深度強化學習簡介








Hugging Face 深度強化學習課程的第 1 章 🤗
⚠️ **本文的更新版本在此處提供** 👉 https://huggingface.co/deep-rl-course/unit1/introduction
本文是深度強化學習課程的一部分。這是一個從入門到精通的免費課程。請在此處檢視課程大綱 here.

⚠️ **本文的更新版本在此處提供** 👉 https://huggingface.co/deep-rl-course/unit1/introduction
本文是深度強化學習課程的一部分。這是一個從入門到精通的免費課程。請在此處檢視課程大綱 here.
歡迎來到人工智慧最引人入勝的主題:**深度強化學習。**
深度強化學習是一種機器學習型別,其中代理透過**執行動作**並**觀察結果**來學習在環境中**如何行動**。
自 2013 年的《深度 Q-學習》論文以來,我們已經看到了許多突破。從 OpenAI 在 Dota2 中擊敗世界上一些最佳玩家的 Five,到 靈巧專案,我們**正處於深度強化學習研究的激動人心的時刻。**

此外,自 2018 年以來,**你現在可以訪問如此多出色的環境和庫來構建你的代理。**
這就是現在是開始學習的最佳時機的原因,透過本課程,**你來對了地方。**
是的,因為本文是深度強化學習課程的第一單元,這是一個**從初學者到專家免費的課程**,你將學習理論並使用著名的深度強化學習庫,如 Stable Baselines3、RL Baselines3 Zoo 和 RLlib。
在這門免費課程中,你將:
- 📖 **理論與實踐**地學習深度強化學習。
- 🧑💻 學習**使用著名的深度強化學習庫**,如 Stable Baselines3、RL Baselines3 Zoo 和 RLlib。
- 🤖 在**獨特環境**中訓練代理,如 SnowballFight、Huggy the Doggo 🐶,以及經典環境,如 Space Invaders 和 PyBullet。
- 💾 **一行程式碼**將訓練好的代理釋出到 Hub。也可以從社群下載強大的代理。
- 🏆 **參與挑戰**,你將在其中評估你的代理與其他團隊的表現。
- 🖌️🎨 學習**分享你使用 Unity 和 Godot 製作的環境**。
所以在這個第一單元中,**你將學習深度強化學習的基礎知識。**然後,你將訓練你的第一個著陸器代理**正確地降落在月球🌕並將其上傳到 Hugging Face Hub,這是一個免費的開放平臺,人們可以在其中共享機器學習模型、資料集和演示。**
在深入實施深度強化學習代理之前,**掌握這些要素**至關重要。本章的目標是為你打下堅實的基礎。
如果你願意,可以觀看本章的 📹 影片版本
那麼,我們開始吧!🚀
**什麼是強化學習?**
要理解強化學習,我們先從大局著眼。
**概述**
強化學習的思想是,**代理(AI)將透過與環境互動(透過試錯)並接收獎勵(負面或正面)作為執行動作的反饋來學習。**
透過與環境互動學習**源於我們的自然經驗。**
例如,想象一下,把你的小弟弟放在一個他從未玩過的影片遊戲面前,手裡拿著控制器,然後讓他一個人玩。

你的弟弟將透過按下正確的按鈕(動作)與環境(影片遊戲)互動。他得到一個硬幣,那是 +1 獎勵。這是積極的,他剛剛明白在這個遊戲中**他必須獲得硬幣。**
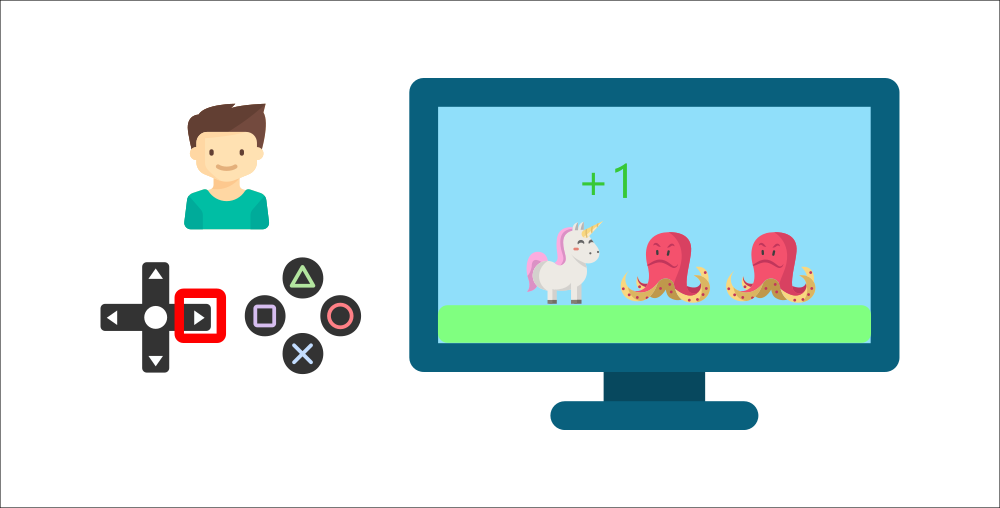
但接著,**他又按下了右鍵**,他碰到了一個敵人,他剛死了 -1 獎勵。
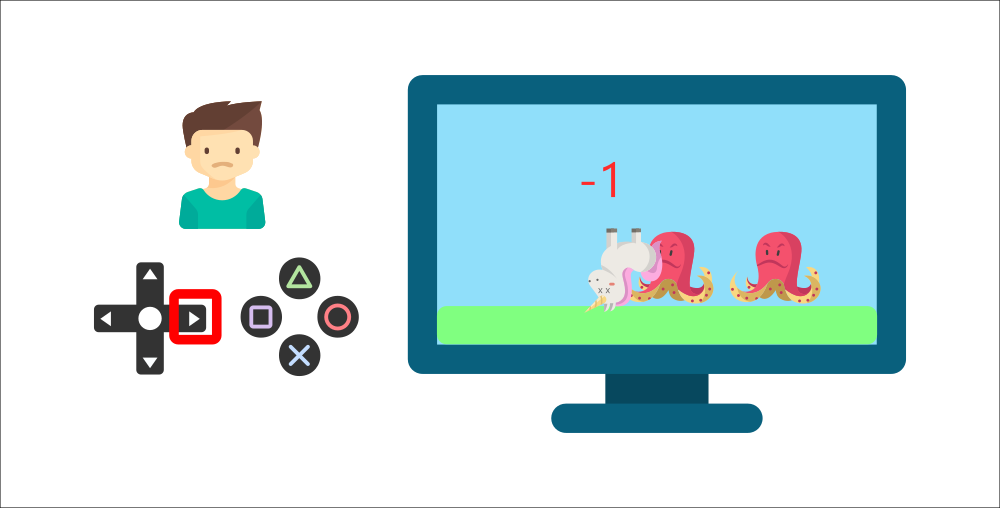
透過與環境的試錯互動,你的小弟弟明白**他需要在這個環境中獲取硬幣,但要避開敵人。**
**在沒有任何監督的情況下**,這個孩子會越來越擅長玩這個遊戲。
這就是人類和動物的學習方式,**透過互動。**強化學習只是一種**透過行動學習的計算方法。**
**正式定義**
現在我們來看一個正式定義
強化學習是一種解決控制任務(也稱為決策問題)的框架,透過構建代理,使其透過試錯與環境互動並接收獎勵(正面或負面)作為唯一反饋來學習。
⇒ 那麼強化學習是如何工作的呢?
