Q-Learning 簡介 第 2/2 部分


Hugging Face 🤗 深度強化學習課程第二單元第 2 部分
⚠️ 本文的最新更新版本在此處提供 👉 https://huggingface.co/deep-rl-course/unit1/introduction
本文是深度強化學習課程的一部分。這是一個從入門到精通的免費課程。請在此處檢視課程大綱 here.
⚠️ 本文的最新更新版本在此處提供 👉 https://huggingface.co/deep-rl-course/unit1/introduction
本文是深度強化學習課程的一部分。這是一個從入門到精通的免費課程。請在此處檢視課程大綱 here.
在本單元的第一部分,我們學習了基於值的方法以及蒙特卡羅學習與時序差分學習之間的區別。
因此,在第二部分中,我們將學習 Q-Learning,並從頭開始實現我們的第一個強化學習代理,一個 Q-Learning 代理,並將在兩個環境中對其進行訓練
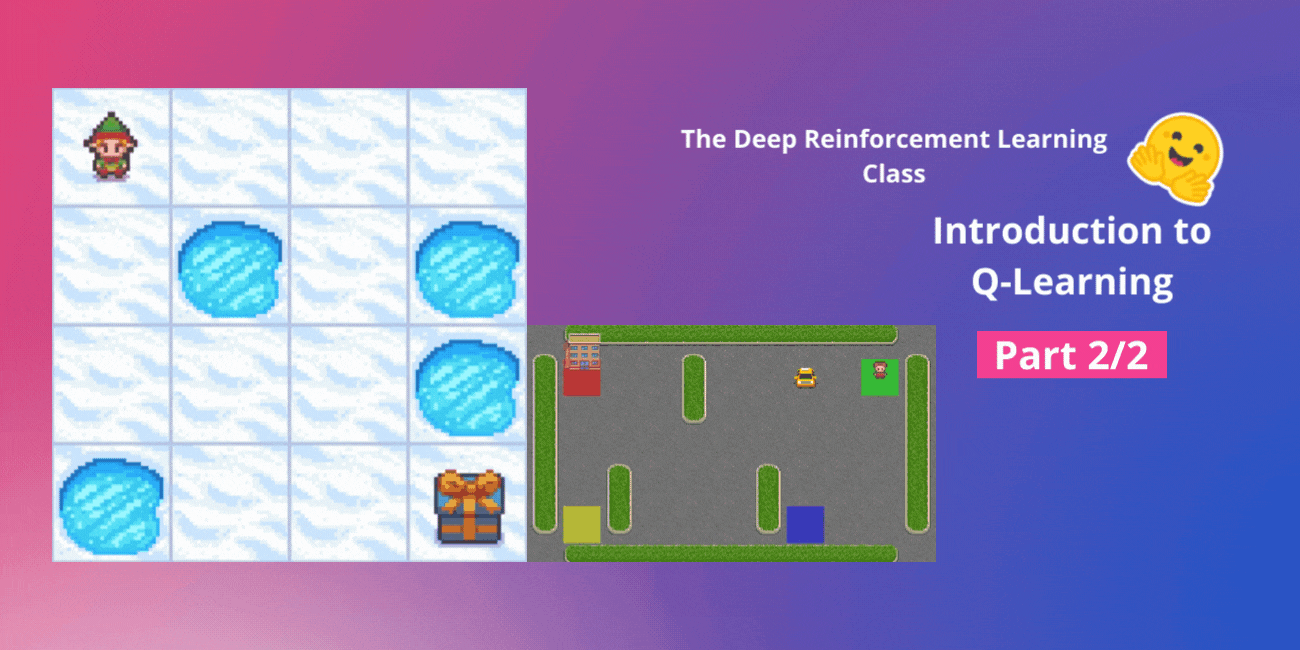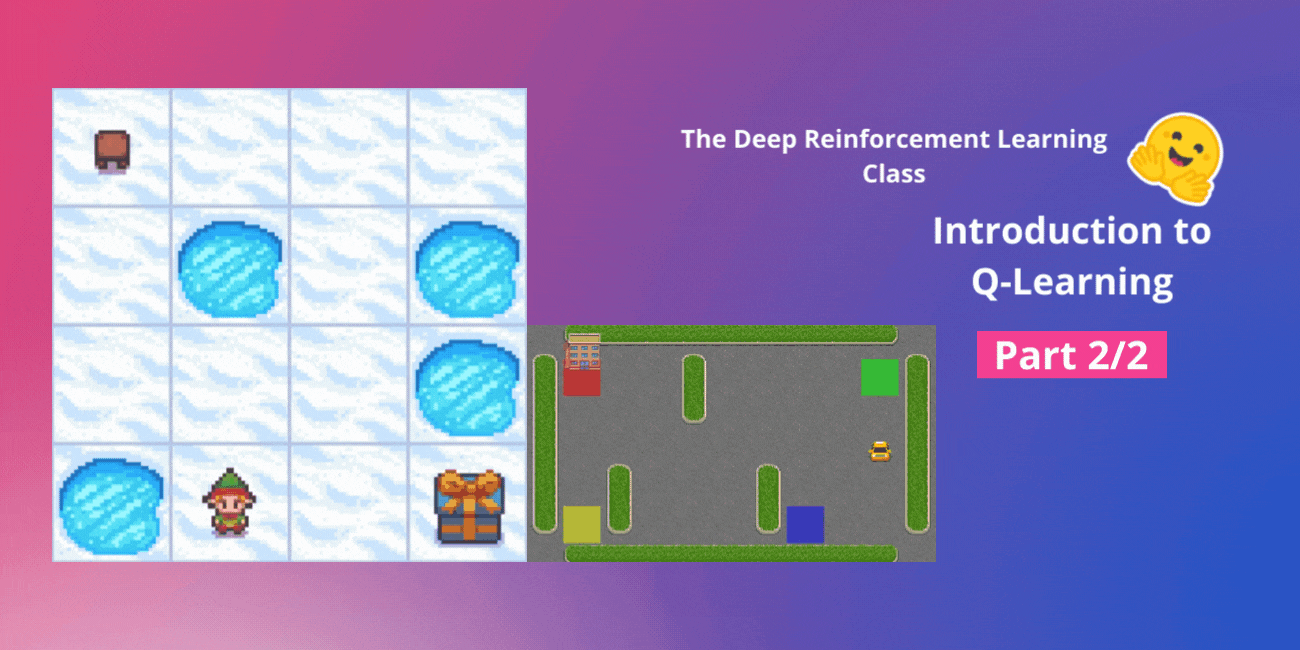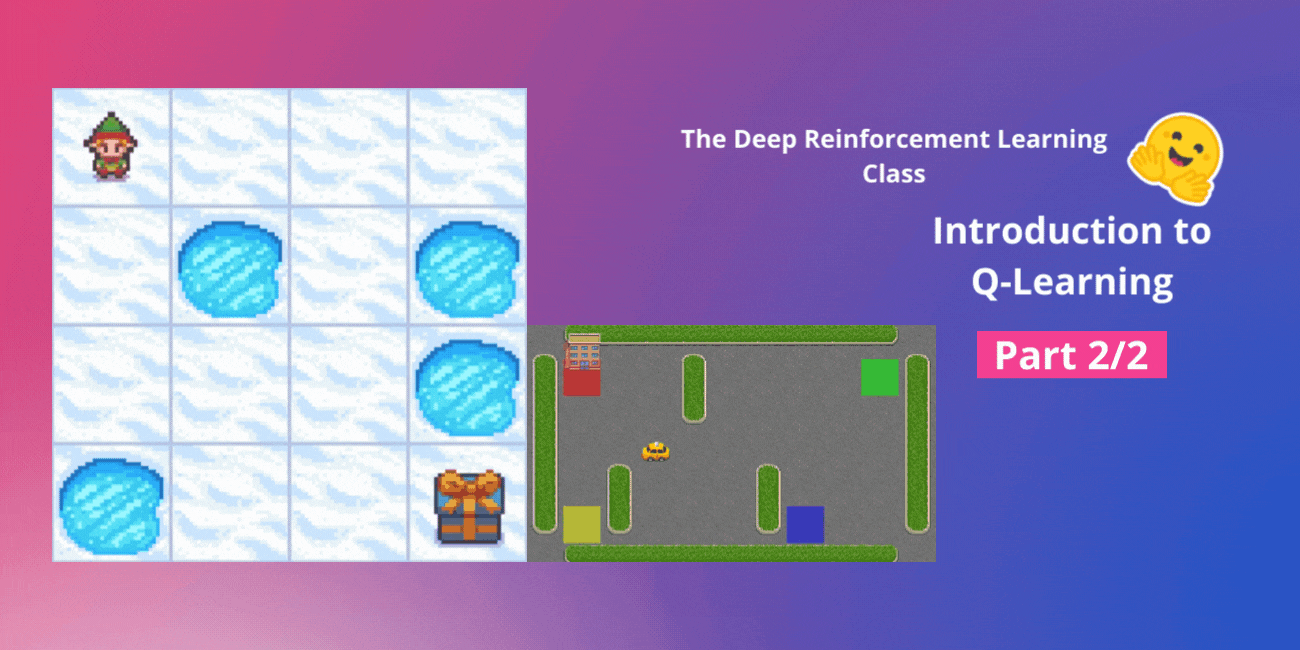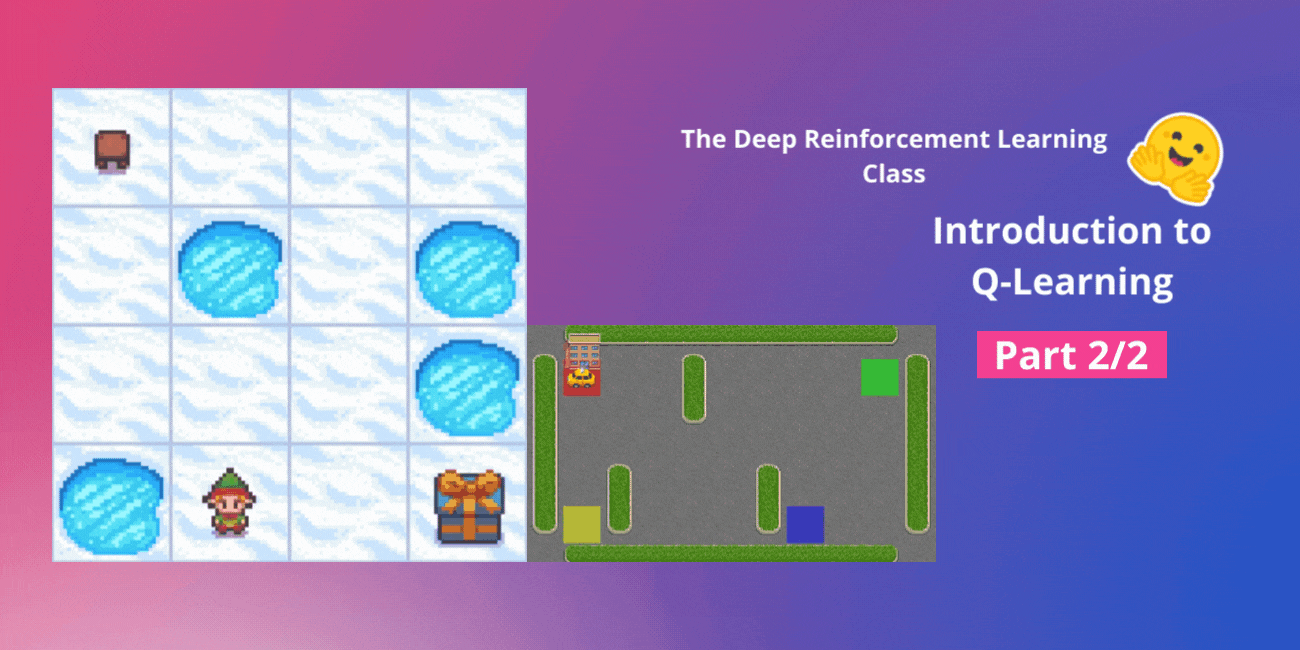
