十億級分類







您已經優化了模型。您的流水線執行順暢。但現在,您的雲賬單卻飛漲。每天執行10億次以上的分類或嵌入任務不僅是技術挑戰,也是財務挑戰。如何在不超出預算的情況下進行如此規模的處理?無論您是執行大規模文件分類還是用於檢索增強生成(RAG)的批次嵌入流水線,您都需要高成本效益、高吞吐量的推理才能使其可行,而這需要透過最佳化配置來實現。
這些任務通常使用編碼器模型,它們比現代LLM小得多,但在10億次以上推理請求的規模下,這仍然是一個相當不平凡的任務。需要明確的是,這相當於英文維基百科的144倍。我沒有看到太多關於如何以成本為導向處理此問題的資訊,我想解決這個問題。本部落格將詳細介紹如何計算大規模分類和嵌入的成本和延遲。我們將分析不同的模型架構,對不同硬體選擇的成本進行基準測試,併為您提供一個清晰的最佳化框架。此外,如果您不想親自經歷這個過程,我們還應該能夠建立一些直覺。
您可能有幾個問題
- 對於10億個輸入,解決我任務最便宜的配置是什麼?(批次推理)
- 在考慮延遲的同時,我該怎麼做?(高負載使用)
這是實現它的程式碼:https://github.com/datavistics/encoder-analysis
tl;我不會重現這個,告訴我你發現了什麼;dr
透過這個定價,我能夠獲得以下成本
| 用例 | 分類 | 嵌入 | 視覺嵌入 |
|---|---|---|---|
| 模型 | lxyuan/distilbert-base-multilingual-cased-sentiments-student | Alibaba-NLP/gte-modernbert-base | vidore/colqwen2-v1.0-merged |
| 資料 | tyqiangz/multilingual-sentiments | sentence-transformers/trivia-qa-triplet | openbmb/RLAIF-V-Dataset |
| 硬體型別 | nvidia-L4 ($0.8/小時) |
nvidia-L4 ($0.8/小時) |
nvidia-L4 ($0.8/小時) |
| 10億輸入的成本 | $253.82 | $409.44 | $44,496.51 |
方法
為了評估成本和延遲,我們需要4個關鍵元件
- 硬體選項:各種硬體以比較成本
- 部署協調器:一種以我們選擇的設定部署模型的方式
- 負載測試:一種傳送請求並衡量效能的方式
- 推理伺服器:一種在所選硬體上高效執行模型的方式
我將利用推理端點作為我的硬體選項,因為它允許我從廣泛的硬體選擇中進行選擇。請注意,您可以將其替換為您選擇/考慮的GPU。對於部署協調器,我將使用非常實用的Hugging Face Hub庫,它允許我輕鬆地以程式設計方式部署模型。
對於推理伺服器,我還將使用Infinity,這是一個用於服務基於編碼器模型(現在更多了!)的絕佳庫。我已經寫過關於TEI的內容,這是另一個很棒的庫。在處理您的用例時,您應該絕對考慮TEI,儘管本部落格側重於方法論而非框架比較。Infinity具有許多關鍵優勢,例如服務多模態嵌入、針對不同硬體(AMD、Nvidia、CPU和Inferentia)以及執行任何包含尚未整合到huggingface transformer庫中的遠端程式碼的新模型。對我來說,其中最重要的是大多數模型預設相容。
