在 Vertex AI 上部署 🤗 ViT



在之前的文章中,我們展示瞭如何將 🤗 Transformers 中的 Vision Transformers (ViT) 模型 本地部署到 Kubernetes 叢集上。本文將向您展示如何在 Vertex AI 平臺上部署相同的模型。您將獲得與基於 Kubernetes 的部署相同的可伸縮性級別,但程式碼量顯著減少。
本文是基於上面連結的兩篇舊文章構建的。如果您還沒有閱讀它們,建議您檢視一下。
您可以在文章開頭的 Colab Notebook 中找到一個完整的示例。
什麼是 Vertex AI?
根據 Google Cloud:
Vertex AI 提供了工具來支援您整個機器學習工作流程,涵蓋不同的模型型別和不同級別的機器學習專業知識。
在模型部署方面,Vertex AI 提供了一些重要的功能,並採用統一的 API 設計:
身份驗證
基於流量的自動擴縮
模型版本控制
不同模型版本之間的流量拆分
速率限制
模型監控和日誌記錄
支援線上和批次預測
對於 TensorFlow 模型,它提供了各種現成的實用程式,您將在本文中瞭解它們。但它也對 PyTorch 和 scikit-learn 等其他框架提供類似的支援。
要使用 Vertex AI,您需要一個已啟用結算的 Google Cloud Platform (GCP) 專案,並啟用以下服務:
Vertex AI
Cloud Storage
重溫服務模型
您將使用與前兩篇文章中相同的TensorFlow 中實現的 ViT B/16 模型。您將模型與相應的預處理和後處理操作一起序列化,以減少訓練-服務偏差。請參閱詳細討論此內容的第一篇文章。最終序列化的 SavedModel 的簽名如下所示:
The given SavedModel SignatureDef contains the following input(s):
inputs['string_input'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_string_input:0
The given SavedModel SignatureDef contains the following output(s):
