NLP 任務。
- 可以透過簡單地將標準自注意力替換為本文提出的長程自注意力,然後對下游任務進行微調,將標準預訓練模型適應於長程輸入。這避免了長程輸入特定的昂貴預訓練。
後續問題
- 膨脹視窗式自注意力(貫穿各層)的尺寸增加與計算機視覺中堆疊 CNN 感受野的增加相呼應。這兩個發現之間有什麼關係?有哪些可借鑑的經驗?
- Longformer 的編碼器-解碼器架構對於不需要長目標長度的任務(如摘要)效果很好。然而,對於需要長目標長度的長程 seq2seq 任務(如文件翻譯、語音識別等),特別是考慮到編碼器-解碼器模型的交叉注意力層,它將如何工作?
- 在實踐中,滑動視窗自注意力依賴於許多索引操作以確保對稱的查詢-鍵權重矩陣。這些操作在 TPU 上非常慢,這凸顯了此類模式在其他硬體上的適用性問題。
用於長程式列建模的壓縮 Transformer
Jack W. Rae, Anna Potapenko, Siddhant M. Jayakumar, Timothy P. Lillicrap
Transformer-XL (2019) 表明,在記憶體中快取先前計算的層啟用可以提高語言建模任務的效能(例如 *enwik8*)。模型不僅可以關注當前的 個輸入 token,還可以關注過去的 個 token,其中 是模型的記憶體大小。Transformer-XL 的記憶體複雜度為 ,這表明對於非常大的 ,記憶體成本會顯著增加。因此,當快取的啟用數量大於 時,Transformer-XL 最終不得不從記憶體中丟棄過去的啟用。壓縮 Transformer 透過新增額外的壓縮記憶體來解決這個問題,以有效地快取原本會最終被丟棄的過去啟用。透過這種方式,模型可以更好地學習長程式列依賴性,因為它能夠訪問顯著更多的過去啟用。
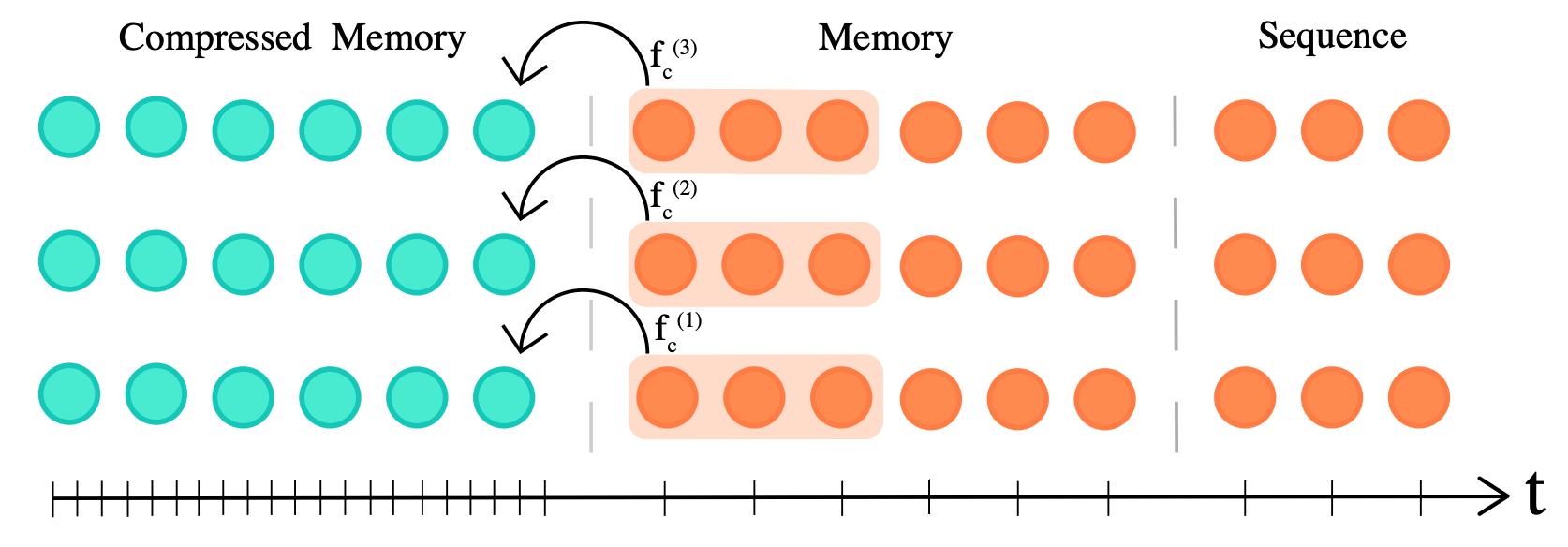
選擇一個壓縮因子 (圖中為 3)來決定過去啟用的壓縮速率。作者實驗了不同的壓縮函式 ,例如最大池化/平均池化(無引數)和一維卷積(可訓練層)。壓縮函式透過時間反向傳播或區域性輔助壓縮損失進行訓練。除了當前長度為 的輸入外,模型還關注常規記憶體中 個快取啟用,以及 個壓縮記憶體啟用,從而實現 的長時序依賴,其中 是注意力層的數量。這使 Transformer-XL 的範圍增加了額外的 個 token,記憶體成本為 。實驗在強化學習、音訊生成和自然語言處理領域進行。作者還引入了一個新的長程語言建模基準,名為 PG19。
主要發現
- 壓縮 Transformer 顯著超越了語言建模領域的最新困惑度(perplexity),尤其是在 enwik8 和 WikiText-103 資料集上。特別地,壓縮記憶體對於建模長序列中出現的稀有詞彙起著至關重要的作用。
- 作者們展示了模型透過越來越多地關注壓縮記憶體而不是常規記憶體來學習保留顯著資訊,這與舊記憶體被訪問頻率降低的趨勢相反。
- 所有壓縮函式(平均池化、最大池化、一維卷積)都產生了相似的結果,證實了記憶體壓縮是儲存過去資訊的有效方式。
後續問題