對於負載測試,我將使用Grafana的k6,這是一個用Go語言編寫的開源負載測試工具,帶有JavaScript介面。它易於配置,效能高,開銷低。它有很多內建的執行器,非常有用。它還預先分配虛擬使用者(VUs),這比自己隨意進行測試更真實。
我將介紹3個用例,它們應該涵蓋各種有趣的方面
| 用例 | 模型 | 基礎架構 | 引數計數 | 關注點 |
|---|---|---|---|---|
| 分類(文字) | lxyuan/distilbert-base-multilingual-cased-sentiments-student | DistilBertForSequenceClassification | 1.35億 | 精簡的架構小巧快速,對某些用例來說很理想。 |
| 嵌入 | Alibaba-NLP/gte-modernbert-base | ModernBertModel | 1.49億 | 使用ModernBERT,速度非常快。也可擴充套件用於長上下文。 |
| 視覺嵌入 | vidore/colqwen2-v1.0-merged | ColQwen2 | 22.1億 | ColQwen2可以在ColBERT風格的VLM檢索中提供獨特的見解。 |
最佳化
最佳化是一個棘手的問題,有很多方面需要考慮。從宏觀層面看,我希望遍歷重要的負載測試引數,並找到最適合單個GPU的引數,因為大多數編碼器模型都能在一個GPU中執行。一旦我們有了單個GPU的基線成本,就可以透過增加副本GPU的數量來橫向擴充套件GPU數量和吞吐量。
設定
對於每個用例,我將使用以下高階流程
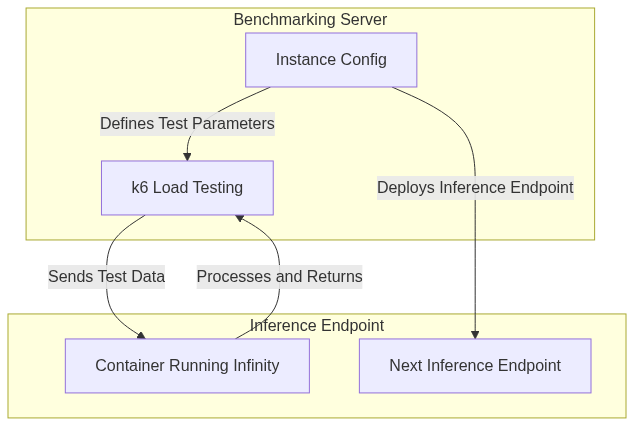
既然您有了程式碼,請隨意根據您的需要調整任何部分
- GPU
- 部署流程
- 實驗框架
- 等等
我不會介意的。
負載測試引數
VUs 和 Batch Size 很重要,因為它們會影響我們如何充分利用 GPU 中所有可用的計算資源。足夠大的 Batch Size 可以確保我們充分利用 Streaming Multiprocessors 和 VRAM。有些情況下我們會剩下 VRAM,但存在頻寬成本,這會阻止吞吐量增加。因此,實驗可以幫助我們。VUs 允許我們確保我們充分利用可用的 Batch Size。
這些是我將要測試的主要引數
INFINITY_BATCH_SIZE- 這是在模型中進行批處理前向傳遞的文件數量
- 太低將無法充分利用 GPU
- 太高將導致 GPU 無法處理大輸入
VUs- 這是模擬傳送到 K6 的並行客戶端請求的虛擬使用者數量
- 模擬大量使用者可能很困難,並且每臺機器都會有所不同。
- GPU
- 推理端點提供多種GPU選擇
- 我優先選擇了效能/成本比最佳的那些
- CPU
- 我省略了這些,因為Nvidia-T4非常便宜,在輕度測試後,CPU顯得沒有吸引力。不過,如果使用者有興趣,我留下了一些程式碼來測試它!