outputs['confidence'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: StatefulPartitionedCall:0
outputs['label'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: StatefulPartitionedCall:1
Method name is: tensorflow/serving/predict
該模型將接受影像的base64 編碼字串,執行預處理,執行推理,最後執行後處理步驟。這些字串經過 base64 編碼以防止在網路傳輸過程中進行任何修改。預處理包括將輸入影像大小調整為 224x224 解析度,將其標準化到 [-1, 1] 範圍,並將其轉置為 channels_first 記憶體佈局。後處理包括將預測的 logits 對映到字串標籤。
要在 Vertex AI 上執行部署,您需要將模型工件儲存在Google Cloud Storage (GCS) 儲存桶中。隨附的 Colab Notebook 展示瞭如何建立 GCS 儲存桶並將模型工件儲存到其中。
使用 Vertex AI 的部署工作流程
下圖描繪了在 Vertex AI 上部署已訓練的 TensorFlow 模型的工作流程。
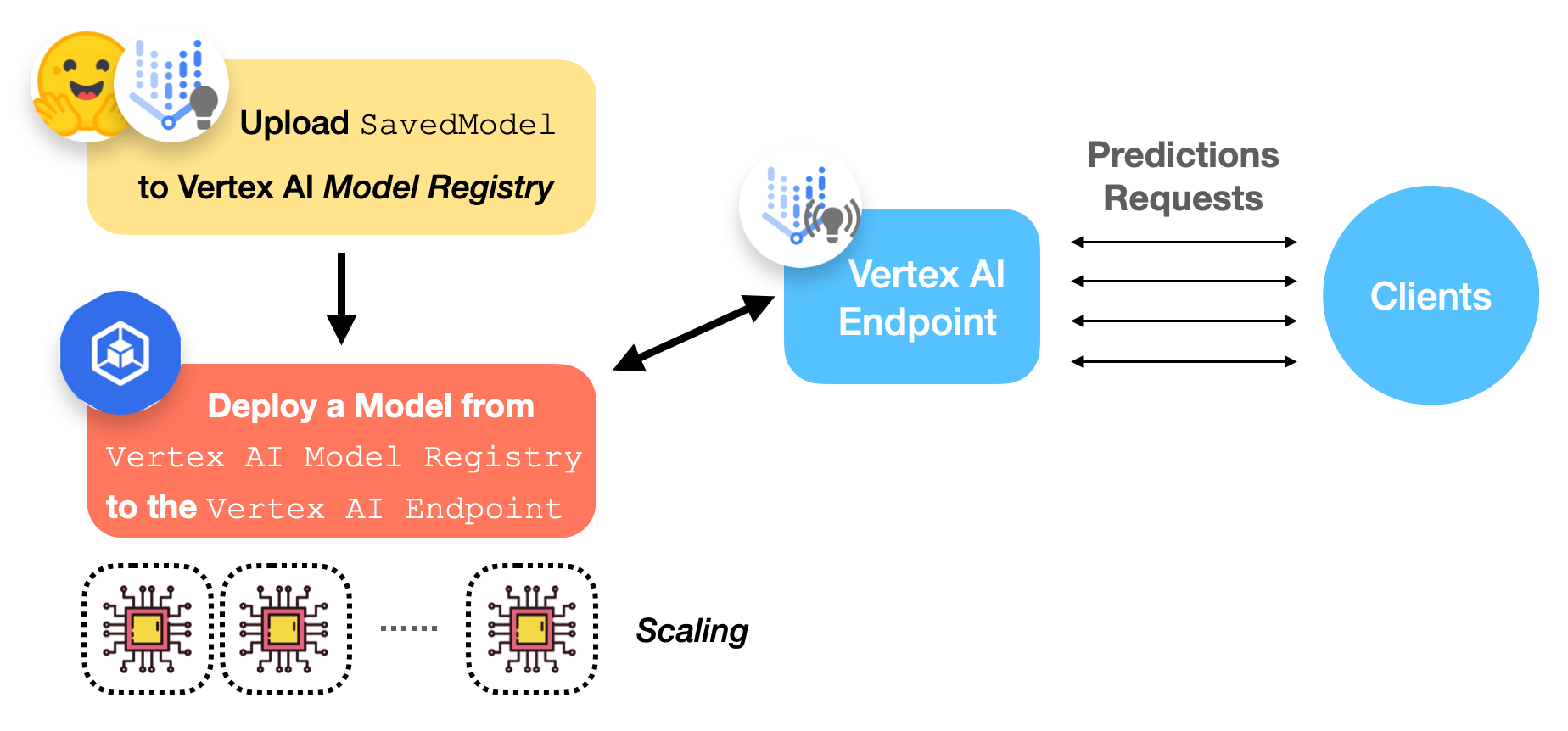
現在我們來討論一下 Vertex AI 模型登錄檔和端點是什麼。
Vertex AI 模型登錄檔
Vertex AI 模型登錄檔是一個完全託管的機器學習模型登錄檔。關於“完全託管”這裡有幾點需要注意。首先,您無需擔心模型的儲存方式和位置。其次,它管理同一模型的不同版本。
這些功能對於生產中的機器學習非常重要。構建一個能保證高可用性和安全性的模型登錄檔絕非易事。此外,由於我們無法控制黑盒機器學習模型的內部,通常會遇到需要將當前模型回滾到舊版本的情況。Vertex AI 模型登錄檔使我們能夠輕鬆實現這些目標。
目前支援的模型型別包括 TensorFlow 的 SavedModel、scikit-learn 和 XGBoost。
Vertex AI 端點
從使用者的角度來看,Vertex AI 端點只是提供一個端點來接收請求併發送響應。然而,它在底層為機器學習操作人員提供了許多可配置的選項。以下是一些您可以選擇的配置:
模型版本
VM 的 CPU、記憶體和加速器規格
計算節點的最小/最大數量
流量拆分百分比
模型監控視窗長度及其目標
預測請求取樣率
執行部署
google-cloud-aiplatform Python SDK 提供了易於使用的 API 來管理 Vertex AI 上部署的生命週期。它分為四個步驟:
- 上傳模型
- 建立端點
- 將模型部署到端點
- 發起預測請求。
在這些步驟中,您將需要 google-cloud-aiplatform Python SDK 中的 ModelServiceClient、EndpointServiceClient 和 PredictionServiceClient 模組來與 Vertex AI 互動。
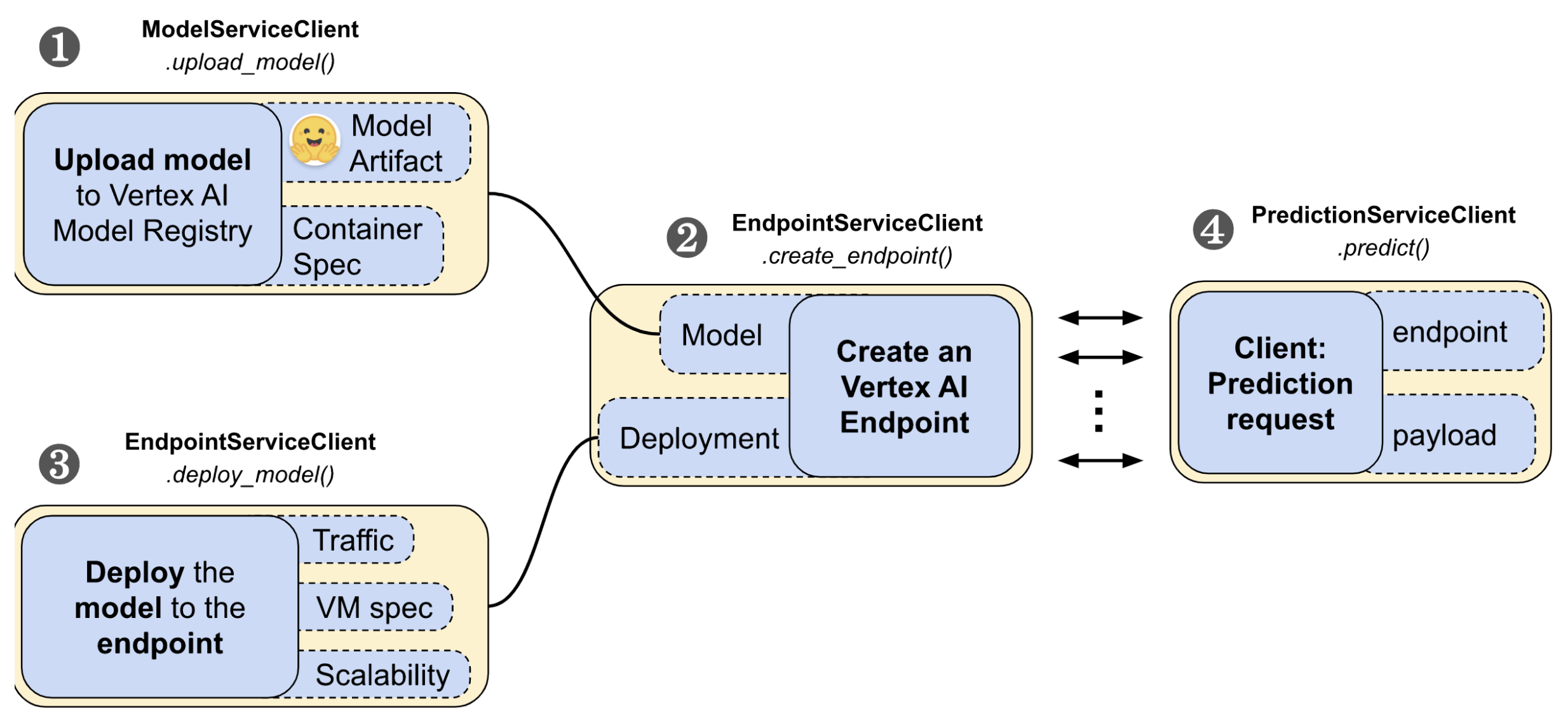
1. 工作流程的第一步是將 SavedModel 上傳到 Vertex AI 的模型登錄檔
tf28_gpu_model_dict = {
"display_name": "ViT Base TF2.8 GPU model",
"artifact_uri": f"{GCS_BUCKET}/{LOCAL_MODEL_DIR}",
"container_spec": {
"image_uri": "us-docker.pkg.dev/vertex-ai/prediction/tf2-gpu.2-8:latest",
},
}
tf28_gpu_model = (
model_service_client.upload_model(parent=PARENT, model=tf28_gpu_model_dict)
.result(timeout=180)
.model
)
我們來逐一分析程式碼:
GCS_BUCKET表示您的 GCS 儲存桶的路徑,其中儲存了模型工件(例如,gs://hf-tf-vision)。在
container_spec中,您提供一個 Docker 映象的 URI,該映象將用於提供預測服務。Vertex AI 提供預構建映象來服務 TensorFlow 模型,但您也可以在使用不同框架時使用自定義 Docker 映象(示例)。model_service_client是一個ModelServiceClient物件,它公開了將模型上傳到 Vertex AI 模型登錄檔的方法。PARENT被設定為f"projects/{PROJECT_ID}/locations/{REGION}",它允許 Vertex AI 確定模型在 GCP 內部的範圍。
