使用《太空侵略者》進行深度 Q 學習


《使用 Hugging Face 🤗 的深度強化學習課程》第三單元
⚠️ 本文的最新更新版本可在此處獲取 👉 https://huggingface.co/deep-rl-course/unit1/introduction
本文是深度強化學習課程的一部分。這是一個從入門到精通的免費課程。請在此處檢視課程大綱 here.

⚠️ 本文的最新更新版本可在此處獲取 👉 https://huggingface.co/deep-rl-course/unit1/introduction
本文是深度強化學習課程的一部分。這是一個從入門到精通的免費課程。請在此處檢視課程大綱 here.
在上一單元中,我們學習了第一個強化學習演算法:Q 學習,並從頭開始實現它,然後在 FrozenLake-v1 ☃️ 和 Taxi-v3 🚕 兩個環境中對其進行了訓練。
我們使用這個簡單的演算法取得了優異的成績。但這些環境相對簡單,因為狀態空間是離散且小的(FrozenLake-v1 有 14 種不同狀態,Taxi-v3 有 500 種)。
但正如我們將看到的,在大型狀態空間環境中,生成和更新 Q 表可能會變得效率低下。
所以今天,我們將研究我們的第一個深度強化學習智慧體:深度 Q 學習。深度 Q 學習不是使用 Q 表,而是使用神經網路,該神經網路以狀態為輸入,並根據該狀態近似每個動作的 Q 值。
我們將使用 RL-Zoo 訓練它玩《太空侵略者》和其他 Atari 環境。RL-Zoo 是一個基於 Stable-Baselines 的 RL 訓練框架,提供用於訓練、評估智慧體、調整超引數、繪製結果和錄製影片的指令碼。

那麼,我們開始吧!🚀
為了理解本單元,您需要首先理解 Q 學習。
從 Q 學習到深度 Q 學習
我們瞭解到,Q 學習是我們用來訓練 Q 函式的演算法,Q 函式是一個動作值函式,它確定處於特定狀態並在該狀態下采取特定動作的價值。
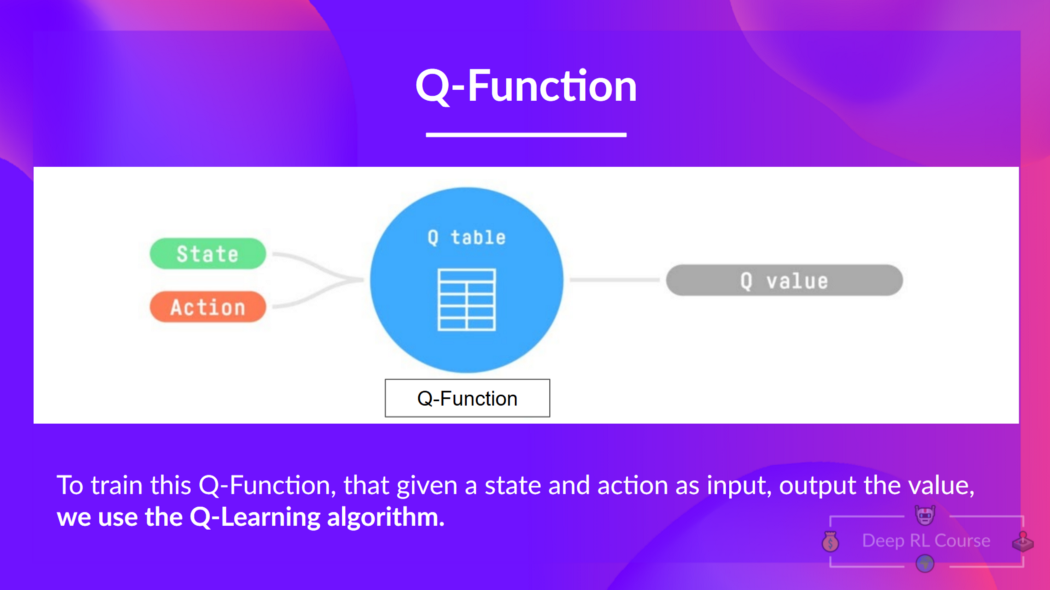
Q 來自該動作在該狀態下的“質量”。
在內部,我們的 Q 函式有一個 Q 表,一個表格,其中每個單元格對應一個狀態-動作對值。將這個 Q 表視為我們 Q 函式的記憶或作弊表。