根據您的模型,您可能需要考慮
- 您正在使用的Docker映象。[
'michaelf34/infinity:0.0.75-trt-onnx','michaelf34/infinity:0.0.75']- 有許多Infinity映象可以支援不同的後端。您應該考慮哪些最適用於您的硬體/模型/配置。
INFINITY_COMPILE是否要使用torch.compile()文件INFINITY_BETTERTRANSFORMER是否要讓torch使用Better Transformer
K6
K6 很棒,因為它允許您預分配虛擬使用者 (VUs) 並防止一些潛在的錯誤。它在傳送請求方面非常靈活。我決定以一種特定的方式使用它。
當我呼叫 K6 實驗時,我主要想知道請求的吞吐量和平均延遲,並對所選的負載測試引數進行一些健全性檢查。我還想進行一次全面掃描,這意味著需要進行許多實驗。
我使用了 `shared-iterations` 執行器 (文件),這意味著 K6 會在虛擬使用者之間共享迭代次數。一旦 K6 執行完所有迭代,測試就結束了。這使得我能夠設定合理的超時時間,同時也能發出足夠的請求,以確保在全面掃描中能夠有效地辨別負載測試引數選擇。與其它執行器相比,這讓我確信我正在模擬客戶端在每個虛擬使用者上儘可能努力地工作,這應該能顯示出最經濟的選擇。
我使用 `10_000` 個請求†,最大實驗時間為 `1 分鐘`。所以如果 10_000 個請求在 1 分鐘內沒有完成,那麼該實驗就結束了。
export const options = {
scenarios: {
shared_load_test: {
executor: 'shared-iterations',
vus: {{ pre_allocated_vus }},
iterations: 10000,
maxDuration: '1m',
},
},
};
統計
- P95††和平均延遲
- 吞吐量
完整性檢查
- 準確性(僅限分類)
- 測試持續時間
- 成功請求
- 格式驗證
† 鑑於視覺嵌入的吞吐量低且影像較大,我為它們設定了較少的最大請求數。
†† P95意味著95%的請求在此時間內完成。它代表了大多數使用者的最壞情況延遲。
編排
您可以在此處找到將最佳化工作流整合在一起的3個筆記本
主要目的是定義我的實驗,使用正確的引數啟動正確的推理端點,並使用正確的引數啟動k6來測試端點。
我做了一些設計選擇,您可能需要仔細考慮它們是否適合您
- 我以指數方式增加虛擬使用者(VU),然後進行二分查詢以找到最佳值。
- 我不認為結果是完全可重複的。
- 如果您多次執行相同的測試,您將得到略微不同的結果
- 我使用2%的改進閾值來決定是否繼續搜尋
分類
介紹
文字分類在大規模應用中具有多種用例,例如垃圾郵件過濾、預訓練資料集中的毒性檢測等。最初的經典架構是BERT,很快又出現了許多其他架構。請注意,與流行的解碼器模型不同,這些模型在使用前需要根據您的任務進行微調。我認為目前以下架構†最值得關注
- DistilBERT
- 良好的任務效能,出色的工程效能
- 它對原始Bert進行了一些架構更改,不相容TEI的分類
- DeBERTa-v3
- 出色的任務效能
- 工程效能非常慢††,因為其獨特的注意力機制難以最佳化
- ModernBERT
- 使用序列打包和Flash-Attention-2
- 出色的任務效能和出色的工程效能††
† 請注意,對於這些模型,您通常需要根據自己的資料進行微調才能獲得良好效能。
†† 我使用“工程效能”來表示預期的延遲/吞吐量
實驗
| 類別 | 數值 |
|---|---|
| 模型 | lxyuan/distilbert-base-multilingual-cased-sentiments-student |
| 模型架構 | DistilBERT |
| 資料 | tyqiangz/multilingual-sentiments(`text` 列)平均 100 個 token(最少 50 個),多種語言 |
| 硬體 | nvidia-L4 ($0.8/小時) nvidia-t4 ($0.5/小時) |
| 無限影像 | trt-onnx vs 預設 |
批處理大小 |
[16, 32, 64, 128, 256, 512, 1024] |
