使用 Intel Gaudi 2 和 Intel Xeon 構建高成本效益的企業級 RAG 應用程式














檢索增強生成 (RAG) 透過結合儲存在外部資料儲存中的新鮮領域知識,增強了大型語言模型的文字生成能力。將公司資料與語言模型在訓練過程中學習到的知識分開對於平衡效能、準確性和安全隱私目標至關重要。
在本部落格中,您將學習英特爾如何幫助您作為 OPEA(企業 AI 開放平臺)的一部分開發和部署 RAG 應用程式。您還將瞭解英特爾 Gaudi 2 AI 加速器和 Xeon CPU 如何透過一個真實的 RAG 用例顯著提升企業效能。
開始
在深入細節之前,讓我們先了解一下硬體。Intel Gaudi 2 專為加速資料中心和雲端的深度學習訓練和推理而設計。它可在 Intel Developer Cloud (IDC) 上公開獲取,也可用於本地部署。IDC 是開始使用 Gaudi 2 的最簡單方式。如果您還沒有賬戶,請註冊一個,訂閱“高階版”,然後申請訪問許可權。
在軟體方面,我們將使用 LangChain 構建應用程式,LangChain 是一個旨在簡化使用 LLM 建立 AI 應用程式的開源框架。它提供基於模板的解決方案,允許開發人員使用自定義嵌入、向量資料庫和 LLM 構建 RAG 應用程式。LangChain 文件提供了更多資訊。英特爾一直積極為 LangChain 貢獻多項最佳化,使開發人員能夠在英特爾平臺上高效部署 GenAI 應用程式。
在 LangChain 中,我們將使用 rag-redis 模板建立 RAG 應用程式,其中使用 BAAI/bge-base-en-v1.5 嵌入模型和 Redis 作為預設向量資料庫。下圖顯示了高階架構。
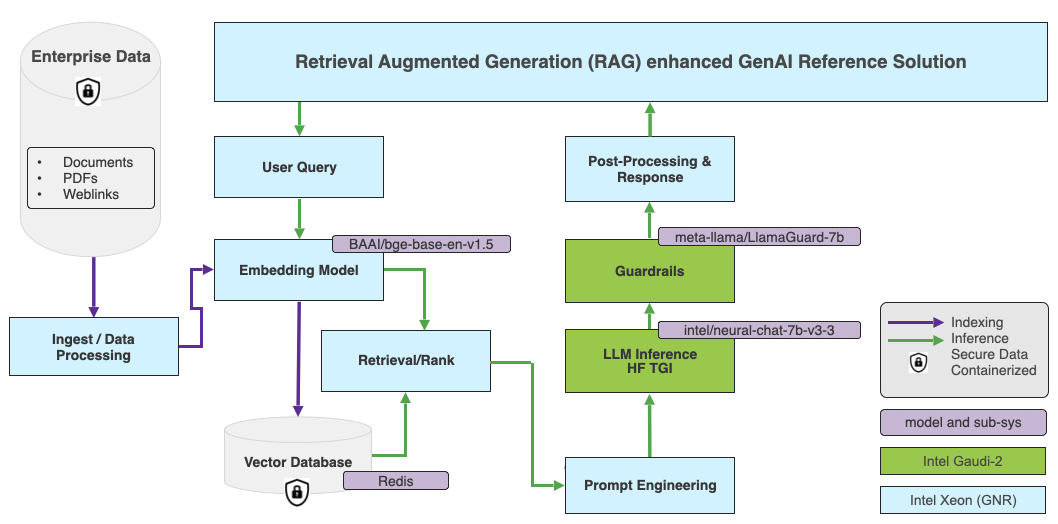
嵌入模型將執行在 Intel Granite Rapids CPU 上。Intel Granite Rapids 架構經過最佳化,可為高核心效能敏感型工作負載和通用計算工作負載提供最低的總擁有成本 (TCO)。GNR 還支援 AMX-FP16 指令集,可為混合 AI 工作負載帶來 2-3 倍的效能提升。
LLM 將執行在 Intel Gaudi 2 加速器上。對於 Hugging Face 模型,Optimum Habana 庫是 Hugging Face Transformers 和 Diffusers 庫與 Gaudi 之間的介面。它為各種下游任務的單卡和多卡設定上的模型載入、訓練和推理提供了簡便的工具。
我們提供了一個 Dockerfile,以簡化 LangChain 開發環境的設定。啟動 Docker 容器後,您可以在 Docker 環境中開始構建向量資料庫、RAG 管道和 LangChain 應用程式。有關詳細的逐步說明,請遵循 ChatQnA 示例。