- 冰凍湖 v1 ❄️:我們的代理需要透過只在冰凍磚塊 (F) 上行走並避開洞 (H) 來從起始狀態 (S) 到達目標狀態 (G)。
- 一輛自動計程車 🚕:代理將需要學習如何在一座城市中導航,將乘客從 A 點運送到 B 點。
如果您想學習深度 Q-Learning(第三單元),本單元至關重要。
那麼,我們開始吧!🚀
Q-Learning 介紹
什麼是 Q-Learning?
Q-Learning 是一種離策略的基於值的方法,它使用 TD 方法來訓練其動作-值函式:
- 離策略:我們將在本章末尾討論。
- 基於值的方法:透過訓練一個值函式或動作-值函式間接找到最優策略,該函式將告訴我們每個狀態或每個狀態-動作對的值。
- 使用 TD 方法:在每一步而不是在情節結束時更新其動作-值函式。
Q-Learning 是我們用來訓練 Q-函式(一種動作-值函式)的演算法,它確定了在特定狀態下采取特定動作的價值。
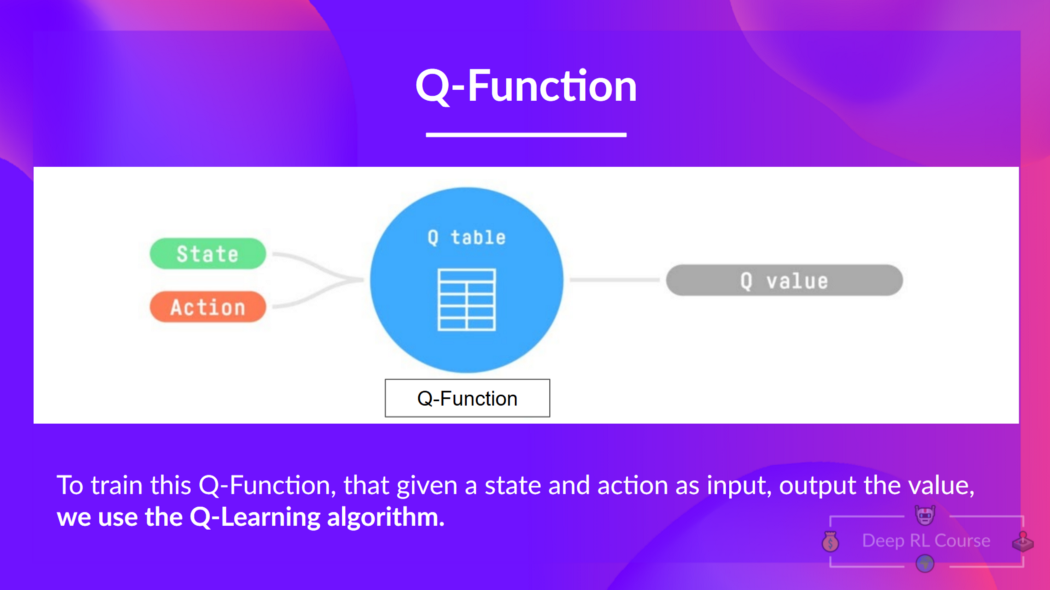
Q 來自於該動作在該狀態下的“質量”。
在內部,我們的 Q-函式有一個 Q-表,其中每個單元格對應一個狀態-動作值對。 將此 Q-表視為我們 Q-函式的記憶或備忘錄。
如果我們以這個迷宮為例