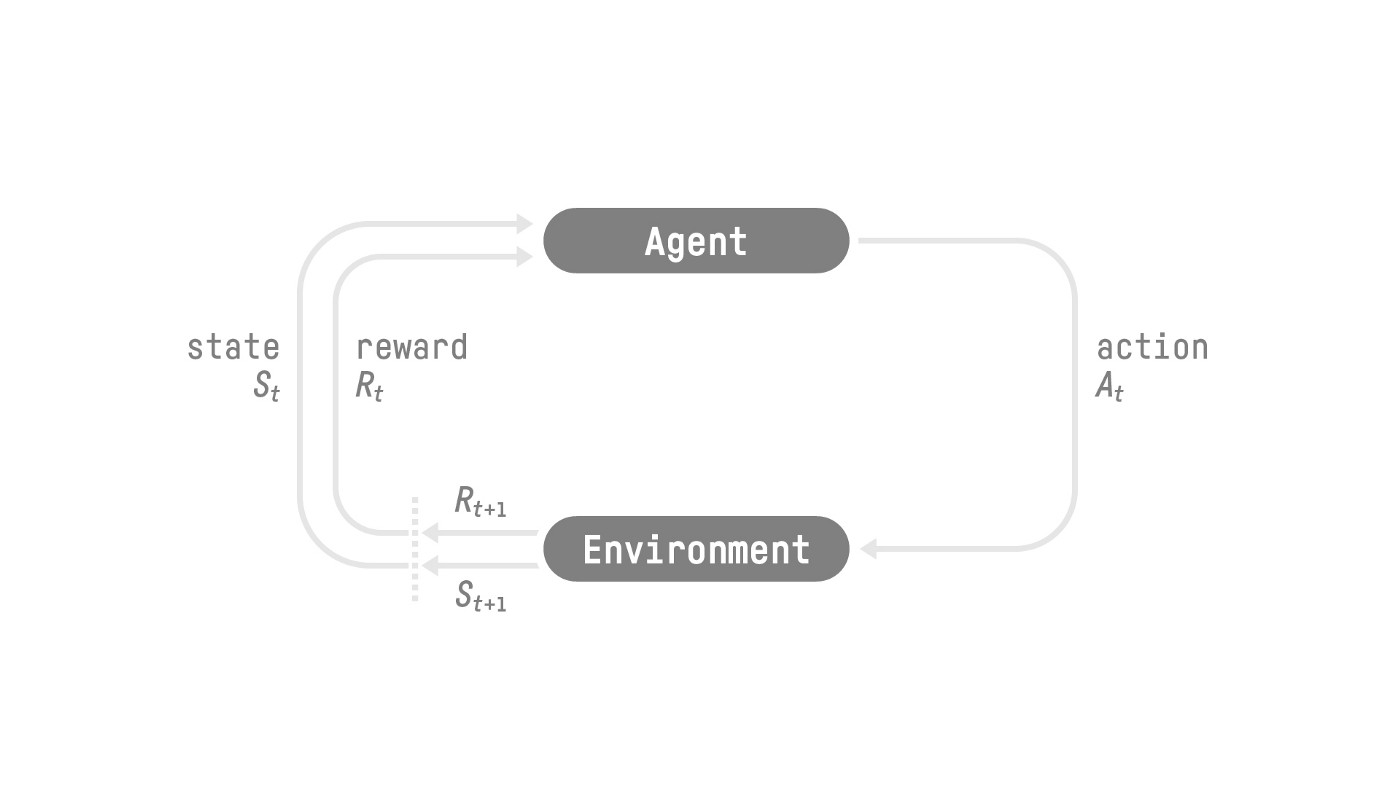
**強化學習框架**
**強化學習過程**
為了理解強化學習過程,讓我們想象一個代理正在學習翫一個平臺遊戲
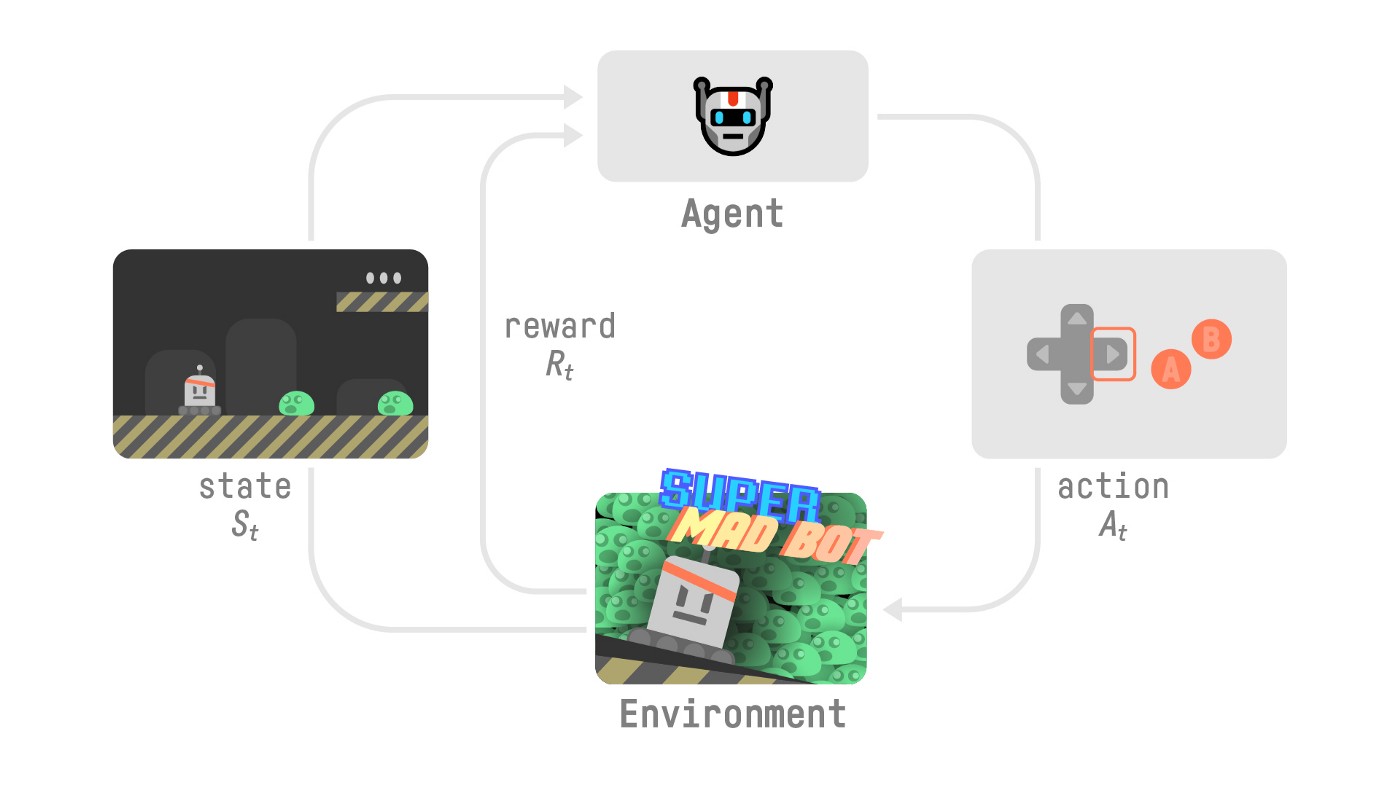
- 我們的代理從**環境**中接收到**狀態 **——我們收到遊戲(環境)的第一幀。
- 根據該**狀態 ,**代理執行**動作 **——我們的代理將向右移動。
- 環境進入一個**新的狀態 **——新的一幀。
- 環境給代理一些**獎勵 **——我們沒有死(*正面獎勵 +1*)。
這個強化學習迴圈輸出一個**狀態、動作、獎勵和下一個狀態**的序列。
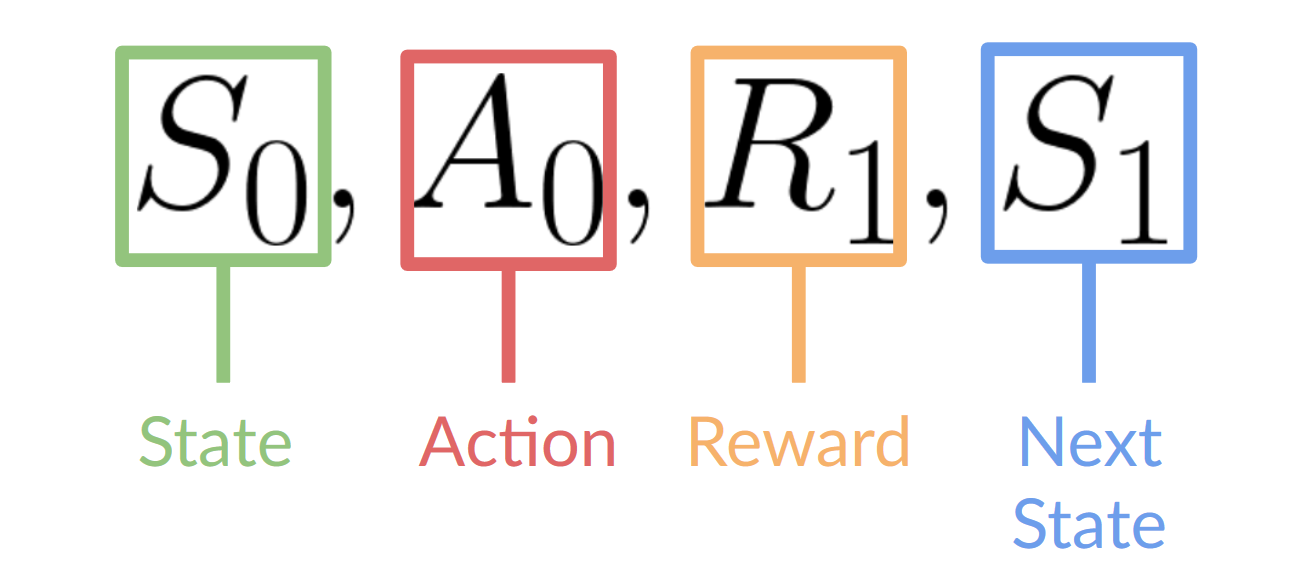
代理的目標是最大化其累積獎勵,**稱為預期回報。**
**獎勵假設:強化學習的核心思想**
⇒ 為什麼代理的目標是最大化預期回報?
因為強化學習基於**獎勵假設**,即所有目標都可以描述為**最大化預期回報**(預期累積獎勵)。
這就是為什麼在強化學習中,**為了獲得最佳行為,**我們需要**最大化預期累積獎勵。**
**馬爾可夫性質**
在論文中,你會看到強化學習過程被稱為**馬爾可夫決策過程**(MDP)。
我們將在後續單元中再次討論馬爾可夫性質。但如果你今天需要記住一些關於它的東西,馬爾可夫性質意味著我們的代理**只需要當前狀態來決定**採取什麼動作,而**不需要之前的所有狀態和動作的歷史記錄**。