虛擬使用者數 |
32+ |
我選擇DistilBERT作為重點,因為它對於許多應用來說是一個出色的輕量級選擇。我比較了兩種GPU,`nvidia-t4`和`nvidia-l4`,以及兩種Infinity Docker映象。
結果
您可以在此處以互動式格式檢視結果,或者在下方“分析”部分嵌入的空間中檢視。這是我執行的實驗中最便宜的配置
| 類別 | 最佳價值 |
|---|---|
| 10億輸入的成本 | $253.82 |
| 硬體型別 | nvidia-L4 ($0.8/小時) |
| 無限影像 | 預設 |
批處理大小 |
64 |
虛擬使用者數 |
448 |
嵌入
介紹
文字嵌入是一種籠統的說法,用於描述將文字輸入投射到語義空間中的任務,在該空間中,相近的點在意義上相似,而遙遠的點則不相似(示例如下)。這在RAG中大量使用,是AI搜尋的重要組成部分(有些人是其擁護者)。
有大量相容的架構,您可以在MTEB排行榜中檢視效能最佳的架構。
實驗
ModernBERT 是自 2020 年 DeBERTa 以來最令人興奮的編碼器釋出。它將所有咳咳現代技巧內建到一個古老而熟悉的架構中。它是一個吸引人的實驗模型,因為它比其他架構探索得少得多,並且具有更大的潛力。在速度和效能方面有一些改進,但對使用者來說最值得注意的是 8k 上下文視窗。請檢視這篇部落格以獲得更全面的理解。
需要注意的是,Flash Attention 2 由於計算能力要求,只能與更現代的 GPU 配合使用,因此我選擇跳過 T4 而轉而使用 L4。對於重度使用者,H100 也會在這裡表現出色。
| 類別 | 數值 |
|---|---|
| 模型 | Alibaba-NLP/gte-modernbert-base |
| 模型架構 | ModernBERT |
| 資料 | sentence-transformers/trivia-qa-triplet(`positive` 列)平均 144 個 token,標準差 14。 |
| 硬體 | nvidia-L4 ($0.8/小時) |
| 無限影像 | 預設 |
批處理大小 |
[16, 32, 64, 128, 256, 512, 1024] |
虛擬使用者數 |
32+ |
結果
您可以在此處以互動式格式檢視結果。這是我執行的實驗中最便宜的配置
| 類別 | 最佳價值 |
|---|---|
| 10億輸入的成本 | $409.44 |
| 硬體型別 | nvidia-L4 ($0.8/小時) |
| 無限影像 | 預設 |
批處理大小 |
32 |
虛擬使用者數 |
256 |
視覺嵌入
介紹
ColQwen2 是一個視覺檢索器,它基於 Qwen2-VL-2B-Instruct,並使用 ColBERT 風格的文字和影像多向量表示。我們可以看到,與我們上面探索的編碼器相比,它具有更復雜的架構。

在大規模應用中,有許多用例可能會從中受益,例如電子商務搜尋、多模態推薦、企業多模態 RAG 等
ColBERT 風格與我們之前的嵌入用例不同,因為它將輸入分解成多個 token,併為每個 token 返回一個向量,而不是為整個輸入返回一個向量。您可以在 Jina AI 的此處找到一篇非常棒的教程。這可以帶來卓越的語義編碼和更好的檢索,但速度也更慢,成本也更高。
我對這個實驗感到興奮,因為它探索了兩個鮮為人知的概念:視覺嵌入和 ColBERT 風格嵌入†。關於 ColQwen2/VLM,有幾點需要注意
- 2B 比我們在這篇部落格中討論的其他模型大約 15 倍
- ColQwen2 擁有一個複雜的架構,包含多個模型,其中包括一個比編碼器慢的解碼器。
- 影像很容易消耗大量 token。
- API 成本
- 透過 API 傳送影像比傳送文字慢。
- 如果您在雲端,您將面臨更高的出口費用。
† 如果您對此新穎有趣的領域感興趣,請務必檢視這篇更詳細的部落格。
實驗
我想嘗試像`nvidia-l4`這樣小型現代的GPU,因為它應該能夠適應20億引數模型,並且由於價格便宜,也能很好地擴充套件。和其他嵌入模型一樣,我將改變`batch_size`和`vus`。
| 類別 | 數值 |
|---|---|
| 模型 | vidore/colqwen2-v1.0-merged |