建立向量資料庫
為了填充向量資料庫,我們使用了耐克公司的公開財務檔案。以下是示例程式碼。
# Ingest PDF files that contain Edgar 10k filings data for Nike.
company_name = "Nike"
data_path = "data"
doc_path = [os.path.join(data_path, file) for file in os.listdir(data_path)][0]
content = pdf_loader(doc_path)
chunks = text_splitter.split_text(content)
# Create vectorstore
embedder = HuggingFaceEmbeddings(model_name=EMBED_MODEL)
_ = Redis.from_texts(
texts=[f"Company: {company_name}. " + chunk for chunk in chunks],
embedding=embedder,
index_name=INDEX_NAME,
index_schema=INDEX_SCHEMA,
redis_url=REDIS_URL,
)
定義 RAG 管道
在 LangChain 中,我們使用 Chain API 連線提示、向量資料庫和嵌入模型。
完整的程式碼可在 倉庫 中找到。
# Embedding model running on Xeon CPU
embedder = HuggingFaceEmbeddings(model_name=EMBED_MODEL)
# Redis vector database
vectorstore = Redis.from_existing_index(
embedding=embedder, index_name=INDEX_NAME, schema=INDEX_SCHEMA, redis_url=REDIS_URL
)
# Retriever
retriever = vectorstore.as_retriever(search_type="mmr")
# Prompt template
template = """…"""
prompt = ChatPromptTemplate.from_template(template)
# Hugging Face LLM running on Gaudi 2
model = HuggingFaceEndpoint(endpoint_url=TGI_LLM_ENDPOINT, …)
# RAG chain
chain = (
RunnableParallel({"context": retriever, "question": RunnablePassthrough()}) | prompt | model | StrOutputParser()
).with_types(input_type=Question)
在 Gaudi 2 上載入 LLM
我們將使用 Hugging Face Text Generation Inference (TGI) 伺服器在 Gaudi2 上執行我們的聊天模型。這種組合可以在 Gaudi2 硬體上為流行的開源 LLM(如 MPT、Llama 和 Mistral)實現高效能文字生成。
無需設定。我們可以使用預構建的 Docker 映象並傳入模型名稱(例如,Intel NeuralChat)。
model=Intel/neural-chat-7b-v3-3
volume=$PWD/data
docker run -p 8080:80 -v $volume:/data --runtime=habana -e HABANA_VISIBLE_DEVICES=all -e OMPI_MCA_btl_vader_single_copy_mechanism=none --cap-add=sys_nice --ipc=host tgi_gaudi --model-id $model
服務預設使用單個 Gaudi 加速器。執行更大的模型(例如,70B)可能需要多個加速器。在這種情況下,請新增適當的引數,例如 --sharded true 和 --num_shard 8。對於 Llama 或 StarCoder 等受限模型,您還需要使用您的 Hugging Face token 指定 -e HUGGING_FACE_HUB_TOKEN=<token>。
容器執行後,我們透過向 TGI 端點發送請求來檢查服務是否正常工作。
curl localhost:8080/generate -X POST \
-d '{"inputs":"Which NFL team won the Super Bowl in the 2010 season?", \
"parameters":{"max_new_tokens":128, "do_sample": true}}' \
-H 'Content-Type: application/json'
如果您看到生成的響應,則 LLM 執行正常,您現在可以在 Gaudi 2 上享受高效能推理!
