使用 🤗 Transformers 對英文 ASR 進行 Wav2Vec2 微調







Wav2Vec2 是一種用於自動語音識別 (ASR) 的預訓練模型,由 Alexei Baevski、Michael Auli 和 Alex Conneau 於 2020 年 9 月釋出。
Wav2Vec2 使用新穎的對比預訓練目標,從超過 50,000 小時的未標記語音中學習強大的語音表示。類似於 BERT 的掩碼語言建模,該模型透過在將特徵向量傳遞給 transformer 網路之前隨機掩碼它們來學習上下文語音表示。
首次證明,預訓練後,在少量標記語音資料上進行微調可以達到與最先進的 ASR 系統相媲美的結果。僅使用 10 分鐘的標記資料,Wav2Vec2 在 LibriSpeech 的純淨測試集上實現了低於 5% 的詞錯誤率 (WER) - 參見 論文表 9。
在本筆記本中,我們將詳細解釋如何對任何英文 ASR 資料集微調 Wav2Vec2 的預訓練檢查點。請注意,在本筆記本中,我們將在不使用語言模型的情況下微調 Wav2Vec2。不使用語言模型作為端到端 ASR 系統使用 Wav2Vec2 要簡單得多,並且已證明獨立的 Wav2Vec2 聲學模型取得了令人印象深刻的結果。出於演示目的,我們對大小為“base”的預訓練檢查點在相對較小的 Timit 資料集上進行微調,該資料集僅包含 5 小時的訓練資料。
Wav2Vec2 使用連線時序分類 (CTC) 進行微調,這是一種用於訓練神經網路解決序列到序列問題(主要在自動語音識別和手寫識別中)的演算法。
我強烈推薦閱讀 Awni Hannun 撰寫的寫得非常好的部落格文章 Sequence Modeling with CTC (2017)。
在開始之前,讓我們從 master 安裝 datasets 和 transformers。此外,我們需要 soundfile 包來載入音訊檔案,以及 jiwer 來使用 詞錯誤率 (WER) 指標 評估我們微調的模型。
!pip install datasets>=1.18.3
!pip install transformers==4.11.3
!pip install librosa
!pip install jiwer
接下來,我們強烈建議在訓練期間將您的訓練檢查點直接上傳到 Hugging Face Hub。Hub 集成了版本控制,因此您可以確保在訓練期間不會丟失任何模型檢查點。
為此,您必須儲存來自 Hugging Face 網站的身份驗證令牌(如果您尚未註冊,請在此處註冊!)。
from huggingface_hub import notebook_login
notebook_login()
列印輸出
Login successful
Your token has been saved to /root/.huggingface/token
Authenticated through git-crendential store but this isn't the helper defined on your machine.
You will have to re-authenticate when pushing to the Hugging Face Hub. Run the following command in your terminal to set it as the default
git config --global credential.helper store
然後您需要安裝 Git-LFS 才能上傳您的模型檢查點
!apt install git-lfs
Timit 通常使用音素錯誤率 (PER) 進行評估,但到目前為止,ASR 中最常見的指標是詞錯誤率 (WER)。為了使本筆記本儘可能通用,我們決定使用 WER 評估模型。
準備資料、分詞器、特徵提取器
ASR 模型將語音轉寫為文字,這意味著我們既需要一個將語音訊號處理成模型輸入格式(例如特徵向量)的特徵提取器,也需要一個將模型輸出格式處理成文字的分詞器。
在 🤗 Transformers 中,Wav2Vec2 模型因此附帶了一個分詞器,稱為 Wav2Vec2CTCTokenizer,以及一個特徵提取器,稱為 Wav2Vec2FeatureExtractor。
讓我們從建立負責解碼模型預測的分詞器開始。
建立 Wav2Vec2CTCTokenizer
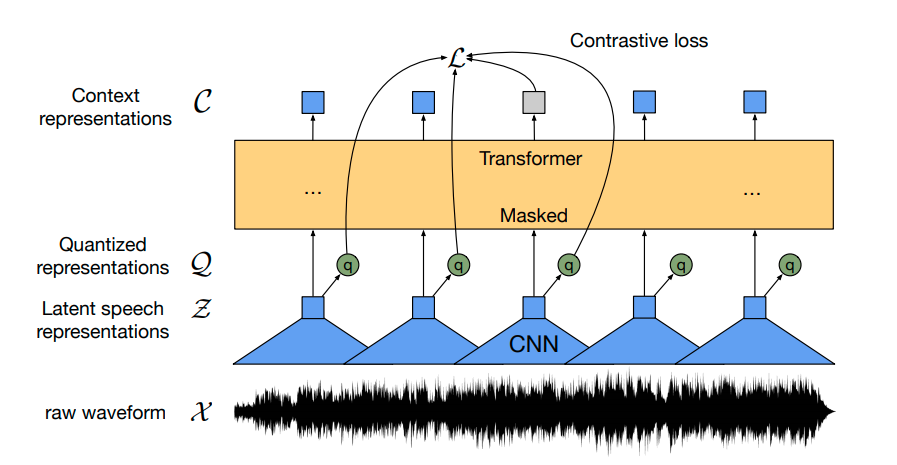
預訓練的 Wav2Vec2 檢查點將語音訊號對映到一系列上下文表示,如上圖所示。微調的 Wav2Vec2 檢查點需要將這一系列上下文表示對映到其對應的轉錄,因此必須在 transformer 塊(黃色所示)之上新增一個線性層。該線性層用於將每個上下文表示分類為一個標記類,類似於,例如,在預訓練後,在 BERT 的嵌入之上新增一個線性層以進行進一步分類 - 參見 這篇部落格文章的“BERT”部分。
此層的輸出大小對應於詞彙表中的標記數量,這**不**取決於 Wav2Vec2 的預訓練任務,而僅取決於用於微調的標記資料集。因此,第一步,我們將檢視 Timit 並根據資料集的轉錄定義詞彙表。
讓我們從載入資料集並檢視其結構開始。
from datasets import load_dataset, load_metric