Q 表已初始化。這就是為什麼所有值都 = 0。此表包含每個狀態的四個狀態-動作值。

這裡我們看到,初始狀態並向上移動的狀態-動作值為 0:

因此,Q-函式包含一個 Q-表,其中包含每個狀態-動作對的值。 給定一個狀態和動作,我們的 Q-函式將在其 Q-表中搜索並輸出該值。
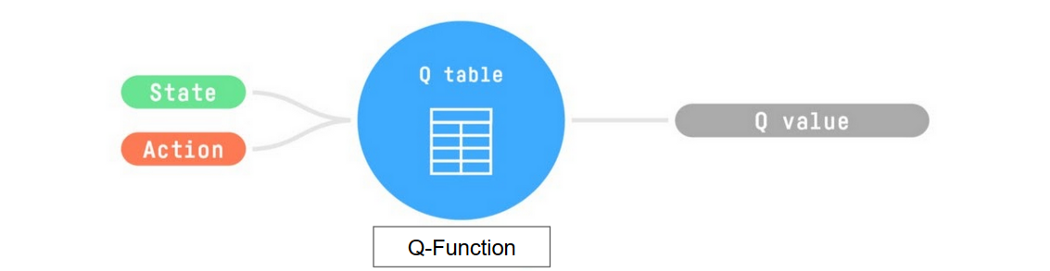
回顧一下,Q-Learning 是強化學習演算法,它:
- 訓練Q-函式(一個動作-值函式),它內部是一個Q-表,包含所有狀態-動作對的值。
- 給定一個狀態和動作,我們的 Q 函式將在其 Q-表中搜索相應的值。
- 訓練完成後,我們擁有一個最優的 Q 函式,這意味著我們擁有一個最優的 Q 表。
- 如果我們擁有最優的 Q 函式,我們就擁有最優策略,因為我們知道在每個狀態下應該採取的最佳動作。

但是,在訓練開始時,我們的 Q 表是無用的,因為它為每個狀態-動作對提供了任意值(大多數情況下,我們將 Q 表初始化為 0)。但是,隨著我們探索環境並更新 Q 表,它將為我們提供越來越好的近似值。

現在我們已經瞭解了 Q-Learning、Q-Function 和 Q-Table 是什麼,讓我們深入瞭解 Q-Learning 演算法。
Q-Learning 演算法
這是 Q-Learning 的虛擬碼;讓我們研究每個部分,並透過一個簡單的例子來看看它是如何工作的,然後再實現它。 不要被它嚇倒,它比看起來簡單!我們將逐步介紹每個步驟。

