使用PyTorch實現策略梯度

Hugging Face 🤗 深度強化學習課程的第五單元
⚠️ **本文的新更新版本可在此處獲取** 👉 https://huggingface.co/deep-rl-course/unit1/introduction
本文是深度強化學習課程的一部分。這是一個從初學者到專家的免費課程。在此處檢視課程大綱 here. 
⚠️ **本文的新更新版本可在此處獲取** 👉 https://huggingface.co/deep-rl-course/unit1/introduction
本文是深度強化學習課程的一部分。這是一個從入門到精通的免費課程。請在此處檢視課程大綱 here.
在上一單元中,我們學習了深度Q學習。在這個基於價值的深度強化學習演算法中,我們**使用深度神經網路來近似某個狀態下每個可能動作的不同Q值。**
事實上,從課程開始,我們只研究了基於價值的方法,**我們透過估計一個價值函式作為找到最優策略的中間步驟。**

因為在基於價值的方法中,**π只存在於動作價值估計中,因為策略只是一個函式**(例如,貪婪策略),它將選擇給定狀態下價值最高的動作。
但是,使用基於策略的方法,我們希望**直接最佳化策略,而無需學習價值函式的中間步驟。**
所以今天,**我們將研究我們的第一個基於策略的方法**:強化。我們將使用PyTorch從頭開始實現它。然後使用CartPole-v1、PixelCopter和Pong測試其魯棒性。

讓我們開始吧,
什麼是策略梯度方法?
策略梯度是基於策略方法的一個子類,這類演算法**旨在不使用價值函式的情況下直接最佳化策略,採用不同的技術。**與基於策略方法不同的是,策略梯度方法是一系列旨在**透過使用梯度上升估計最優策略的權重**來直接最佳化策略的演算法。
策略梯度概述
為什麼我們在策略梯度方法中透過使用梯度上升估計最優策略的權重來直接最佳化策略?
請記住,強化學習的目的是**找到最優行為策略(policy)以最大化其預期累積獎勵。**
我們還需要記住,策略是一個函式,**給定一個狀態,它會輸出一個動作分佈**(在我們的例子中,使用隨機策略)。

我們使用策略梯度的目標是透過調整策略來控制動作的機率分佈,從而使**好的動作(最大化回報的動作)在未來被更頻繁地取樣。**
舉一個簡單的例子
我們透過讓我們的策略與環境互動來收集一個回合。
然後我們檢視該回合的獎勵總和(預期回報)。如果這個總和是正的,我們**認為在該回閤中採取的動作是好的**:因此,我們希望增加每個狀態-動作對的P(a|s)(在該狀態下采取該動作的機率)。
策略梯度演算法(簡化版)如下:

但是深度Q學習很棒!為什麼要使用策略梯度方法呢?
策略梯度方法的優點
與深度Q學習方法相比,有許多優點。讓我們來看看其中一些:
整合的簡易性:**我們可以直接估計策略而無需儲存額外資料(動作值)。**
策略梯度方法**可以學習隨機策略,而價值函式不能**。
這有兩點影響:
a. 我們**不需要手動實現探索/利用權衡**。由於我們輸出的是動作的機率分佈,因此代理會**探索狀態空間,而不會總是採取相同的軌跡。**
b. 我們也擺脫了**感知混疊**問題。感知混疊是指兩個狀態看起來(或確實是)相同,但需要不同的動作。
舉個例子:我們有一個智慧吸塵器,它的目標是吸塵並避免殺死倉鼠。