timit = load_dataset("timit_asr")
print(timit)
列印輸出
DatasetDict({
train: Dataset({
features: ['file', 'audio', 'text', 'phonetic_detail', 'word_detail', 'dialect_region', 'sentence_type', 'speaker_id', 'id'],
num_rows: 4620
})
test: Dataset({
features: ['file', 'audio', 'text', 'phonetic_detail', 'word_detail', 'dialect_region', 'sentence_type', 'speaker_id', 'id'],
num_rows: 1680
})
})
許多 ASR 資料集僅提供每個音訊檔案 'file' 的目標文字 'text'。Timit 實際上提供了關於每個音訊檔案的更多資訊,例如 'phonetic_detail' 等,這就是為什麼許多研究人員在處理 Timit 時選擇評估他們的模型在音素分類而不是語音識別方面的原因。但是,我們希望使筆記本儘可能通用,因此我們只考慮用於微調的轉錄文字。
timit = timit.remove_columns(["phonetic_detail", "word_detail", "dialect_region", "id", "sentence_type", "speaker_id"])
讓我們寫一個簡短的函式來顯示資料集的一些隨機樣本,並執行幾次以感受一下轉寫文字的特點。
from datasets import ClassLabel
import random
import pandas as pd
from IPython.display import display, HTML
def show_random_elements(dataset, num_examples=10):
assert num_examples <= len(dataset), "Can't pick more elements than there are in the dataset."
picks = []
for _ in range(num_examples):
pick = random.randint(0, len(dataset)-1)
while pick in picks:
pick = random.randint(0, len(dataset)-1)
picks.append(pick)
df = pd.DataFrame(dataset[picks])
display(HTML(df.to_html()))
show_random_elements(timit["train"].remove_columns(["file", "audio"]))
列印輸出
| 索引 | 轉錄 |
|---|---|
| 1 | 誰把皮划艇帶到了河口? |
| 2 | 因此,它充當人們的錨。 |
| 3 | 她一整年都把你的深色西裝放在油膩的洗滌水中。 |
| 4 | 我們不是酒鬼,她說。 |
| 5 | 最近的地質調查發現了地震活動。 |
| 6 | 贍養費損害了離婚男子的財富。 |
| 7 | 我們的整個經濟將得到巨大的提升。 |
| 8 | 別讓我帶著那樣的油膩抹布。 |
| 9 | 華麗的蝴蝶吃了大量的花蜜。 |
| 10 | 你要帶我去哪兒? |
好的!轉錄看起來非常乾淨,語言似乎更像是書面文字而不是對話。考慮到 Timit 是一個朗讀語音語料庫,這很有道理。
我們可以看到轉錄中包含一些特殊字元,例如 ,.?!;:。如果沒有語言模型,將語音塊分類為這些特殊字元要困難得多,因為它們實際上不對應於特徵聲音單元。例如,字母 "s" 有一個或多或少清晰的聲音,而特殊字元 "." 則沒有。此外,為了理解語音訊號的含義,通常不需要在轉錄中包含特殊字元。
此外,我們將文字標準化為僅包含小寫字母。
import re
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"]'
def remove_special_characters(batch):
batch["text"] = re.sub(chars_to_ignore_regex, '', batch["text"]).lower()
return batch
timit = timit.map(remove_special_characters)
讓我們看一下預處理後的轉錄。
show_random_elements(timit["train"].remove_columns(["file", "audio"]))
列印輸出
| 索引 | 轉錄 |
|---|---|
| 1 | 總之,是時候給男孩加鹽了 |
| 2 | 他們的基礎似乎比單純的權威更深 |
| 3 | 只有最好的球員才受歡迎 |
| 4 | 龍捲風經常摧毀數英畝的農田 |
| 5 | 你要帶我去哪兒 |
| 6 | 感受當地風情 |
| 7 | 衛星 人造衛星 火箭 氣球 下一個是什麼 |
| 8 | 我給了他們幾個選擇,讓他們自己設定優先順序 |