步驟 1:我們初始化 Q-表

我們需要為每個狀態-動作對初始化 Q-表。大多數情況下,我們將其初始化為 0。
步驟 2:使用 Epsilon 貪婪策略選擇動作
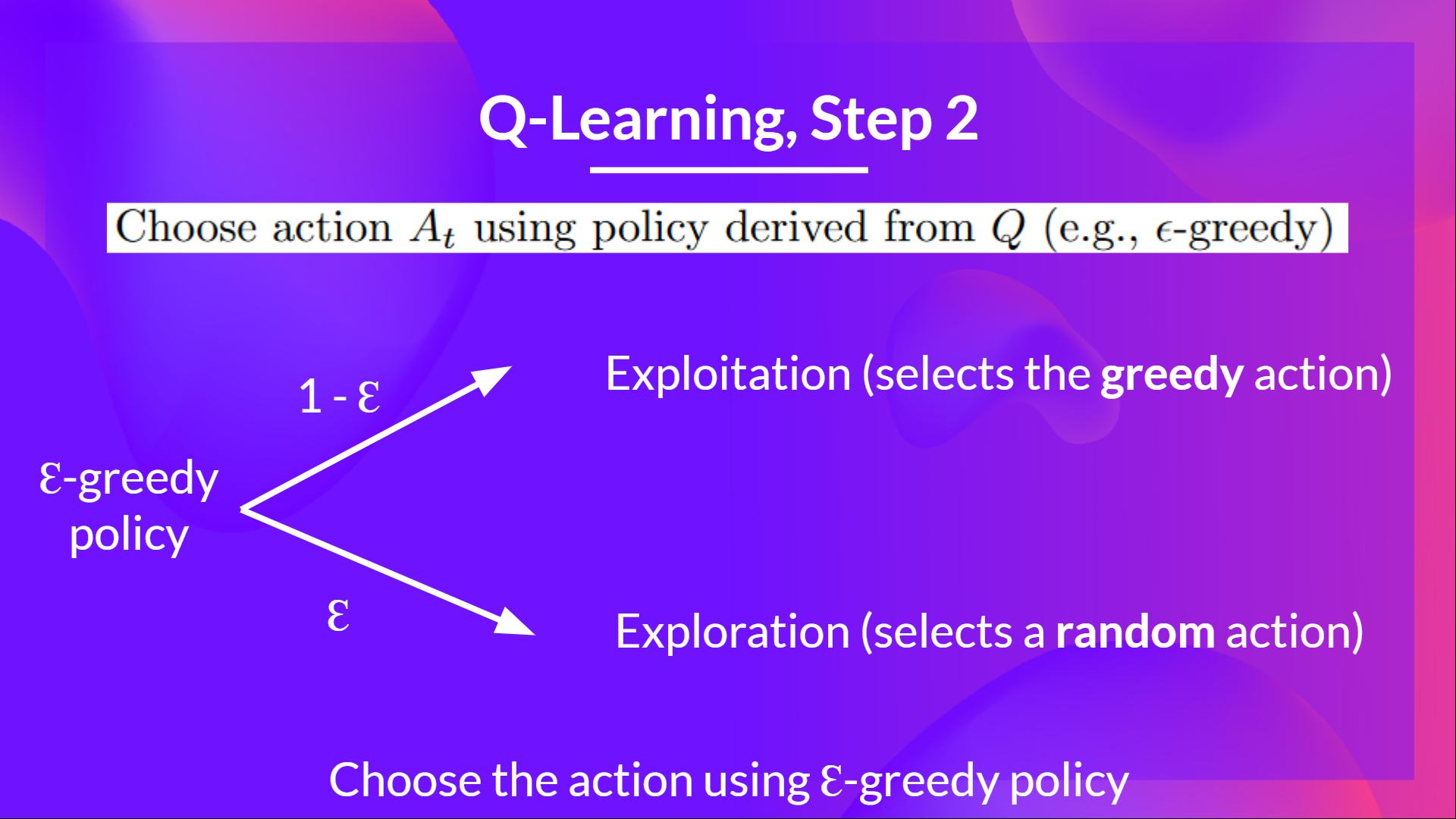
Epsilon Greedy 策略是一種處理探索/利用權衡的策略。
其思想是我們將 epsilon ɛ = 1.0
- 以 1 - ɛ 的機率:我們進行利用(即我們的代理選擇具有最高狀態-動作對值的動作)。
- 以 ɛ 的機率:我們進行探索(嘗試隨機動作)。
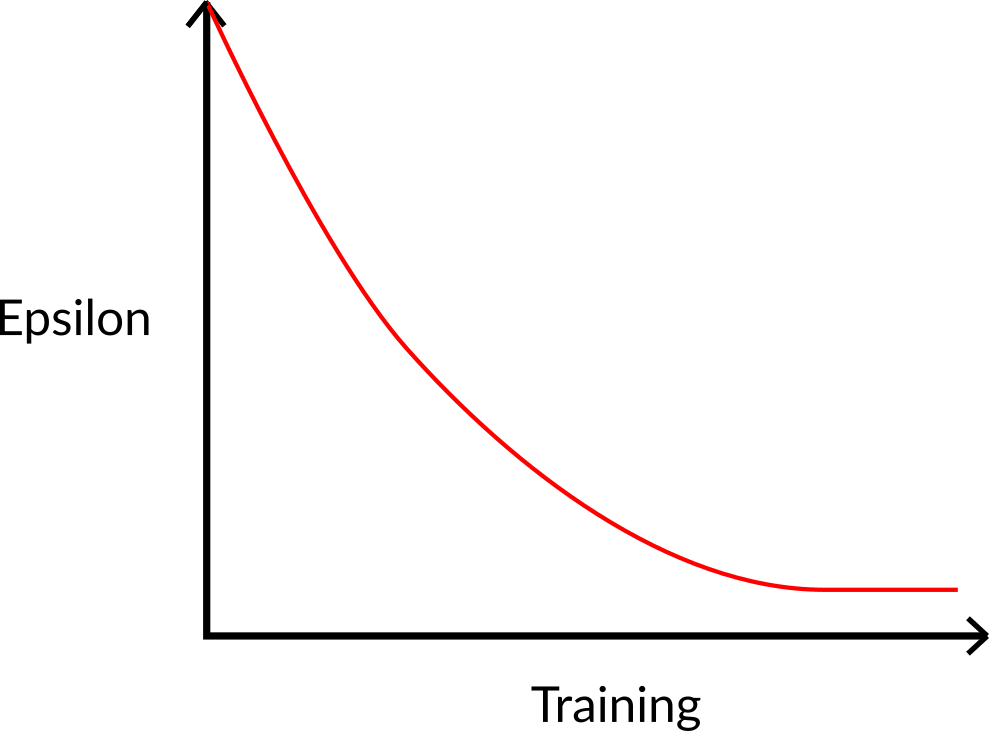
在訓練開始時,探索的機率將非常大,因為 ɛ 值很高,所以大部分時間我們都會進行探索。 但是隨著訓練的進行,我們的 Q-表在估計方面變得越來越好,我們逐漸降低 epsilon 值,因為我們需要的探索越來越少,而利用越來越多。
步驟 3:執行動作 At,得到獎勵 Rt+1 和下一個狀態 St+1