TGI Gaudi 容器預設使用 bfloat16 資料型別。為了獲得更高的吞吐量,您可能希望啟用 FP8 量化。根據我們的測試結果,FP8 量化應該比 BF16 帶來 1.8 倍的吞吐量提升。FP8 指令可在 README 檔案中找到。
最後,您可以使用 Meta Llama Guard 模型啟用內容稽核。README 檔案提供了在 TGI Gaudi 上部署 Llama Guard 的說明。
執行 RAG 服務
我們使用以下說明啟動 RAG 應用程式後端服務。server.py 指令碼使用 fastAPI 定義服務端點。
docker exec -it qna-rag-redis-server bash
nohup python app/server.py &
預設情況下,TGI Gaudi 端點應在 localhost 的 8080 埠(即 http://127.0.0.1:8080)上執行。如果它在不同的地址或埠上執行,請相應地設定 TGI_ENDPOINT 環境變數。
啟動 RAG GUI
我們使用以下說明安裝前端 GUI 元件。
sudo apt-get install npm && \
npm install -g n && \
n stable && \
hash -r && \
npm install -g npm@latest
然後,我們透過將 .env 檔案中的 DOC_BASE_URL 環境變數中的 localhost IP 地址 (127.0.0.1) 替換為 GUI 執行伺服器的實際 IP 地址來更新它。
我們執行以下命令安裝所需依賴項
npm install
最後,我們使用以下命令啟動 GUI 伺服器
nohup npm run dev &
這將執行前端服務並啟動應用程式。
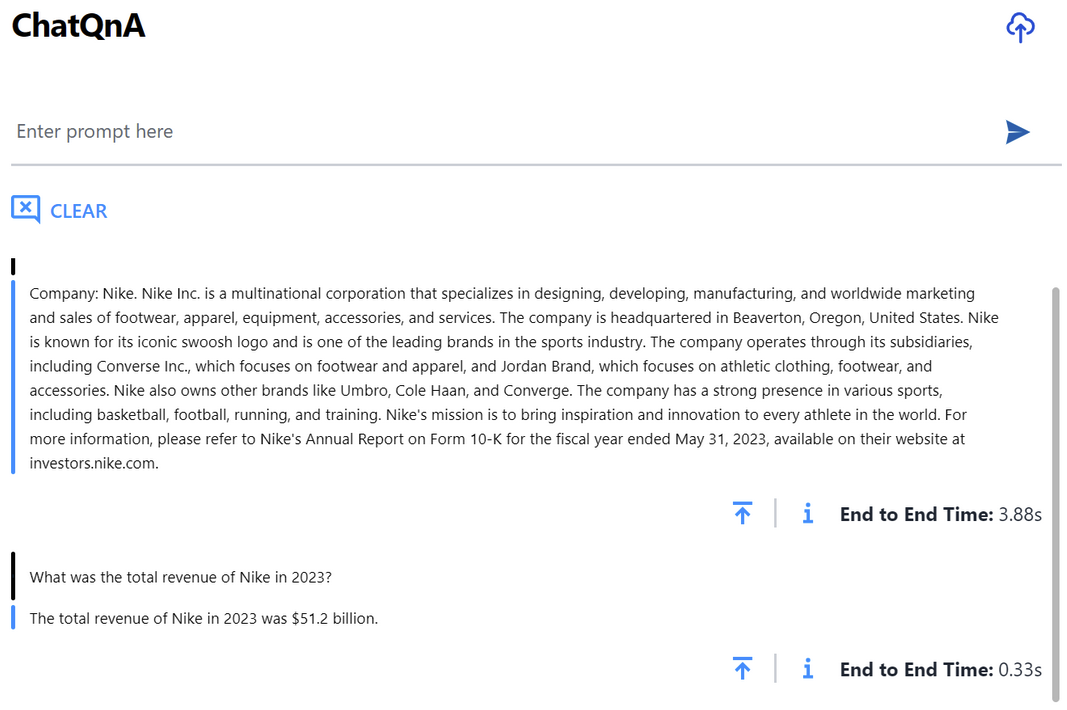
基準測試結果
我們對不同的模型和配置進行了密集的實驗。下面兩圖展示了 Llama2-70B 模型在 16 個併發使用者下,在四個 Intel Gaudi 2 和四個 Nvidia H100 平臺上端到端吞吐量和每美元效能的相對比較。
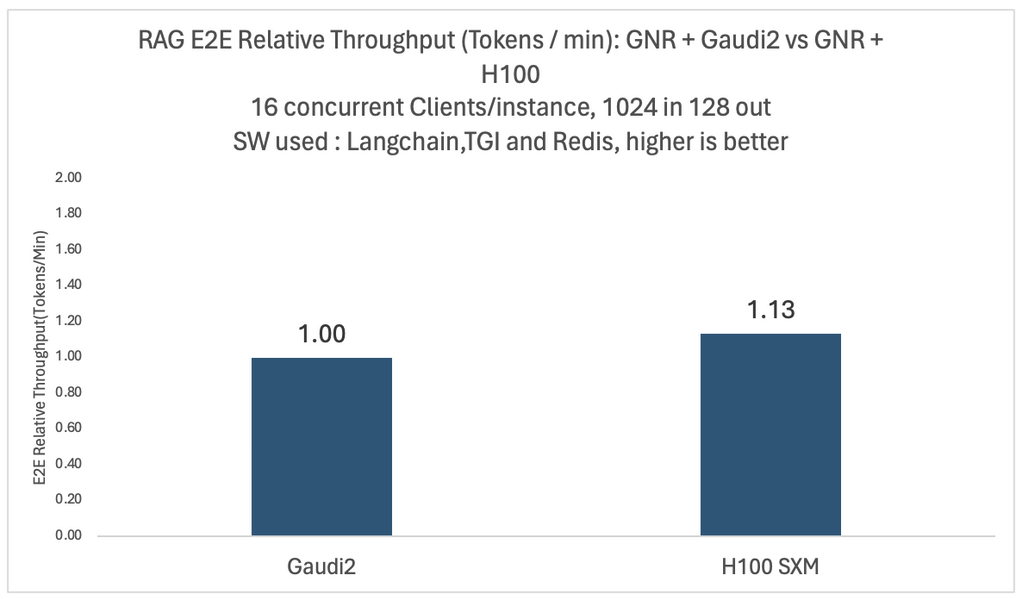
