使用 TF Serving 在 Kubernetes 上部署 🤗 ViT


在上一篇文章中,我們展示瞭如何使用 TensorFlow Serving 在本地部署來自 🤗 Transformers 的Vision Transformer (ViT) 模型。我們涵蓋了將預處理和後處理操作嵌入 Vision Transformer 模型、處理 gRPC 請求等主題!
雖然本地部署是構建有用內容的絕佳開端,但在實際專案中,您需要執行可以服務大量使用者的部署。在這篇文章中,您將學習如何使用 Docker 和 Kubernetes 擴充套件上一篇文章中的本地部署。因此,我們假設您對 Docker 和 Kubernetes 有一定的熟悉度。
這篇文章是在上一篇文章的基礎上編寫的,所以我們強烈建議您先閱讀該文章。您可以在這個倉庫中找到本文中討論的所有程式碼。
為什麼選擇 Docker 和 Kubernetes?
擴充套件我們部署的基本工作流程包括以下步驟:
容器化應用邏輯:應用邏輯涉及一個可以處理請求並返回預測的服務模型。對於容器化,Docker 是行業標準的首選。
部署 Docker 容器:您有多種選擇。最廣泛使用的選項是將 Docker 容器部署到 Kubernetes 叢集上。Kubernetes 提供了許多部署友好的功能(例如自動擴縮和安全性)。您可以使用像 Minikube 這樣的解決方案在本地管理 Kubernetes 叢集,或者像 Elastic Kubernetes Service (EKS) 這樣的無伺服器解決方案。
您可能想知道,在Sagemaker、Vertex AI 等直接提供 ML 部署特定功能的時代,為什麼還要使用這種顯式設定呢?這是很合理的想法。
上述工作流程在業界被廣泛採用,許多組織從中受益。它已經經過多年實戰檢驗。它還允許您對部署進行更精細的控制,同時抽象掉不重要的部分。
本文使用 Google Kubernetes Engine (GKE) 來配置和管理 Kubernetes 叢集。如果您使用 GKE,我們假設您已經擁有一個已啟用計費的 GCP 專案。此外,請注意,您需要配置 gcloud 工具才能在 GKE 上執行部署。但本文討論的概念同樣適用於您決定使用 Minikube 的情況。
注意:本文中顯示的程式碼片段可以在 Unix 終端上執行,只要您配置了 `gcloud` 工具以及 Docker 和 `kubectl`。更多說明請參閱隨附的儲存庫。
使用 Docker 進行容器化
該服務模型可以處理原始影像輸入(以位元組為單位),並能夠進行預處理和後處理。
在本節中,您將看到如何使用 基礎 TensorFlow Serving 映象 來容器化該模型。TensorFlow Serving 以 SavedModel 格式使用模型。回想一下您在上一篇文章中是如何獲取這種 SavedModel 的。我們假設您的 SavedModel 已壓縮為 tar.gz 格式。如果需要,您可以從此處獲取。然後,SavedModel 應放置在特殊的目錄結構
準備 Docker 映象
下面的 shell 指令碼將 `SavedModel` 放置在 `models` 父目錄下的 `hf-vit/1` 中。在準備 Docker 映象時,您將複製其中的所有內容。這個例子中只有一個模型,但這是一種更通用的方法。
$ MODEL_TAR=model.tar.gz
$ MODEL_NAME=hf-vit
$ MODEL_VERSION=1
$ MODEL_PATH=models/$MODEL_NAME/$MODEL_VERSION
$ mkdir -p $MODEL_PATH
$ tar -xvf $MODEL_TAR --directory $MODEL_PATH
下面,我們展示了在我們的案例中 `models` 目錄的結構
$ find /models
/models
/models/hf-vit
/models/hf-vit/1
/models/hf-vit/1/keras_metadata.pb
/models/hf-vit/1/variables
/models/hf-vit/1/variables/variables.index
/models/hf-vit/1/variables/variables.data-00000-of-00001
/models/hf-vit/1/assets
/models/hf-vit/1/saved_model.pb
自定義的 TensorFlow Serving 映象應基於官方映象構建。有多種方法可以實現這一點,但您將透過執行 Docker 容器來完成,如官方文件所示。我們首先在後臺模式下執行 `tensorflow/serving` 映象,然後將整個 `models` 目錄複製到正在執行的容器中,如下所示。
$ docker run -d --name serving_base tensorflow/serving
$ docker cp models/ serving_base:/models/
我們使用了 TensorFlow Serving 的官方 Docker 映象作為基礎,但您也可以使用您從原始碼構建的映象。
注意:TensorFlow Serving 受益於利用 AVX512 等指令集的硬體最佳化。這些指令集可以加速深度學習模型推理。因此,如果您知道模型將部署在什麼硬體上,通常最好獲取 TensorFlow Serving 映象的最佳化版本並在整個過程中使用它。
現在,執行中的容器已經擁有了所有必需的檔案並以適當的目錄結構排列,我們需要建立一個包含這些更改的新 Docker 映象。這可以透過下面的 `docker commit` 命令完成,您將獲得一個名為 `$NEW_IMAGE` 的新 Docker 映象。需要注意的一點是,您需要將 `MODEL_NAME` 環境變數設定為模型名稱,在本例中為 `hf-vit`。這會告訴 TensorFlow Serving 要部署哪個模型。