問題在於 Q 學習是一種表格方法。也就是說,當狀態和動作空間足夠小,可以透過陣列和表格表示價值函式時,它才有效。這不具備可擴充套件性。
Q 學習在小狀態空間環境中表現良好,例如:
- FrozenLake,我們有 14 個狀態。
- Taxi-v3,我們有 500 個狀態。
但想想我們今天要做的:我們將訓練一個智慧體使用幀作為輸入來學習翫《太空侵略者》。
正如尼基塔·梅爾科澤羅夫(Nikita Melkozerov)所說,Atari 環境的觀察空間形狀為 (210, 160, 3),包含 0 到 255 的值,因此這給我們帶來了 256^(210x160x3) = 256^100800(作為比較,我們可觀測宇宙中大約有 10^80 個原子)。
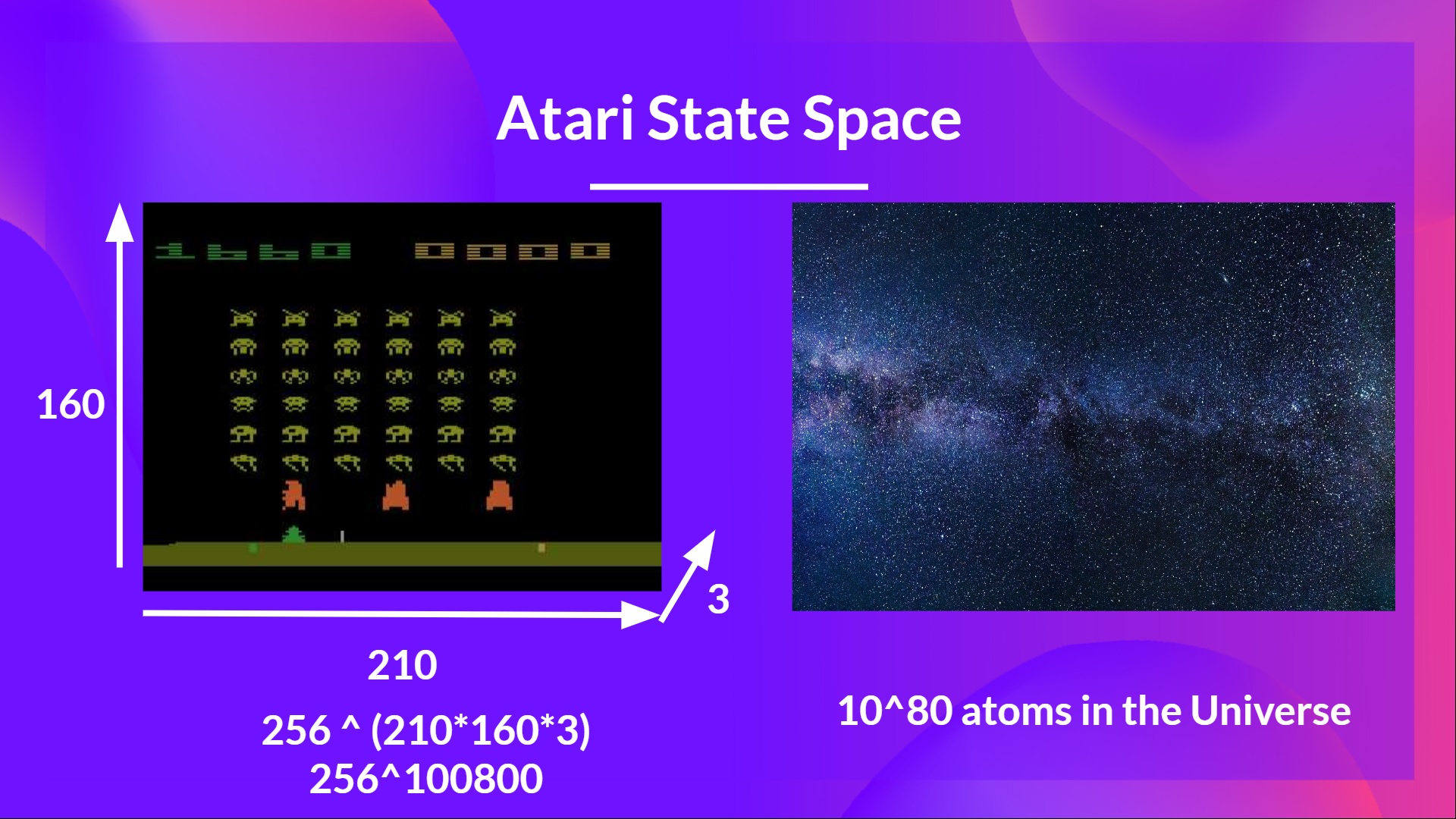
因此,狀態空間是巨大的;因此,為該環境建立和更新 Q 表將效率低下。在這種情況下,最好的方法是使用引數化的 Q 函式 來近似 Q 值,而不是使用 Q 表。