| 9 | 在光線不足的地方閱讀會讓你眼睛疲勞 |
| 10 | 那隻狗無情地追逐貓 |
很好!這看起來好多了。我們已經從轉錄中刪除了大部分特殊字元,並將其規範化為全小寫。
在 CTC 中,通常將語音塊分類為字母,所以我們在這裡也這樣做。讓我們提取訓練和測試資料中所有不同的字母,並從這個字母集合構建我們的詞彙表。
我們編寫一個對映函式,將所有轉錄連線成一個長轉錄,然後將字串轉換為一組字元。重要的是將引數 batched=True 傳遞給 map(...) 函式,以便對映函式可以一次訪問所有轉錄。
def extract_all_chars(batch):
all_text = " ".join(batch["text"])
vocab = list(set(all_text))
return {"vocab": [vocab], "all_text": [all_text]}
vocabs = timit.map(extract_all_chars, batched=True, batch_size=-1, keep_in_memory=True, remove_columns=timit.column_names["train"])
現在,我們建立訓練集和測試集中所有不同字母的並集,並將結果列表轉換為一個帶索引的字典。
vocab_list = list(set(vocabs["train"]["vocab"][0]) | set(vocabs["test"]["vocab"][0]))
vocab_dict = {v: k for k, v in enumerate(vocab_list)}
vocab_dict
列印輸出
{
' ': 21,
"'": 13,
'a': 24,
'b': 17,
'c': 25,
'd': 2,
'e': 9,
'f': 14,
'g': 22,
'h': 8,
'i': 4,
'j': 18,
'k': 5,
'l': 16,
'm': 6,
'n': 7,
'o': 10,
'p': 19,
'q': 3,
'r': 20,
's': 11,
't': 0,
'u': 26,
'v': 27,
'w': 1,
'x': 23,
'y': 15,
'z': 12
}
很酷,我們看到字母表中的所有字母都出現在資料集中(這並不奇怪),而且我們還提取了特殊字元 " " 和 '。請注意,我們沒有排除這些特殊字元,因為
- 模型必須學會預測何時一個單詞結束,否則模型的預測將始終是一串字元,這將使得單詞之間無法分離。
- 在英語中,我們需要保留
'字元來區分單詞,例如,"it's"和"its",它們具有非常不同的含義。
為了更清楚地表明 " " 有其自己的標記類別,我們給它一個更明顯的字元 |。此外,我們還添加了一個“未知”標記,以便模型以後可以處理在 Timit 訓練集中未遇到的字元。
vocab_dict["|"] = vocab_dict[" "]
del vocab_dict[" "]
最後,我們還添加了一個與 CTC 的“空白標記”相對應的填充標記。“空白標記”是 CTC 演算法的核心元件。欲瞭解更多資訊,請參閱此處的“對齊”部分。
vocab_dict["[UNK]"] = len(vocab_dict)
vocab_dict["[PAD]"] = len(vocab_dict)
print(len(vocab_dict))
列印輸出
30
酷,現在我們的詞彙表已完成,包含 30 個標記,這意味著我們將新增到預訓練 Wav2Vec2 檢查點之上的線性層將具有 30 的輸出維度。
現在讓我們將詞彙表儲存為 json 檔案。
import json
with open('vocab.json', 'w') as vocab_file:
json.dump(vocab_dict, vocab_file)
最後一步,我們使用 JSON 檔案例項化一個 Wav2Vec2CTCTokenizer 類的物件。
from transformers import Wav2Vec2CTCTokenizer
tokenizer = Wav2Vec2CTCTokenizer("./vocab.json", unk_token="[UNK]", pad_token="[PAD]", word_delimiter_token="|")
如果想將剛剛建立的分詞器與本筆記本中微調的模型重複使用,強烈建議將 tokenizer 上傳到 🤗 Hub。我們將上傳檔案的倉庫命名為 "wav2vec2-large-xlsr-turkish-demo-colab"
repo_name = "wav2vec2-base-timit-demo-colab"
然後將分詞器上傳到 🤗 Hub。
tokenizer.push_to_hub(repo_name)
太棒了,您可以在 https://huggingface.co/<your-username>/wav2vec2-base-timit-demo-colab 找到剛剛建立的倉庫
建立 Wav2Vec2 特徵提取器
語音是一種連續訊號,要由計算機處理,首先必須將其離散化,這通常稱為**取樣**。取樣率在此起著重要作用,因為它定義了每秒測量多少語音訊號資料點。因此,更高的取樣率會導致對*真實*語音訊號的更好近似,但每秒也需要更多值。