2. 接下來您需要建立一個 Vertex AI 端點:
tf28_gpu_endpoint_dict = {
"display_name": "ViT Base TF2.8 GPU endpoint",
}
tf28_gpu_endpoint = (
endpoint_service_client.create_endpoint(
parent=PARENT, endpoint=tf28_gpu_endpoint_dict
)
.result(timeout=300)
.name
)
在這裡,您使用的是 endpoint_service_client,它是一個 EndpointServiceClient 物件。它允許您建立和配置 Vertex AI 端點。
3. 現在您要執行實際的部署了!
tf28_gpu_deployed_model_dict = {
"model": tf28_gpu_model,
"display_name": "ViT Base TF2.8 GPU deployed model",
"dedicated_resources": {
"min_replica_count": 1,
"max_replica_count": 1,
"machine_spec": {
"machine_type": DEPLOY_COMPUTE, # "n1-standard-8"
"accelerator_type": DEPLOY_GPU, # aip.AcceleratorType.NVIDIA_TESLA_T4
"accelerator_count": 1,
},
},
}
tf28_gpu_deployed_model = endpoint_service_client.deploy_model(
endpoint=tf28_gpu_endpoint,
deployed_model=tf28_gpu_deployed_model_dict,
traffic_split={"0": 100},
).result()