$ NEW_IMAGE=tfserving:$MODEL_NAME
$ docker commit \
--change "ENV MODEL_NAME $MODEL_NAME" \
serving_base $NEW_IMAGE
在本地執行 Docker 映象
最後,您可以在本地執行新構建的 Docker 映象,看看它是否正常工作。下面您可以看到 `docker run` 命令的輸出。由於輸出非常詳細,我們將其精簡,只關注重要部分。此外,值得注意的是,它分別打開了 `8500` 和 `8501` 埠,用於 gRPC 和 HTTP/REST 端點。
$ docker run -p 8500:8500 -p 8501:8501 -t $NEW_IMAGE &
---------OUTPUT---------
(Re-)adding model: hf-vit
Successfully reserved resources to load servable {name: hf-vit version: 1}
Approving load for servable version {name: hf-vit version: 1}
Loading servable version {name: hf-vit version: 1}
Reading SavedModel from: /models/hf-vit/1
Reading SavedModel debug info (if present) from: /models/hf-vit/1
Successfully loaded servable version {name: hf-vit version: 1}
Running gRPC ModelServer at 0.0.0.0:8500 ...
Exporting HTTP/REST API at:localhost:8501 ...
推送 Docker 映象
這裡的最後一步是將 Docker 映象推送到映象倉庫。您將使用 Google Container Registry (GCR) 來實現此目的。以下程式碼行可以為您完成此操作
$ GCP_PROJECT_ID=<GCP_PROJECT_ID>
$ GCP_IMAGE=gcr.io/$GCP_PROJECT_ID/$NEW_IMAGE
$ gcloud auth configure-docker
$ docker tag $NEW_IMAGE $GCP_IMAGE
$ docker push $GCP_IMAGE
由於我們使用 GCR,您需要在 Docker 映象標籤(請注意其他格式)前加上 `gcr.io/
在 Kubernetes 叢集上部署
在 Kubernetes 叢集上部署需要以下內容:
配置 Kubernetes 叢集,本文使用 Google Kubernetes Engine (GKE) 完成。但是,歡迎您使用其他平臺和工具,如 EKS 或 Minikube。
連線到 Kubernetes 叢集以執行部署。
編寫 YAML 清單。
使用實用工具 `kubectl` 使用清單執行部署。
讓我們逐一回顧這些步驟。
在 GKE 上配置 Kubernetes 叢集
您可以使用類似這樣的 shell 指令碼來實現此目的(可在此處獲取)
$ GKE_CLUSTER_NAME=tfs-cluster
$ GKE_CLUSTER_ZONE=us-central1-a
$ NUM_NODES=2
$ MACHINE_TYPE=n1-standard-8
$ gcloud container clusters create $GKE_CLUSTER_NAME \
--zone=$GKE_CLUSTER_ZONE \
--machine-type=$MACHINE_TYPE \
--num-nodes=$NUM_NODES
GCP 提供了多種機器型別,可讓您按需配置部署。我們鼓勵您參考文件以瞭解更多資訊。
叢集配置完成後,您需要連線到它以執行部署。由於此處使用了 GKE,您還需要進行身份驗證。您可以使用如下 shell 指令碼來完成這兩個操作:
$ GCP_PROJECT_ID=<GCP_PROJECT_ID>
$ export USE_GKE_GCLOUD_AUTH_PLUGIN=True
$ gcloud container clusters get-credentials $GKE_CLUSTER_NAME \
--zone $GKE_CLUSTER_ZONE \
--project $GCP_PROJECT_ID
`gcloud container clusters get-credentials` 命令負責連線到叢集和身份驗證。完成此操作後,您就可以編寫清單了。
編寫 Kubernetes 清單
Kubernetes 清單使用 YAML 檔案編寫。雖然可以使用單個清單檔案來執行部署,但建立單獨的清單檔案通常有利於委派關注點分離。通常使用三個清單檔案來實現這一點:
deployment.yaml透過提供 Docker 映象的名稱、執行 Docker 映象時的額外引數、用於外部訪問的埠以及資源限制來定義 Deployment 的期望狀態。service.yaml定義外部客戶端與 Kubernetes 叢集內部 Pod 之間的連線。hpa.yaml定義了根據 CPU 利用率等規則來擴縮 Deployment 中 Pod 數量的規則。
您可以在這裡找到本文的相關清單。下面,我們提供了一個圖片概覽,說明這些清單是如何使用的。
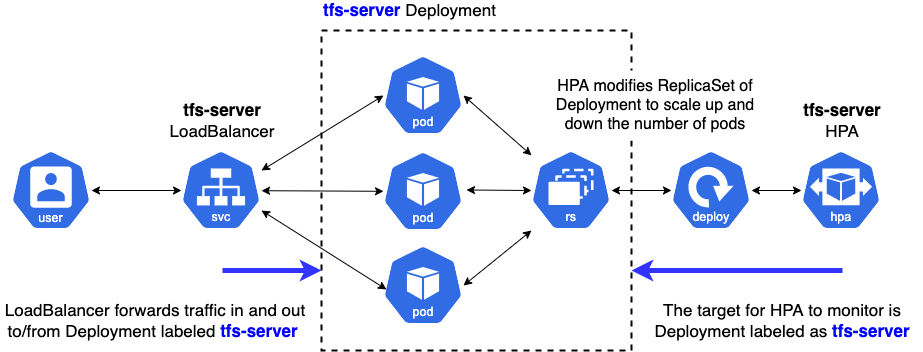
接下來,我們介紹每個清單的重要部分。
deployment.yaml:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: tfs-server
name: tfs-server
...