預訓練檢查點期望其輸入資料以或多或少與訓練資料相同的分佈進行取樣。以兩種不同速率取樣的相同語音訊號具有非常不同的分佈,例如,取樣率加倍會導致資料點長度加倍。因此,在對 ASR 模型的預訓練檢查點進行微調之前,驗證用於預訓練模型的資料的取樣率是否與用於微調模型的資料集的取樣率匹配至關重要。
Wav2Vec2 在 LibriSpeech 和 LibriVox 的音訊資料上進行預訓練,它們都以 16kHz 取樣。我們的微調資料集 Timit 也很幸運地以 16kHz 取樣。如果微調資料集以低於或高於 16kHz 的速率取樣,我們首先必須對語音訊號進行上取樣或下采樣,以匹配用於預訓練的資料的取樣率。
Wav2Vec2 特徵提取器物件需要以下引數來例項化
feature_size:語音模型將特徵向量序列作為輸入。雖然此序列的長度顯然不同,但特徵大小不應改變。對於 Wav2Vec2,特徵大小為 1,因為模型在原始語音訊號上進行了訓練 。sampling_rate: 模型訓練時使用的取樣率。padding_value:對於批次推理,較短的輸入需要用特定值填充。do_normalize:輸入是否應該進行零均值單位方差歸一化。通常,語音模型在歸一化輸入後表現更好。return_attention_mask:模型是否應該在批次推理中使用attention_mask。通常,模型應該**始終**使用attention_mask來掩蓋填充的標記。然而,由於Wav2Vec2的“base”檢查點的一個非常特殊的設計選擇,在不使用attention_mask時可以獲得更好的結果。這**不**建議用於其他語音模型。欲瞭解更多資訊,請參閱此問題。**重要**:如果要使用此筆記本微調large-lv60,則此引數應設定為True。
from transformers import Wav2Vec2FeatureExtractor
feature_extractor = Wav2Vec2FeatureExtractor(feature_size=1, sampling_rate=16000, padding_value=0.0, do_normalize=True, return_attention_mask=False)
太棒了,Wav2Vec2 的特徵提取管道由此完全定義!
為了使 Wav2Vec2 的使用盡可能方便使用者,特徵提取器和分詞器被包裝到單個 Wav2Vec2Processor 類中,這樣只需要一個 model 和 processor 物件。
from transformers import Wav2Vec2Processor
processor = Wav2Vec2Processor(feature_extractor=feature_extractor, tokenizer=tokenizer)
資料預處理
到目前為止,我們還沒有檢視語音訊號的實際值,只查看了轉錄。除了句子之外,我們的資料集還包含另外兩個列名:路徑和音訊。路徑表示音訊檔案的絕對路徑。讓我們看一下。
print(timit[0]["path"])
列印輸出
'/root/.cache/huggingface/datasets/downloads/extracted/404950a46da14eac65eb4e2a8317b1372fb3971d980d91d5d5b221275b1fd7e0/data/TRAIN/DR4/MMDM0/SI681.WAV'
Wav2Vec2 期望輸入為 16 kHz 的 1 維陣列格式。這意味著必須載入並重新取樣音訊檔案。
值得慶幸的是,資料集透過呼叫其他列音訊自動完成了這項工作。讓我們試一試。
common_voice_train[0]["audio"]
列印輸出
{'array': array([-2.1362305e-04, 6.1035156e-05, 3.0517578e-05, ...,
-3.0517578e-05, -9.1552734e-05, -6.1035156e-05], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/404950a46da14eac65eb4e2a8317b1372fb3971d980d91d5d5b221275b1fd7e0/data/TRAIN/DR4/MMDM0/SI681.WAV',
'sampling_rate': 16000}
我們可以看到音訊檔案已自動載入。這要歸功於 datasets == 4.13.3 中引入的新的 "Audio" feature,它在呼叫時即時載入和重新取樣音訊檔案。
取樣率設定為 16kHz,這是 Wav2Vec2 所期望的輸入。
太棒了,讓我們聽幾段音訊檔案,以便更好地理解資料集並驗證音訊是否正確載入。
import IPython.display as ipd
import numpy as np
import random
rand_int = random.randint(0, len(timit["train"]))
print(timit["train"][rand_int]["text"])
ipd.Audio(data=np.asarray(timit["train"][rand_int]["audio"]["array"]), autoplay=True, rate=16000)