**觀測/狀態空間**
觀測/狀態是**代理從環境中獲取的資訊**。在影片遊戲的情況下,它可以是一幀(截圖)。在交易代理的情況下,它可以是某種股票的價值等。
觀察和狀態之間有一個區別
- 狀態 s:是對**世界狀態的完整描述**(沒有隱藏資訊)。在完全可觀測的環境中。

在國際象棋遊戲中,我們從環境中接收到一個狀態,因為我們可以訪問整個棋盤資訊。
在國際象棋遊戲中,我們處於一個完全可觀測的環境中,因為我們可以訪問整個棋盤資訊。
- 觀測 o:是**狀態的部分描述**。在部分可觀測的環境中。

在《超級馬里奧兄弟》中,我們只能看到靠近玩家的部分關卡,所以我們收到一個觀測。
在《超級馬里奧兄弟》中,我們處於一個部分可觀測的環境中。我們收到一個觀測,**因為我們只能看到關卡的一部分。**
實際上,在本課程中我們使用“狀態”一詞,但在實現中我們將進行區分。
總結一下

動作空間
動作空間是**環境中所有可能動作的集合。**
動作可以來自*離散*或*連續空間*
- 離散空間:可能的動作數量是**有限的**。
在《超級馬里奧兄弟》中,我們的動作集是有限的,因為我們只有 4 個方向和跳躍。
- 連續空間:可能的動作數量是**無限的**。

自動駕駛汽車代理有無限多的可能動作,因為它可以左轉 20°、21.1°、21.2°、按喇叭、右轉 20°……
總結一下

考慮這些資訊至關重要,因為它將在**將來選擇強化學習演算法時具有重要意義。**
**獎勵與折扣**
獎勵在強化學習中至關重要,因為它是代理的**唯一反饋**。多虧了它,我們的代理才知道**所採取的行動是否正確。**