在這裡,您將上傳到 Vertex AI 模型登錄檔的模型與您在上述步驟中建立的端點連結在一起。您首先在 tf28_gpu_deployed_model_dict 下定義部署的配置。
在 dedicated_resources 下,您正在配置:
min_replica_count和max_replica_count處理您部署的自動擴縮方面。machine_spec允許您定義部署硬體的配置:machine_type是用於執行 Docker 映象的基礎機器型別。底層自動縮放器將根據流量負載對此機器進行縮放。您可以從支援的機器型別中選擇一個。accelerator_type是將用於執行推理的硬體加速器。accelerator_count表示要連線到每個副本的硬體加速器數量。
請注意,提供加速器並非在 Vertex AI 上部署模型的必需條件。
接下來,您將使用上述規範部署端點:
tf28_gpu_deployed_model = endpoint_service_client.deploy_model(
endpoint=tf28_gpu_endpoint,
deployed_model=tf28_gpu_deployed_model_dict,
traffic_split={"0": 100},
).result()
請注意您如何定義模型的流量分割。如果您有多個版本的模型,您可以定義一個字典,其中鍵表示模型版本,值表示模型應該服務的流量百分比。
透過模型登錄檔和管理端點的專用介面,Vertex AI 可以讓您輕鬆控制部署的重要方面。
Vertex AI 大約需要 15 到 30 分鐘來確定部署範圍。完成後,您應該能夠在控制檯上看到它。
執行預測
如果您的部署成功,您可以透過發出預測請求來測試已部署的端點。
首先,準備一個 base64 編碼的影像字串:
import base64
import tensorflow as tf
image_path = tf.keras.utils.get_file(
"image.jpg", "http://images.cocodataset.org/val2017/000000039769.jpg"
)
bytes = tf.io.read_file(image_path)
b64str = base64.b64encode(bytes.numpy()).decode("utf-8")