這個神經網路將近似地給出給定狀態下每個可能動作的不同 Q 值。這正是深度 Q 學習所做的。
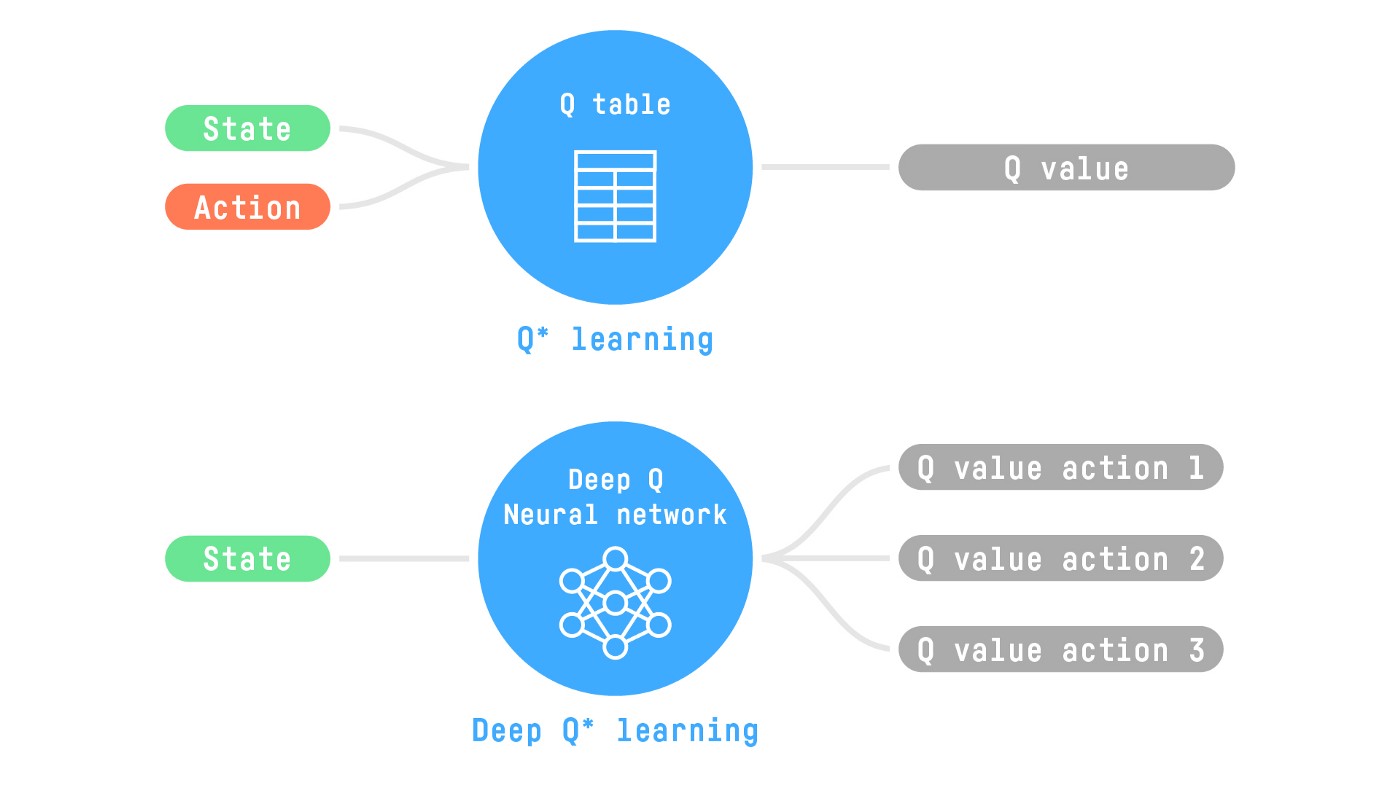
現在我們瞭解了深度 Q 學習,讓我們深入瞭解深度 Q 網路。
深度 Q 網路 (DQN)
這是我們的深度 Q 學習網路的架構
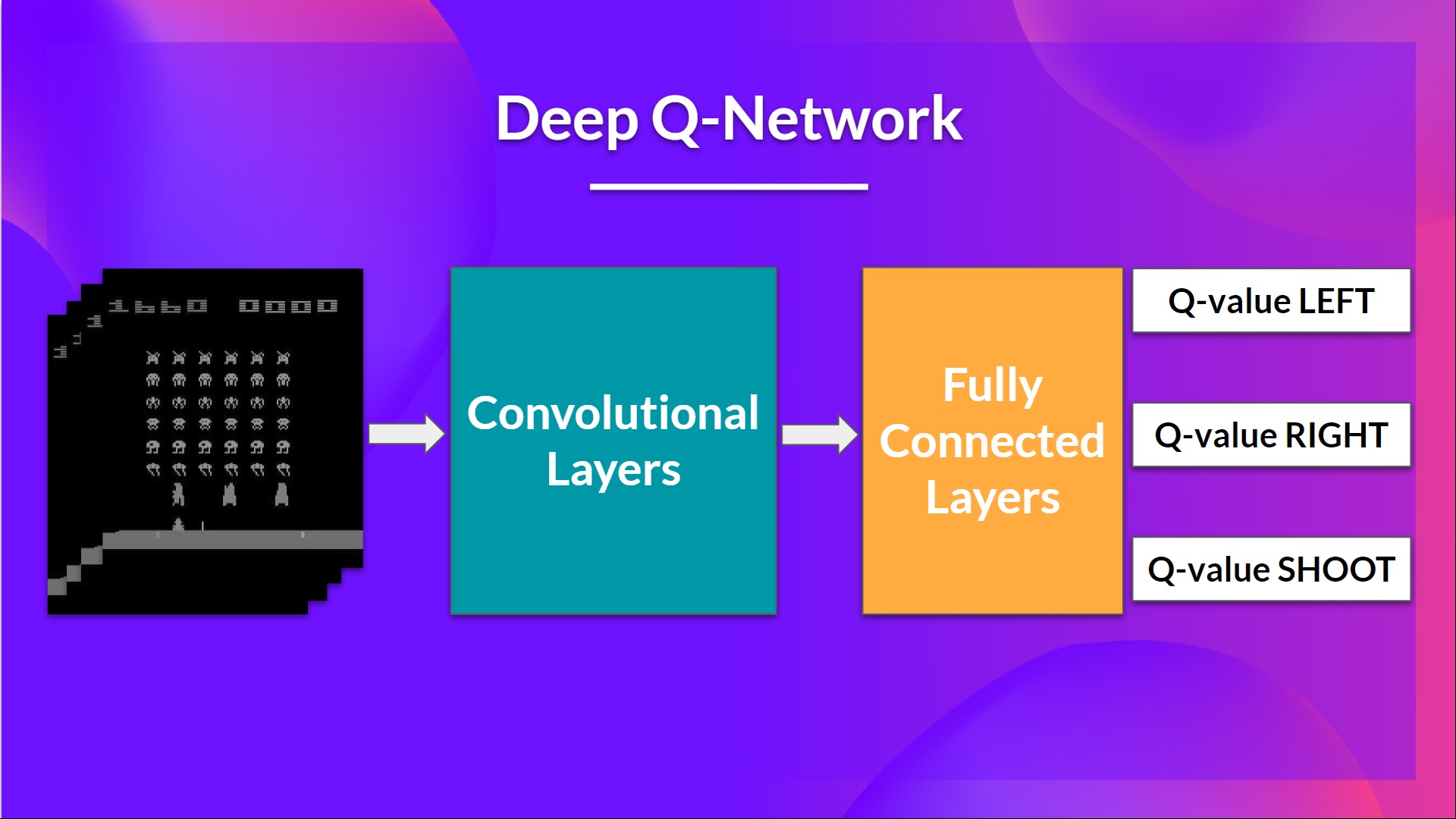
作為輸入,我們獲取4 幀的堆疊作為狀態透過網路,並輸出一個向量,其中包含該狀態下每個可能動作的 Q 值。然後,像 Q 學習一樣,我們只需使用 epsilon-greedy 策略來選擇要執行的動作。
當神經網路初始化時,Q 值估計很糟糕。但在訓練期間,我們的深度 Q 網路智慧體將把情況與適當的動作關聯起來,並學會很好地玩遊戲。
輸入預處理和時間限制
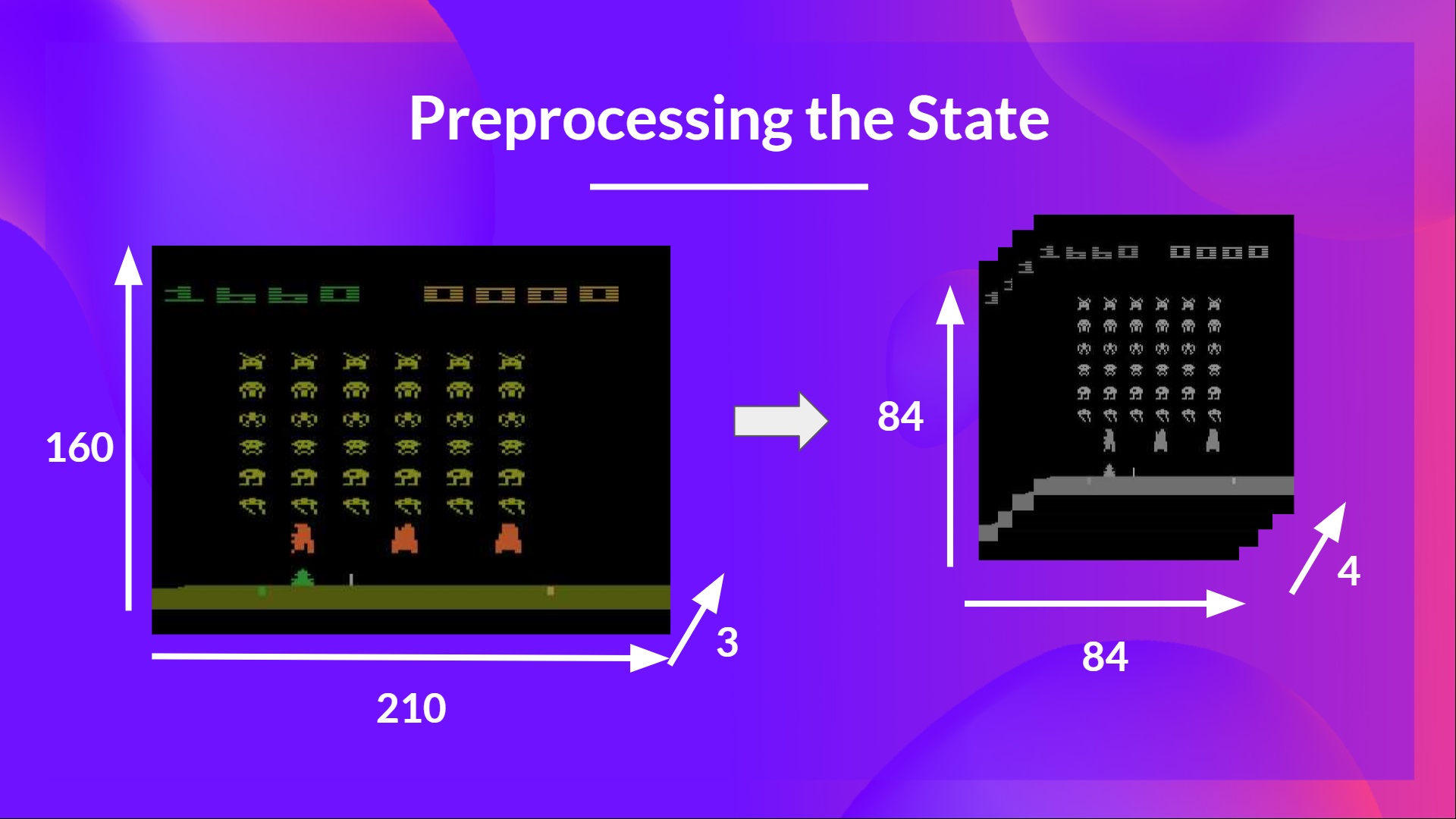
我們提到我們預處理輸入。這是一個重要的步驟,因為我們希望降低狀態的複雜性,以減少訓練所需的計算時間。
