筆記本上的聊天機器人:Intel Meteor Lake 上的 Phi-2












大型語言模型 (LLM) 因其令人印象深刻的能力而需要大量的計算能力,這在個人電腦上很少能得到。因此,我們別無選擇,只能將它們部署在本地或雲中託管的強大定製 AI 伺服器上。
為什麼本地 LLM 推理是可取的
如果我們能在普通的個人電腦上執行最先進的開源 LLM 會怎麼樣?我們難道不能享受到以下好處嗎?
- 提高隱私性:我們的資料不會被髮送到外部 API 進行推理。
- 更低的延遲:我們可以節省網路往返時間。
- 離線工作:我們可以離線工作(常旅客的夢想!)。
- 更低的成本:我們不會在 API 呼叫或模型託管上花費任何費用。
- 可定製性:每個使用者都可以找到最適合他們日常工作的模型,甚至可以對它們進行微調或使用本地檢索增強生成(RAG)來提高相關性。
這一切聽起來確實令人興奮。那我們為什麼還沒有開始呢?回到我們最初的宣告,您的典型價格合理的筆記型電腦沒有足夠的計算能力來以可接受的效能執行 LLM。看不到數千核 GPU,也沒有閃電般快速的高頻寬記憶體。
那是不是就沒戲了?當然不是。
為什麼本地 LLM 推理現在成為可能
沒有什麼人類思維無法做得更小、更快、更優雅、更具成本效益。近幾個月來,人工智慧社群一直在努力縮小模型,同時不損害其預測質量。以下三個領域令人興奮:
硬體加速:現代 CPU 架構嵌入了專門用於加速最常見的深度學習運算元的硬體,例如矩陣乘法或卷積,從而在 AI PC 上實現了新的生成式 AI 應用程式,並顯著提高了它們的速度和效率。
小型語言模型(SLM):得益於創新的架構和訓練技術,這些模型與大型模型不相上下甚至更優。由於引數更少,推理所需的計算和記憶體更少,使其成為資源受限環境的絕佳選擇。
量化:量化是透過減少模型權重和啟用的位寬(例如,從 16 位浮點(`fp16`)到 8 位整數(`int8`))來降低記憶體和計算需求的過程。減少位數意味著生成的模型在推理時所需的記憶體更少,從而加快了記憶體密集型步驟(如文字生成時的解碼階段)的延遲。此外,當權重和啟用都進行量化時,由於整數運算,矩陣乘法等操作可以更快地執行。
在本文中,我們將利用上述所有技術。我們將從 Microsoft Phi-2 模型開始,藉助我們 Optimum Intel 庫中整合的 Intel OpenVINO,對模型權重應用 4 位量化。然後,我們將在搭載 Intel Meteor Lake CPU 的中端筆記型電腦上執行推理。
注意:如果您有興趣對權重和啟用都進行量化,您可以在我們的 文件 中找到更多資訊。
開始工作吧。
英特爾 Meteor Lake
英特爾 Meteor Lake 於 2023 年 12 月釋出,現已更名為 酷睿 Ultra,這是一種為高效能筆記型電腦最佳化的新 架構。
作為英特爾首款採用晶片組架構的客戶端處理器,Meteor Lake 包含:
一個高能效 CPU,最多擁有 16 個核心,
一個整合 GPU (iGPU),最多擁有 8 個 Xe 核心,每個核心配備 16 個 Xe 向量引擎 (XVE)。顧名思義,XVE 可以對 256 位向量執行向量操作。它還實現了 DP4a 指令,該指令計算兩個 4 位元組值向量的點積,將結果儲存在 32 位整數中,並將其新增到第三個 32 位整數中。
神經網路處理單元(NPU),這是英特爾架構的首次嘗試。NPU 是專為高效客戶端 AI 設計的專用 AI 引擎。它經過最佳化,可高效處理要求苛刻的 AI 計算,從而為主 CPU 和圖形處理器騰出資源,用於其他任務。與使用 CPU 或 iGPU 執行 AI 任務相比,NPU 的設計更加節能。
為了執行下面的演示,我們選擇了一款搭載 酷睿 Ultra 7 155H CPU 的 中端筆記型電腦。現在,讓我們選擇一個可愛的小型語言模型在這檯筆記本電腦上執行。
注意:要在 Linux 上執行此程式碼,請按照 這些說明 安裝 GPU 驅動程式。
微軟 Phi-2 模型
Phi-2 於 2023 年 12 月釋出,是一個擁有 27 億引數的模型,用於文字生成。
根據已報告的基準測試,Phi-2 儘管規模較小,但其效能超越了一些最佳的 70 億和 130 億 LLM,甚至與更大的 Llama-2 70B 模型旗鼓相當。
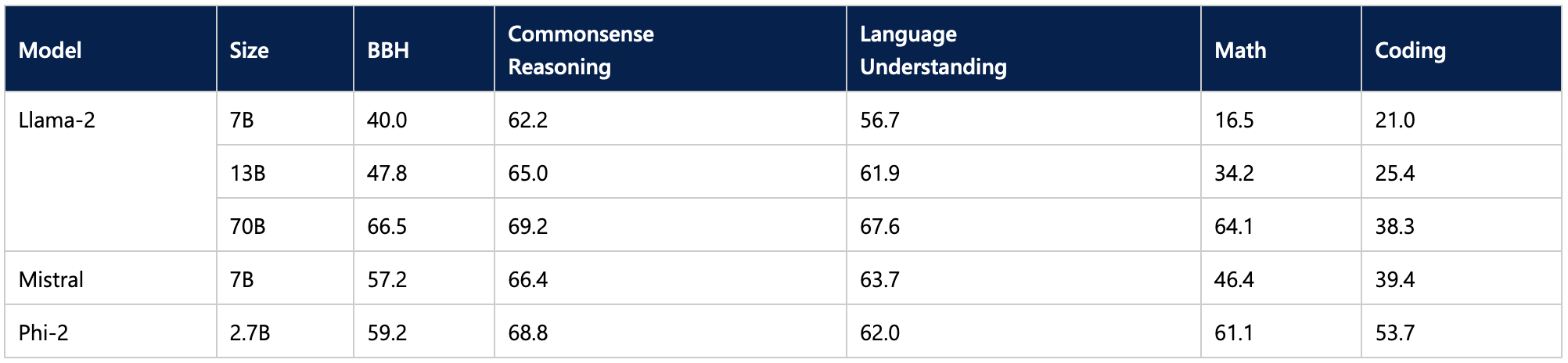
這使得它成為筆記型電腦推理的一個令人興奮的候選模型。好奇的讀者可能還想嘗試使用 11 億引數的 TinyLlama 模型。
現在,讓我們看看如何縮小模型,使其更小更快。
使用 Intel OpenVINO 和 Optimum Intel 進行量化
Intel OpenVINO 是一個開源工具包,用於在許多 Intel 硬體平臺(Github、文件)上最佳化 AI 推理,特別是透過模型量化。