4. 下面的實用程式首先準備一個例項列表(本例中只有一個例項),然後使用預測服務客戶端(型別為PredictionServiceClient)。serving_input 是已服務模型的輸入簽名鍵的名稱。在這種情況下,serving_input 是 string_input,您可以從上面顯示的 SavedModel 簽名輸出中驗證。
from google.protobuf import json_format
from google.protobuf.struct_pb2 import Value
def predict_image(image, endpoint, serving_input):
# The format of each instance should conform to
# the deployed model's prediction input schema.
instances_list = [{serving_input: {"b64": image}}]
instances = [json_format.ParseDict(s, Value()) for s in instances_list]
print(
prediction_service_client.predict(
endpoint=endpoint,
instances=instances,
)
)
predict_image(b64str, tf28_gpu_endpoint, serving_input)
對於部署在 Vertex AI 上的 TensorFlow 模型,請求負載需要以特定方式格式化。對於處理影像等二進位制資料的模型(如 ViT),它們需要經過 base64 編碼。根據官方指南,每個例項的請求負載需要如下所示:
{serving_input: {"b64": base64.b64encode(jpeg_data).decode()}}
predict_image() 實用程式根據此規範準備請求負載。
如果部署一切順利,當您呼叫 predict_image() 時,您應該會得到如下輸出:
predictions {
struct_value {
fields {
key: "confidence"
value {