每個時間步 t 的累積獎勵可以寫成
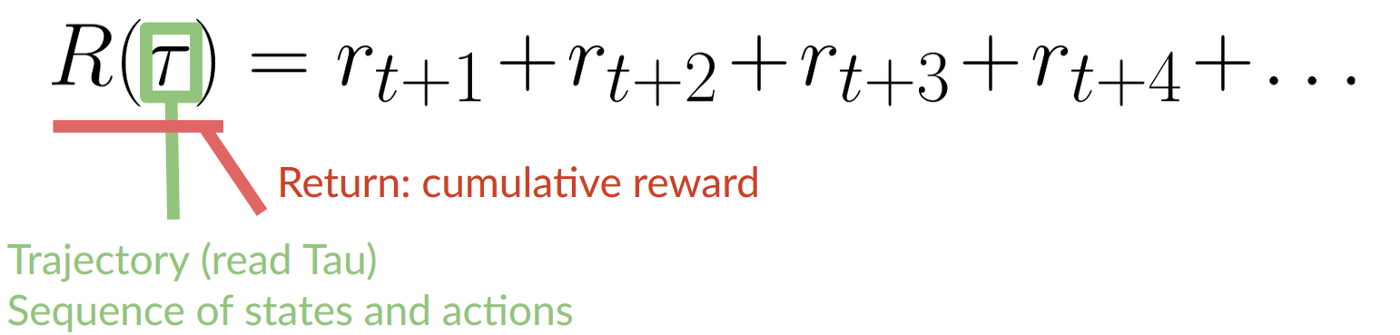
這相當於
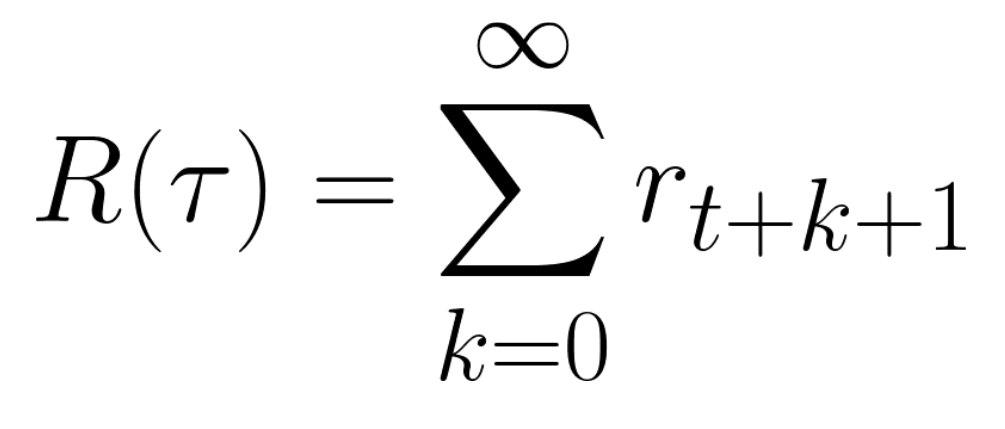
然而,實際上,**我們不能就這樣把它們加起來。**較早(遊戲開始時)的獎勵**更有可能發生**,因為它們比長期未來的獎勵更可預測。
假設你的代理是這隻小老鼠,它每個時間步可以移動一格,你的對手是貓(它也可以移動)。你的目標是**在被貓吃掉之前吃到最大量的乳酪。**

正如我們在圖中所見,**吃到我們附近的乳酪比吃到靠近貓的乳酪更有可能**(我們離貓越近,就越危險)。
因此,**靠近貓的獎勵,即使它更大(更多的乳酪),也會被更多地折扣**,因為我們不確定能否吃到它。
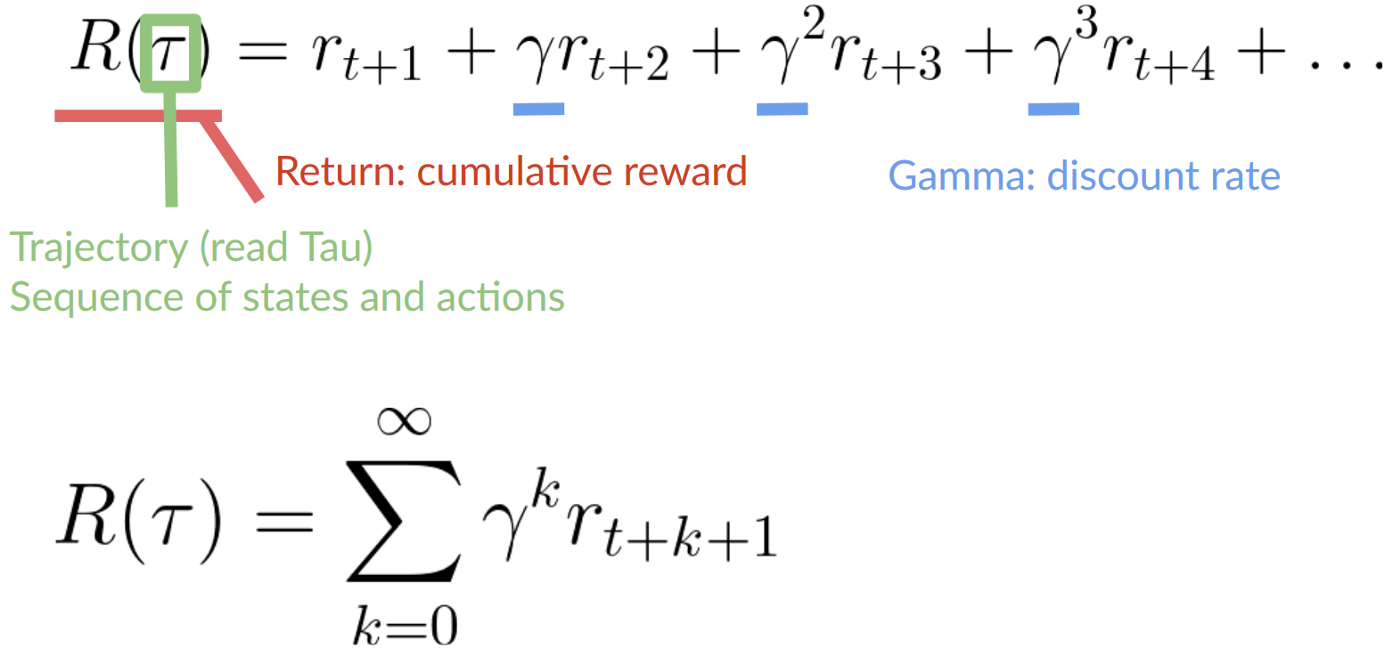
要**折扣獎勵**,我們這樣做
- 我們定義一個稱為伽馬的折扣率。**它必須在 0 到 1 之間。**大多數情況下在 **0.99 和 0.95** 之間。
伽馬值越大,折扣越小。這意味著我們的代理**更關心長期獎勵。**
另一方面,伽馬值越小,折扣越大。這意味著我們的代理**更關心短期獎勵(最近的乳酪)。**
2. 然後,每個獎勵將以時間步數的指數對伽馬進行折扣。隨著時間步的增加,貓離我們越來越近,**所以未來的獎勵發生的可能性越來越小。**
我們**折扣後的累積預期獎勵**是
任務型別
任務是強化學習問題的**一個例項**。我們可以有兩種型別的任務:情節性和連續性。
情節性任務