步驟 4:更新 Q(St, At)
請記住,在 TD 學習中,我們在互動的每一步後更新我們的策略或值函式(取決於我們選擇的強化學習方法)。
為了生成我們的 TD 目標,我們使用了即時獎勵 加上下一個狀態最佳狀態-動作對的折扣值(我們稱之為自舉)。
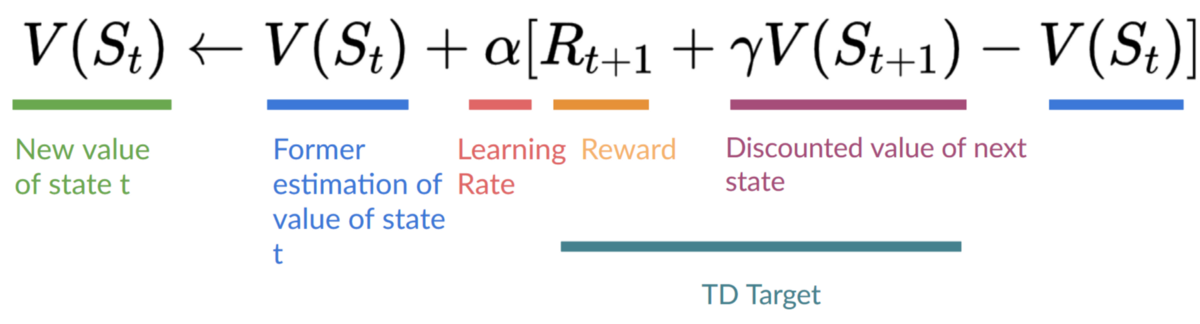
因此,我們的 更新公式如下:
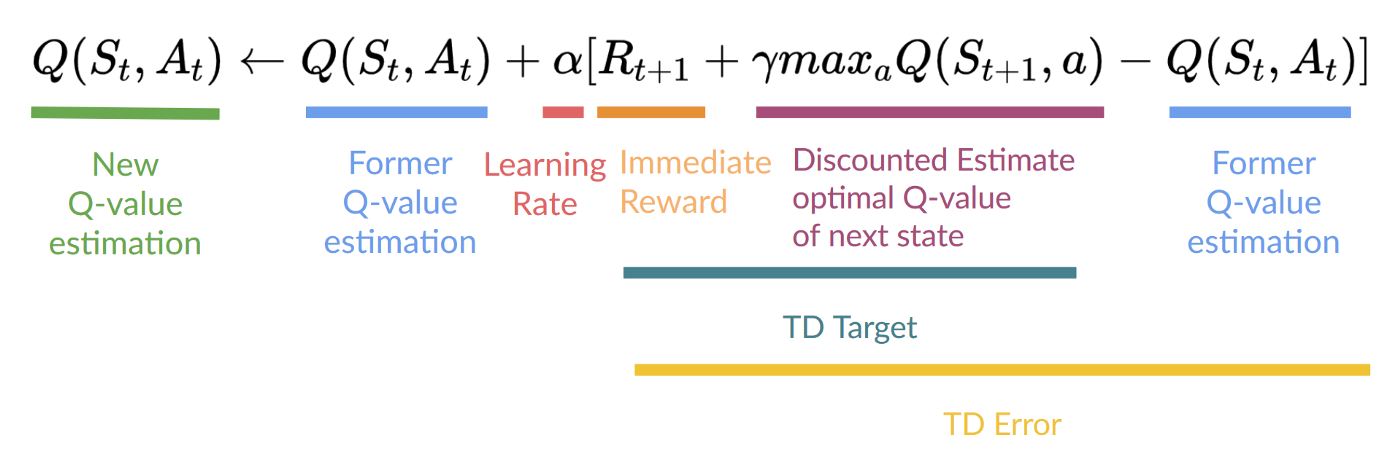
這意味著要更新我們的
- 我們需要 。
- 為了更新給定狀態-動作對的 Q 值,我們使用 TD 目標。
我們如何形成 TD 目標?
- 在執行動作 後,我們獲得了獎勵。
- 為了獲得最佳的下一個狀態-動作對值,我們使用貪婪策略來選擇下一個最佳動作。請注意,這不是 epsilon 貪婪策略,它總是選擇具有最高狀態-動作值的動作。
然後,當這個 Q 值的更新完成後。我們進入一個新狀態,並再次使用我們的 epsilon-貪婪策略選擇動作。
這就是為什麼我們說這是一種離策略演算法。
離策略 vs. 在策略
差異是微妙的
- 離策略:使用不同的策略進行行動和更新。
例如,對於 Q-Learning,Epsilon 貪婪策略(行動策略)與用於選擇最佳下一個狀態-動作值以更新我們的 Q 值(更新策略)的貪婪策略不同。
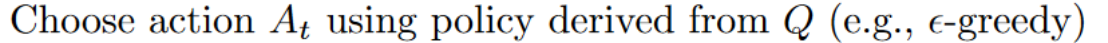
與訓練過程中使用的策略不同
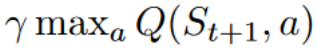
- 在策略:使用相同的策略進行行動和更新。
例如,對於另一種基於值的演算法 Sarsa,Epsilon-Greedy 策略選擇的是 next_state-action 對,而不是貪婪策略。


Q-Learning 示例
為了更好地理解 Q-Learning,我們來看一個簡單的例子

- 你是一隻迷宮裡的小老鼠。你總是從同一個起點開始。
- 目標是吃到右下角的那一大堆乳酪,並避開毒藥。畢竟,誰不喜歡乳酪呢?
- 如果吃毒藥、吃一大堆乳酪或超過五步,情節就會結束。
- 學習率為 0.1
- 伽馬(折扣率)為 0.99

- +0: 進入沒有乳酪的狀態。
- +1: 進入有少量乳酪的狀態。
- +10: 進入有大量乳酪的狀態。
- -10: 進入有毒藥的狀態,從而死亡。
- +0 如果我們花費超過五步。