所以我們所做的是將狀態空間縮小到 84x84 並進行灰度處理(因為 Atari 環境中的顏色沒有增加重要資訊)。這是一個重要的節省,因為我們將三個顏色通道(RGB)減少到 1 個。
在某些遊戲中,如果螢幕的某個部分不包含重要資訊,我們還可以裁剪它。然後我們將四幀堆疊在一起。
我們為什麼要將四幀堆疊在一起?我們將幀堆疊在一起有助於我們處理時間限制問題。我們以 Pong 遊戲為例。當您看到這一幀時:

你能告訴我球的走向嗎?不能,因為一幀不足以感知運動!但如果我再新增三幀呢?現在你可以看到球正向右邊移動。
 這就是為什麼,為了捕捉時間資訊,我們將四幀堆疊在一起。
這就是為什麼,為了捕捉時間資訊,我們將四幀堆疊在一起。然後,堆疊的幀由三個卷積層處理。這些層允許我們捕獲和利用影像中的空間關係。此外,由於幀是堆疊在一起的,您可以利用這些幀之間的一些空間屬性。
最後,我們有幾個全連線層,它們輸出該狀態下每個可能動作的 Q 值。
因此,我們看到深度 Q 學習使用神經網路來近似給定狀態下每個可能動作的不同 Q 值。現在讓我們研究深度 Q 學習演算法。
深度 Q 學習演算法