可以聽到,說話者的語速、口音等都有變化。儘管如此,總體而言,錄音聽起來相對清晰,這對於朗讀語音語料庫來說是意料之中的。
讓我們做最後一次檢查,確認資料準備是否正確,透過列印語音輸入的形狀、其轉寫文字以及相應的取樣率。
rand_int = random.randint(0, len(timit["train"]))
print("Target text:", timit["train"][rand_int]["text"])
print("Input array shape:", np.asarray(timit["train"][rand_int]["audio"]["array"]).shape)
print("Sampling rate:", timit["train"][rand_int]["audio"]["sampling_rate"])
列印輸出
Target text: she had your dark suit in greasy wash water all year
Input array shape: (52941,)
Sampling rate: 16000
好的!一切看起來都沒問題——資料是一維陣列,取樣率總是 16kHz,目標文字也已規範化。
最後,我們可以將資料集處理成模型訓練所需的格式。我們將使用 map(...) 函式。
首先,我們透過簡單地呼叫 batch["audio"] 來載入和重新取樣音訊資料。其次,我們從載入的音訊檔案中提取 input_values。在我們的例子中,Wav2Vec2Processor 僅對資料進行歸一化。然而,對於其他語音模型,此步驟可能包括更復雜的特徵提取,例如 對數梅爾頻率倒譜系數提取。第三,我們將轉錄編碼為標籤 ID。
注意:此對映函式是 Wav2Vec2Processor 類如何使用的很好的例子。在“正常”情況下,呼叫 processor(...) 會重定向到 Wav2Vec2FeatureExtractor 的呼叫方法。然而,當將處理器包裝到 as_target_processor 上下文中時,相同的方法會重定向到 Wav2Vec2CTCTokenizer 的呼叫方法。有關更多資訊,請查閱文件。
def prepare_dataset(batch):
audio = batch["audio"]
# batched output is "un-batched" to ensure mapping is correct
batch["input_values"] = processor(audio["array"], sampling_rate=audio["sampling_rate"]).input_values[0]
with processor.as_target_processor():
batch["labels"] = processor(batch["text"]).input_ids
return batch
讓我們將資料準備函式應用到所有樣本上。
timit = timit.map(prepare_dataset, remove_columns=timit.column_names["train"], num_proc=4)
注意:目前 datasets 使用 torchaudio 和 librosa 進行音訊載入和重取樣。如果您希望實現自己的自定義資料載入/取樣,請隨意只使用 "path" 列並忽略 "audio" 列。
訓練與評估
資料已處理,因此我們準備好開始設定訓練管道。我們將使用 🤗 的 Trainer,為此我們主要需要執行以下操作
定義資料整理器。與大多數 NLP 模型不同,Wav2Vec2 的輸入長度遠大於輸出長度。例如,輸入長度為 50000 的樣本的輸出長度不超過 100。鑑於輸入尺寸較大,動態填充訓練批次效率更高,這意味著所有訓練樣本都應僅填充到其批次中最長的樣本,而不是總體最長的樣本。因此,微調 Wav2Vec2 需要一個特殊的填充資料整理器,我們將在下面定義。
評估指標。在訓練期間,模型應以詞錯誤率進行評估。我們應該相應地定義一個
compute_metrics函式。載入預訓練檢查點。我們需要載入預訓練檢查點並對其進行正確配置以進行訓練。
定義訓練配置。
在微調模型後,我們將在測試資料上對其進行正確評估,並驗證它確實學會了正確轉寫語音。
設定訓練器
讓我們首先定義資料整理器。資料整理器的程式碼是從這個示例中複製的。
不深入細節,與常見的資料整理器不同,此資料整理器對 input_values 和 labels 進行不同的處理,因此對其應用單獨的填充函式(再次利用 Wav2Vec2 的上下文管理器)。這是必要的,因為在語音中,輸入和輸出是不同的模態,這意味著它們不應由相同的填充函式處理。類似於常見的資料整理器,標籤中的填充標記用 -100 填充,以便在計算損失時**不**考慮這些標記。
import torch
from dataclasses import dataclass, field
from typing import Any, Dict, List, Optional, Union
@dataclass
class DataCollatorCTCWithPadding:
"""
Data collator that will dynamically pad the inputs received.
