隆重推出 🤗 Optimum:用於大規模 Transformer 模型的最佳化工具包






這篇文章是 Hugging Face 普及最先進機器學習生產效能之旅的第一步。為此,我們將與我們的硬體合作伙伴(如本文中的英特爾)攜手合作。加入我們,關注我們的新開源庫 Optimum!
為什麼選擇 🤗 Optimum?
🤯 擴充套件 Transformer 模型並非易事
特斯拉、谷歌、微軟和 Facebook 有什麼共同點?當然有很多,但其中之一是它們每天都執行數十億個 Transformer 模型預測。特斯拉的自動駕駛(真幸運!)使用 Transformer 模型,Gmail 完成你的句子,Facebook 即時翻譯你的帖子,Bing 回答你的自然語言查詢。
Transformer 模型極大地提高了機器學習模型的準確性,征服了自然語言處理領域,現在正擴充套件到其他模態,從語音和視覺開始。但將這些龐大的模型投入生產並使其大規模快速執行,對於任何機器學習工程團隊來說都是一個巨大的挑戰。
如果你不像上述公司那樣擁有數百名高技能機器學習工程師,該怎麼辦?透過 Optimum,我們的新開源庫,我們旨在構建用於 Transformer 模型生產效能的權威工具包,並實現模型在特定硬體上訓練和執行的最大效率。
🏭 Optimum 讓 Transformer 模型發揮作用
為了獲得最佳的模型訓練和推理效能,模型加速技術需要與目標硬體專門相容。每個硬體平臺都提供特定的軟體工具、功能和可對效能產生巨大影響的旋鈕。同樣,為了利用稀疏性、量化等高階模型加速技術,最佳化的核心需要與晶片上的運算元相容,並針對從模型架構派生出的神經網路圖進行定製。深入研究這種三維相容性矩陣以及如何使用模型加速庫是一項艱鉅的工作,很少有機器學習工程師擁有這方面的經驗。
Optimum 旨在簡化這項工作,提供針對高效人工智慧硬體的效能最佳化工具,這些工具是與我們的硬體合作伙伴協作構建的,並將機器學習工程師轉變為機器學習最佳化嚮導。
透過 Transformers 庫,我們讓研究人員和工程師輕鬆使用最先進的模型,抽象化框架、架構和管道的複雜性。
透過 Optimum 庫,我們讓工程師輕鬆利用他們可用的所有硬體功能,抽象化硬體平臺上模型加速的複雜性。
🤗 Optimum 實踐:如何為 Intel Xeon CPU 量化模型
🤔 為什麼量化很重要,但很難做到完美
預訓練語言模型(如 BERT)在各種自然語言處理任務上取得了最先進的結果,其他基於 Transformer 的模型(如 ViT 和 Speech2Text)分別在計算機視覺和語音任務上取得了最先進的結果:Transformer 無處不在機器學習世界,並將繼續存在。
然而,將基於 Transformer 的模型投入生產可能很棘手且成本高昂,因為它們需要大量的計算能力才能工作。為了解決這個問題,存在許多技術,其中最流行的是量化。不幸的是,在大多數情況下,量化模型需要大量工作,原因有很多:
- 模型需要被編輯:一些操作需要被其量化對應項替換,需要插入新的操作(量化和反量化節點),其他操作需要適應權重和啟用將被量化的事實。
這部分可能非常耗時,因為 PyTorch 等框架以急切模式工作,這意味著上述更改需要新增到模型實現本身。PyTorch 現在提供了一個名為 torch.fx 的工具,它允許你在不實際更改模型實現的情況下跟蹤和轉換模型,但在你的模型開箱即不支援跟蹤時,使用起來很棘手。
除了實際的編輯之外,還需要找出模型哪些部分需要編輯,哪些操作有可用的量化核心對應項,哪些操作沒有,等等。
模型編輯完成後,還有許多引數可以調整以找到最佳量化設定。
- 我應該使用哪種觀察器進行範圍校準?
- 我應該使用哪種量化方案?
- 我的目標裝置支援哪些量化相關資料型別(int8、uint8、int16)?