為了訓練我們的代理以獲得最優策略(即向右、向右、向下移動的策略),我們將使用 Q-Learning 演算法。
步驟 1:我們初始化 Q-表

所以,現在,我們的 Q-表毫無用處;我們需要使用 Q-Learning 演算法來訓練我們的 Q-函式。
讓我們進行 2 次訓練時間步
訓練時間步 1
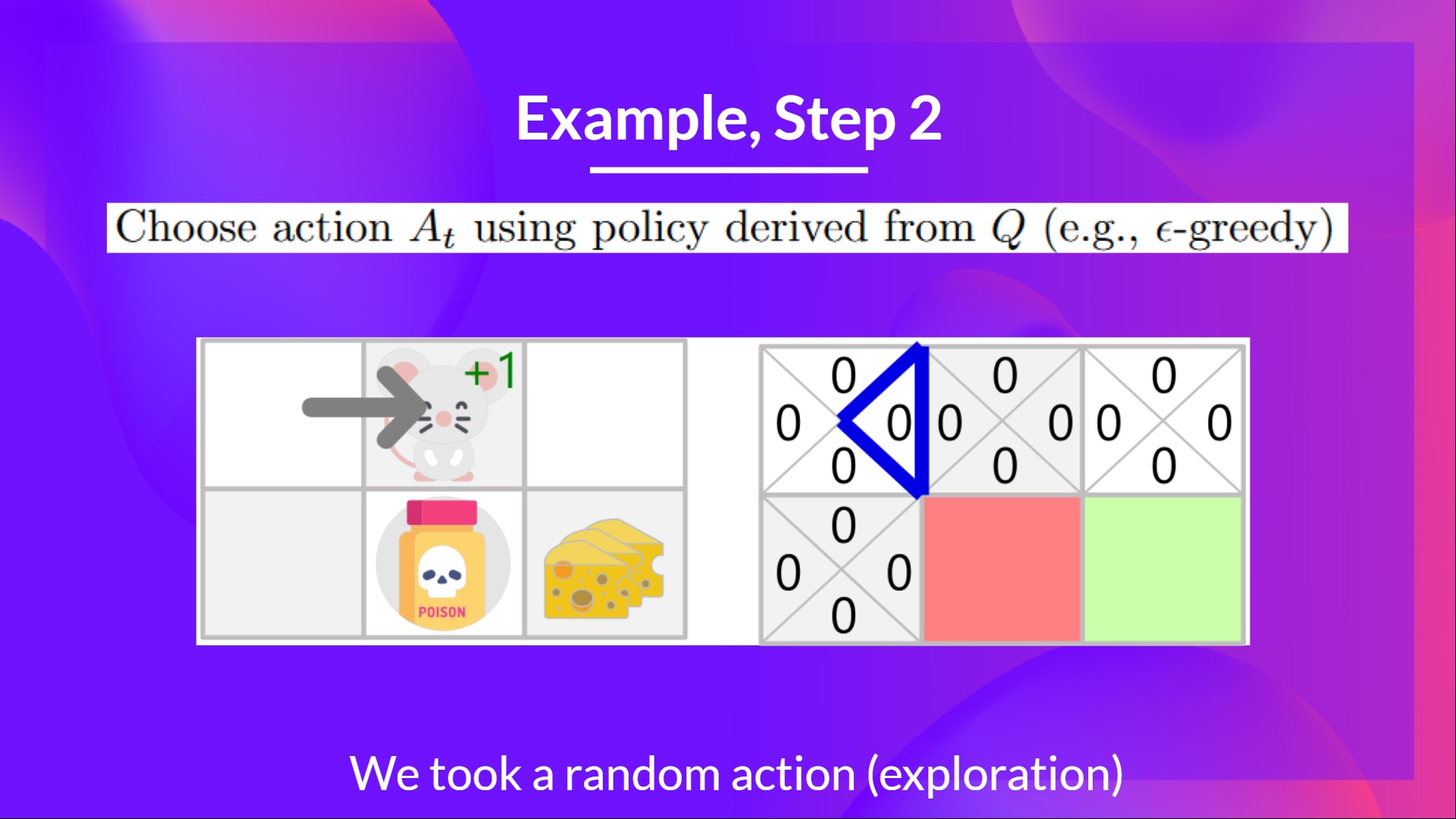
步驟 2:使用 Epsilon 貪婪策略選擇動作
因為 epsilon 很大 = 1.0,我採取一個隨機動作,在這種情況下,我向右移動。
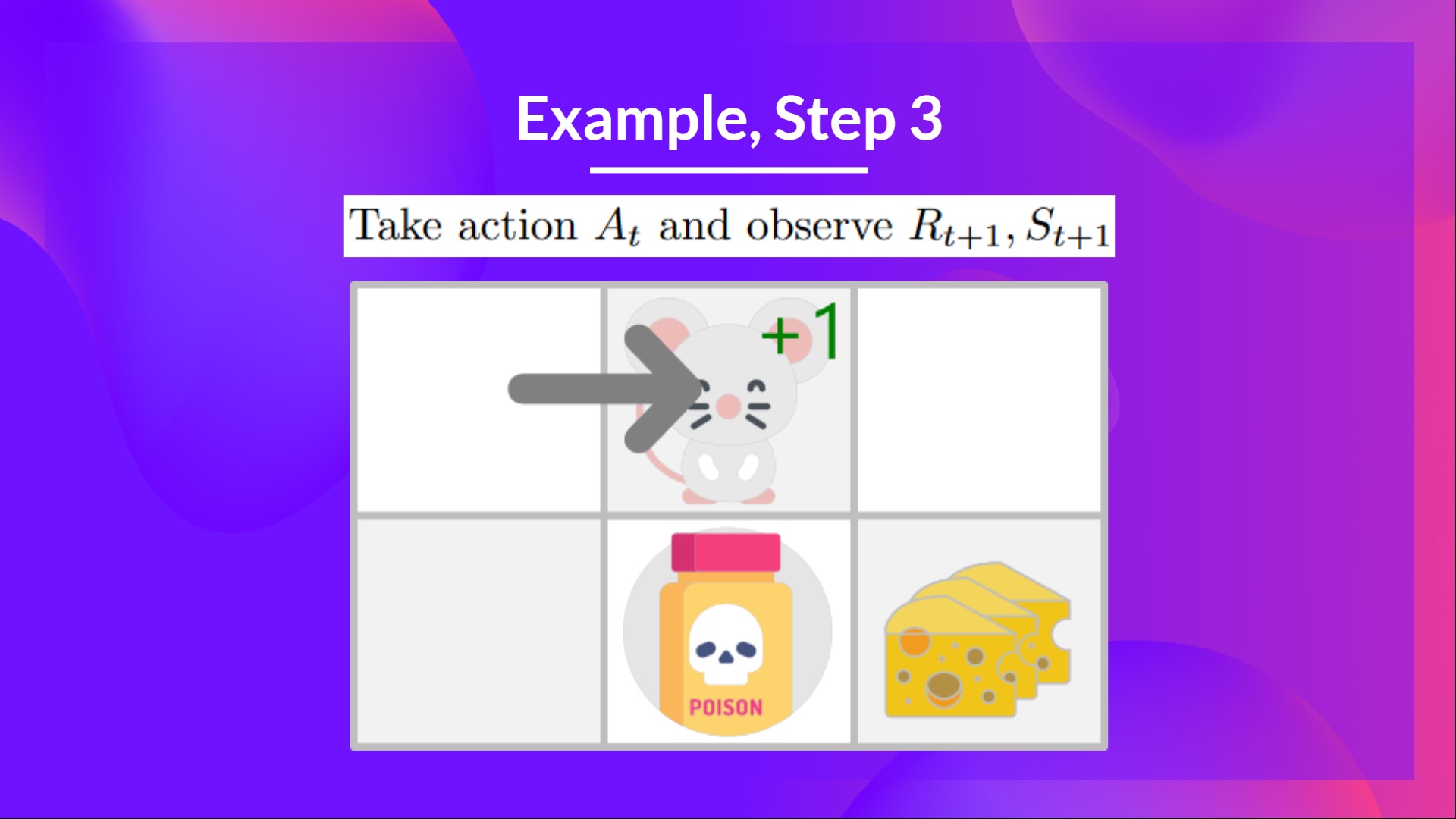
步驟 3:執行動作 At,得到 Rt+1 和 St+1
透過向右走,我得到了一小塊乳酪,所以 ,然後我進入了一個新狀態。
步驟 4:更新
我們現在可以使用我們的公式更新 。