我們瞭解到,深度 Q 學習使用深度神經網路來近似給定狀態下每個可能動作的不同 Q 值(值函式估計)。
不同之處在於,在訓練階段,我們不是像 Q 學習那樣直接更新狀態-動作對的 Q 值,

在深度 Q 學習中,我們建立了一個損失函式,用於衡量我們的 Q 值預測與 Q 目標之間的差異,並使用梯度下降來更新深度 Q 網路的權重,以更好地近似我們的 Q 值。

深度 Q 學習訓練演算法有兩個階段
- 取樣:我們執行動作並將觀察到的經驗元組儲存在重放記憶中。
- 訓練:隨機選擇一小批元組,並使用梯度下降更新步驟從中學習。

但是,這並不是與 Q 學習相比的唯一變化。深度 Q 學習訓練可能會受到不穩定性困擾,主要是由於結合了非線性 Q 值函式(神經網路)和自舉(當我們用現有估計而不是實際完整回報更新目標時)。
為了幫助我們穩定訓練,我們實施了三種不同的解決方案:
- 經驗回放,以更有效地利用經驗。
- 固定 Q 目標以穩定訓練。
- 雙重深度 Q 學習,以處理 Q 值過高估計的問題。
經驗回放以更有效地利用經驗
我們為什麼建立重放記憶?