| 模型架構 | ColQwen2 |
| 資料 | openbmb/RLAIF-V-Dataset(`image` 列)大多數影像為 ~600x400,大小為 4MB |
| 硬體 | nvidia-L4 ($0.8/小時) |
| 無限影像 | 預設 |
批處理大小 |
[1, 2, 4, 8, 16] |
虛擬使用者數 |
1+ |
結果
您可以在此處以互動式格式檢視結果。這是我執行的實驗中最便宜的配置
| 類別 | 最佳價值 |
|---|---|
| 10億輸入的成本 | $44,496.51 |
| 硬體型別 | nvidia-l4 |
| 無限影像 | 預設 |
批處理大小 |
4 |
虛擬使用者數 |
4 |
分析
請檢視此空間(derek-thomas/classification-analysis)中關於分類用例的詳細分析(隱藏側邊欄並向下滾動檢視圖表)
結論
每天將分類或嵌入擴充套件到十億以上是一個不小的挑戰,但透過適當的最佳化,可以實現成本效益。從我的實驗中,出現了一些關鍵模式
- 硬體至關重要——NVIDIA L4(0.80美元/小時)在效能和成本之間始終提供了最佳平衡,使其成為現代工作負載T4的首選。CPU在大規模應用中不具有競爭力。
- 批處理大小至關重要——批處理大小的最佳點因任務而異,但總的來說,在不觸及GPU記憶體和頻寬限制的情況下,最大化批處理大小是實現效率的關鍵。對於分類,批處理大小64是最佳選擇;對於嵌入,則是32。
- 並行性是關鍵——找到合適的虛擬使用者(VU)數量可確保GPU得到充分利用。指數增加+二分查詢方法有助於高效地收斂到最佳VU設定。
- ColBERT 風格的視覺嵌入成本高昂——每十億次嵌入超過 44,000 美元,基於影像的檢索比基於文字的任務成本高出兩個數量級。
您的資料、硬體、模型等可能有所不同,但我希望您能從提供的方法和程式碼中找到一些用處。獲得估計的最佳方法是使用您自己的配置在您自己的任務上執行此程式碼。讓我們開始探索吧!
特別感謝 andrewrreed/auto-bench 提供的一些靈感,以及 Michael Feil 建立 Infinity。還要感謝 Pedro Cuenca、Erik Kaunismaki 和 Tom Aarsen 幫助我審查。
參考文獻
- https://towardsdatascience.com/exploring-the-power-of-embeddings-in-machine-learning-18a601238d6b
- https://yellow-apartment-148.notion.site/AI-Search-The-Bitter-er-Lesson-44c11acd27294f4495c3de778cd09c8d
- https://jina.ai/news/what-is-colbert-and-late-interaction-and-why-they-matter-in-search/
附錄
完整性檢查
隨著複雜度的增加,擴充套件完整性檢查變得很重要。由於我們使用 `subprocess` 和 `jinja` 來呼叫 `k6`,我感覺離實際測試很遠,所以我進行了一些檢查。
任務表現
任務效能的目標是確保在特定配置下,我們的表現與預期相似。任務效能在不同任務中會有不同的含義。對於分類,我選擇了準確性,而對於嵌入,我跳過了。我們可以檢視平均相似度和其他類似指標。對於 ColBERT 樣式,由於我們每個請求會得到許多向量,因此會變得更加複雜。
即使對於某些3類分類任務來說,58%的準確率不算差,但這並不重要。目標是確保我們獲得預期的任務效能。如果我們發現顯著變化(增加或減少),我們應該懷疑並嘗試理解原因。
下面是一個來自分類用例的很好的例子,我們可以看到一個極其緊密的分佈和一個異常值。經過進一步調查,這個異常值是由於傳送的請求數量較少。
您可以在此處透過nbviewer檢視互動式結果
失敗請求檢查
我們應該期望沒有失敗的請求,因為推理端點有一個佇列來處理額外的請求。這適用於所有三種用例:分類、嵌入和視覺嵌入。
sum(df.total_requests - df.successful_requests) 可以讓我們檢視是否有任何失敗的請求。
單調序列——我們是否嘗試了足夠多的虛擬使用者?