訓練時間步 2
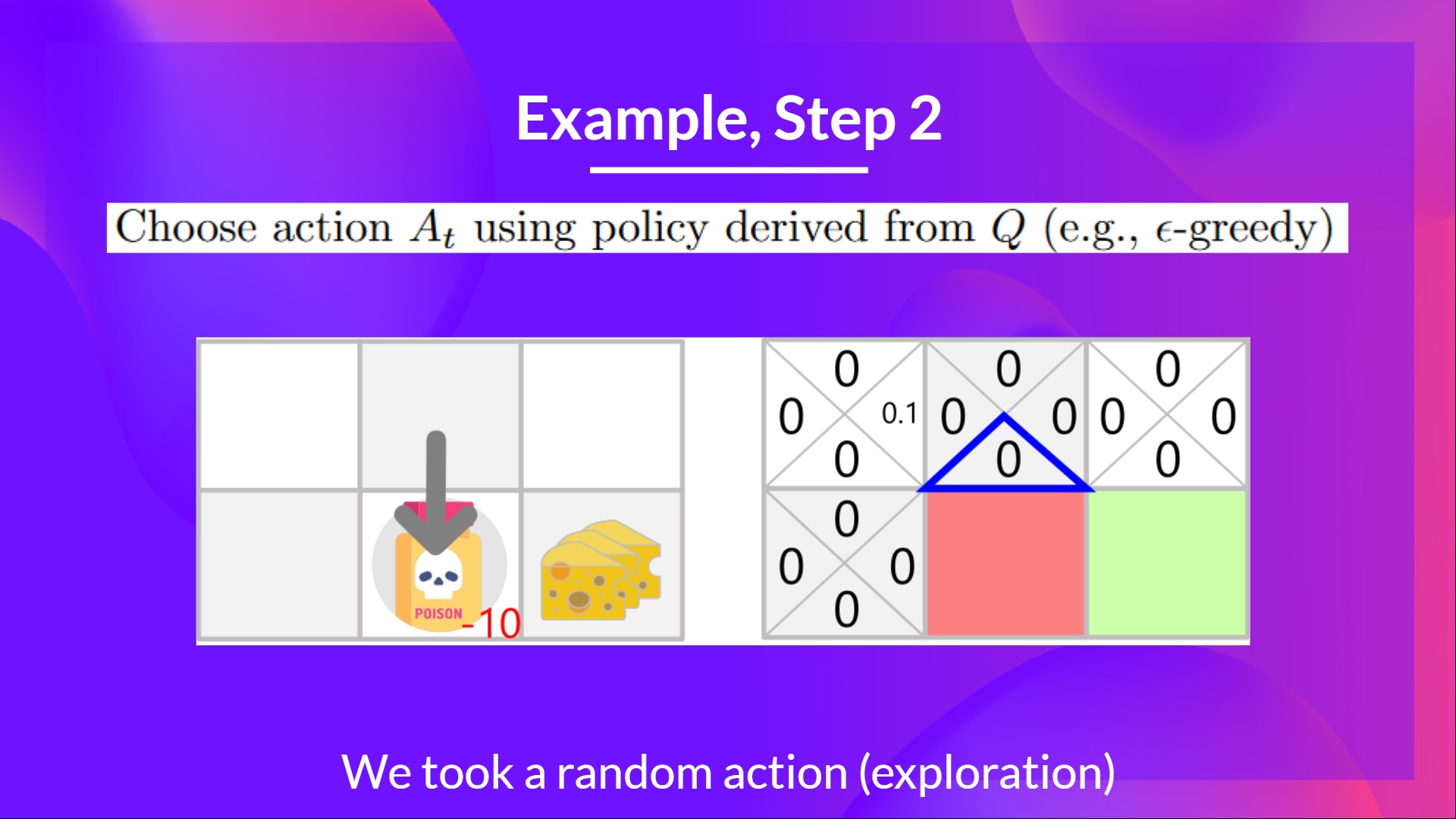
步驟 2:使用 Epsilon 貪婪策略選擇動作
我再次採取隨機動作,因為 epsilon 仍然很大,為 0.99(因為我們稍微衰減了它,隨著訓練的進行,我們希望探索越來越少)。
我採取了向下移動的動作。這不是一個好的動作,因為它把我帶到了毒藥。
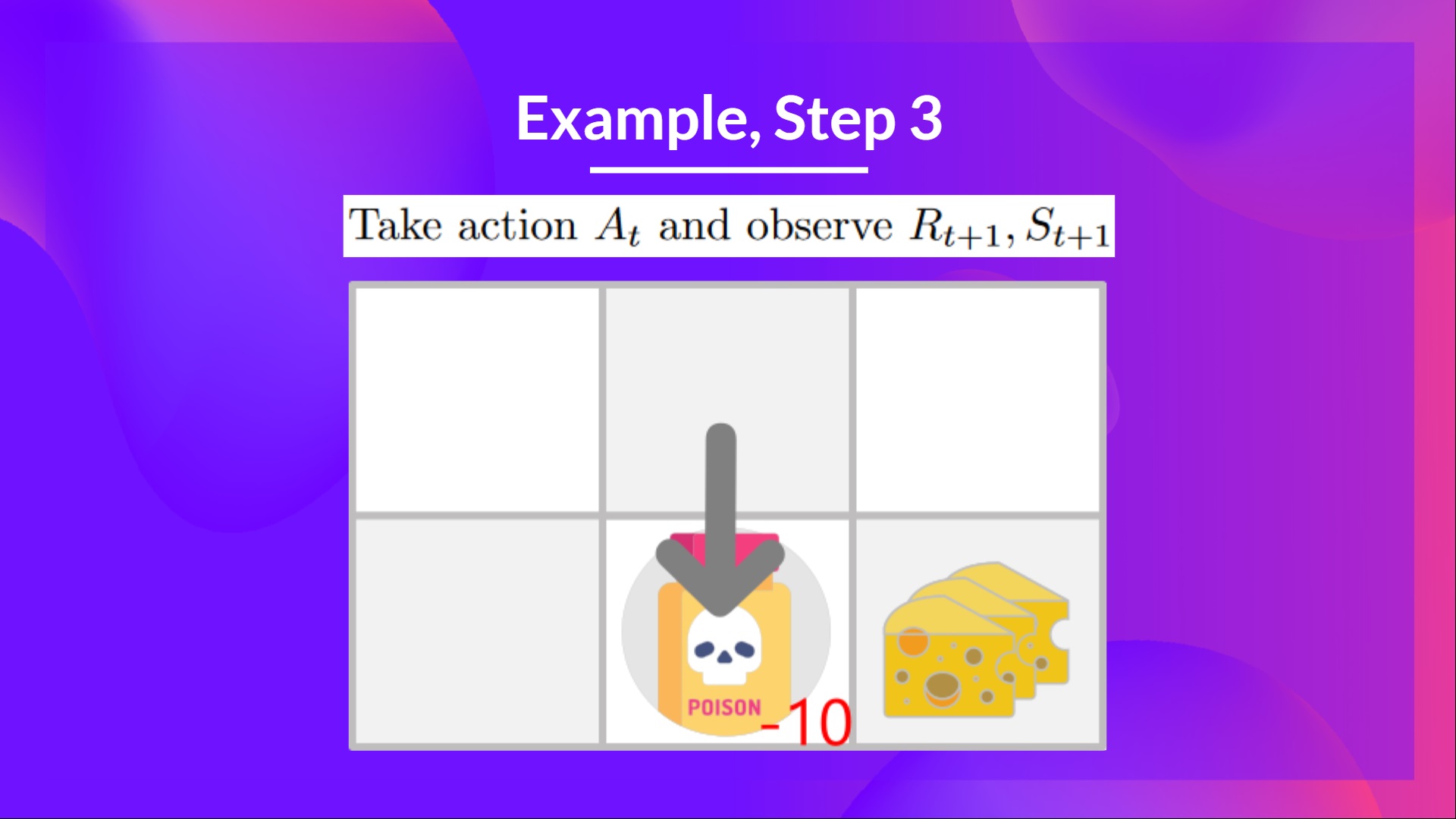
步驟 3:執行動作 At,得到 和 St+1
因為我到了毒藥狀態,我得到了 ,然後我就死了。
步驟 4:更新