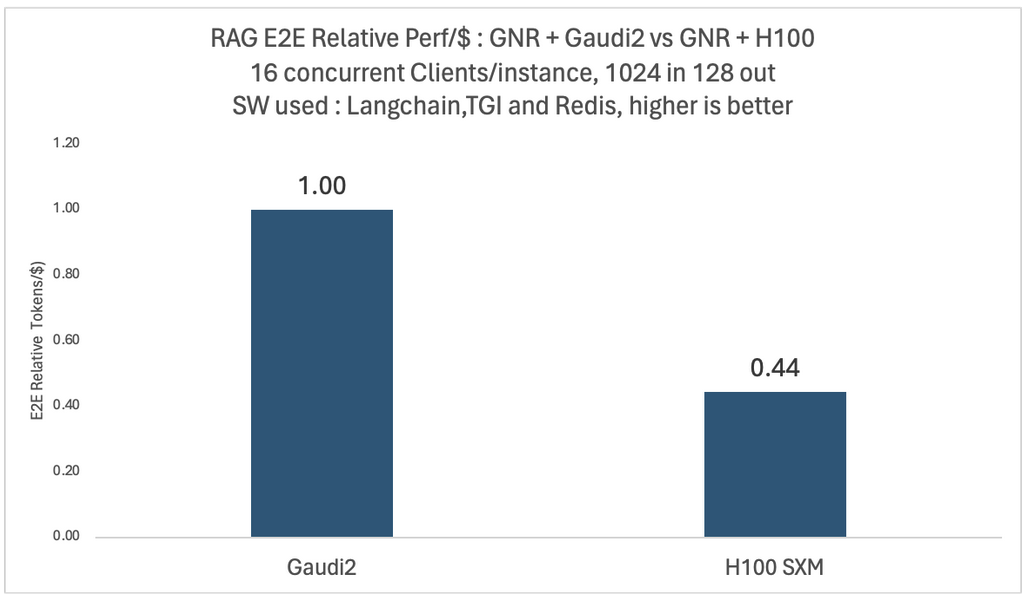
在這兩種情況下,向量資料庫和嵌入模型都使用了相同的 Intel Granite Rapids CPU 平臺。對於每美元效能比較,我們使用公開定價計算平均訓練每美元效能,這與 MosaicML 團隊在 2024 年 1 月報告的相同。
如您所見,基於 H100 的系統吞吐量高出 1.13 倍,但每美元效能僅為 Gaudi 2 的 0.44 倍。這些比較可能會因不同雲提供商的客戶特定折扣而異。詳細的基準測試配置列於文章末尾。
結論
上述部署示例成功展示了基於 RAG 的聊天機器人在英特爾平臺上的執行。此外,隨著英特爾不斷髮布即用型 GenAI 示例,開發人員受益於經過驗證的工具,這些工具簡化了建立和部署過程。這些示例具有通用性和易於定製的特點,使其成為英特爾平臺上廣泛應用的理想選擇。
在執行企業 AI 應用程式時,基於 Intel Granite Rapids CPU 和 Gaudi 2 加速器的系統具有更低的總體擁有成本。透過 FP8 最佳化,還可以進一步提高效能。
以下開發者資源應能幫助您自信地啟動您的 GenAI 專案。
如果您有任何問題或反饋,我們很樂意在 Hugging Face 論壇上回答。感謝閱讀!
致謝:我們感謝 Chaitanya Khened、Suyue Chen、Mikolaj Zyczynski、Wenjiao Yue、Wenxin Zhang、Letong Han、Sihan Chen、Hanwen Cheng、Yuan Wu 和 Yi Wang 在 Intel Gaudi 2 上構建企業級 RAG 系統方面做出的傑出貢獻。
基準測試配置
Gaudi2 配置:HLS-Gaudi2,帶八塊 Habana Gaudi2 HL-225H Mezzanine 卡和兩顆 Intel® Xeon® Platinum 8380 CPU @ 2.30GHz,以及 1TB 系統記憶體;作業系統:Ubuntu 22.04.03,5.15.0 核心
H100 SXM 配置:Lambda labs 例項 gpu_8x_h100_sxm5;8xH100 SXM 和兩顆 Intel Xeon® Platinum 8480 CPU@2 GHz,以及 1.8TB 系統記憶體;作業系統 Ubuntu 20.04.6 LTS,5.15.0 核心