透過與英特爾合作,我們已將 OpenVINO 整合到 Optimum Intel 中,Optimum Intel 是我們專門用於加速英特爾平臺上 Hugging Face 模型的開源庫(Github、文件)。
首先,請確保您已安裝最新版本的 optimum-intel 以及所有必要的庫
pip install --upgrade-strategy eager optimum[openvino,nncf]
這種整合使得將 Phi-2 量化到 4 位變得非常簡單。我們定義一個量化配置,設定最佳化引數,然後從 hub 載入模型。一旦模型被量化和最佳化,我們將其本地儲存。
from transformers import AutoTokenizer, pipeline
from optimum.intel import OVModelForCausalLM, OVWeightQuantizationConfig
model_id = "microsoft/phi-2"
device = "gpu"
# Create the quantization configuration with desired quantization parameters
q_config = OVWeightQuantizationConfig(bits=4, group_size=128, ratio=0.8)
# Create OpenVINO configuration with optimal settings for this model
ov_config = {"PERFORMANCE_HINT": "LATENCY", "CACHE_DIR": "model_cache", "INFERENCE_PRECISION_HINT": "f32"}
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = OVModelForCausalLM.from_pretrained(
model_id,
export=True, # export model to OpenVINO format: should be False if model already exported
quantization_config=q_config,
device=device,
ov_config=ov_config,
)
# Compilation step : if not explicitly called, compilation will happen before the first inference
model.compile()
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
results = pipe("He's a dreadful magician and")
save_directory = "phi-2-openvino"
model.save_pretrained(save_directory)
tokenizer.save_pretrained(save_directory)
`ratio` 引數控制我們將量化為 4 位(此處為 80%)的權重比例,其餘的量化為 8 位。`group_size` 引數定義了權重量化組的大小(此處為 128),每個組都有其縮放因子。減小這兩個值通常會提高精度,但會犧牲模型大小和推理延遲。
您可以在我們的文件中找到有關僅權重量化的更多資訊。
注意:包含文字生成示例的完整筆記本可在 Github 上找到。
那麼,量化模型在我們的筆記型電腦上有多快呢?觀看以下影片,親眼看看。請記住選擇 1080p 解析度以獲得最大清晰度。
第一個影片向我們的模型提出了一個高中物理問題:“莉莉有一個橡皮球,她從牆頂上扔下來。牆高 2 米。球需要多長時間才能落地?”
第二個影片向我們的模型提出了一個編碼問題:“編寫一個類,使用 numpy 實現一個具有前向和後向函式的全連線層。程式碼使用 markdown 標記。”
正如您在兩個示例中看到的,生成的答案質量非常高。量化過程並未降低 Phi-2 的高質量,並且生成速度也足夠。我很樂意每天使用此模型進行本地工作。
結論
感謝 Hugging Face 和 Intel,您現在可以在筆記型電腦上執行 LLM,享受本地推理的諸多好處,例如隱私、低延遲和低成本。我們希望看到更多為 Meteor Lake 平臺及其後續產品 Lunar Lake 最佳化的優質模型。Optimum Intel 庫使為 Intel 平臺量化模型變得非常容易,所以為什麼不嘗試一下並在 Hugging Face Hub 上分享您的優秀模型呢?我們總是需要更多!
以下是一些資源可幫助您入門:
如果您有任何問題或反饋,我們很樂意在 Hugging Face 論壇上回答。
感謝閱讀!


