專家支援案例研究:利用 LLM 充當“評委”來增強 RAG 應用程式










這是一篇由 Digital Green 撰寫的客座部落格文章。Digital Green 正在參與一項由 CGIAR 牽頭、旨在為小農提供農業支援的合作專案。
全球估計有 5 億小農:他們在全球糧食安全中發揮著關鍵作用。及時獲取準確資訊對於這些農民做出明智決策和提高產量至關重要。
“農業推廣服務”為農民提供農業技術諮詢,併為他們提供支援農業生產所需的投入和服務。
僅印度就有 30 萬農業推廣員,他們提供有關改進農業實踐的必要資訊,並幫助小農做出決策。
然而,儘管他們的數量令人印象深刻,但推廣人員的數量不足以應對所有需求:他們與農民的互動比例通常為 1:1000。透過合作和技術接觸農業推廣員和農民仍然是關鍵。
“GAIA 專案”應運而生,這是一個由 CGIAR 首創的合作倡議。
它透過 將 Hugging Face 匯聚為導師,並將 Digital Green 匯聚為專案合作伙伴。
GAIA 的崇高目標是將 GARDIAN 門戶 中精心維護的多年農業知識以研究論文的形式帶到農民手中。全球有近 46000 篇農業研究論文和報告,涵蓋了數十年來的不同作物。
Digital Green 立即看到了在批准的、精選的資訊上開發由檢索增強生成 (RAG) 提供支援的智慧聊天機器人的潛力。因此,他們決定開發 Farmer.chat,這是一個利用大型語言模型 (LLM) 的能力,為農民和一線推廣員提供個性化、可靠的農業建議的聊天機器人。
為各種語言、地理、作物和用例建立這樣一個聊天機器人是一項巨大的挑戰:傳播的資訊必須符合當地農場的具體情況,使用農民能理解的語言和語氣,並且準確(基於可靠來源),以便農民可以根據其採取行動。為了評估系統的效能,CGIAR 團隊和 HF 專家合作建立了一套強大的評估套件,即一個 LLM 充當“評委”的系統。
讓我們看看他們是如何應對這一挑戰的!
系統架構
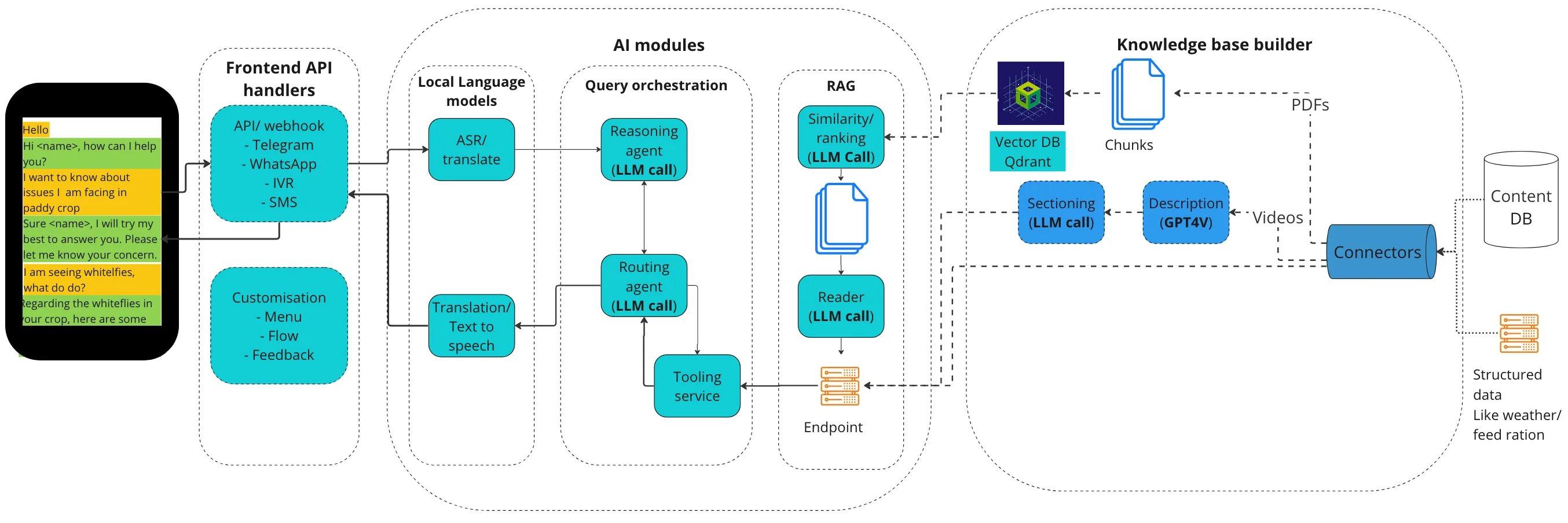
整個系統使用了許多元件,以便提供基於多種工具和外部知識的聊天機器人答案。它有幾個關鍵要素
- 知識庫
- 預處理:第一步是在 Scio 維護的 API 的幫助下,將 PDF 文件攝取到 Farmer.chat 管道中。在知識庫中,主題會自動分類到相關的地理區域並進行語義分組。
- 語義分塊:將整理好的帶有元資料的檔案進行處理,將意思相似的句子分組到文字塊中。該函式目前使用小文字嵌入進行餘弦相似度計算。
- 轉換為 VectorDB 格式:每個文字塊使用嵌入模型轉換為向量表示,然後將向量表示儲存在 QdrantDB 中。
- RAG 管道:它確保所傳遞的資訊基於內容而非外部來源。它包含兩部分:
- 資訊檢索:在知識庫中搜索與使用者查詢相關的匹配資訊。這涉及呼叫知識庫構建器中建立的向量資料庫 API,以獲取必要的文字塊。
- 生成:利用檢索到的文字塊資訊和使用者查詢,生成器呼叫 LLM 並生成類似人類的響應,以滿足使用者的需求。
- 面向使用者的代理:規劃代理底層使用了 GPT-4o。
- 它的任務是:
- 理解使用者意圖
- 根據使用者意圖和工具描述決定需要哪些更多資訊
- 向用戶詢問該資訊,直到請求明確
- 請求明確後,呼叫執行代理
- 從執行代理獲取響應並生成響應
- 該代理執行基於 ReAct 的提示,以逐步思考並呼叫相應的工具和分析響應。然後它可以利用其工具進行回答:目前,該代理使用以下工具集:
- 繼續對話
- RAG 問答端點
- 影片檢索端點
- 天氣端點
- 作物表格
- 它的任務是:
這個系統有許多運動部件,每個部件都對效能的某些方面產生根本性影響。因此,我們需要仔細進行效能評估。
在過去一年中,Farmer.chat 的使用量已增長到為超過 2 萬名農民提供服務,處理超過 34 萬個查詢。我們如何評估系統在這種規模下的效能?
在每週的頭腦風暴會議中,Hugging Face 提到了 LLM 作為“評委”,並提供了其筆記本 LLM as a Judge 的連結。這一資源經過詳細討論,隨後形成了一種實踐,有助於指導 Farmer.chat 的開發。
LLM 充當“評委”的力量