Args:
processor (:class:`~transformers.Wav2Vec2Processor`)
The processor used for proccessing the data.
padding (:obj:`bool`, :obj:`str` or :class:`~transformers.tokenization_utils_base.PaddingStrategy`, `optional`, defaults to :obj:`True`):
Select a strategy to pad the returned sequences (according to the model's padding side and padding index)
among:
* :obj:`True` or :obj:`'longest'`: Pad to the longest sequence in the batch (or no padding if only a single
sequence if provided).
* :obj:`'max_length'`: Pad to a maximum length specified with the argument :obj:`max_length` or to the
maximum acceptable input length for the model if that argument is not provided.
* :obj:`False` or :obj:`'do_not_pad'` (default): No padding (i.e., can output a batch with sequences of
different lengths).
max_length (:obj:`int`, `optional`):
Maximum length of the ``input_values`` of the returned list and optionally padding length (see above).
max_length_labels (:obj:`int`, `optional`):
Maximum length of the ``labels`` returned list and optionally padding length (see above).
pad_to_multiple_of (:obj:`int`, `optional`):
If set will pad the sequence to a multiple of the provided value.
This is especially useful to enable the use of Tensor Cores on NVIDIA hardware with compute capability >=
7.5 (Volta).
"""
processor: Wav2Vec2Processor
padding: Union[bool, str] = True
max_length: Optional[int] = None
max_length_labels: Optional[int] = None
pad_to_multiple_of: Optional[int] = None
pad_to_multiple_of_labels: Optional[int] = None
def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
# split inputs and labels since they have to be of different lengths and need
# different padding methods
input_features = [{"input_values": feature["input_values"]} for feature in features]
label_features = [{"input_ids": feature["labels"]} for feature in features]
batch = self.processor.pad(
input_features,
padding=self.padding,
max_length=self.max_length,
pad_to_multiple_of=self.pad_to_multiple_of,
return_tensors="pt",
)
with self.processor.as_target_processor():
labels_batch = self.processor.pad(
label_features,
padding=self.padding,
max_length=self.max_length_labels,
pad_to_multiple_of=self.pad_to_multiple_of_labels,
return_tensors="pt",
)
# replace padding with -100 to ignore loss correctly
labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
batch["labels"] = labels
return batch
讓我們初始化資料整理器。
data_collator = DataCollatorCTCWithPadding(processor=processor, padding=True)
接下來,定義評估指標。如前所述,ASR 中最主要的指標是詞錯誤率 (WER),因此我們在這個 notebook 中也使用它。
wer_metric = load_metric("wer")
模型將返回一個 logits 向量序列
,
其中 和 。
一個 logits 向量 包含我們之前定義的詞彙表中每個詞的對數機率,因此 config.vocab_size。我們對模型最有可能的預測感興趣,因此取 logits 的 argmax(...)。此外,我們透過將 -100 替換為 pad_token_id 並解碼 ID,同時確保連續的標記**不**以 CTC 樣式 分組來將編碼的標籤轉換回原始字串。
def compute_metrics(pred):
pred_logits = pred.predictions
pred_ids = np.argmax(pred_logits, axis=-1)
pred.label_ids[pred.label_ids == -100] = processor.tokenizer.pad_token_id
pred_str = processor.batch_decode(pred_ids)
# we do not want to group tokens when computing the metrics
label_str = processor.batch_decode(pred.label_ids, group_tokens=False)
wer = wer_metric.compute(predictions=pred_str, references=label_str)
return {"wer": wer}
現在,我們可以載入預訓練的 Wav2Vec2 檢查點。分詞器的 pad_token_id 必須定義模型的 pad_token_id,或者在 Wav2Vec2ForCTC 的情況下,也定義 CTC 的空白標記 。為了節省 GPU 記憶體,我們啟用了 PyTorch 的 梯度檢查點,並將損失減少設定為“mean”。
from transformers import Wav2Vec2ForCTC
model = Wav2Vec2ForCTC.from_pretrained(
"facebook/wav2vec2-base",
ctc_loss_reduction="mean",
pad_token_id=processor.tokenizer.pad_token_id,
)
列印輸出
Some weights of Wav2Vec2ForCTC were not initialized from the model checkpoint at facebook/wav2vec2-base and are newly initialized: ['lm_head.weight', 'lm_head.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Wav2Vec2 的第一個元件由一系列 CNN 層組成,這些層用於從原始語音訊號中提取具有聲學意義但與上下文無關的特徵。模型的這一部分在預訓練期間已經得到了充分訓練,並且如論文所述,不再需要進行微調。因此,我們可以將特徵提取部分的所有引數的 requires_grad 設定為 False。
model.freeze_feature_extractor()
最後一步,我們定義所有與訓練相關的引數。對其中一些引數進行更多解釋:
group_by_length透過將輸入長度相似的訓練樣本分組到一個批次中,使訓練更高效。這可以透過大大減少透過模型的無用填充標記的總數來顯著加快訓練時間learning_rate和weight_decay經過啟發式調整,直到微調變得穩定。請注意,這些引數強烈依賴於 Timit 資料集,可能不適用於其他語音資料集。
關於其他引數的更多解釋,可以檢視文件。
訓練期間,每 400 個訓練步驟會將一個檢查點非同步上傳到 Hub。這允許您在模型仍在訓練時也可以使用演示小部件。
注意:如果不想將模型檢查點上傳到 Hub,只需設定 push_to_hub=False。
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir=repo_name,
group_by_length=True,
per_device_train_batch_size=32,
evaluation_strategy="steps",
num_train_epochs=30,
fp16=True,
gradient_checkpointing=True,
save_steps=500,
eval_steps=500,
logging_steps=500,
learning_rate=1e-4,
weight_decay=0.005,
warmup_steps=1000,
save_total_limit=2,
)
現在,所有例項都可以傳遞給 Trainer,我們準備開始訓練了!