- 壓縮 Transformer 需要一種特殊的最佳化策略,其中有效批次大小逐漸增加,以避免較低學習率下顯著的效能下降。這種影響尚未被很好理解,需要更多的分析。
- 與 BERT 或 GPT2 等簡單模型相比,壓縮 Transformer 具有更多超引數:壓縮率、壓縮函式和損失、常規記憶體和壓縮記憶體大小等。目前尚不清楚這些引數是否能在不同任務(除了語言建模之外)中很好地泛化,或者像學習率一樣,使訓練變得非常脆弱。
- 探測常規記憶體和壓縮記憶體以分析透過長序列記憶了哪些資訊將是很有趣的。闡明最顯著的資訊片段可以為諸如 Funnel Transformer 等方法提供資訊,該方法旨在減少維持全長 token 級序列的冗餘。
Linformer:具有線性複雜度的自注意力
Sinong Wang, Belinda Z. Li, Madian Khabsa, Han Fang, Hao Ma
目標是將自注意力機制相對於序列長度 )的複雜度從二次方降低到線性。本文觀察到注意力矩陣是低秩的(即它們不包含 的資訊),並探索使用高維資料壓縮技術來構建更記憶體高效的 Transformer 的可能性。
所提方法的理論基礎基於 Johnson-Lindenstrauss 引理。考慮高維空間中的 個點。我們希望將它們投影到低維空間,同時以誤差 的餘量來保留資料集的結構(即點之間的相互距離)。Johnson-Lindenstrauss 引理指出,我們可以選擇一個小的維度 ,並透過簡單地嘗試隨機正交投影,在多項式時間內找到合適的投影到 Rk 中。
Linformer 透過學習注意力上下文矩陣的低秩分解,將序列長度投射到更小的維度。然後,自注意力的矩陣乘法可以巧妙地重寫,使得無需計算和儲存大小為 的矩陣。
標準 Transformer
(n * h) (n * n) (n * h)
Linformer
(n * h) (n * d) (d * n) (n * h)
主要發現
- 自注意力矩陣是低秩的,這意味著其大部分資訊可以透過其前幾個最高特徵值恢復,並且可以用低秩矩陣進行近似。
- 許多工作都專注於降低隱藏狀態的維度。本文表明,透過學習投影來減小序列長度是一種強有力的替代方案,同時將自注意力的記憶體複雜度從二次方縮小到線性。
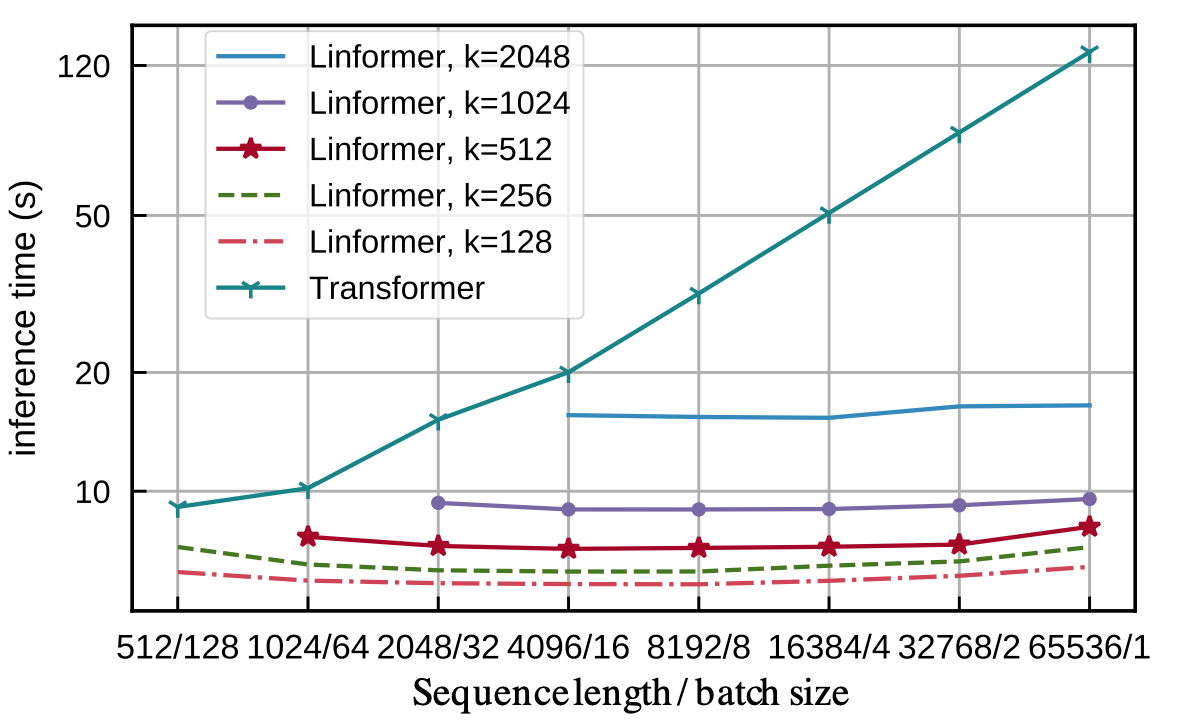
- 增加序列長度不影響 Linformer 的推理速度(時鐘時間),而 Transformer 則呈線性增長。此外,Linformer 的自注意力不影響收斂速度(更新次數)。
後續問題
- 儘管投影矩陣在各層之間共享,但此處提出的方法與 Johnson-Lindenstrauss 定理相悖,後者指出隨機正交投影就足夠了(在多項式時間內)。隨機投影在這裡會起作用嗎?這讓人想起 Reformer,它在區域性敏感雜湊中使用隨機投影來降低自注意力的記憶體複雜度。
使用 Performer 重新思考注意力機制
Krzysztof Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Davis, Afroz Mohiuddin, Lukasz Kaiser, David Belanger, Lucy Colwell, Adrian Weller