spec:
containers:
- image: gcr.io/$GCP_PROJECT_ID/tfserving-hf-vit:latest
name: tfs-k8s
imagePullPolicy: Always
args: ["--tensorflow_inter_op_parallelism=2",
"--tensorflow_intra_op_parallelism=8"]
ports:
- containerPort: 8500
name: grpc
- containerPort: 8501
name: restapi
resources:
limits:
cpu: 800m
requests:
cpu: 800m
...
您可以隨意配置 `tfs-server`、`tfs-k8s` 等名稱。在 `containers` 下,您指定部署將使用的 Docker 映象 URI。透過設定容器 `resources` 的允許範圍來監控當前資源利用率。這可以使 Horizontal Pod Autoscaler(稍後討論)決定擴縮容器數量。`requests.cpu` 是操作員設定的確保容器正常工作的最小 CPU 資源量。這裡 800m 表示整個 CPU 資源的 80%。因此,HPA 監控所有 Pod 的 `requests.cpu` 總和的平均 CPU 利用率,以做出擴縮決策。
除了 Kubernetes 特定的配置外,您還可以在 `args` 中指定 TensorFlow Serving 特定的選項。在這種情況下,您有兩個:
`tensorflow_inter_op_parallelism`,它設定並行執行以執行獨立操作的執行緒數。建議值為 2。
`tensorflow_intra_op_parallelism`,它設定並行執行以執行單個操作的執行緒數。建議值為部署 CPU 的物理核心數。
您可以從此處和此處瞭解有關這些選項(以及其他選項)的更多資訊以及調整它們以進行部署的技巧。
service.yaml:
apiVersion: v1
kind: Service
metadata:
labels:
app: tfs-server
name: tfs-server
spec:
ports:
- port: 8500
protocol: TCP
targetPort: 8500
name: tf-serving-grpc
- port: 8501
protocol: TCP
targetPort: 8501
name: tf-serving-restapi
selector:
app: tfs-server
type: LoadBalancer
我們將服務型別設定為“LoadBalancer”,以便端點可以外部暴露給 Kubernetes 叢集。它選擇“tfs-server”部署,透過指定的埠與外部客戶端建立連線。我們為 gRPC 和 HTTP/REST 連線分別開放了“8500”和“8501”兩個埠。
hpa.yaml:
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: tfs-server
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: tfs-server
minReplicas: 1
maxReplicas: 3
targetCPUUtilizationPercentage: 80
HPA 代表橫向 Pod 自動擴縮。它設定了決定何時擴縮目標部署中 Pod 數量的標準。您可以在此處瞭解更多關於 Kubernetes 內部使用的自動擴縮演算法的資訊。
在這裡,您指定 Kubernetes 應如何處理自動擴縮。特別是,您定義了它應該執行自動擴縮的副本範圍——`minReplicas` 和 `maxReplicas`,以及目標 CPU 利用率。`targetCPUUtilizationPercentage` 是一個重要的自動擴縮指標。以下帖子恰當地總結了它的含義(摘自此處)
CPU 利用率是部署中所有 Pod 在過去一分鐘內的平均 CPU 使用率除以該部署的請求 CPU。如果 Pod 的平均 CPU 利用率高於您定義的目標,則您的副本將被調整。
回想一下在部署清單中指定 `resources`。透過指定 `resources`,Kubernetes 控制平面開始監控指標,因此 `targetCPUUtilization` 才能正常工作。否則,HPA 不知道 Deployment 的當前狀態。
您可以根據自己的需求進行實驗並將其設定為所需的數字。但是請注意,自動擴縮將取決於您在 GCP 上可用的配額,因為 GKE 內部使用 Google Compute Engine 來管理這些資源。
執行部署
清單準備好後,您可以使用 `kubectl apply` 命令將其應用於當前連線的 Kubernetes 叢集。
$ kubectl apply -f deployment.yaml
$ kubectl apply -f service.yaml
$ kubectl apply -f hpa.yaml
雖然使用 `kubectl` 來應用每個清單以執行部署很方便,但如果清單數量很多,它很快就會變得困難。這時,像 Kustomize 這樣的實用工具就能派上用場了。您只需定義另一個名為 `kustomization.yaml` 的規範,如下所示:
commonLabels:
app: tfs-server
resources:
- deployment.yaml
- hpa.yaml
- service.yaml
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
然後,只需一行程式碼即可執行實際部署:
$ kustomize build . | kubectl apply -f -
完整的說明可在此處找到。部署完成後,我們可以像這樣檢索端點 IP:
$ kubectl rollout status deployment/tfs-server
$ kubectl get svc tfs-server --watch
---------OUTPUT---------
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
tfs-server LoadBalancer xxxxxxxxxx xxxxxxxxxx 8500:30869/TCP,8501:31469/TCP xxx
當外部 IP 可用時,請記下它。
這就總結了將模型部署到 Kubernetes 所需的所有步驟!Kubernetes 優雅地提供了複雜部分的抽象,例如自動擴縮和叢集管理,同時讓您專注於部署模型時應關注的關鍵方面,包括資源利用率、安全性(我們在此未涉及)、延遲等效能指標。
測試端點
假設您獲得了端點的外部 IP,您可以使用以下列表對其進行測試:
import tensorflow as tf
import json
import base64
image_path = tf.keras.utils.get_file(
"image.jpg", "http://images.cocodataset.org/val2017/000000039769.jpg"
)
bytes_inputs = tf.io.read_file(image_path)
b64str = base64.urlsafe_b64encode(bytes_inputs.numpy()).decode("utf-8")
data = json.dumps(
{"signature_name": "serving_default", "instances": [b64str]}
)
json_response = requests.post(
"http://<ENDPOINT-IP>:8501/v1/models/hf-vit:predict",
headers={"content-type": "application/json"},
data=data
)
print(json.loads(json_response.text))
---------OUTPUT---------
{'predictions': [{'label': 'Egyptian cat', 'confidence': 0.896659195}]}
如果您有興趣瞭解此部署在面對更多流量時的效能,我們建議您檢視這篇文章。請參閱相應的倉庫,瞭解更多關於使用 Locust 執行負載測試和視覺化結果的資訊。
關於不同 TF Serving 配置的說明
TensorFlow Serving 提供了各種選項,可根據您的應用程式用例定製部署。下面,我們簡要討論其中一些選項。
`enable_batching` 啟用批處理推理功能,該功能在一定的時間視窗內收集傳入請求,將它們整理為批次,執行批處理推理,並將每個請求的結果返回給相應的客戶端。TensorFlow Serving 提供了一組豐富的可配置選項(例如 `max_batch_size`、`num_batch_threads`)以根據您的部署需求進行調整。您可以在此處瞭解更多資訊。批處理對於那些不需要模型即時預測的應用程式特別有利。在這種情況下,您通常會將多個樣本批次收集起來進行預測,然後將這些批次傳送進行預測。幸運的是,當我們啟用 TensorFlow Serving 的批處理功能時,它可以自動配置所有這些功能。
`enable_model_warmup` 使用虛擬輸入資料預熱一些惰性例項化的 TensorFlow 元件。透過這種方式,您可以確保所有內容都已正確載入,並且在實際服務期間不會出現延遲。
結論
在本文和相關的倉庫中,您學習瞭如何在 Kubernetes 叢集上部署 🤗 Transformers 中的 Vision Transformer 模型。如果您是第一次進行此操作,這些步驟可能看起來有點令人望而生畏,但一旦掌握,它們很快就會成為您工具箱中必不可少的一部分。如果您已經熟悉此工作流程,我們希望本文對您仍然有所幫助。
我們對同一個 Vision Transformer 模型的 ONNX 最佳化版本應用了相同的部署工作流程。欲瞭解更多詳情,請檢視此連結。如果您的部署使用 x86 CPU,則 ONNX 最佳化模型特別有利。
在下一篇文章中,我們將向您展示如何使用 Vertex AI 大幅減少程式碼量來執行這些部署——更像是 `model.deploy(autoscaling_config=...)`,然後搞定!我們希望您和我們一樣興奮。
致謝
感謝 Google 的 ML 開發者關係專案團隊,他們為我們提供了 GCP 積分,用於進行實驗。