from transformers import Trainer
trainer = Trainer(
model=model,
data_collator=data_collator,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=timit_prepared["train"],
eval_dataset=timit_prepared["test"],
tokenizer=processor.feature_extractor,
)
為了使模型獨立於說話者語速,在 CTC 中,連續的相同標記簡單地被分組為單個標記。然而,在解碼時,編碼的標籤不應分組,因為它們不對應於模型的預測標記,這就是為什麼必須傳遞 group_tokens=False 引數。如果我們不傳遞此引數,像 "hello" 這樣的詞將被錯誤地編碼並解碼為 "helo"。 空白標記允許模型預測一個詞,例如 "hello",透過強制它在兩個 l 之間插入空白標記。我們模型對 "hello" 的符合 CTC 的預測將是 [PAD] [PAD] "h" "e" "e" "l" "l" [PAD] "l" "o" "o" [PAD]。
訓練
訓練將需要 90 到 180 分鐘,具體取決於分配給此筆記本的 Google Colab 的 GPU。雖然訓練好的模型在 Timit 的測試資料上取得了令人滿意的結果,但它絕不是一個最優微調的模型。本筆記本的目的是演示如何對 Wav2Vec2 的 base、large 和 large-lv60 檢查點在任何英語資料集上進行微調。
如果您想使用此 Google Colab 微調您的模型,您應該確保您的訓練不會因為不活動而停止。一個簡單的防止方法是將以下程式碼貼上到此標籤的控制檯中(右鍵單擊 -> 檢查 -> 控制檯選項卡並插入程式碼)。
function ConnectButton(){
console.log("Connect pushed");
document.querySelector("#top-toolbar > colab-connect-button").shadowRoot.querySelector("#connect").click()
}
setInterval(ConnectButton,60000);
trainer.train()
根據您的 GPU,這裡可能會出現 "記憶體不足" 錯誤。在這種情況下,最好將 per_device_train_batch_size 減少到 16 或更少,並最終使用 gradient_accumulation。
列印輸出
| 步驟 | 訓練損失 | 驗證損失 | 詞錯誤率 (WER) | 執行時 | 每秒樣本數 |
|---|---|---|---|---|---|
| 500 | 3.758100 | 1.686157 | 0.945214 | 97.299000 | 17.266000 |
| 1000 | 0.691400 | 0.476487 | 0.391427 | 98.283300 | 17.093000 |
| 1500 | 0.202400 | 0.403425 | 0.330715 | 99.078100 | 16.956000 |
| 2000 | 0.115200 | 0.405025 | 0.307353 | 98.116500 | 17.122000 |
| 2500 | 0.075000 | 0.428119 | 0.294053 | 98.496500 | 17.056000 |
| 3000 | 0.058200 | 0.442629 | 0.287299 | 98.871300 | 16.992000 |
| 3500 | 0.047600 | 0.442619 | 0.285783 | 99.477500 | 16.888000 |
| 4000 | 0.034500 | 0.456989 | 0.282200 | 99.419100 | 16.898000 |
最終 WER 應低於 0.3,考慮到最先進的音素錯誤率 (PER) 略低於 0.1(參見排行榜),並且 WER 通常比 PER 差,這是合理的。
您現在可以將訓練結果上傳到 Hub,只需執行此指令
trainer.push_to_hub()
你現在可以和所有的朋友、家人、心愛的寵物分享這個模型:他們都可以用“your-username/the-name-you-picked”這個識別符號來載入它,例如:
from transformers import AutoModelForCTC, Wav2Vec2Processor
model = AutoModelForCTC.from_pretrained("patrickvonplaten/wav2vec2-base-timit-demo-colab")
processor = Wav2Vec2Processor.from_pretrained("patrickvonplaten/wav2vec2-base-timit-demo-colab")
評估
最後一部分,我們將在測試集上評估我們的微調模型並進行一些嘗試。
讓我們載入 processor 和 model。
processor = Wav2Vec2Processor.from_pretrained(repo_name)