目標(再次!)是將自注意力機制相對於序列長度 )的複雜度從二次方降低到線性。與其他論文不同,作者指出自注意力的稀疏性和低秩先驗可能不適用於其他模態(語音、蛋白質序列建模)。因此,本文探討了在不預設注意力矩陣任何先驗的情況下,減輕自注意力記憶體負擔的方法。
作者觀察到,如果能透過 softmax 執行矩陣乘法 (),我們就無需計算大小為 的 矩陣,這是記憶體瓶頸。他們使用隨機特徵對映(又稱隨機投影)來近似 softmax,如下所示:
,其中 是一個非線性函式。然後
受 2000 年代早期機器學習論文的啟發,作者引入了 **FAVOR+**(**F**ast **A**ttention **V**ia **O**rthogonal **R**andom positive (**+**) **F**eatures),該程式旨在找到自注意力矩陣的無偏或近乎無偏估計,具有均勻收斂性和低估計方差。
主要發現
- FAVOR+ 過程可以高精度地近似自注意力矩陣,而無需預設注意力矩陣的形式,使其可以作為標準自注意力的直接替代品,並在多個應用和模態中帶來強大的效能。
- 對 softmax 如何近似以及不該如何近似的深入數學研究,凸顯了即使在深度學習時代,2000 年代早期開發的原則性方法仍然具有重要意義。
- FAVOR+ 也可應用於除了 softmax 之外的其他可核化注意力機制的有效建模。
後續問題
- 即使注意力機制的近似是緊密的,小誤差也會透過 Transformer 層傳播。這就提出了使用 FAVOR+ 作為自注意力近似的預訓練網路微調的收斂性和穩定性問題。
- FAVOR+ 演算法是多個元件的組合。目前尚不清楚這些元件中哪個對效能影響最大,尤其是在考慮到這項工作中涉及的各種模態的情況下。
閱讀小組討論
基於 Transformer 的預訓練語言模型在自然語言理解和生成方面的進展令人印象深刻。使這些系統高效用於生產目的已成為一個非常活躍的研究領域。這強調了我們仍有許多東西需要學習和構建,無論是在方法論還是實踐方面,以實現高效和通用的基於深度學習的系統,特別是對於需要建模長程輸入的應用程式。
上述四篇論文提供了不同的方法來處理自注意力機制的二次記憶體複雜度,通常透過將其降低到線性複雜度。Linformer 和 Longformer 都依賴於自注意力矩陣不包含 資訊量(注意力矩陣是低秩和稀疏的)的觀察結果。Performer 提供了一種原則性方法來近似 softmax-attention 核(以及任何可核化的注意力機制,超越 softmax)。壓縮 Transformer 提供了一種基於遞迴來建模長程依賴關係的正交方法。
這些不同的歸納偏置在計算速度和訓練設定之外的泛化能力方面都有影響。特別是,Linformer 和 Longformer 帶來了不同的權衡:Longformer 明確設計了自注意力的稀疏注意力模式(固定模式),而 Linformer 學習了自注意力矩陣的低秩分解。在我們的實驗中,Longformer 的效率低於 Linformer,並且目前高度依賴於實現細節。另一方面,Linformer 的分解僅適用於固定上下文長度(訓練時固定),並且在沒有特定適應的情況下無法泛化到更長的序列。此外,它無法快取先前的啟用,這在生成設定中可能非常有用。有趣的是,Performer 在概念上是不同的:它學習近似 softmax 注意力核,而不依賴於任何稀疏性或低秩假設。這些歸納偏置在不同訓練資料量下如何相互比較的問題仍然存在。