在這種情況下,我們有一個起點和終點(**一個終點狀態**)。**這構成一個回合**:一個由狀態、動作、獎勵和新狀態組成的列表。
例如,想想《超級馬里奧兄弟》:一個回合從啟動一個新的馬里奧關卡開始,並**在你被殺死或到達關卡末尾時結束。**
連續性任務
這些任務將永遠持續下去(沒有終止狀態)。在這種情況下,代理必須**學習如何選擇最佳動作並同時與環境互動。**
例如,一個進行自動化股票交易的代理。對於這個任務,沒有起點和終點狀態。**代理將一直執行,直到我們決定停止它們。**
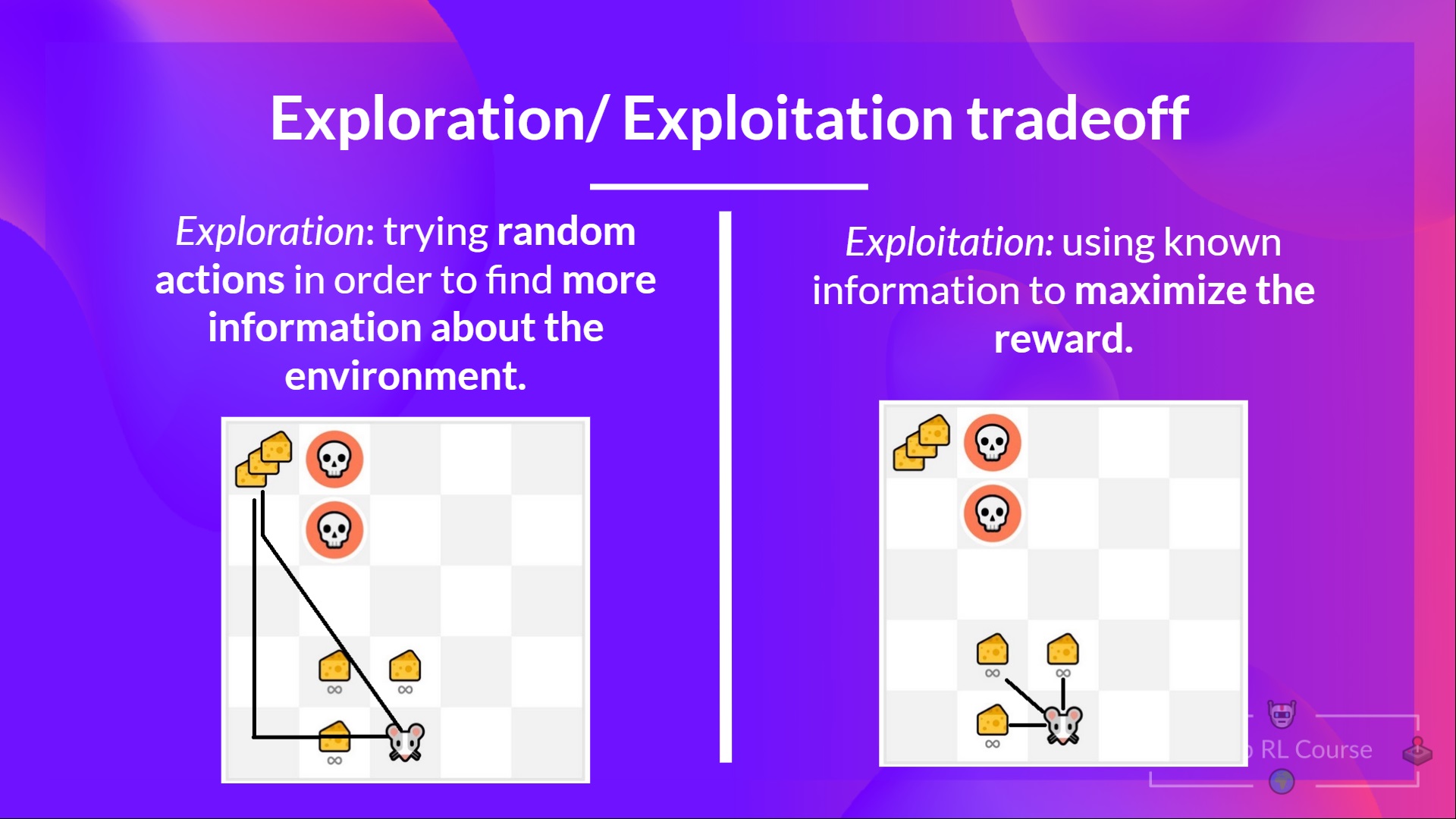
**探索/利用權衡**
最後,在研究解決強化學習問題的不同方法之前,我們必須涵蓋一個非常重要的話題:*探索/利用權衡。*
探索是指透過嘗試隨機動作來探索環境,以**發現更多關於環境的資訊。**
利用是指**利用已知資訊來最大化獎勵。**
請記住,我們強化學習代理的目標是最大化預期累積獎勵。然而,**我們可能會陷入一個常見的陷阱。**
舉個例子
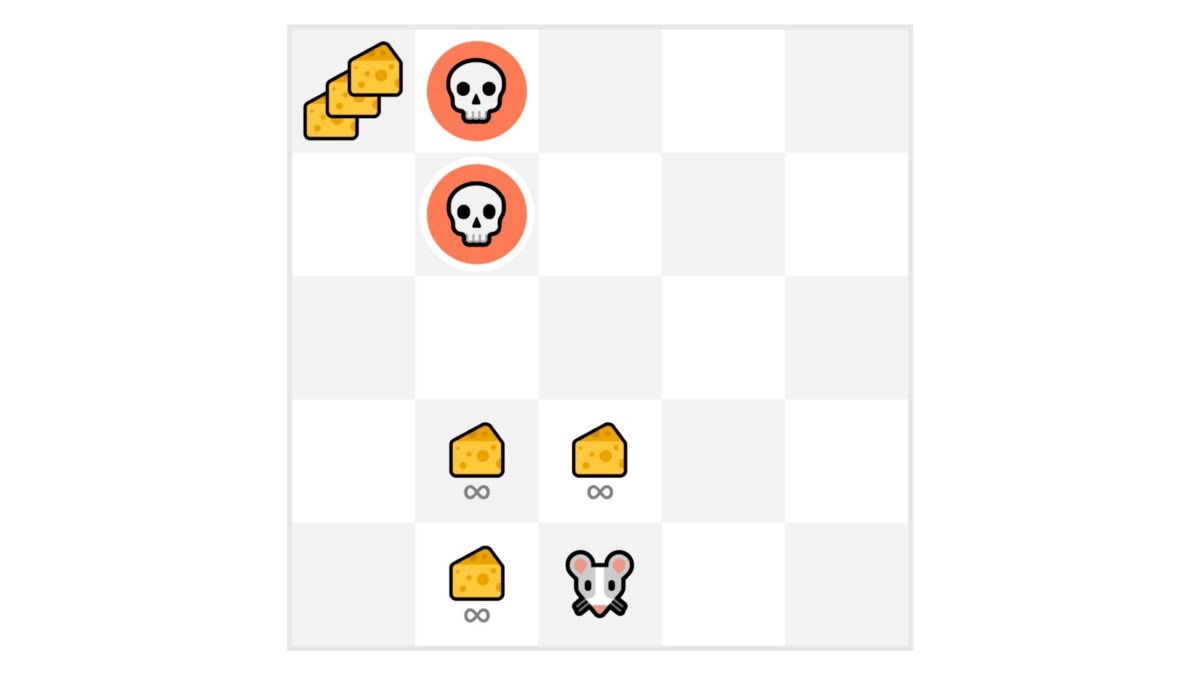
在這個遊戲中,我們的老鼠可以吃到**無限量的小塊乳酪**(每塊+1)。但在迷宮的頂部,有巨量的乳酪(+1000)。
然而,如果我們只關注利用,我們的代理將永遠無法達到巨量的乳酪。相反,它只會利用**最近的獎勵來源**,即使這個來源很小(利用)。
但是如果我們的代理進行一些探索,它就可以**發現巨大的獎勵**(那堆大乳酪)。
這就是我們所說的**探索/利用權衡**。我們需要平衡**探索環境**的程度和**利用我們所瞭解的環境**的程度。