深度 Q 學習中的經驗回放有兩個功能
- 在訓練過程中更有效地利用經驗.
- 經驗回放幫助我們在訓練過程中更有效地利用經驗。通常,在線上強化學習中,我們在環境中進行互動,獲取經驗(狀態、動作、獎勵和下一個狀態),從中學習(更新神經網路)並丟棄它們。
- 但是透過經驗回放,我們建立了一個重放緩衝區,它儲存了我們可以在訓練期間重複使用的經驗樣本。

⇒ 這使我們能夠從單個經驗中多次學習。
- 避免遺忘過去的經驗並減少經驗之間的相關性.
- 如果我們向神經網路提供順序的經驗樣本,就會出現一個問題:它傾向於遺忘過去的經驗,因為新的經驗會覆蓋舊的經驗。例如,如果我們在第一關,然後是第二關(不同),我們的智慧體可能會忘記如何在第一關中行動和玩遊戲。
解決方案是建立一個回放緩衝區,在與環境互動時儲存經驗元組,然後取樣一小批元組。這可以防止網路只學習它立即做過的事情。
經驗回放還有其他好處。透過隨機取樣經驗,我們消除了觀察序列中的相關性,並避免了動作值振盪或災難性發散。
在深度 Q 學習的虛擬碼中,我們看到我們初始化一個容量為 N 的重放記憶體緩衝區 D(N 是您可以定義的超引數)。然後我們將經驗儲存在記憶體中,並採樣一個經驗小批次,在訓練階段將其饋送到深度 Q 網路。

固定 Q 目標以穩定訓練
當我們要計算 TD 誤差(即損失)時,我們計算TD 目標(Q 目標)與當前 Q 值(Q 的估計值)之間的差異。
但是,我們沒有任何關於真實 TD 目標的想法。我們需要估計它。使用貝爾曼方程,我們看到 TD 目標只是在該狀態下采取該動作的獎勵加上下一個狀態的折扣最高 Q 值。
然而,問題在於我們使用相同的引數(權重)來估計 TD 目標和 Q 值。因此,TD 目標和我們正在改變的引數之間存在顯著相關性。
因此,這意味著在訓練的每一步,我們的 Q 值都在變化,而目標值也在變化。這就像追逐一個移動的目標!這導致訓練中出現顯著的振盪。
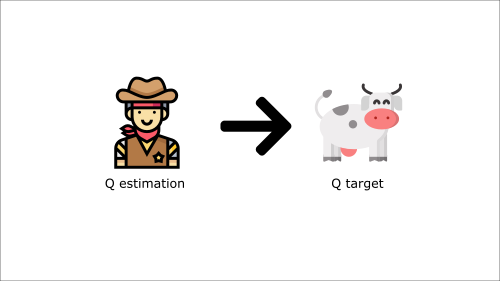
這就像你是一個牛仔(Q 估計),你想抓住牛(Q 目標),你必須靠近(減少誤差)。
在每個時間步,你都試圖接近牛,而牛也在每個時間步移動(因為你使用相同的引數)。

 這導致了奇怪的追逐路徑(訓練中的顯著振盪)。
這導致了奇怪的追逐路徑(訓練中的顯著振盪)。 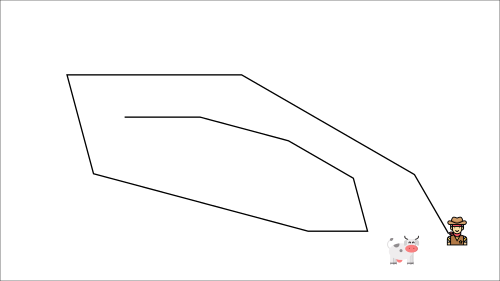
相反,我們在虛擬碼中看到的是:
- 使用一個具有固定引數的獨立網路來估計 TD 目標。
- 每隔 C 步從我們的深度 Q 網路複製引數以更新目標網路。

雙重 DQN
雙重 DQN 或雙重學習由 Hado van Hasselt 提出。這種方法解決了 Q 值高估的問題。
為了理解這個問題,請記住我們如何計算 TD 目標
透過計算 TD 目標,我們面臨一個簡單的問題:我們如何確定下一個狀態的最佳動作是具有最高 Q 值的動作?