所有這些工作都強調了自然語言中長程輸入建模的重要性。在工業界,經常會遇到諸如文件翻譯、文件分類或文件摘要等用例,這些用例需要以高效且穩健的方式建模非常長的序列。最近,零樣本示例預熱(類似 GPT3)也成為標準微調的一種有前景的替代方案,並且增加預熱示例的數量(從而增加上下文大小)穩步提高了效能和魯棒性。最後,在語音或蛋白質建模等其他模態中,通常會遇到超過標準 512 個時間步長的長序列。
對長輸入進行建模並非與對短輸入進行建模相互對立,而應將其視為從短序列到長序列的一個連續過程。Shortformer、Longformer 和 BERT 都提供了證據,表明在短序列上訓練模型並逐漸增加序列長度可以加速訓練並提高下游效能。這一觀察與以下直覺相符:在資料量很少時獲得的長程依賴關係可能依賴於虛假相關性,而不是可靠的語言理解。這與 Teven Le Scao 在語言建模方面進行的一些實驗相呼應:與 Transformer 相比,LSTM 在低資料狀態下是更強的學習器,並且在諸如 Penn Treebank 等小規模語言建模基準上提供了更好的困惑度。
從實踐角度來看,位置編碼問題也是一個關鍵的方法論方面,涉及計算效率的權衡。相對位置編碼(在 Transformer-XL 中引入並在壓縮 Transformer 中使用)具有吸引力,因為它們可以很容易地擴充套件到尚未見過的序列長度,但同時,相對位置編碼計算成本高昂。另一方面,絕對位置編碼(在 Longformer 和 Linformer 中使用)對於比訓練期間見過的序列更長的序列靈活性較低,但計算效率更高。有趣的是,Shortformer 引入了一種簡單的替代方案,透過將位置資訊新增到自注意力機制的查詢和鍵中,而不是將其新增到 token 嵌入中。該方法被稱為位置注入注意力(position-infused attention),被證明非常高效,同時產生強大的結果。
@Hugging Face 🤗:長程建模
Longformer 的實現及相關開源檢查點可透過 Transformers 庫和 模型中心 獲取。Performer 和 Big Bird(一種基於稀疏注意力的長程模型)目前正在開發中,作為我們模型徵集的一部分,這是一項旨在促進開源貢獻的社群工作。如果您想知道如何為 `transformers` 做貢獻但不知道從何開始,我們非常期待您的來信!
如需進一步閱讀,我們建議檢視 Patrick Platen 關於 Reformer 的部落格、Teven Le Scao 關於 Johnson-Lindenstrauss 近似 的帖子、《高效 Transformer:一項調查》以及《長程競技場:高效 Transformer 的基準》。
下個月,我們將介紹自訓練方法和應用。三月再見!