如上所述,我們正在使用一個很好的策略,即採用指數增長,然後進行二分查詢來找到最佳的虛擬使用者(VUs)數量。但是我們怎麼知道我們是否嘗試了足夠的VUs呢?如果我們嘗試了更高數量的VUs,並且吞吐量持續增加,那該怎麼辦?如果是這種情況,我們就會看到VUs和吞吐量之間存在單調遞增的關係,那麼我們就需要執行更多的測試。
您可以在此處透過nbviewer檢視互動式結果
嵌入大小檢查
當我們請求嵌入時,返回的嵌入大小與模型型別指定的大小相同是有道理的。您可以在此處檢視檢查
ColBERT 嵌入計數
我們正在使用 ColBERT 風格的模型進行視覺嵌入,這意味著每張影像我們應該獲得多個向量。檢視這些向量的分佈很有趣,因為它允許我們檢查是否有任何意外情況並瞭解我們的資料。為此,我在實驗中儲存了 `min_num_vectors`、`avg_num_vectors` 和 `max_num_vectors`。
我們應該會看到所有3個值都有一些變化,但`min_num_vectors`和`max_num_vectors`在不同實驗中具有相同的值是可以接受的。
你可以在這裡檢視檢查結果
成本分析
這裡有一個簡短的描述,但您可以在空間中獲得更詳細的互動式體驗:derek-thomas/classification-analysis
成本節省最佳影像
對於分類用例,我們查看了兩種不同的Infinity Images,`default`和`trt-onnx`。哪種更好?最好在相同的設定(GPU,batch_size,VUs)下進行比較。我們可以簡單地按這些設定對結果進行分組,然後檢視哪種更便宜。

成本與延遲
這是一個關鍵圖表,因為對於許多用例而言,使用者能夠承受的最大延遲是有限的。通常,如果我們允許延遲增加,我們可以提高吞吐量,從而形成權衡場景。這在我所研究的所有用例中都是如此。擁有帕累託曲線對於幫助視覺化這種權衡在哪裡非常有用。
成本與 VUs 和批處理大小等高線圖
最後,重要的是要對嘗試這些不同設定時發生的情況建立直覺。我們會得到漂亮的理想化圖表嗎?我們會看到意想不到的梯度嗎?我們需要在某個區域進行更多探索嗎?我們的設定是否存在問題,例如沒有隔離環境?所有這些都是很好的問題,有些可能很難回答。
等高線圖是透過在由3個維度定義的空間中插入中間點來構建的。有幾種值得理解的現象
- 顏色梯度:顯示成本水平,顏色越深表示成本越高,顏色越淺表示成本越低。
- 等高線:表示成本水平,有助於識別成本效益高的區域。
- 緊密聚類:(等高線)表示成本隨批次大小或虛擬使用者(VUs)的微小調整而迅速變化。
我們可以看到一個複雜的等高線圖,其中包含來自分類用例的一些有趣結果

但這是視覺嵌入任務的一個更清晰的圖表。

Infinity客戶端
實際使用時,請考慮使用infinity客戶端。在進行基準測試時,使用k6瞭解可能性是個好習慣。對於實際使用,請使用官方庫或類似的東西,以獲得以下幾點好處
- Base64意味著更小的負載(更快更便宜)
- 維護良好的庫應使開發更簡潔、更容易。
- 您具有固有的相容性,這將加快開發速度。
您還可以選擇與Infinity後端相容的OpenAI庫。
例如,視覺嵌入可以這樣訪問
pip install infinity_client && python -c "from infinity_client.vision_client import InfinityVisionAPI"
其他經驗教訓
- 我嘗試在同一GPU上部署多個模型,但沒有看到明顯的改進,儘管還有剩餘的VRAM和GPU處理能力,這可能是由於處理大批次資料的頻寬成本造成的。
- 在使用SharedArrays之前,讓 K6 處理影像是一件令人頭疼的事情。
- 影像資料處理起來可能非常麻煩
- 除錯 K6 時,生成指令碼的關鍵是手動執行 K6 並檢視輸出。
未來改進
- 讓測試並行執行,同時管理全域性最大`VUs`,將節省大量時間
- 研究更多樣化的資料集,看看它們如何影響數字。