因此,我們必須**定義一個規則來處理這種權衡**。我們將在未來的章節中看到不同的處理方法。
如果仍然感到困惑,**請思考一個實際問題:選擇一家餐廳:**
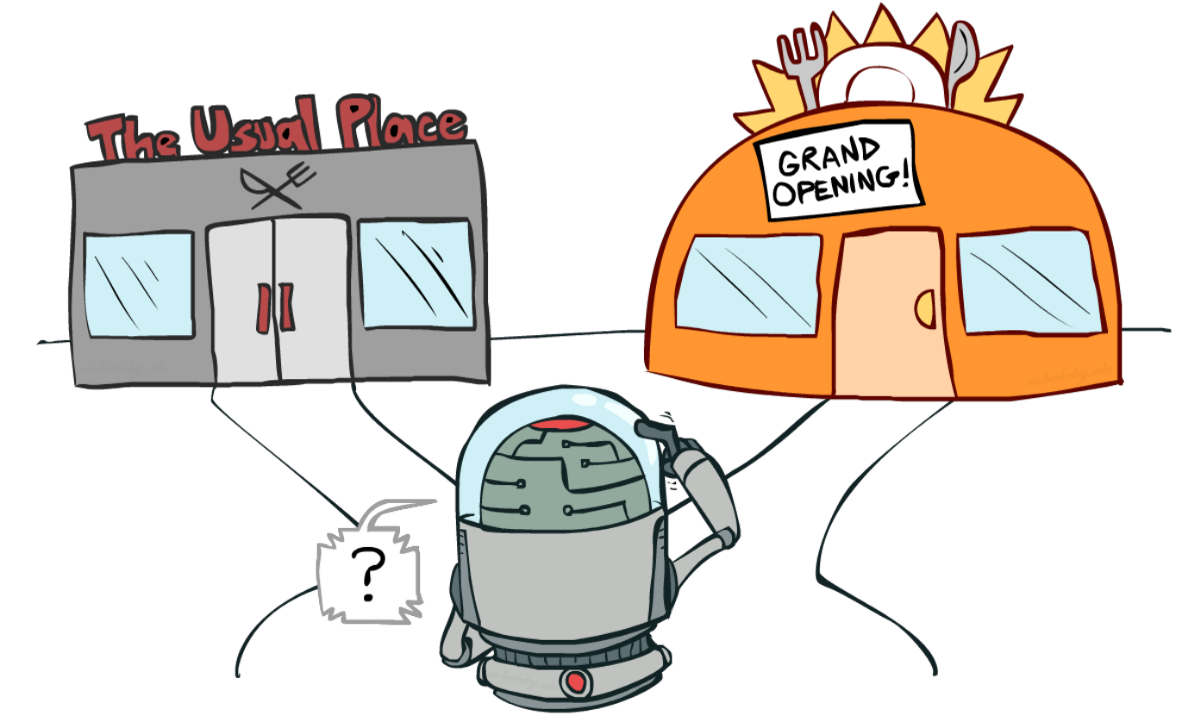
- 利用:你每天都去你熟悉的同一家餐廳,**承擔錯過另一家更好餐廳的風險。**
- 探索:嘗試你從未去過的餐廳,有不好的體驗的風險,**但有極好體驗的可能機會。**
總結一下
**解決強化學習問題的兩種主要方法**
⇒ 現在我們瞭解了強化學習框架,如何解決強化學習問題呢?
換句話說,如何構建一個能**選擇能最大化其預期累積獎勵的動作**的強化學習代理?
**策略 π:代理的大腦**
策略**π**是**代理的大腦**,它是一個函式,告訴我們**在給定當前狀態下應該採取什麼行動。**因此,它**定義了代理在給定時間點的行為**。
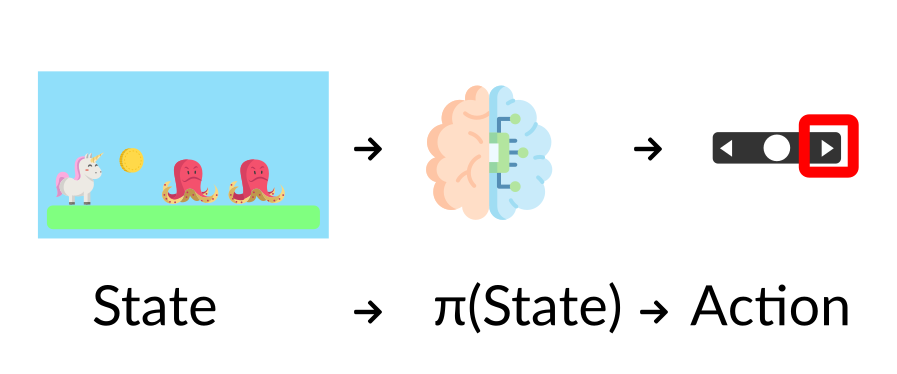
將策略視為我們代理的大腦,該函式會告訴我們給定狀態下要採取的動作
此策略**是我們想要學習的函式**,我們的目標是找到最優策略**π**,即當代理根據該策略行動時,**能最大化預期回報的策略。我們透過訓練找到這個**π**。
訓練我們的代理找到這個最優策略 π* 有兩種方法
- **直接**教代理學習在給定狀態下**採取什麼動作**:**基於策略的方法。**
- **間接**地教代理學習**哪些狀態更有價值**,然後採取**導致更有價值狀態的動作**:基於價值的方法。