number_value: 0.896659553
}
}
fields {
key: "label"
value {
string_value: "Egyptian cat"
}
}
}
}
deployed_model_id: "5163311002082607104"
model: "projects/29880397572/locations/us-central1/models/7235960789184544768"
model_display_name: "ViT Base TF2.8 GPU model"
然而,請注意,這並非獲取使用 Vertex AI 端點進行預測的唯一方法。如果您前往端點控制檯並選擇您的端點,它將顯示兩種不同的獲取預測的方法:
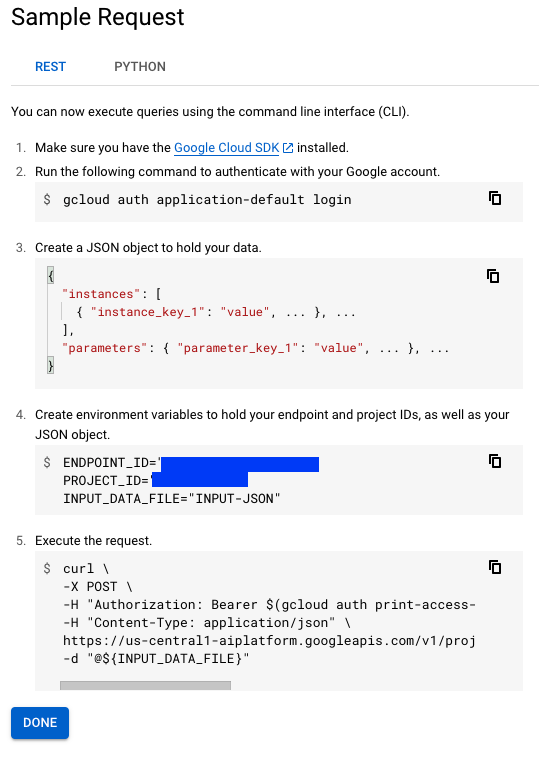
也可以避免 cURL 請求,並在不使用 Vertex AI SDK 的情況下以程式設計方式獲取預測。請參閱此筆記本以瞭解更多資訊。
既然您已經瞭解瞭如何使用 Vertex AI 部署 TensorFlow 模型,那麼現在讓我們討論一下 Vertex AI 提供的一些有益功能。這些功能可幫助您更深入地瞭解您的部署。
使用 Vertex AI 進行監控
Vertex AI 還允許您在沒有任何配置的情況下監控您的模型。從端點控制檯,您可以獲取有關端點效能和分配資源利用率的詳細資訊。
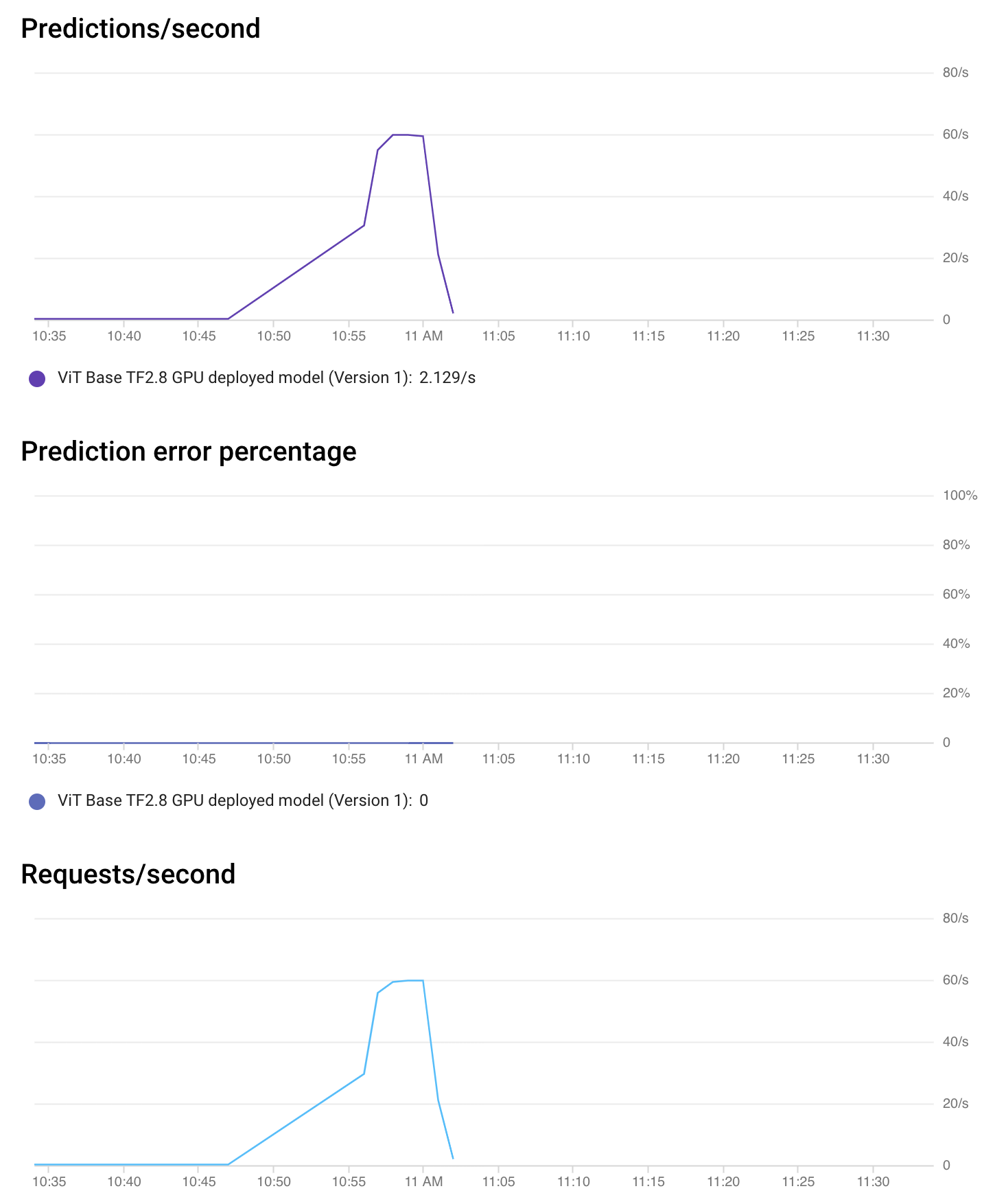
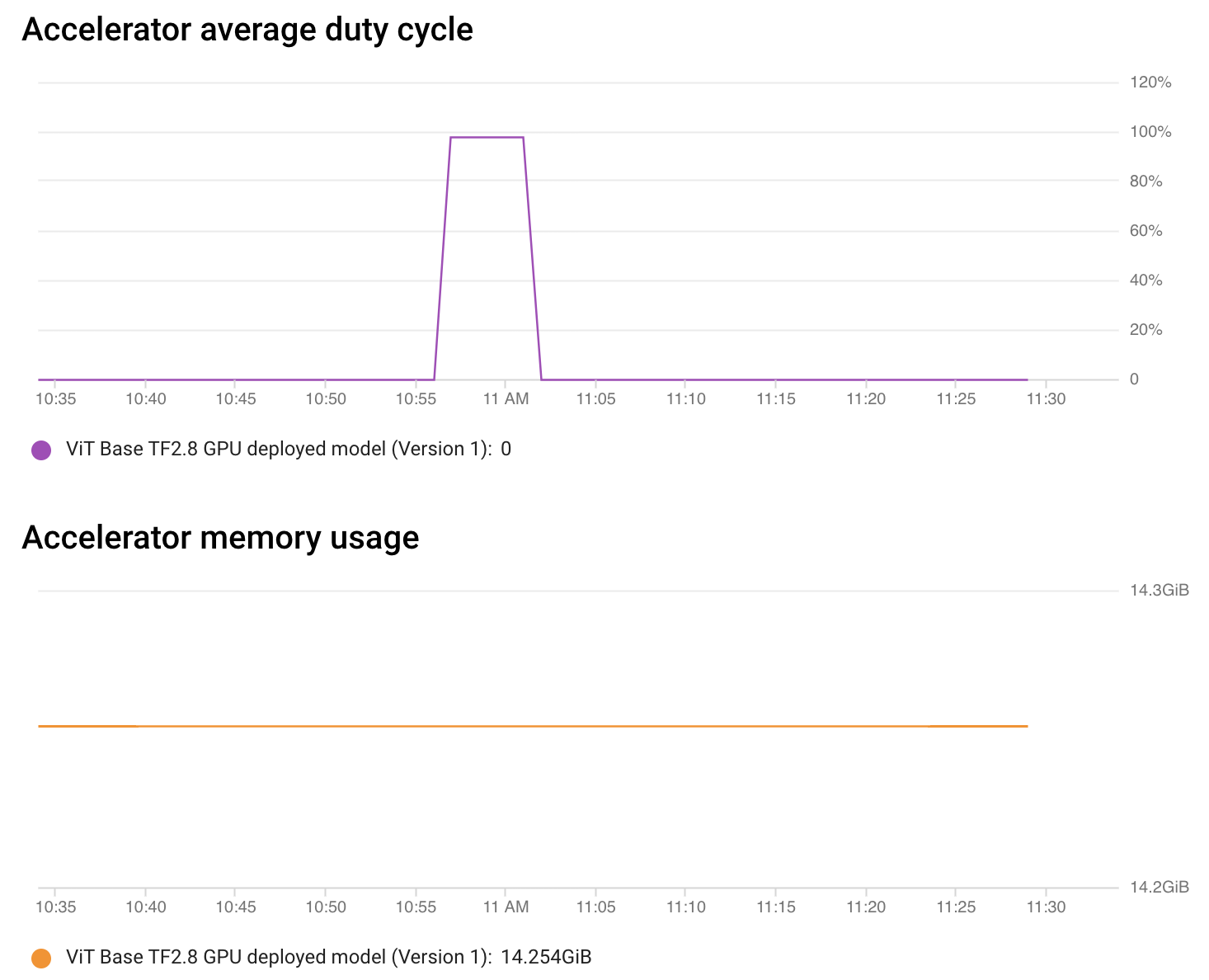
如上圖所示,在短時間內,加速器負載(利用率)約為 100%,這令人賞心悅目。其餘時間,沒有請求需要處理,因此一切都處於空閒狀態。
這種型別的監控有助於您快速標記當前部署的端點並根據需要進行調整。也可以請求監控模型解釋。請參閱此處瞭解更多資訊。
本地負載測試
我們使用 Locust 進行了本地負載測試,以更好地瞭解端點的限制。下表總結了請求統計資訊:

在表中顯示的所有不同統計資料中,平均值 (ms) 指的是端點的平均延遲。Locust 發起了大約 17230 個請求,報告的平均延遲為 646 毫秒,這令人印象深刻。在實踐中,您會希望透過分散式方式進行負載測試來模擬更真實的流量。請參閱此處瞭解更多資訊。