我們的吸塵器只能感知牆壁的位置。
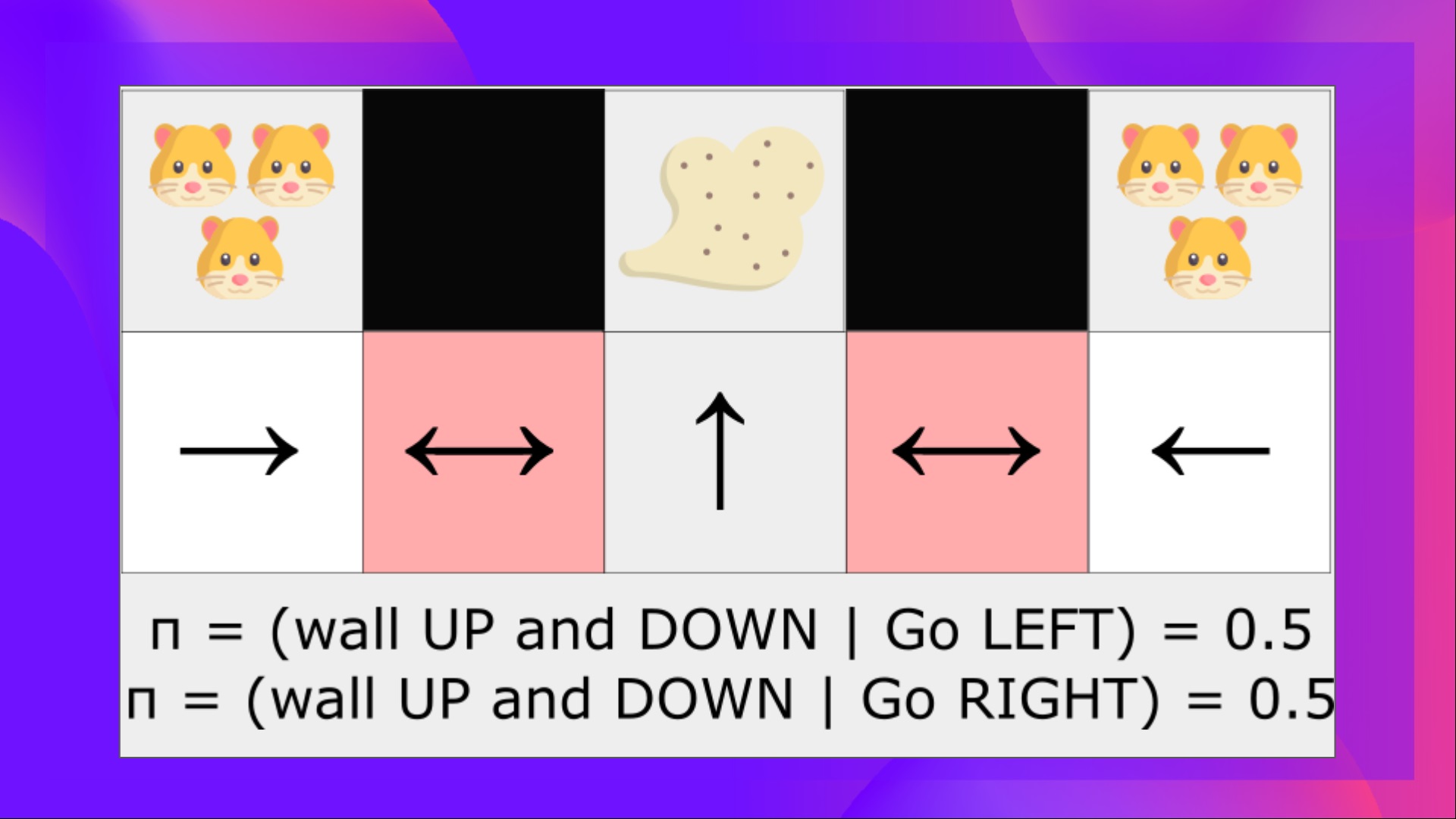
問題是這兩個紅色方框是混疊狀態,因為代理在每個方框中都感知到上方和下方的牆壁。
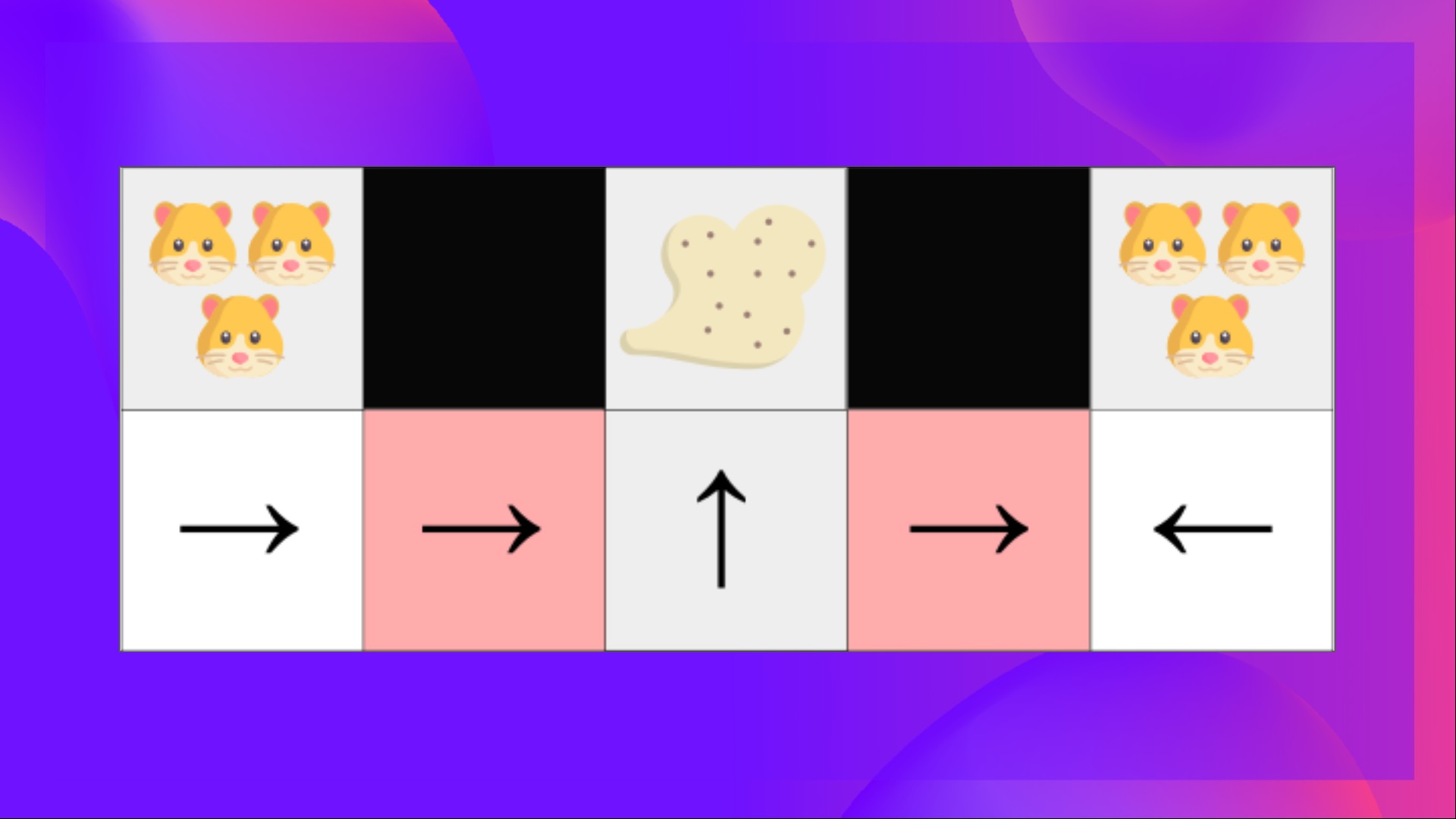
在確定性策略下,策略將在處於紅色狀態時向右移動或向左移動。**無論哪種情況都會導致我們的代理卡住,永遠無法吸到灰塵。**
在基於價值的強化學習演算法下,我們學習了一個準確定性策略(“貪婪 ε 策略”)。因此,我們的代理在找到灰塵之前可能會花費大量時間。
另一方面,最優隨機策略將在灰色狀態下隨機向左或向右移動。因此,**它不會卡住,並且以高機率達到目標狀態。**
- 策略梯度在**高維動作空間和連續動作空間中更有效**。
事實上,深度Q學習的問題在於,它們的**預測為每個可能的動作分配一個分數(最大預期未來獎勵)**,在每個時間步,給定當前狀態。
但是如果我們有無限的行動可能性呢?
例如,對於自動駕駛汽車,在每個狀態下,你可能(幾乎)有無限的動作選擇(方向盤轉15°、17.2°、19.4°、鳴笛等)。我們需要為每個可能的動作輸出一個Q值!而從連續輸出中選擇最大動作本身就是一個最佳化問題!
相反,使用策略梯度,我們輸出一個**動作的機率分佈。**
策略梯度方法的缺點
當然,策略梯度方法也有一些缺點:
- 策略梯度很多時候會收斂到區域性最大值而不是全域性最優。
- 策略梯度進展更快,**一步一步地:訓練可能需要更長時間(效率低下)。**
- 策略梯度可能具有高方差(解決方案基線)。
👉 如果你想深入瞭解策略梯度方法的優點和缺點,你可以檢視這個影片。
現在我們已經瞭解了策略梯度的大致情況及其優缺點,**讓我們研究並實現其中一個**:強化。
強化(蒙特卡洛策略梯度)
強化,也稱為蒙特卡洛策略梯度,**使用整個回合的估計回報來更新策略引數** 。
我們有一個策略π,它有一個引數θ。這個π在給定一個狀態下,**輸出一個動作的機率分佈**。