平衡量化和可接受的精度損失之間的權衡。
匯出量化模型以供目標裝置使用。
儘管 PyTorch 和 TensorFlow 在簡化量化方面取得了巨大進展,但基於 Transformer 模型的複雜性使得它們很難開箱即用,並且在不付出大量努力的情況下很難讓它們正常工作。
💡 英特爾如何利用 Neural Compressor 解決量化及更多問題
英特爾® Neural Compressor(以前稱為低精度最佳化工具或 LPOT)是一個開源 Python 庫,旨在幫助使用者部署低精度推理解決方案。後者將低精度配方應用於深度學習模型,以實現最佳產品目標,例如推理效能和記憶體使用,並滿足預期的效能標準。Neural Compressor 支援訓練後量化、量化感知訓練和動態量化。為了指定量化方法、目標和效能標準,使用者必須提供一個指定調優引數的 YAML 配置檔案。該配置檔案可以託管在 Hugging Face 的模型中心,也可以透過本地目錄路徑提供。
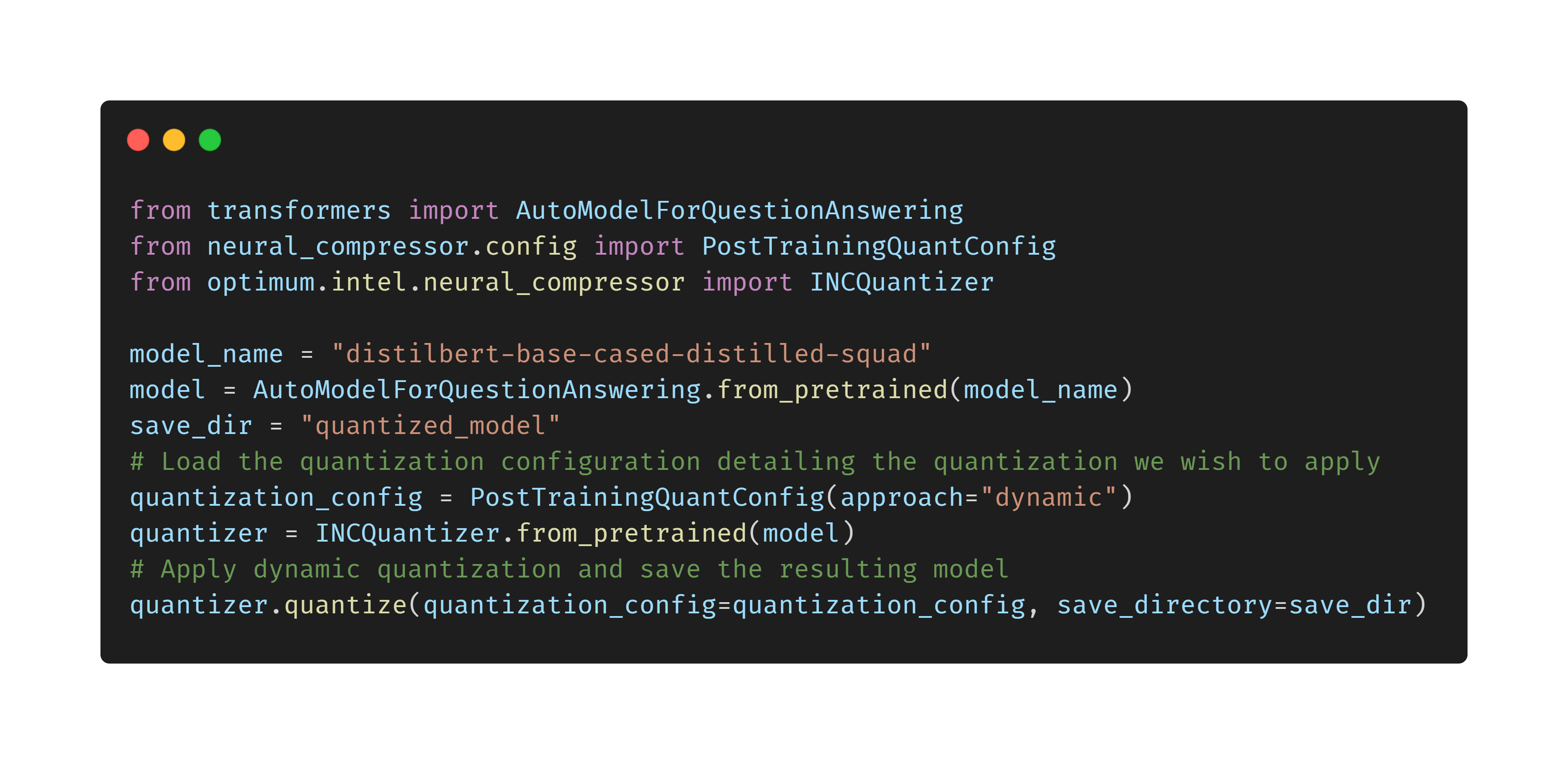
🔥 如何使用 Optimum 輕鬆為 Intel Xeon CPU 量化 Transformer 模型
關注 🤗 Optimum:普及 ML 生產效能的旅程
⚡️最先進的硬體
Optimum 將專注於在專用硬體上實現最佳生產效能,在該硬體上可以應用軟體和硬體加速技術以實現最大效率。我們將與我們的硬體合作伙伴攜手合作,以輕鬆且易於訪問的方式透過 Optimum 啟用、測試和維護加速,就像我們與英特爾和 Neural Compressor 所做的那樣。我們很快將宣佈新的硬體合作伙伴,他們已加入我們實現機器學習效率的旅程。
🔮 最先進的模型
與我們的硬體合作伙伴的合作將產生針對硬體最佳化的模型配置和工件,我們將透過 Hugging Face 模型中心向 AI 社群提供這些配置和工件。我們希望 Optimum 和硬體最佳化的模型能夠加速生產工作負載中效率的採用,這代表了機器學習所消耗的大部分總能量。最重要的是,我們希望 Optimum 能夠加速 Transformer 模型的大規模採用,不僅適用於最大的科技公司,也適用於我們所有人。
🌟 協作之旅:加入我們,關注我們的進展
每一次旅程都始於第一步,而我們的第一步就是 Optimum 的公開發布。加入我們,透過為該庫點贊邁出你的第一步,這樣你就可以在我們推出新支援的硬體、加速技術和最佳化模型時隨時關注我們的進展。
如果您希望 Optimum 支援新的硬體和功能,或者您有興趣加入我們,在軟體和硬體的交叉領域工作,請透過 hardware@huggingface.co 聯絡我們