我們知道 Q 值的準確性取決於我們嘗試的動作和我們探索的相鄰狀態。
因此,在訓練開始時,我們沒有足夠的資訊來判斷要採取的最佳行動。因此,將最大 Q 值(有噪聲)作為要採取的最佳行動可能會導致誤報。如果非最優行動經常被賦予高於最優最佳行動的 Q 值,那麼學習將變得複雜。
解決方案是:在計算 Q 目標時,我們使用兩個網路將動作選擇與目標 Q 值生成解耦。我們:
- 使用我們的 DQN 網路為下一個狀態選擇最佳動作(具有最高 Q 值的動作)。
- 使用我們的目標網路計算在下一個狀態下執行該動作的目標 Q 值。
因此,雙重 DQN 有助於我們減少 Q 值的過高估計,從而有助於我們更快地訓練並獲得更穩定的學習。
自深度 Q 學習這三個改進以來,又增加了許多改進,例如優先經驗回放、對抗深度 Q 學習。這些超出了本課程的範圍,但如果您感興趣,請檢視我們在閱讀列表中列出的連結。👉 https://github.com/huggingface/deep-rl-class/blob/main/unit3/README.md
現在您已經學習了深度 Q 學習的理論,您已經準備好訓練您的深度 Q 學習智慧體來玩 Atari 遊戲了。我們將從《太空侵略者》開始,但您可以使用任何您想玩的 Atari 遊戲🔥
我們使用的是 RL-Baselines-3 Zoo 整合,它是深度 Q 學習的原始版本,沒有雙重 DQN、對戰 DQN 和優先經驗回放等擴充套件。
從這裡開始教程 👉 https://colab.research.google.com/github/huggingface/deep-rl-class/blob/main/unit3/unit3.ipynb
與同學比較結果的排行榜 🏆 👉 https://huggingface.co/spaces/chrisjay/Deep-Reinforcement-Learning-Leaderboard
恭喜您完成本章!資訊量很大。恭喜您完成本教程。您剛剛訓練了您的第一個深度 Q 學習智慧體並將其分享到 Hub 🥳。
如果所有這些元素讓你**仍然感到困惑**,那是**正常現象**。**我和所有學習強化學習的人都經歷過同樣的感覺。**
花時間真正掌握這些材料,然後再繼續。
不要猶豫,在其他環境(Pong、Seaquest、QBert、Ms Pac Man)中訓練您的智慧體。最好的學習方式是自己嘗試!
如果您想深入瞭解,我們在教學大綱中釋出了額外的閱讀材料 👉 https://github.com/huggingface/deep-rl-class/blob/main/unit3/README.md
在下一單元中,我們將學習策略梯度方法。
別忘了分享給你想學習的朋友 🤗!
最後,我們希望根據您的反饋迭代改進和更新課程。如果您有任何反饋,請填寫此表格 👉 https://forms.gle/3HgA7bEHwAmmLfwh9