其中 是代理在給定策略下從狀態st選擇動作at的機率。
**但我們如何知道我們的策略是好是壞呢?**我們需要有一種方法來衡量它。為此,我們定義了一個稱為 的分數/目標函式。
評分函式J是預期回報

請記住,策略梯度可以看作是一個最佳化問題。因此,我們必須找到最佳引數(θ)來最大化評分函式J(θ)。
為此,我們將使用策略梯度定理。我不會深入數學細節,如果你感興趣,請檢視此影片
強化演算法的工作原理如下:迴圈
- 使用策略 收集一個回合
- 使用該回合估算梯度

- 更新策略的權重:
我們可以這樣解釋:
- 是從狀態st選擇動作at的**(對數)機率增加最陡峭的方向**。這意味著它告訴我們,如果我們想增加/減少在狀態st選擇動作at的對數機率,**我們應該如何改變策略的權重**。
- :是評分函式。
- 如果回報高,它將提高(狀態,動作)組合的機率。
- 反之,如果回報低,它將降低(狀態,動作)組合的機率。
既然我們已經學習了強化背後的理論,**你就可以用 PyTorch 編寫你的強化智慧體了**。你將使用 CartPole-v1、PixelCopter 和 Pong 來測試它的魯棒性。
從這裡開始教程 👉 https://colab.research.google.com/github/huggingface/deep-rl-class/blob/main/unit5/unit5.ipynb
與同學比較結果的排行榜 🏆 👉 https://huggingface.co/spaces/chrisjay/Deep-Reinforcement-Learning-Leaderboard
恭喜你完成了這一章!有很多資訊。恭喜你完成了教程。你剛剛使用 PyTorch 從零開始編寫了你的第一個深度強化學習智慧體,並將其分享到 Hub 🥳。
**如果你仍然對所有這些元素感到困惑,這是正常的**。**我和所有學習 RL 的人都一樣。**
花時間真正掌握這些材料,然後再繼續。
不要猶豫,在其他環境中訓練你的 Agent。最好的學習方式是自己動手嘗試!
如果你想深入瞭解,我們在大綱中釋出了額外的閱讀材料👉**https://github.com/huggingface/deep-rl-class/blob/main/unit5/README.md**
在下一單元中,我們將學習策略基於價值方法和基於價值方法相結合的方法,稱為 Actor Critic 方法。
別忘了與想要學習的朋友分享 🤗!
最後,我們希望**透過您的反饋不斷改進和更新本課程**。如果您有任何反饋,請填寫此表格 👉**https://forms.gle/3HgA7bEHwAmmLfwh9**