因為我們死了,所以我們開始了一個新的回合。但我們在這裡看到的是,經過兩次探索步驟,我的代理變得更聰明瞭。
隨著我們繼續探索和利用環境,並使用 TD 目標更新 Q 值,Q-表將為我們提供越來越好的近似值。因此,在訓練結束時,我們將得到最優 Q-函式的估計。
現在我們已經學習了 Q-Learning 的理論,接下來讓我們從頭開始實現它。我們將訓練一個 Q-Learning 代理,並在兩個環境中對其進行訓練
- 冰凍湖 v1 ❄️(非光滑版):我們的代理需要透過只在冰凍磚塊 (F) 上行走並避開洞 (H) 來從起始狀態 (S) 到達目標狀態 (G)。
- 一輛自動計程車 🚕 將需要學習如何在城市中導航,將乘客從 A 點運送到 B 點。
在此處開始教程 👉 https://colab.research.google.com/github/huggingface/deep-rl-class/blob/main/unit2/unit2.ipynb
排行榜 👉 https://huggingface.co/spaces/chrisjay/Deep-Reinforcement-Learning-Leaderboard
恭喜您完成本章!其中包含大量資訊。也恭喜您完成了所有教程。您剛剛從頭開始實現了您的第一個強化學習代理並將其分享到 Hub 上 🥳。
在學習新架構時,從頭開始實現對於理解其工作原理至關重要。
如果所有這些元素讓你**仍然感到困惑**,那是**正常現象**。**我和所有學習強化學習的人都經歷過同樣的感覺。**
花時間真正掌握這些材料,然後再繼續。
因為學習和避免能力錯覺的最佳方法是測試自己。我們編寫了一個測驗來幫助您找到需要加強學習的地方。在此處檢查您的知識 👉 https://github.com/huggingface/deep-rl-class/blob/main/unit2/quiz2.md
掌握這些要素並打下堅實的基礎對於進入有趣的部分至關重要。請毫不猶豫地修改實現,嘗試改進它並更改環境,學習的最佳方式是自己嘗試!
如果您想深入瞭解,我們在教學大綱中釋出了其他閱讀材料 👉 https://github.com/huggingface/deep-rl-class/blob/main/unit2/README.md
別忘了分享給你想學習的朋友 🤗!
最後,我們希望**根據你的反饋不斷改進和更新課程**。如果你有任何反饋,請填寫此表格 👉 https://forms.gle/3HgA7bEHwAmmLfwh9