**基於策略的方法**
在基於策略的方法中,**我們直接學習一個策略函式。**
此函式將每個狀態對映到該狀態下最佳的相應動作。**或者在該狀態下可能動作集上的機率分佈。**
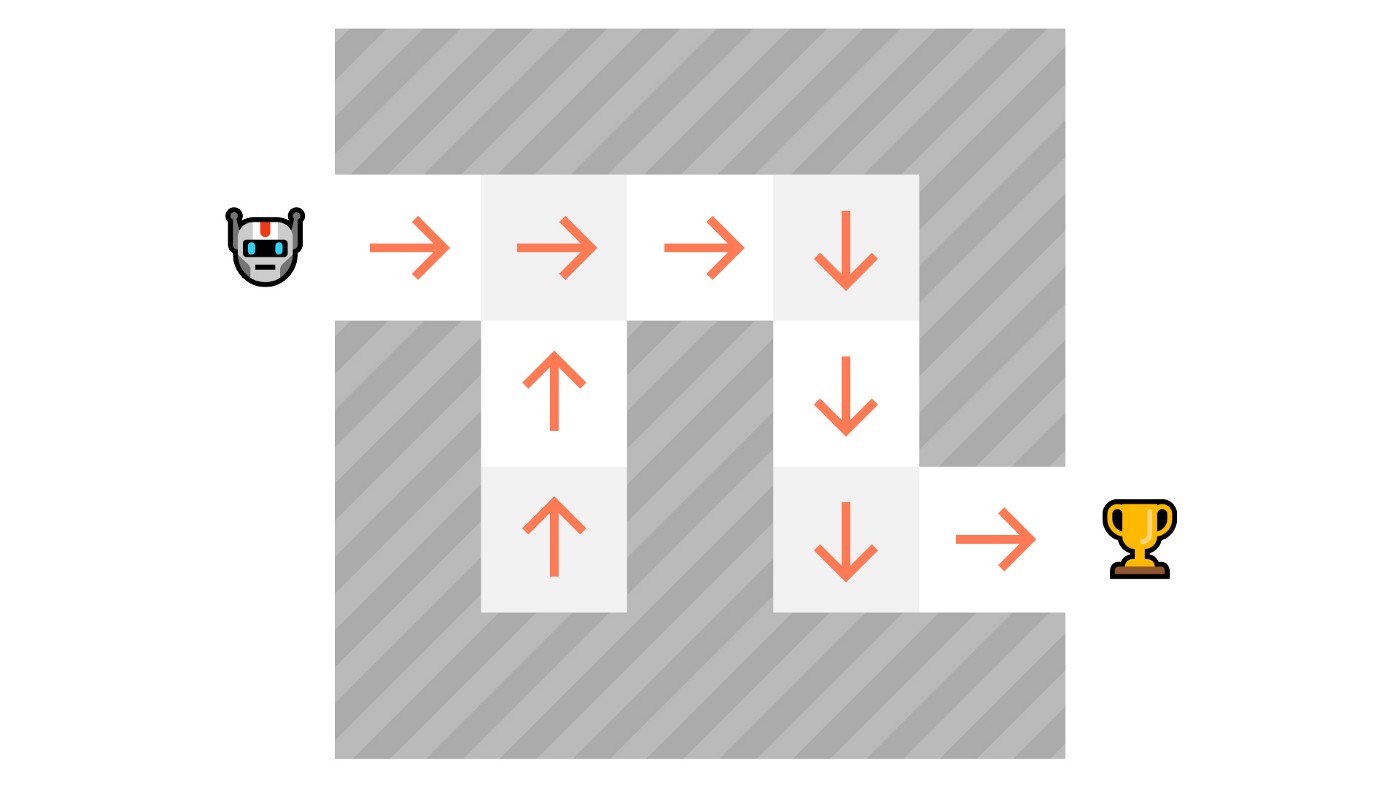
我們有兩種策略型別
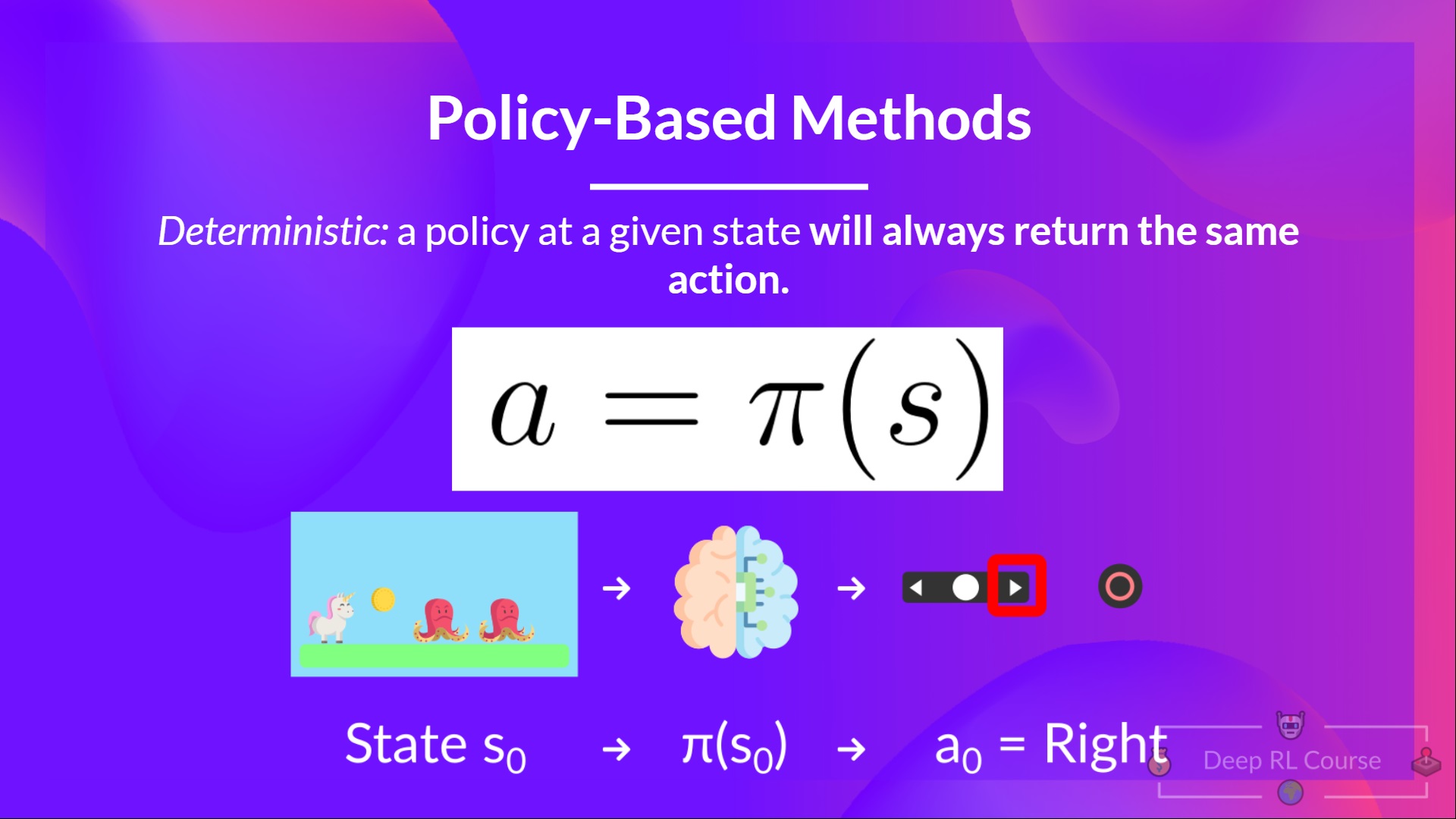
- 確定性:給定狀態下的策略**總是返回相同的動作。**
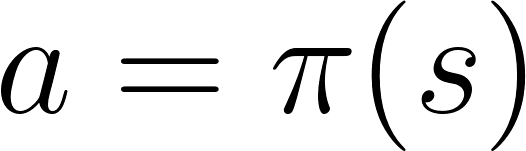
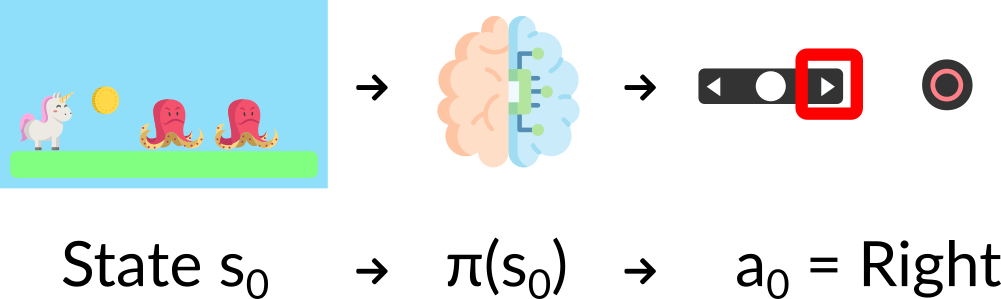
- 隨機性:輸出**動作上的機率分佈。**

總結一下

**基於價值的方法**
在基於價值的方法中,我們不是訓練一個策略函式,而是**訓練一個價值函式**,該函式將狀態對映到**處於該狀態的預期價值。**
一個狀態的價值是代理在**從該狀態開始並按照我們的策略行動**時可以獲得的**預期折扣回報**。
“根據我們的策略行動”只是指我們的策略是“**走向價值最高的州**”。
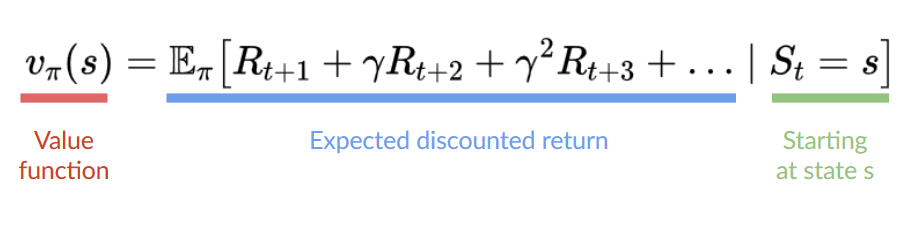
這裡我們看到我們的價值函式**為每個可能的狀態定義了價值。**

多虧了我們的價值函式,我們的策略每一步都會選擇價值函式定義的價值最大的狀態:-7,然後是-6,然後是-5(依此類推),以達到目標。
總結一下


**強化學習中的“深度”**
⇒ 到目前為止我們談論的是強化學習。但“深度”又從何而來呢?