model = Wav2Vec2ForCTC.from_pretrained(repo_name)
現在,我們將使用 map(...) 函式來預測每個測試樣本的轉錄,並將預測儲存到資料集本身中。我們將結果字典稱為 "results"。
注意:由於此問題,我們故意以 batch_size=1 評估測試資料集。由於填充輸入不會產生與非填充輸入完全相同的輸出,因此透過完全不填充輸入可以獲得更好的 WER。
def map_to_result(batch):
with torch.no_grad():
input_values = torch.tensor(batch["input_values"], device="cuda").unsqueeze(0)
logits = model(input_values).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_str"] = processor.batch_decode(pred_ids)[0]
batch["text"] = processor.decode(batch["labels"], group_tokens=False)
return batch
results = timit["test"].map(map_to_result, remove_columns=timit["test"].column_names)
現在讓我們計算整體 WER。
print("Test WER: {:.3f}".format(wer_metric.compute(predictions=results["pred_str"], references=results["text"])))
列印輸出
Test WER: 0.221
22.1% WER - 不錯!我們的演示模型可能已經登上了官方排行榜。
讓我們看看一些預測,瞭解模型犯了哪些錯誤。
列印輸出
show_random_elements(results.remove_columns(["speech", "sampling_rate"]))
| 預測字串 | 目標文字 |
|---|---|
| 旨在平衡您的員工福利待遇 | 旨在平衡您的員工福利待遇 |
| 大霧阻礙了他們準時到達 | 大霧阻礙了他們準時到達 |
| 幼兒應避免接觸傳染病 | 幼兒應避免接觸傳染病 |
| 人工智慧是真的 | 人工智慧是真的 |
| 他們的道具是兩個梯子、一把椅子和一個棕櫚扇 | 他們的道具是兩個梯子、一把椅子和一個棕櫚扇 |
| 如果人們更慷慨,就不需要福利了 | 如果人們更慷慨,就不需要福利了 |
| 魚兒開始在小湖水面上瘋狂跳躍 | 魚兒開始在小湖水面上瘋狂跳躍 |
| 她的右手一到氣壓變化就疼 | 她的右手一到氣壓變化就疼 |
| 只有律師愛百萬富翁 | 只有律師愛百萬富翁 |
| 最近的離經叛道者可能不在步行範圍內 | 最近的猶太教堂可能不在步行範圍內 |
很明顯,預測的轉錄在聲學上與目標轉錄非常相似,但經常包含拼寫或語法錯誤。這並不令人驚訝,因為我們完全依賴 Wav2Vec2,而沒有使用語言模型。
最後,為了更好地理解 CTC 的工作原理,值得更深入地研究模型的精確輸出。讓我們透過模型執行第一個測試樣本,獲取預測的 ID 並將其轉換為相應的標記。
model.to("cuda")
with torch.no_grad():
logits = model(torch.tensor(timit["test"][:1]["input_values"], device="cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
# convert ids to tokens
" ".join(processor.tokenizer.convert_ids_to_tokens(pred_ids[0].tolist()))
列印輸出
[PAD] [PAD] [PAD] [PAD] [PAD] [PAD] t t h e e | | b b [PAD] u u n n n g g [PAD] a [PAD] [PAD] l l [PAD] o o o [PAD] | w w a a [PAD] s s | | [PAD] [PAD] p l l e e [PAD] [PAD] s s e n n t t t [PAD] l l y y | | | s s [PAD] i i [PAD] t t t [PAD] u u u u [PAD] [PAD] [PAD] a a [PAD] t t e e e d d d | n n e e a a a r | | t h h e | | s s h h h [PAD] o o o [PAD] o o r r [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]
該輸出應該更清楚地說明 CTC 在實踐中是如何工作的。該模型在某種程度上不受語速的影響,因為它已經學會了在需要分類的語音塊仍然對應於同一個標記時,簡單地重複相同的標記。這使得 CTC 成為語音識別的強大演算法,因為語音檔案的轉錄通常與其長度非常無關。
我再次建議讀者檢視這篇非常好的部落格文章,以便更好地理解 CTC。