Farmer.Chat 採用複雜的檢索增強生成(RAG)管道,為農民提供基於知識庫的準確和相關資訊。RAG 管道使用 LLM 從龐大的知識庫中檢索資訊,然後生成簡潔明瞭的響應。
但我們如何衡量這個管道的有效性呢?
這裡的難點在於,沒有一個確定性的指標可以用來評估答案的質量、簡潔性、精確性……
這就是 **LLM 充當“評委”** 技術介入的地方。這個想法很簡單:讓 LLM 根據任何指標來評分輸出。其巨大的優勢在於,指標可以是任何東西:LLM 充當“評委”具有極強的通用性。
例如,您可以使用它來評估提示的清晰度,如下所示:
You will be given a user input about agriculture, and your task is to score it on various aspects.
Think step by step and rate the user input on all three following criteria and give a score for each:
1) The intent and ask is clear.
2) The topic is well-specified.
3) The target entity is well-specified, as well as its attributes, for instance "disease resistant" or "high yield".
You should give your scores on an integer scale of 1 to 3, 1 being the worst and 3 the best score.
After creating a score for each three, take the average and round it off to the nearest integer which becomes the final score.
Example:
User input: "tell the benefits of batian coffee variety"
Criterion 1: scores 3, as the intent is clear (about knowing about batian variety of coffee) and the ask is clear (want to summarize the benefits).
Criterion 2: scores 3, the topic is well specified (coffee varieties)
Criterion 3: scores 2, as the entity is clear (batian variety) but not the attributes.
如我們前面提到的 這篇文章 所述,使用 LLM 作為“評委”的關鍵是明確定義任務、標準和整數評分量表。
Farmer.Chat 的研究團隊利用 LLM 的能力來評估幾個關鍵指標:
- 提示清晰度:此指標評估使用者表達問題的清晰程度。LLM 經過訓練,可以評估使用者意圖的清晰度、主題特異性和實體屬性識別,從而深入瞭解使用者如何有效地溝通其需求。
- 問題型別:此指標根據其認知複雜性將使用者問題分為不同類別。LLM 分析使用者的查詢並將其分配到六個類別之一,例如“記憶”、“理解”、“應用”、“分析”、“評估”和“建立”,幫助我們瞭解使用者互動的認知需求。
- 已回答查詢:此指標跟蹤聊天機器人回答問題的百分比,提供有關知識庫廣度和平臺處理各種查詢能力的資訊。
- RAG 準確性:此指標評估 RAG 管道檢索資訊的忠實度和相關性。LLM 充當“評委”,將檢索到的資訊與使用者查詢進行比較,並評估響應是否準確和相關。
它使我們能夠超越簡單地衡量聊天機器人能回答多少問題或響應速度。相反,我們可以更深入地研究響應的質量,並以更細緻的方式理解使用者體驗。
對於 RAG 準確性,我們使用 LLM 充當“評委”在二元尺度上進行評估:0 或 1。但是,任務分解的方式形成了一個完善的過程,得出的分數我們已經用人工評估員對大約 360 個問題進行了測試:結果發現 LLM 的回答確實做得很好,並且與人工評估具有高度相關性!