Intel Xeon:預生產的 Granite Rapids 平臺,配備 2Sx120C @ 1.9GHz 和 8800 MCR DIMM,以及 1.5TB 系統記憶體。作業系統:CentOS 9,6.2.0 核心
Llama2 70B 部署到 4 張卡(查詢歸一化到 8 張卡)。Gaudi2 使用 BF16,H100 使用 FP16。
嵌入模型為 BAAI/bge-base v1.5。測試使用:TGI-gaudi 1.2.1, TGI-GPU 1.4.5 Python 3.11.7, Langchain 0.1.11, sentence-transformers 2.5.1, langchain benchmarks 0.0.10, redis 5.0.2, cuda 12.2.r12.2/compiler.32965470 0, TEI 1.2.0,
RAG 查詢最大輸入長度 1024,最大輸出長度 128。測試資料集:langsmith Q&A。併發客戶端數量 16
Gaudi2 (70B) 的 TGI 引數:
batch_bucket_size=22,prefill_batch_bucket_size=4,max_batch_prefill_tokens=5102,max_batch_total_tokens=32256,max_waiting_tokens=5,streaming=falseH100 (70B) 的 TGI 引數:
batch_bucket_size=8,prefill_batch_bucket_size=4,max_batch_prefill_tokens=4096,max_batch_total_tokens=131072,max_waiting_tokens=20,max_batch_size=128,streaming=false總擁有成本參考:https://www.databricks.com/blog/llm-training-and-inference-intel-gaudi2-ai-accelerators