此目錄包含了解我們如何進行負載測試所需的所有資訊。
定價
您可以使用GCP 費用估算器來估算使用成本,精確的小時定價表可在此處找到。值得注意的是,您僅在節點處理實際預測請求時才被收費,並且您需要計算帶 GPU 和不帶 GPU 的價格。
對於自定義訓練模型的 Vertex Prediction,我們可以選擇從 n1-standard-2 到 n1-highcpu-32 的 N1 機器型別。本文中使用了 n1-standard-8,它配備了 8 個 vCPU 和 32GB 記憶體。
| 機器型別 | 每小時價格 (美元) |
|---|---|
| n1-standard-8 (8vCPU, 30GB) | $ 0.4372 |
此外,當您將加速器連線到計算節點時,將根據您想要的加速器型別額外收費。我們在本部落格文章中使用了 NVIDIA_TESLA_T4,但幾乎所有現代加速器,包括 TPU 都支援。您可以在此處找到更多資訊。
| 加速器型別 | 每小時價格 (美元) |
|---|---|
| NVIDIA_TESLA_T4 | $ 0.4024 |
行動呼籲
🤗 Transformers 中的 TensorFlow 視覺模型集合正在不斷壯大。它現在支援使用 SegFormer 實現最先進的語義分割。我們鼓勵您將本文中學到的部署工作流程擴充套件到 SegFormer 等語義分割模型。
結論
在本文中,您學習瞭如何使用 Vertex AI 平臺提供的易用 API 部署視覺 Transformer 模型。您還了解了 Vertex AI 的功能如何透過讓您專注於宣告性配置並消除複雜部分來使模型部署過程受益。Vertex AI 還透過自定義預測路由支援 PyTorch 模型的部署。請參閱此處瞭解更多詳情。
該系列首先向您介紹了 TensorFlow Serving,用於在本地部署 🤗 Transformers 中的視覺模型。在第二篇文章中,您學習瞭如何使用 Docker 和 Kubernetes 擴充套件該本地部署。我們希望本系列關於 TensorFlow 視覺模型線上部署的文章對您將機器學習工具箱提升到新水平有所幫助。我們迫不及待地想看看您使用這些工具能構建出什麼。
致謝
感謝 Google 機器學習開發者關係專案團隊為我們提供 GCP 積分,用於進行實驗。