這是提示,它受到 RAGAS 庫的啟發。
You are a natural language inference engine. You will be presented with a set of factual statements and context. You are supposed to analyze if each statement is factually correct given the context. You can come up with the scores of 'Yes' (1) and 'No' (0) as verdict.
Use the following rules:
If the statement can be derived from the context, give a score of 1.
If there is no statement and there is no context, give a score of 1.
If the statement can’t be derived from the context, give a score of 0.
If there is no context but there is a statement, give a score of 0.
#### Input :
Context : {context}
Statements : {statements}
上面的上下文變數是用於生成答案的輸入塊,而語句是另一個 LLM 呼叫生成的原子事實語句。
這是非常重要的一步,因為它支援大規模評估,這在處理大量文件和查詢時非常重要。LLM 充當“評委”最終會產生指標,這些指標就像指南針一樣,引導我們選擇 AI 管道的各種可用選項。
結果:RAG 的 LLM 基準測試
我們建立了一個包含 700 多個使用者查詢的樣本資料集,這些查詢隨機分佈在不同的價值鏈(作物)和日期(月份)中。雖然此升級本身有 11 個不同的版本,並使用 RAG 準確性和已回答百分比進行評估,但同一方法也用於測量領先 LLM 的效能,且每次 LLM 呼叫中不更改任何提示。在此實驗中,我們選擇了 OpenAI 的 GPT-4-Turbo、Gemini-1.5 的 Pro 和 Flash 版本,以及 Llama-3-70B-Instruct。
| 大型語言模型 | 忠實 | 相關 | 已回答 * 相關 | 已回答 * 忠實 | 未回答 |
|---|---|---|---|---|---|
| GPT-4-turbo | 88% | 75% | 59% | 69% | 21.9% |
| Llama-3-70B | 78% | 76% | 76% | 78% | 0.3% |
| Gemini-1.5-Pro | 91% | 88% | 71% | 73% | 19.4% |
| Gemini-1.5-Flash | 89% | 78% | 74 % | 85% | 4.5% |
我們看到,在四個模型中,Gemini-1.5-pro 獲得了最高的事實正確答案(“忠實”列),緊隨其後的是 Gemini-1.5-Flash 和 GPT-4-turbo。
我們發現,僅從忠實度來看,Gemini-1.5-Pro 勝過其他模型。但如果我們也考慮模型接受回答的問題百分比,Llama-3-70B 和 Gemini-1.5-Flash 表現更好。
最終,我們選擇了 Gemini-1.5-Flash,因為它在未回答問題百分比低和忠實度極高之間取得了卓越的平衡。
結論
透過利用 LLM 充當“評委”,我們能更深入地瞭解使用者行為以及 AI 驅動工具在農業背景下的有效性。這種資料驅動的方法對於以下方面至關重要:
- 改善使用者體驗:透過識別使用者難以清晰表達需求或 RAG 管道表現不佳的領域,我們可以改進平臺的設計和功能。
- 最佳化知識庫:對未回答查詢的分析有助於我們識別知識庫中的空白並優先進行內容開發。
- 選擇正確的 LLM:透過對不同 LLM 在關鍵指標上進行基準測試,我們可以就哪些模型最適合特定任務和上下文做出明智的決策。
LLM 能夠充當“評委”來評估 AI 系統的效能,這是一項顛覆性的能力。它使我們能夠以更客觀、資料驅動的方式衡量這些系統的影響,最終促進開發出更健壯、更有效、更使用者友好的農業 AI 工具。
在一年多的時間裡,我們不斷改進產品。在如此短的時間內,我們已經能夠:
- 覆蓋超過 2 萬名農民
- 回答超過 34 萬個問題
- 為 6 種以上語言、50 種價值鏈作物提供服務
- 保持幾乎零偏見或有害回覆
最近在 這篇科學文章 中發表了結果,重點是使用者研究的定量研究。
.gif)
如果您對貴公司的 Hugging Face 專家支援計劃感興趣,請隨時點選此處聯絡我們——我們的銷售團隊將與您聯絡,討論您的需求!