深度強化學習引入了**深度神經網路來解決強化學習問題**——因此得名“深度”。
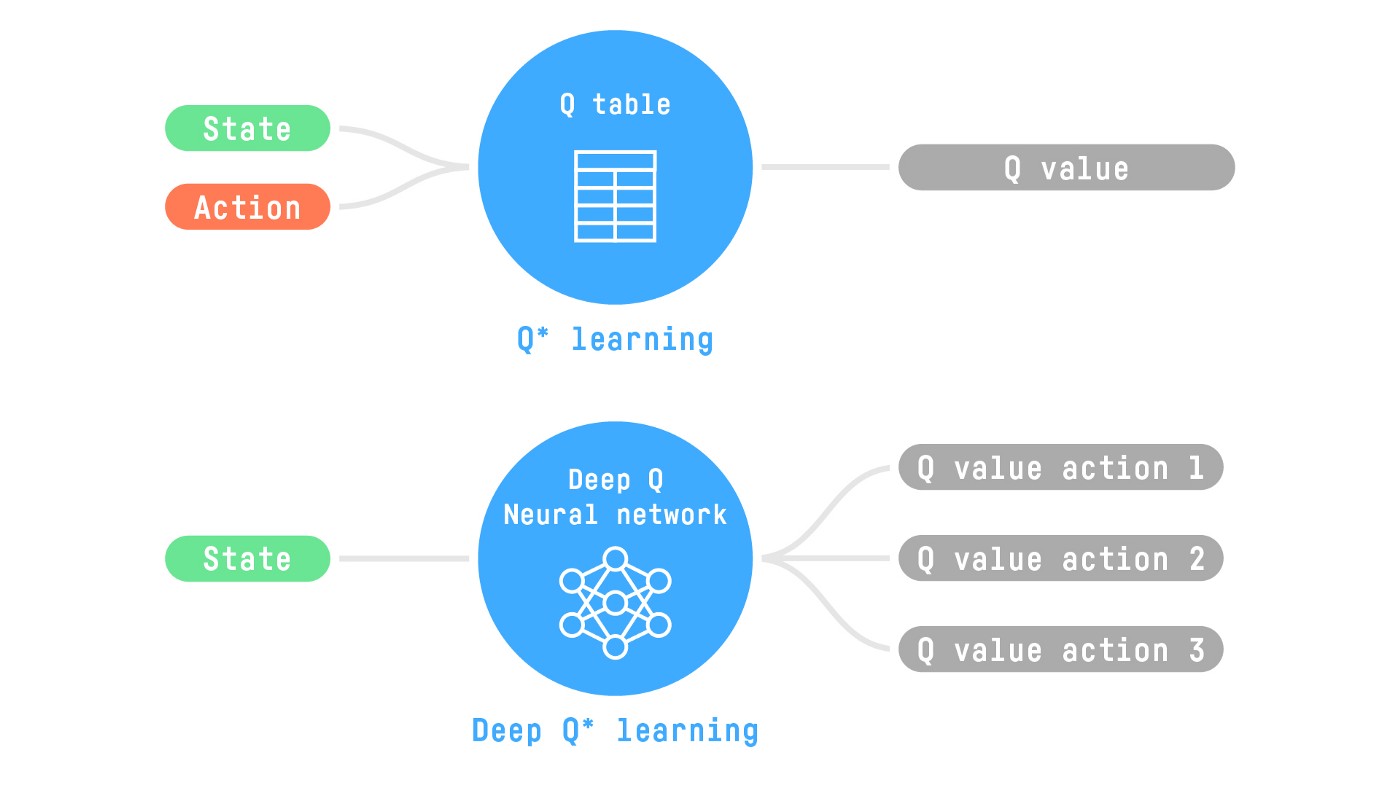
例如,在下一篇文章中,我們將研究 Q-學習(經典強化學習),然後是深度 Q-學習,兩者都是基於價值的強化學習演算法。
你會發現不同之處在於,第一種方法中,**我們使用傳統演算法**來建立一個 Q 表,幫助我們找到每個狀態下要採取的動作。
在第二種方法中,**我們將使用神經網路**(來近似 q 值)。
如果你不熟悉深度學習,你絕對應該觀看 fastai 的面向程式設計師的實用深度學習課程(免費)
資訊量很大,我們來總結一下
強化學習是一種透過行動學習的計算方法。我們構建一個代理,透過**試錯**與環境互動並接收獎勵(負面或正面)作為反饋來學習。
任何強化學習代理的目標都是最大化其預期累積獎勵(也稱為預期回報),因為強化學習基於**獎勵假設**,即**所有目標都可以描述為最大化預期累積獎勵。**
強化學習過程是一個迴圈,輸出一系列**狀態、動作、獎勵和下一個狀態。**
為了計算預期累積獎勵(預期回報),我們對獎勵進行折扣:較早(遊戲開始時)的獎勵**更有可能發生,因為它們比長期未來的獎勵更可預測。**
為了解決強化學習問題,你需要**找到一個最優策略**,策略是人工智慧的“大腦”,它會告訴我們**在給定狀態下應該採取什麼行動。**最優策略是**能夠最大化預期回報的策略。**
有兩種方法可以找到你的最優策略
- 透過直接訓練策略:**基於策略的方法。**
- 透過訓練一個價值函式,告訴我們代理在每個狀態下將獲得的預期回報,並使用該函式來定義我們的策略:**基於價值的方法。**
最後,我們談論深度強化學習,因為我們引入了**深度神經網路來估計要採取的動作(基於策略)或估計狀態的價值(基於價值)**,因此得名“深度”。
現在你已經學習了強化學習的基礎知識,你已經準備好訓練你的第一個著陸器代理,使其**正確地降落在月球🌕並將其透過 Hub 🔥 分享給社群**
點選這裡開始教程 👉 https://github.com/huggingface/deep-rl-class/blob/main/unit1/unit1.ipynb
由於學習和避免能力錯覺的最佳方法是**自我測試**。我們編寫了一個測驗來幫助你找出**你需要加強學習的地方**。在此處檢查你的知識 👉 https://github.com/huggingface/deep-rl-class/blob/main/unit1/quiz.md
恭喜你完成了本章!**這是最長的一章**,資訊量很大。也恭喜你完成了教程。你剛剛訓練了你的第一個深度強化學習代理並將其分享到 Hub 🥳。
如果所有這些元素讓你**仍然感到困惑**,那是**正常現象**。**我和所有學習強化學習的人都經歷過同樣的感覺。**
花些時間真正理解這些材料再繼續。掌握這些元素並打下堅實的基礎,才能進入**有趣的部分。**
如果你想深入瞭解,我們在教學大綱中釋出了額外的閱讀材料 👉 https://github.com/huggingface/deep-rl-class/blob/main/unit1/README.md
當然,在課程中,**我們將再次使用和解釋這些術語**,但最好在深入下一章之前理解它們。
在下一章中,我們將學習 Q-學習並更深入地瞭解**基於價值的方法。**
別忘了分享給你想學習的朋友 🤗!
最後,我們希望**根據你的反饋不斷改進和更新課程**。如果你有任何反饋,請填寫此表格 👉 https://forms.gle/3HgA7bEHwAmmLfwh9

